准备
Java Downloads | Oracle 官网:下载hadoop-2.7.3.tar.gz
Apache Hadoop 官网:下载hadoop-2.7.3.tar.gz
下到本地后用Xftp 6或者其它方法上传到服务器,我上传到了/opt/local,用XShell和notepad++(或vscode或直接vi编辑器)连接服务器
连接XShell后,执行停止防火墙 systemctl stop firewalld.service,禁止firewall开机启动 systemctl disable firewalld.service,查看firewall-cmd --state 显示not running
解压
连上服务器先切到压缩包路径下,cd /opt/software,执行解压缩,解压到/usr/local/(必须是这个路径,不要自定义)
tar -zxvf jdk-8u162-linux-x64.tar.gz -C /usr/local/ #解压jdk
tar -zxvf hadoop-2.7.3.tar.gz -C /usr/local/ # 解压hadoop
配置JDK环境
在notepad++中打开/etc/profile,最后面添加
export JAVA_HOME=/usr/local/jdk1.8.0_162 #<-改成自己的jdk
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=${JAVA_HOME}/bin:$PATH
配置完成后输入XShell中source /etc/profile让环境变量生效
检查结果输入javac或javac或java -version返回相关信息
# 示例
[root@server1 ~]# java -version
java version "1.8.0_162"
Java(TM) SE Runtime Environment (build 1.8.0_162-b12)
Java HotSpot(TM) 64-Bit Server VM (build 25.162-b12, mixed mode)
配置Hadoop
Hadoop有三种模式
-
Local (Standalone) Mode(本地模式):开发人员debug调试使用,local把文件存到本地的文件系统中
-
Pseudo-Distributed Mode(伪分布式):开发人员debug调试使用,在本地搭建HDFS,伪分布式,完全分布
-
Fully-Distributed Mode(完全分布式(集群) ):生产环境使用,高可用性,比如突然有个节点出问题,保证集群还可用
本地模式
在notepad++中打开/etc/profile,最后面添加
export HADOOP_HOME=/usr/local/hadoop-2.7.3 #<-换成自己的
export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
配置完成后输入XShell中输入source /etc/profile让环境变量生效,接着
cd ~
cd $HADOOP_HOME
cd share/hadoop/mapreduce
ls # 查看目录有一个hadoop-mapreduce-examples-2.7.3.jar,用这个测试样例程序
hadoop jar hadoop-mapreduce-examples-2.7.3.jar pi 10 20 #返回圆周率
# 结果返回一大串最后一行是圆周率,就对了
Job Finished in 6.524 seconds
Estimated value of Pi is 3.12000000000000000000
伪分布模式
完全分布式需要免密登录,不然每一次都需要输入密码
根目录下没有.ssh这个文件,在XShell中输入ssh localhost输入密码,输入yes,exit,退出之后,输入ls -a此时根目录下已有.ssh文件
cd .ssh
ssh-keygen -t rsa # 连续三次回车,生成公钥
ssh-copy-id root@localhost # 将公钥加入授权文件
ssh localhost # 测试,不需要再输入密码
exit # 退出
先为主机添加映射,本地电脑C:\Windows\System32\drivers\etc\host
# 打开CMD,输入
ipconfig
# 找VMware Network Adapter VMnet8的IPV4
以太网适配器 VMware Network Adapter VMnet8:
IPv4 地址 . . . . . . . . . . . . : xxx.xxx.xx.x
# 查看本机名字
hostname
# 返回名字
xxxxxx
# 任务栏搜索cmd右击管理员运行(host文件需要管理员权限),输入
notepad C:\Windows\System32\drivers\etc\hosts
# 在最下面加
xxx.xxx.xx.x name #查到本地电脑的IPV4 主机名
xxx.xxx.xx.x name #虚拟机的ip 主机名
同理为虚拟机添加映射,不知道配置可以先在XShell输命令找一下,查看虚拟机主机名hostname,查看ip地址ifconfig,用notepad++找/etc/hosts
