文章目录
西瓜书笔记
1. 基本流程
决策树学习的目的是为了产生一颗泛化能力强,即处理未见示例能力强的决策树,其基本流程遵循简单且直观的“分而治之”策略。
决策树的生成是一个递归过程。在决策树基本算法中,有三种情形会导致递归返回:(1)当前结点包含的样本全属于同一类别,无需划分;(2)当前属性集为空,或是所有样本在所有属性上取值相同,无法划分;(3)当前结点包含的样本集合为空,不能划分。
在第(2)中情况下,我们把当前结点标记为叶结点,并将其类别设定为该结点所含样本最多的类别,即在利用当前结点的后验分布;在第(3)种情况下,同样把当前结点标记为叶结点,但将其类别设定为其父结点所含样本最多的类别,即把父结点的样本分布作为当前结点的先验分布。
2. 划分选择
决策树学习的关键在于如何选择最优划分属性。一般而言,随着划分过程不断进行,我们希望决策树的分支结点所包含的样本尽可能属于同一类别,即结点的“纯度”越来越高。
2.1信息增益
“信息熵”是度量样本集合纯度最常用的一种指标。假定当前样本集合D中第k类样本所占的比例为 p k ( k = 1 , 2 , . . . , ∣ Y ∣ ) p_k(k=1,2,...,|\mathcal{Y}|) pk(k=1,2,...,∣Y∣),则D的信息熵定义为:
Ent ( D ) = − ∑ k = 1 ∣ Y ∣ p k log 2 p k \operatorname{Ent}(D)=-\sum_{k=1}^{|\mathcal{Y}|} p_{k} \log _{2} p_{k} Ent(D)=−k=1∑∣Y∣pklog2pk
Ent ( D ) \operatorname{Ent}(D) Ent(D)的值越小,则D的纯度越高。我们约定计算信息熵时,若p=0,则 p l o g 2 p = 0 plog_2p=0 plog2p=0. Ent ( D ) \operatorname{Ent}(D) Ent(D)的最小值为0,最大值为 log 2 ∣ Y ∣ \log _{2} |\mathcal{Y}| log2∣Y∣。

著名的ID3决策树(Iterative Dichotomiser迭代二分器)就是以信息增益为准则来选择划分属性的。
以西瓜数据集2.0为例
import pandas as pd
import numpy as np
from math import log
data=pd.read_csv(r"C:\Users\DELL\Desktop\西瓜数据集.csv")
data.head()
色泽 根蒂 敲声 纹理 脐部 触感 target
0 青绿 蜷缩 浊响 清晰 凹陷 硬滑 是
1 乌黑 蜷缩 沉闷 清晰 凹陷 硬滑 是
2 乌黑 蜷缩 浊响 清晰 凹陷 硬滑 是
3 青绿 蜷缩 沉闷 清晰 凹陷 硬滑 是
4 浅白 蜷缩 浊响 清晰 凹陷 硬滑 是
def calShanEnt(dataset,col):
tarset=set(dataset[col])
res=0
for i in tarset:
pi=np.sum(dataset[col] == i)/len(dataset)
res=res-pi* log(pi, 2)
return res
def ID3(dataset,fea):
baseEnt = calShanEnt(dataset, "target")
newEnt = 0
value_set=set(dataset[fea])
for v in value_set:
newEnt += np.sum(dataset[fea] == v) / len(dataset) * calShanEnt(dataset[dataset[fea] == v],"target")
return baseEnt-newEnt
ID3(data,"根蒂")
0.14267495956679288
可以看到,在给定西瓜"根蒂"条件的基础上,信息增益为0.142
使用信息增益进行分裂时我们的特征选择方法是:对训练集(或者子集)D,计算其每个特征的信息增益,并且比较大小,选择信息增益最大的特征。
方法也是很直接,既然给定每个特征都可以得到一个新增增益,那哪个特征的信息增益大,我们选择哪个特征不就好了?于是:
def chooseBestFea(dataset):
features=[i for i in dataset.columns if i!='target']
bestFet=features[0]
bestInfoGain=-1
for fea in features:
gain=ID3(dataset,fea)
if gain>bestInfoGain:
bestInfoGain=gain
bestFet=fea
print(set(dataset[bestFet]))
print(bestInfoGain)
return bestFet
chooseBestFea(data)
{
'清晰', '模糊', '稍糊'}
0.3805918973682686
'纹理'
可以看到,选择"纹理"进行分裂信息增益最大(0.38059189736826)。因此我们可以根据特征"纹理"将整个样本集分为三份,分别是"纹理=模糊",“纹理=清晰”,“纹理=稍糊”.
