1 列式存储与行式存储对比
-
采用行式存储时,数据在磁盘上的组织结构为:

-
行式存储
好处是想查某个人所有的属性时,可以通过一次磁盘查找加顺序读取就可以。但是当想查所有人的年龄时,需要不停的查找,或者全表扫描才行,遍历的很多数据都是不需要的。
-
采用列式存储时,数据在磁盘上的组织结构为:

-
列式存储
-
这时想查所有人的年龄只需把年龄那一列拿出来就可以了
-
对于列的聚合,计数,求和等统计操作原因优于行式存储。
-
由于某一列的数据类型都是相同的,针对于数据存储更容易进行数据压缩,每一列选择更优的数据压缩算法,大大提高了数据的压缩比重。
-
由于数据压缩比更好,一方面节省了磁盘空间,另一方面对于 cache 也有了更大的发挥空间。
2 数据类型-典型的cpp
-
整型:int8/int16/int32/int64 uint8/uint16/uint32/uint64
-
浮点型:float32 float64
-
decimal型:Decimal32(s)->Decimal(9-s,s) Decimal64(s)->Decimal(18-s,s) Decimal128(s)-Decimal(38-s,s)
-
字符串:String FixedString(N)固定长度
-
枚举型:Enum8 用 'String'= Int8 对描述 Enum16 用 'String'= Int16 对描述
-
日期类型:date-2个字节 datetime datetime64
-
数组类型:Array
3表引擎
3.1 TinyLog
-
以列文件的形式保存在磁盘上,不支持索引,没有并发控制
3.2 Memory
-
内存引擎,数据以未压缩的原始形式直接保存在内存当中,服务器重启数据就会消失
3.3 MergeTree:ClickHouse 中最强大的表引擎当属 MergeTree(合并树)引擎

create table t_order_mt( id UInt32, sku_id String, total_amount Decimal(16,2), create_time Datetime ) engine =MergeTree partition by toYYYYMMDD(create_time) primary key (id) order by (id,sku_id);
1) partition by 分区(可选)
-
分区目录:MergeTree 是以列文件+索引文件+表定义文件组成的,但是如果设定了分区那么这些文件就会保存到不同的分区目录中
-
分区并行计算:
-
数据写入与分区合并:任何一个批次的数据写入都会产生一个临时分区,不会纳入任何一个已有的分区。手动合并optimize table xxxx final;
2) primary key 主键(可选)
-
只提供了数据的一级索引,但是却不是唯一约束。这就意味着是可以存在相同 primary key 的数据的。
-
index granularity: 直接翻译的话就是索引粒度,指在稀疏索引中两个相邻索引对应数据的间隔。一般不修改
3) order by(必选)
-
分区内排序
-
不设置主键的情况,很多处理会依照 order by 的字段进行处理
-
主键必须是 order by 字段的前缀字段。(id,sku_id) 那么主键必须是 id 或者(id,sku_id)
4)二级索引

