看了网上对url批量检测cdn的脚本没有多少也不准确,这里写一下
一般判断cdn的方法如下
全球ping
显示的ip地址超过一个则使用了cdn,这是最靠谱的方法
nslookup
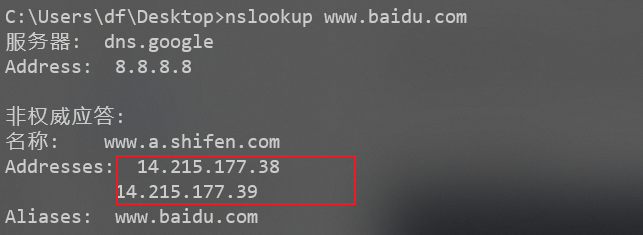
1. nslookup默认解析
使用 "nslookup 域名",如果目标有CDN服务的话,那么“非权威应答”中的“addresses”中的IP数 >=2个,但是也会有误报
2. 不同DNS域名解析
不同DNS域名解析情况对比,判断其是否使用了CDN。不同DNS解析结果若不一样,很有可能存在CDN服务
所以我们可以根据这两点来判断是否使用了cdn
批量检测脚本
如果引用全球ping的api接口进行检测,那检测效率会受限于服务器网速以及可能遇到被封ip的风险。这里使用nslookup进行多次检测,以确认是否使用cdn,准确率99%
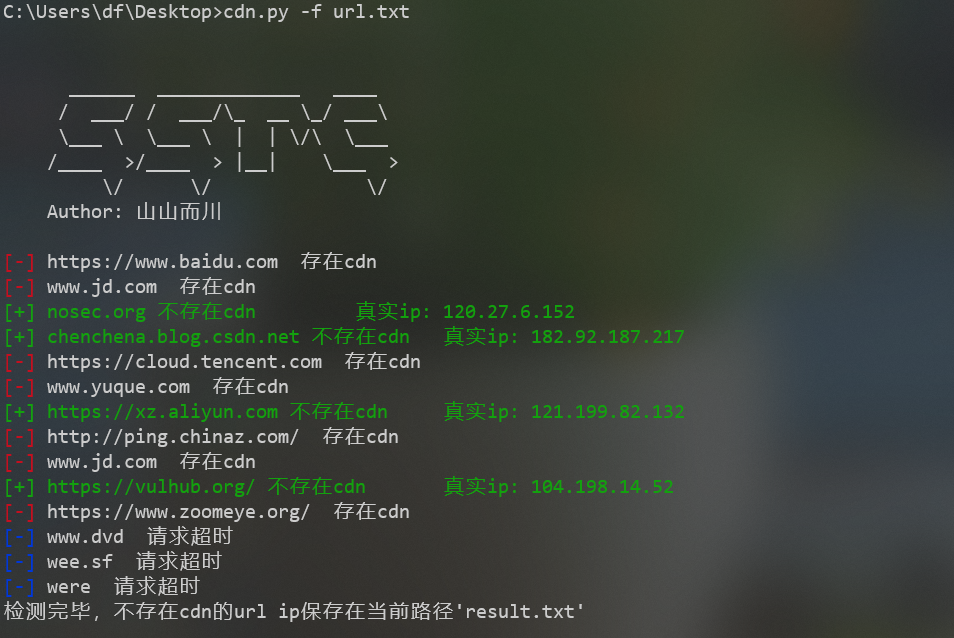
cdn.py
from subprocess import PIPE, Popen
import re
import os
from colorama import init,Fore
init(autoreset=True)
import argparse
def args():
parser = argparse.ArgumentParser(description='cdn批量检测脚本')
parser.add_argument('-f',type=str,help='批量检测,请将url放在txt文档中,一个一行')
args = parser.parse_args()
ssrc = """
______ _____________ ____
/ ___/ / ___/\_ __ \_/ ___\
\___ \ \___ \ | | \/\ \___
/____ >/____ > |__| \___ >
\/ \/ \/
Author: 山山而川
"""
print(ssrc)
if args.f:
filename = args.f
if os.path.exists(filename):
check_cdn(filename)
else:
print("输入的文件名不存在!")
def check_cdn(filename):
result_list = []
for url in open(filename,'r'):
url = url.replace("\n","")
ip = url.replace("http://","").replace("https://","").replace("/","").replace("\n","")
proc = Popen('nslookup %s' %(ip),stdin=None,stdout=PIPE,stderr=PIPE,shell=True)
outinfo, errinfo = proc.communicate()
info = outinfo.decode('gbk')
ip_list = re.findall(r"\d{1,3}.\d{1,3}.\d{1,3}.\d{1,3}",info,re.S)
if len(ip_list) >= 3:
print(Fore.RED+"[-]",url," 存在cdn")
continue
if len(ip_list) == 1:
print(Fore.BLUE+"[-]",url," 请求超时")
continue
if len(ip_list) == 2:
#二次判断,提高准确率
proc = Popen('nslookup %s 223.5.5.5' %(ip),stdin=None,stdout=PIPE,stderr=PIPE,shell=True)
outinfo, errinfo = proc.communicate()
info1 = outinfo.decode('gbk')
ip_list1 = re.findall(r"\d{1,3}.\d{1,3}.\d{1,3}.\d{1,3}",info1,re.S)
if len(ip_list1) >= 3:
print(Fore.RED+"[-]",url," 存在cdn")
continue
if len(ip_list1) ==2:
name1 = re.findall(r'名称:.*Address:.*?(\d{1,3}.\d{1,3}.\d{1,3}.\d{1,3})',info,re.S)[0]
name2 = re.findall(r'名称:.*Address:.*?(\d{1,3}.\d{1,3}.\d{1,3}.\d{1,3})',info1,re.S)[0]
if name1 != name2:
print(Fore.RED+"[-]",url," 存在cdn")
continue
if name1 == name2:
print(Fore.GREEN+"[+] %s 不存在cdn \t真实ip: %s" %(url,name2))
result_list.append(name2)
lis = list(set(result_list))
if len(lis):
for r in lis:
with open("result.txt",'a') as f:
f.write(r+"\n")
print("检测完毕,不存在cdn的url ip保存在当前路径'result.txt'")
if not len(lis):
print("检测完毕!")
if __name__ == '__main__':
args()