2.2增益率
信息增益准则对可取值数目较多的属性有所偏好,为减少这种偏好可能带来的不利影响,C4.5决策树算法使用“增益率”来选择最优划分属性。增益率定义为:
Gain ratio ( D , a ) = Gain ( D , a ) IV ( a ) \text { Gain ratio }(D, a)=\frac{\operatorname{Gain}(D, a)}{\operatorname{IV}(a)} Gain ratio (D,a)=IV(a)Gain(D,a)
其中有属性a的“固有值”:
IV ( a ) = − ∑ v = 1 V ∣ D v ∣ ∣ D ∣ log 2 ∣ D v ∣ ∣ D ∣ \operatorname{IV}(a)=-\sum_{v=1}^{V} \frac{\left|D^{v}\right|}{|D|} \log _{2} \frac{\left|D^{v}\right|}{|D|} IV(a)=−v=1∑V∣D∣∣Dv∣log2∣D∣∣Dv∣
属性a的可能取值数目越多(即V越大),则 I V ( a ) IV(a) IV(a)的值通常越大。
def C4_5(dataset,fea):
gain=ID3(dataset,fea)
IVa=calShanEnt(dataset,fea)
return gain/IVa
C4_5(data,"纹理")
0.2630853587192754
若我们直接选取增益率最大的候选划分属性,则有:
def chooseBestFea(dataset):
features=[i for i in dataset.columns if i!='target']
bestFet=features[0]
bestInfoGain=-1
for fea in features:
gain=C4_5(dataset,fea)
if gain>bestInfoGain:
bestInfoGain=gain
bestFet=fea
print(set(dataset[bestFet]))
print(bestInfoGain)
return bestFet
chooseBestFea(data)
{
'稍糊', '清晰', '模糊'}
0.2630853587192754
'纹理'
增益率准则对可取值数目较少的属性有所偏好,因此C4.5算法并不是直接选择增益率最大的候选划分属性,而是直接使用了一个启发式:先从候选划分属性中找出信息增益高于平均水平的属性,再从中选择增益率最高的。
2.3基尼指数
CART(Classification and Regression Tree)使用“基尼指数”来选择划分属性,数据集D的纯度可用基尼值来度量:
Gini ( D ) = ∑ k = 1 ∣ Y ∣ ∑ k ′ ≠ k p k p k ′ = 1 − ∑ k = 1 ∣ Y ∣ p k 2 \begin{aligned} \operatorname{Gini}(D) &=\sum_{k=1}^{|\mathcal{Y}|} \sum_{k^{\prime} \neq k} p_{k} p_{k^{\prime}} \\ &=1-\sum_{k=1}^{|\mathcal{Y}|} p_{k}^{2} \end{aligned} Gini(D)=k=1∑∣Y∣k′=k∑pkpk′=1−k=1∑∣Y∣pk2
G i n i ( D ) Gini(D) Gini(D)反映了从数据集D中随机抽取两个样本,其类别标签不一致的概率。因此, G i n i ( D ) Gini(D) Gini(D)越小,则数据集D的纯度越高。
属性a的基尼指数定义为:
G i n i _ i n d e x ( D , a ) = ∑ v = 1 V ∣ D v ∣ ∣ D ∣ Gini ( D v ) Gini\_index(D, a)=\sum_{v=1}^{V} \frac{\left|D^{v}\right|}{|D|} \operatorname{Gini}\left(D^{v}\right) Gini_index(D,a)=v=1∑V∣D∣∣Dv∣Gini(Dv)