# 在最下面加
xxx.xxx.xx.x name #查到本地电脑的IPV4 主机名
xxx.xxx.xx.x name #虚拟机的ip 主机名
完全分布式与伪分布大同小异,多台虚拟机,之后的配置文件都需要配一遍然后且每一个虚拟机的/etc/hosts和本地的host都需要做映射
xxx.xxx.xx.x name #查到本地电脑的IPV4 主机名
xxx.xxx.xx.x name #虚拟机1号的ip 主机名
xxx.xxx.xx.x name #虚拟机2号的ip 主机名
之后配置文件,以下操作到notepad++进行文件编辑,在/usr/local/hadoop-2.7.3/etc/hadoop找对应文件
hadoop-env.sh
# The java implementation to use.
export JAVA_HOME=${JAVA_HOME} #<-找到这行
# The java implementation to use.
export JAVA_HOME=/usr/local/jdk1.8.0_162 # <-改为自己的jdk
mapred-env.sh
# export JAVA_HOME=/home/y/libexec/jdk1.6.0/ <-找到这行(16)
export JAVA_HOME=/usr/local/jdk1.8.0_162 # <-改为自己的jdk
yarn-env.sh
# export JAVA_HOME=/home/y/libexec/jdk1.6.0/ #<-找到这行(23)
export JAVA_HOME=/usr/local/jdk1.8.0_162 # <-改为自己的jdk
建好目录(之后格式化也会自动生成,可以跳过)
cd /usr/local/hadoop-2.7.3/
mkdir data
cd data
mkdir name
mkdir tmp
core-site.xml,最下面修改<configuration></configuration>,第6行换为自己的主机
<configuration>
<!--指定Hadoop框架使用HDFS作为文件系统-->
<!--这里的主机名就是namenode所在的节点的主机名-->
<property>
<name>fs.defaultFS</name>
<value>hdfs://server1:8020</value> <!--server是自己的主机名-->
</property>
<!--hadoop工作目录,如果没有data/tmp目录,要先在磁盘上创建。如果不创建,格式化hdfs后会自动创建。-->
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/hadoop-2.7.3/data/tmp</value>
</property>
</configuration>
hdfs-site.xml,最下面修改<configuration></configuration>
<!--注:如果没有data目录和data/name目录,要先在磁盘上创建。如果不创建,格式化hdfs后会自动创建。-->
<configuration>
<property>
<name>dfs.namenode.name.dir</name>
<value>/usr/local/hadoop-2.7.3/data/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/usr/local/hadoop-2.7.3/data</value>
</property>
<!--设置HDFS文件系统块的复制份数,默认是3。伪分布模式要设为1-->
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
mapred-site.xml,默认没有这个文件,从notepad++直接新建文件命名mapred-site.xml,从mapred-site.xml.template复制内容,也可以通过XShell命令cp mapred-site.xml.template mapred-site.xml
最下面修改<configuration></configuration>,注意第10、14行换成自己主机名,注意server是自己的主机名,也可以写IP地址,前提都是需要做好主机名与ip的映射
<configuration>
<!--指定mapreduce运行在yarn集群-->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<!--历史服务-->
<property>
<name>mapreduce.jobhistory.address</name>
<value>server1:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>server1:19888</value>
</property>
</configuration>