create table t_order_mt2( id UInt32, , Decimal(16,2), Datetime, INDEX a total_amount TYPE minmax GRANULARITY 5 ) engine =MergeTree partition by toYYYYMMDD() primary key (id) order by (id, sku_id); --GRANULARITY N 是设定二级索引对于一级索引粒度的粒度
5)TTL
-
列级:
create table t_order_mt3( id UInt32, , Decimal(16,2) TTL create_time+interval 10 SECOND, Datetime ) engine =MergeTree partition by toYYYYMMDD() primary key (id) order by (id, sku_id);
-
表级
alter table t_order_mt3 MODIFY TTL create_time + INTERVAL 10 SECOND; -- 涉及判断的字段必须是 Date 或者 Datetime 类型,推荐使用分区的日期字段。
3.4 ReplacingMergeTree - 去重
1) 去重时机
-
数据的去重只会在合并的过程中出现。合并会在未知的时间在后台进行,所以你无法预先作出计划。有一些数据可能仍未被处理。
2) 去重范围
-
如果表经过了分区,去重只会在分区内部进行去重,不能执行跨分区的去重
create table t_order_rmt( id UInt32, , Decimal(16,2) , Datetime ) engine =ReplacingMergeTree() partition by toYYYYMMDD() primary key (id) order by (id, sku_id);
3)ReplacingMergeTree()
-
填入的参数为版本字段,重复数据保留版本字段值最大的。如果不填版本字段,默认按照插入顺序保留最后一条。
3.5 SummingMergeTree - 预聚合
-
以 SummingMergeTree()中指定的列作为汇总数据列
-
可以填写多列必须数字列,如果不填,以所有非维度列且为数字列的字段为汇总数据列
-
以 order by 的列为准,作为维度列
-
其他的列按插入顺序保留第一行
-
不在一个分区的数据不会被聚合
-
只有在同一批次插入(新版本)或分片合并时才会进行聚合
4 sql
1)Update 和 Delete
-
虽然可以实现修改和删除,但是和一般的 OLTP 数据库不一样,Mutation 语句是一种很“重”的操作,而且不支持事务。“重”的原因主要是每次修改或者删除都会导致放弃目标数据的原有分区,重建新分区。所以尽量做批量的变更,不要进行频繁小数据的操作。
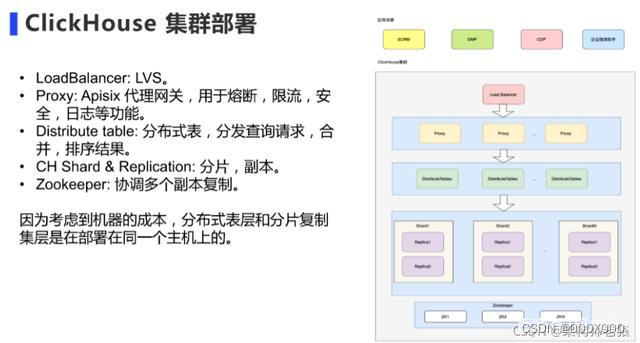
5 分片与副本集群
ClickHouse 的集群是表级别的,实际企业中,大部分做了高可用,但是没有用分片,避免降低查询性能以及操作集群的复杂性。
5.1 高可用集群
clickhouse高可用
-
每个节点/etc/clickhouse-server/ config.xml
<yandex> <zookeeper-servers> <node index="1"> <host>hadoop01</host> <port>2181</port> </node> <node index="2"> <host>hadoop02</host> <node index="3"> <host>hadoop03</host> </zookeeper-servers> </yandex>
-
创建表设置分片与副本
create table t_order_rep2 (
id UInt32,
,
Decimal(16,2),
Datetime
) engine =ReplicatedMergeTree('/clickhouse/table/01/t_order_rep','rep_01')
partition by toYYYYMMDD()
primary key (id)
order by (id,sku_id);
-
ReplicatedMergeTree 中,第一个参数是分片的 zk_path 一般按照: /clickhouse/table/{shard}/{table_name} 的格式写,如果只有一个分片就写 01 即可
-
第二个参数是副本名称,相同的分片副本名称不能相同
5.2 带有路由高可用集群
-
配置每个节点/etc/clickhouse-server/config.xml
<?xml version="1.0"?> <remote_servers> <ck_cluster> <!-- 集群名称--> <shard> <!--集群的第一个分片--> <internal_replication>true</internal_replication> <replica> <!--该分片的第一个副本--> <host>hadoop102</host> <port>9000</port> </replica> <replica> <!--该分片的第二个副本--> <host>hadoop103</host> </shard> <shard> <!--集群的第二个分片--> <internal_replication>true</internal_replication> <replica> <!--该分片的第一个副本--> <host>hadoop104</host> <port>9000</port> </replica> </ck_cluster> </remote_servers> <node index=> <host>hadoop102</host> <port>2181</port> </node> <node index=> <host>hadoop103</host> <port>2181</port> <node index=> <macros> <shard>01</shard> <!--不同机器放的分片数不一样--> <replica>rep_1_1</replica> <!--不同机器放的副本数不一样--> </macros>
-
分片和副本名称从配置文件的宏定义中获取
create table st_order_mt on cluster gmall_cluster (
id UInt32,
,
Decimal(16,2),
Datetime
) engine
= ReplicatedMergeTree('/clickhouse/tables/{shard}/st_order_mt','{replica}')
partition by toYYYYMMDD()
primary key (id)
order by (id,sku_id);
-
Distributed类mysql之mycat
create table st_order_mt_all2 on cluster ck_cluster ( id UInt32, , Decimal(16,2), Datetime ) engine = Distributed(ck_cluster,default, st_order_mt,hiveHash(sku_id));
-
Distributed(集群名称,库名,本地表名,分片键)
-
分片键必须是整型数字,所以用 hiveHash 函数转换,也可以 rand()
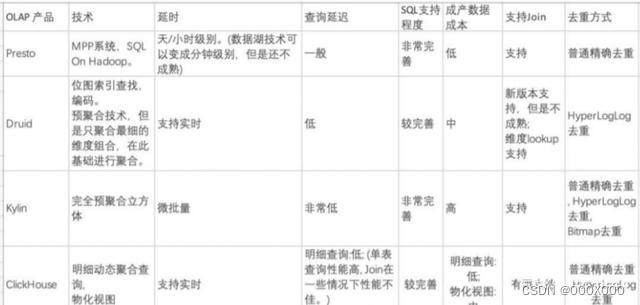
6 OLAP技术演进与选型
主流OLAP引擎对比
6.1 ClickHouse优点
-
灵活,支持明细数据SQL查询,并用物化视图加速。
-
多核(垂直扩展),可以在一台机器上使用多线程去进行查询;分布式处理,它有不同的分片,这样的话可以进行水平扩展,MPP架构。
-
支持实时批量数据摄入。
-
列式存储、向量化引擎、代码编译生成。向量化引擎和代码编译生成基本是为了解决算子瓶颈,如果不通过这些技术的话一般是个火山模型,火山模型会有一些虚函数以及分支判断之间的一些开销。通过这两种方法,向量化可以去平摊开销,代码编译可以把它转成以数据为中心进而消除开销。但是这两种方法也不是万能的,比如说当Aggregation或者Join数据量比较大时候需要物化到内存,物化到内存的时候瓶颈也就产生了,因此也不会有非常大的性能争议。
-
主键索引,ClickHouse会按照用户设置的主键进行排序,ClickHouse中MergeTree的文件就是按照这个逐渐进行排序的,Bloom Filter、minmax等做了二级索引。
6.2 ClickHouse缺点
-
没有高速,低延迟的更新和删除方法。不擅长单行数据,行级别数据的更新删除方法一般都是异步进行。
-
稀疏索引使得点查性能不佳。点查没办法用ClickHouse,最好的是用KV类型的Redis或者HBASE。
-
不支持事务。尽管事务现在对OLAP也会有一些用途,但是不是非常大的用途。
6.3 ClickHouse的应用场景:
-
用户行为分析,精细化运营分析:日活、留存率分析、路径分析、有序漏斗转化率分析、Session分析等。
-
实时日志分析,监控分析,实时数仓。