于是,我们在候选属性集合A中,选择那个使得划分后基尼指数最小的属性作为最优划分属性,即 a ∗ = arg min a ∈ A G i n i _ i n d e x ( D , a ) a_{*}=\underset{a \in A}{\arg \min } Gini\_index(D, a) a∗=a∈AargminGini_index(D,a)。
def Gini(dataset,col):
tarset = set(dataset[col])
gini=1
for i in tarset:
gini=gini-(np.sum(dataset[col] == i)/len(dataset))**2
return gini
Gini(data,"target")
0.49826989619377154
def CART(dataset,fea):
value_set=set(dataset[fea])
gini = 0
for v in value_set:
gini += np.sum(dataset[fea] == v) / len(dataset) * Gini(dataset[dataset[fea] == v],"target")
return gini
CART(data,"纹理")
0.2771241830065359
在这里插入代码片
def chooseBestFea(dataset):
features=[i for i in dataset.columns if i!='target']
bestFet=features[0]
bestInfoGain=1000
for fea in features:
gain=CART(dataset,fea)
if gain<bestInfoGain:
bestInfoGain=gain
bestFet=fea
print(set(dataset[bestFet]))
print(bestInfoGain)
return bestFet
chooseBestFea(data)
{
'清晰', '模糊', '稍糊'}
0.2771241830065359
'纹理'
3.剪枝处理
剪枝是决策树学习算法对付“过拟合”的主要手段。在决策树学习中,为了尽可能正确分类训练样本,结点划分过程将不断重复,有时会造成决策树分支过多,这时就可能因训练样本学得“太好”了,以至于把训练集自身的一些特点当作所有数据都具有的一般性质而导致过拟合。因此可以通过主动去掉一些分支来降低过拟合的风险。
决策树剪枝的基本策略有“预剪枝”和“后剪枝”。预剪枝是指在决策树生成过程中,对每个结点在划分前进行估计,若当前结点的划分不能带来决策树泛化性能提升,则停止划分并将当前结点标记为叶结点;后剪枝则是先从训练集生成一颗完整的决策树,然后自底向上对非叶结点进行考察,若将该结点对应的子树替换为叶结点能带来决策树泛化性能提升,则将该子树替换为叶结点。
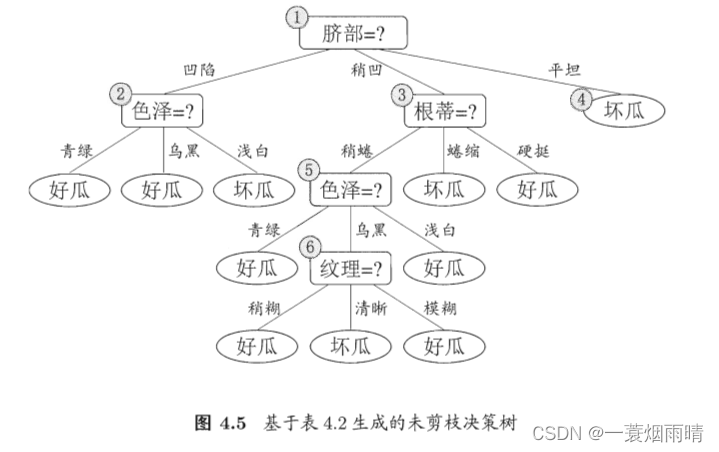
我们从西瓜数据集2.0中取一部分作为训练集采用信息增益准则来进行划分属性选择,即可生成如下的决策树:
3.1预剪枝
基于信息增益准则,我们会选取属性“脐部”来对训练集进行划分,并产生3个分支,如下图所示。是否应该进行这个划分呢?预剪枝要对划分前后的泛化性能进行估计。
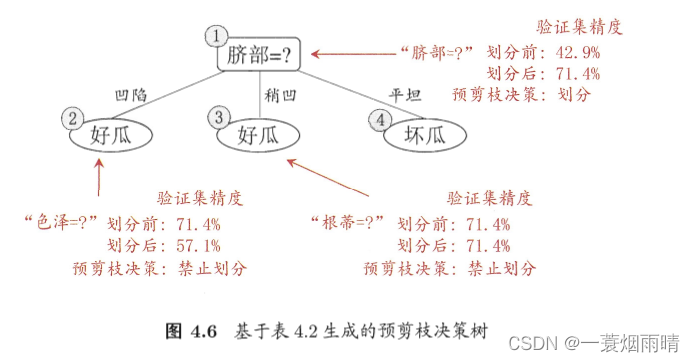
在划分之前,所有样例集中在根结点。若不进行划分。则该结点被标记为叶结点,其类别标记为训练样例数最多的类别,假设我们将这个叶结点标记为“好瓜”。用验证集对这个单结点决策树进行评估,则编号为{4,5,8}的样例被分类正确,另外4个样例分类错误,于是,验证集精度为3/4×100%=42.9%.