yarn-site.xml,最下面修改<configuration></configuration>,注意第12行换成自己主机名
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce_shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>server1</value>
</property>
</configuration>
格式化只能做一次!hdfs namenode -format,格式化成功会返回Exiting with status 0
22/06/05 00:08:46 INFO util.ExitUtil: Exiting with status 0
22/06/05 00:08:46 INFO namenode.NameNode: SHUTDOWN_MSG:
/************************************************************
SHUTDOWN_MSG: Shutting down NameNode at server1/192.168.26.153
************************************************************/
如果是status 其它查看报错根据报错修改,检查错误后,执行以下命令,然后再次格式化
cd /usr/local/hadoop-2.7.3/data
rm tmp -rf
rm name -rf
测试
- 启动集群
start-dfs.sh,输入yes - 使用jps命令查看当前节点上运行的服务:
jps - 启动
start-yarn.sh - 成功启动后,通过Web界面查看NameNode和Datanode信息和HDFS文件系统:打开浏览器输入(Windows
C:\Windows\System32\drivers\etc\host的和Linux的/etc/hosts映射配置好):http://server1:50070,http://server1:8088查看任务进度
http://server1:50070如图
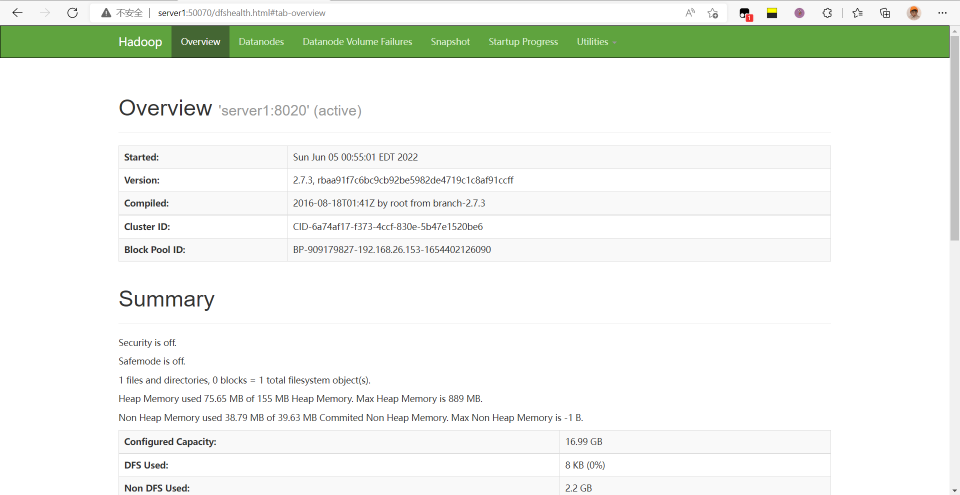
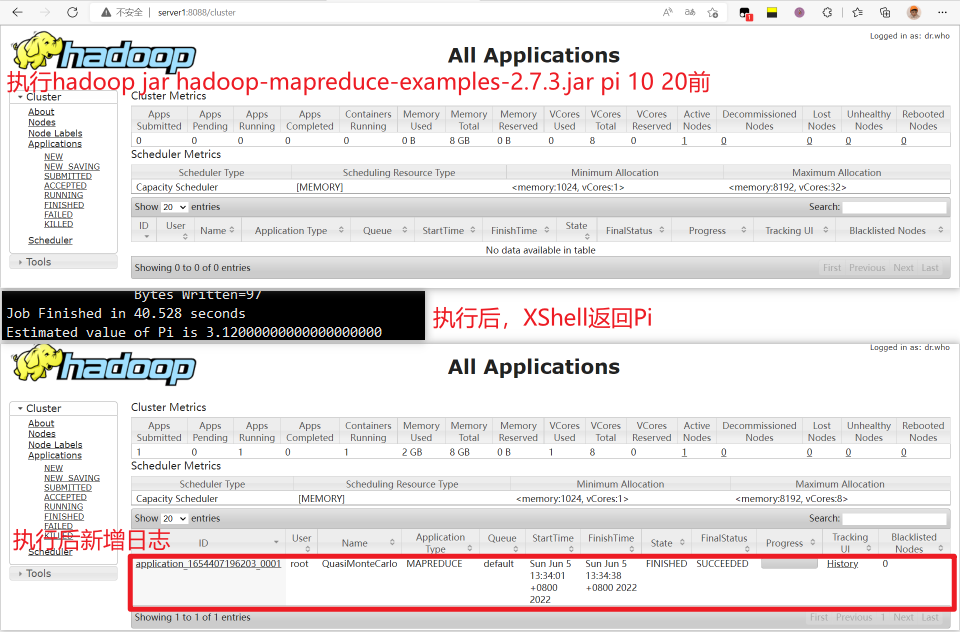
# 执行一个程序,以圆周率为例子,http://server1:8088中查看日志
cd $HADOOP_HOME
cd share/hadoop/mapreduce
hadoop jar hadoop-mapreduce-examples-2.7.3.jar pi 10 20 #返回圆周率
- 关闭集群
stop-yarn.sh,stop-dfs.sh或者一键关闭stop-all.sh
服务汇总
一、启动服务:
1.单独启动namenode:
sbin/hadoop-daemon.sh start namenode
2.单独启动datanode:
sbin/hadoop-daemon.sh start datanode
3.单独启动secondarynamenode
sbin/hadoop-daemon.sh start secondarynamenode
4.单独启动yarn的两个服务:
sbin/yarn-daemon.sh start resourcemanager
sbin/yarn-daemon.sh start nodemanager
启动hdfs(启动了namenode,secondarynamenode和datanode):start-dfs.sh
启动yarn(启动了resourcemanager和nodemanager):start-yarn.sh
一键启动所有的进程服务:start-all.sh
启动历史服务:mr-jobhistory-daemon.sh start historyserver
二、停止服务
1.单独停止yarn的两个服务:
sbin/yarn-daemon.sh stop resourcemanager
sbin/yarn-daemon.sh stop nodemanager
2.单独停止datanode:
sbin/hadoop-daemon.sh stop datanode
3.单独停止secondarynamenode
sbin/hadoop-daemon.sh stop secondarynamenode
4.单独停止namenode:
sbin/hadoop-daemon.sh stop namenode
停止yarn(停止了resourcemanager和nodemanager):stop-yarn.sh
停止hdfs(停止了namenode,secondarynamenode和datanode):stop-dfs.sh
一键停止所有的进程服务:stop-all.sh
停止历史服务:mr-jobhistory-daemon.sh stop historyserver