在用属性“脐部”划分之后,上图结点圈2、圈3、圈4分别包含编号为{1,2,3,14}、{6,7,15,17}、{10,16}的训练样例,因此这3个结点分别被标记为叶结点“好瓜”、“好瓜”、“坏瓜”。此时,验证集中编号为{4,5,8,11,12}的样例被分类正确,验证集精度为5/7×100%=71.4%>42.9%.于是“脐部”进行划分得以确定。
然后,决策树算法应该对结点圈2进行划分,基于信息增益准则将挑选出划分属性“色泽”。然而,在使用“色泽”划分后,编号为{5}的验证集样本分类结果会由正确转为错误,使得验证集精度下降为57.1%。于是预剪枝策略将禁止结点圈2被划分。
对结点圈3,最优划分属性为“根蒂”,划分后验证集精度仍为71.4%。这个划分不能提高验证集精度,于是,预剪枝策略禁止结点圈3被划分。
对结点圈4,其所含训练样例已属于同一类,不再进行划分。
于是,基于预剪枝策略得到上图的决策树,其验证集精度为71.4%。这是一颗仅有一层划分的决策树,亦称“决策树桩”。
可以观察到预剪枝使得决策树的很多分支都没有“展开”,这不仅降低了过拟合的风险,还显著减少了决策树的训练时间开销和测试时间开销。但另一方面,有些分支的当前划分虽不能提升泛化性能、甚至可能导致泛化性能暂时下降,但其基础上进行的后续划分却有可能导致性能显著提高;预剪枝基于“贪心”本质禁止这些分支展开,给预剪枝决策树带来了欠拟合的风险。
3.2 后剪枝
后剪枝先从训练集生成如下的完整决策树,该决策树的验证集精度为42.9%。
后剪枝首先考虑上图的结点圈6。若将其领衔的分支剪除,则相当于把圈6替换为叶结点。替换后的叶结点包含编号为{7,15}的训练样本,于是,该叶结点的类别标记为“好瓜”,此时决策树的验证集精度提高至57.1%。于是,后剪枝策略决定剪枝。
然后考虑结点圈5,若将其领衔的子树替换为叶结点,则替换后的叶结点包含编号为{6,7,15}的训练样例,叶结点类别标记为“好瓜”,此时决策树验证集精度仍为57.1%。于是,可以不进行剪枝。
对于结点圈2,若将其领衔的子树替换为叶结点,则替换后的叶结点包含编号为{1,2,3,14}的训练样例,叶结点标记为“好瓜”。此时决策树的验证集精度提高至71.4%。于是,后剪枝策略决定剪枝。
对结点圈3和圈1,若将其领衔的子树替换为叶结点,则所得决策树的验证集精度分别为71.4%与42.9%,均未得到提高,于是它们被保留。
最终基于后剪枝策略生成的决策树如下图所示,其验证集精度为71.4%。
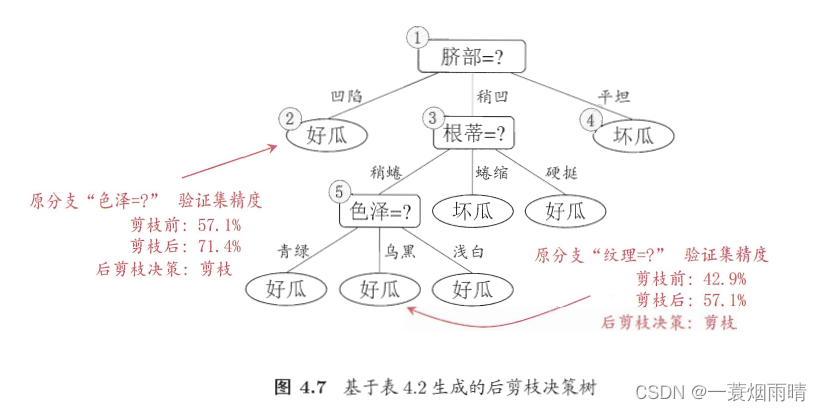
后剪枝决策树通常比预剪枝决策树保留了更多的分支。一般情况下,侯建志决策树的欠拟合风险很小,泛化性能往往优于预剪枝决策树。但后剪枝过程是在生成完全决策树之后进行的,并且要自底向上地对树中的所有非叶结点进行逐一考察,因此其训练时间开销比未剪枝决策树和预剪枝决策树都要大得多。
4. 连续与缺失值
4.1 连续值处理
由于连续属性的可取值数目不再有限,因此,不能直接根据连续属性的可取值来对结点进行划分,此时连续属性离散化技术可派上用场。最简单的策略是采用二分法对连续属性进行处理,正是C4.5决策树算法中采用的机制。

与离散属性不同,若当前结点划分属性为连续属性,该属性还可作为其后代结点的划分属性。
4.2 缺失值处理
现实任务中常会遇到不完整样本,即样本的某些属性值缺失。
我们需解决两个问题:(1)如何在属性值缺失的情况下进行划分属性选择?(2)给定划分属性,若样本在该属性上的值缺失,如何对样本进行划分?


C4.5算法使用了上述的解决方案。
5. 多变量决策树
若我们把每个属性视为坐标空间中的一个坐标轴,则d个属性描述的样本就对应了d维空间中的一个数据点,对样本分类意味着在这个坐标空间中寻找不同类样本之间的分类边界。决策树所形成的分类边界有一个明显的特点:轴平行,即它的分类边界由若干个与坐标轴平行的分段组成。
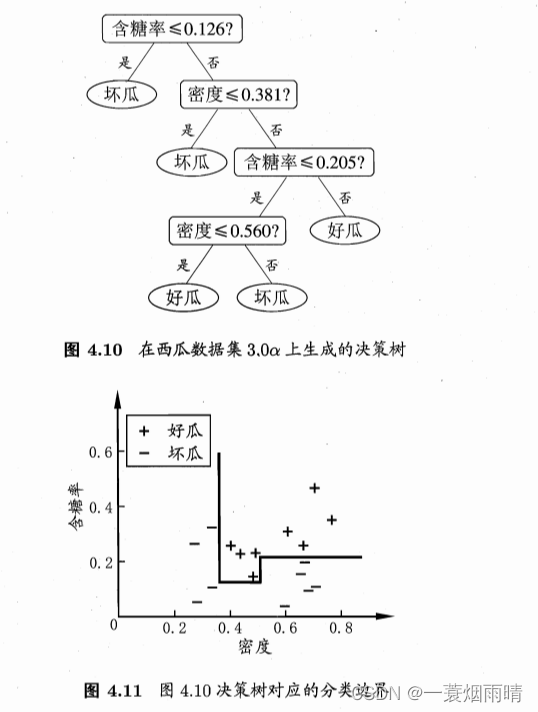
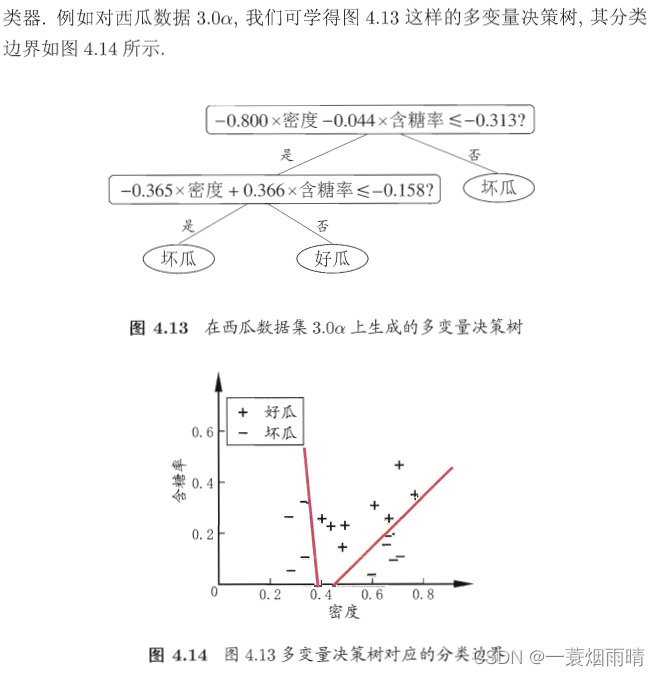
若能使用斜的划分边界,则决策树模型将大为简化。“多变量决策树”就是能实现这样的“斜划分”甚至更复杂划分的决策树。以实现斜划分的多变量决策树为例,在此类决策树中,非叶结点不再是仅对某个属性,而是对属性的线性组合进行测试。

代码实现
三种算法实现
ID3同原文,C4_5直接选取增益率最大的候选划分属性,CART使用Gini指数指导分裂只用于分裂二叉树,与上面的两个方法相比,Gini指数进行分裂不仅要选择特征,而且要选择特征值。来自和鲸社区。
### 使用三种方法建立一个决策树
import pandas as pd
from math import log
import numpy as np
class DT:
def __init__(self, data, model):
self.data = data
self.model = model
def calShanEnt(self, dataset, col):
tarset = set(dataset[col])
res = 0
for i in tarset:
pi = np.sum(dataset[col] == i) / len(dataset)
res = res - pi * log(pi, 2)
return res
def ID3(self, dataset, fea):
baseEnt = self.calShanEnt(dataset, "target")
newEnt = 0
value_set = set(dataset[fea])
for v in value_set:
newEnt += np.sum(dataset[fea] == v) / len(dataset) * self.calShanEnt(dataset[dataset[fea] == v], "target")
return baseEnt - newEnt
def C4_5(self, dataset, fea):
gain = self.ID3(dataset, fea)
IVa = self.calShanEnt(dataset, fea)
return gain / IVa
def Gini(self, dataset, col):
tarset = set(dataset[col])
gini = 1
for i in tarset:
gini = gini - (np.sum(dataset[col] == i) / len(dataset)) ** 2
return gini
def CART(self, dataset, fea):
value_set = set(dataset[fea])
Gini_min = 100
fea_min = ""
for v in value_set:
Gini_index = np.sum(dataset[fea] == v) / len(dataset) * self.Gini(dataset[dataset[fea] == v], "target") + \
np.sum(dataset[fea] != v) / len(dataset) * self.Gini(dataset[dataset[fea] != v], "target")
if Gini_index < Gini_min: # 越小越好
Gini_min = Gini_index
fea_min = v
return -Gini_min, fea_min ##由于另外连个方法都是最大的值进行分裂,而Gini指数是最小,因此取负数,这样-Gini_min越大越好
def chooseBestFea(self, dataset):
features = [i for i in dataset.columns if i != 'target']
bestFet = features[0]
bestFetFea = ""
bestInfoGain = -1
value_fea = ""
for fea in features:
if self.model == "C4_5":
gain = self.C4_5(dataset, fea)
elif self.model == "ID3":
gain = self.ID3(dataset, fea)
elif self.model == "CART":
gain, value_fea = self.CART(dataset, fea)
else:
raise ("输入的model值之只能是:C4_5,ID3,CART,但是实际输入的值为:", self.model)
if gain > bestInfoGain:
bestInfoGain = gain
bestFet = fea
bestFetFea = value_fea
return bestFet, bestFetFea
def creatTree(self, dataset):
if len(dataset.columns) == 1:
return dataset['target'].value_counts().index[0]
if len(set(dataset['target'])) == 1:
return list(dataset['target'])[0]
bestFea, bestFetFea = self.chooseBestFea(dataset)
myTree = {
bestFea: {
}}
if bestFetFea == "":
for i in set(dataset[bestFea]):
new_data = dataset[dataset[bestFea] == i].reset_index(drop=True) # drop=True 就是把原来的索引index列去掉,重置index
myTree[bestFea][i] = self.creatTree(new_data)
else:
new_data = dataset[dataset[bestFea] == bestFetFea].reset_index(drop=True)
myTree[bestFea][bestFetFea] = self.creatTree(new_data)
new_data2 = dataset[dataset[bestFea] != bestFetFea].reset_index(drop=True)
myTree[bestFea]["不等于" + bestFetFea] = self.creatTree(new_data2)
return myTree
data_path=r"C:\Users\DELL\Desktop"
data = pd.read_csv(r"C:\Users\DELL\Desktop\西瓜数据集.csv")
model = DT(data, "CART")
tree=model.creatTree(data)
{
'纹理': {
'清晰': {
'触感': {
'软粘': {
'色泽': {
'乌黑': '否',
'不等于乌黑': {
'根蒂': {
'稍蜷': '是', '不等于稍蜷': '否'}}}},
'不等于软粘': '是'}},
'不等于清晰': {
'色泽': {
'乌黑': {
'敲声': {
'沉闷': '否', '不等于沉闷': '是'}}, '不等于乌黑': '否'}}}}
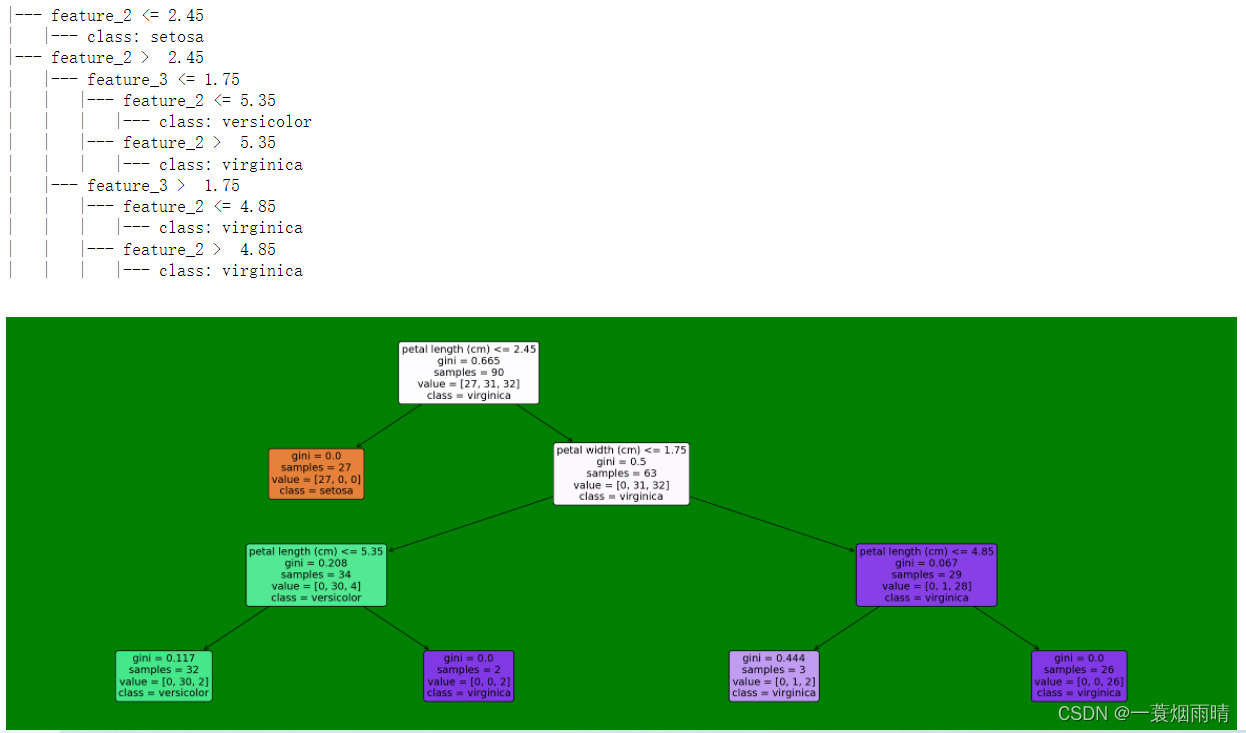
鸢尾花(iris)数据集sklearn决策树
# 加载数据集
data = load_iris()
# 转换成.DataFrame形式
df = pd.DataFrame(data.data, columns = data.feature_names)
# 添加品种列
df['Species'] = data.target
# 用数值替代品种名作为标签
target = np.unique(data.target)
target_names = np.unique(data.target_names)
targets = dict(zip(target, target_names))
df['Species'] = df['Species'].replace(targets)
# 提取数据和标签
X = df.drop(columns="Species")
y = df["Species"]
feature_names = X.columns
labels = y.unique()
X_train, test_x, y_train, test_lab = train_test_split(X,y,
test_size = 0.4,
random_state = 42)
model = DecisionTreeClassifier(max_depth =3, random_state = 42)
model.fit(X_train, y_train)
# 以文字形式输出树
text_representation = tree.export_text(model)
print(text_representation)
# 用图片画出
plt.figure(figsize=(30,10), facecolor ='g') #
a = tree.plot_tree(model,
feature_names = feature_names,
class_names = labels,
rounded = True,
filled = True,
fontsize=14)
plt.show()