查看系统配置
查看系统表
select * from system.clusters;
验证zookeeper
#验证zookeeper是否与当前数据库clickhouse进行了正确的配置
SELECT * FROM system.zookeeper WHERE path = '/clickhouse';
建表
创建本地表
MergeTree,这个引擎本身不具备同步副本的功能,如果指定的是ReplicaMergeTree,会同步到对应的replica上面去。一般在实际应用中,创建分布式表指定的都是Replica的表。
分布式表本身不存储数据,数据存储其实还是由本地表t_cluster完成的。这个dist_t_cluster仅仅做一个代理的作用。
如果在任意节点创建表以后,其他节点都能同步到表结构,说明集群生效。
使用 ReplacingMergeTree
CREATE TABLE default.test ON CLUSTER clickhouse_cluster
(
name String DEFAULT 'lemonNan' COMMENT '姓名',
age int DEFAULT 18 COMMENT '年龄',
gongzhonghao String DEFAULT 'lemonCode' COMMENT '公众号',
my_time DateTime64(3, 'UTC') COMMENT '时间'
) ENGINE = ReplacingMergeTree()
PARTITION BY toYYYYMM(my_time)
ORDER BY my_time使用 MergeTree
CREATE TABLE t_cluster ON CLUSTER clickhouse_cluster (
id Int16,
name String,
birth Date
)ENGINE = MergeTree()
PARTITION BY toYYYYMM(birth)
ORDER BY idclickhouse 什么时候用ReplacingMergeTree引擎? 什么时候用 MergeTree 引擎?
ReplacingMergeTree 引擎和 MergeTree 引擎都是 ClickHouse 中常用的引擎类型,但它们适用场景略有不同。
ReplacingMergeTree 引擎适用于需要在数据更新时保留历史数据的场景。该引擎在进行数据插入时,会检测新数据是否与已有的数据冲突,如果冲突,则会用新数据替换旧数据,并记录旧数据的删除时间。这样就可以在查询时保留历史数据,并且支持撤销和恢复历史数据。
MergeTree 引擎适用于大多数常规的 OLAP 场景。该引擎可以对数据进行快速的排序和压缩,并支持按照某一列或多列进行分区,从而实现快速的查询和聚合。MergeTree 引擎比较适合处理大量的数据和高并发的查询请求。
因此,如果需要在数据更新时保留历史数据,可以使用 ReplacingMergeTree 引擎;如果只需要进行常规的 OLAP 查询,可以使用 MergeTree 引擎。
ClickHouse 用什么依据判断新数据是否与已有的数据冲突?
ClickHouse 在使用 ReplacingMergeTree 引擎时,会根据表中指定的主键来判断新数据是否与已有数据冲突。具体来说,ClickHouse 会根据主键值进行匹配,如果新数据中的主键值与已有数据中的主键值相同,则认为两条数据冲突。
在没有指定主键的情况下,ClickHouse 会使用所有列作为合并键,将新数据和已有数据进行比较。如果所有列的值都相同,则认为两条数据冲突。
在判断数据冲突时,ClickHouse 包括了对数据类型和大小写的严格比较,因此需要注意数据的精度和格式。同时,ClickHouse 还支持自定义函数来进行特定条件下的判断,以满足更加灵活的业务需求。
例如如下是指定name字段为主键
CREATE TABLE default.test88 ON CLUSTER clickhouse_cluster
(
name String NOT NULL COMMENT '姓名',
age int DEFAULT 18 COMMENT '年龄',
gongzhonghao String DEFAULT 'lemonCode' COMMENT '公众号',
my_time DateTime64(3, 'UTC') COMMENT '时间',
PRIMARY KEY (name)
) ENGINE = ReplacingMergeTree()
PARTITION BY toYYYYMM(my_time)
ORDER BY name创建分布式表
CREATE TABLE default.dist_t_cluster
ON CLUSTER clickhouse_cluster as t_cluster
engine = Distributed(clickhouse_cluster, default, t_cluster, rand());插入测试数据
多插入几条,在任意节点上查看分布式表,都能够看到数据。
insert into dist_t_cluster values(1, 'aaa', '2021-02-01'), (2, 'bbb', '2021-02-02');分布式表引擎的创建模板:
Distributed(clusterName, databaseName, tableName[, sharding_key])
1、集群标识符(clusterName)
注意不是复制表宏中的标识符,而是<remote_servers>中指定的那个。
2、本地表所在的数据库名称(databaseName)
3、本地表名称(tableName)
4、(可选的)分片键(sharding key)
该键与config.xml中配置的分片权重(weight)一同决定写入分布式表时的路由,即数据最终落到哪个物理表上。它可以是表中一列的原始数据(如site_id),也可以是函数调用的结果,如上面的SQL语句采用了随机值rand()。注意该键要尽量保证数据均匀分布,另外一个常用的操作是采用区分度较高的列的哈希值,如intHash64(user_id)。
分布式DDL
在ClickHouse中创建表、删表等DDL操作是一件麻烦的事,需要登录集群中的每一个节点去执行DDL语句,怎么简化这个操作呢?
ClickHouse(即CH)支持集群模式。 可以在DDL语句上附加ON CLUSTER <cluster_name>的语法,使得该DDL语句执行一次即可在集群中所有实例上都执行,简单方便。
一个集群拥有1到多个节点。
CREATE、ALTER、DROP、RENAME、TRUNCATE这些DDL语句,都支持分布式执行
【即如果在集群中的任意一个节点上执行DDL语句,那么集群中的每个节点都会以相同的顺序执行相同的语句,
这样就省去了需要依次去单个节点执行DDL的烦恼】
来源:clickhouse 基于集群实现分布式DDL的使用示例及坑_clickhouse insert on cluster_java编程艺术的博客-CSDN博客
分区partition
表中的数据可以按照指定的字段分区存储,每个分区在文件系统中都是都以目录的形式存在。常用时间字段作为分区字段,数据量大的表可以按照小时分区,数据量小的表可以在按照天分区或者月分区,查询时,使用分区字段作为Where条件,可以有效的过滤掉大量非结果集数据。
根据某个字段分区
create table partition_table_test(
id UInt32,
name String,
city String
) engine = MergeTree()
order by id
partition by city;根据时间分区
CREATE TABLE default.test ON CLUSTER clickhouse_cluster
(
name String DEFAULT 'lemonNan' COMMENT '姓名',
age int DEFAULT 18 COMMENT '年龄',
gongzhonghao String DEFAULT 'lemonCode' COMMENT '公众号',
my_time DateTime64(3, 'UTC') COMMENT '时间'
) ENGINE = ReplacingMergeTree()
PARTITION BY toYYYYMM(my_time)
ORDER BY my_time#查询partition相关信息
select database, table, partition, partition_id, name, path from system.parts where database = 'data_sync' and table = 'test';#删除partition
alter table data_sync.test drop partition '202203'来源:Clickhouse数据表、数据分区partition的基本操作_clickhouse drop partition_Bulut0907的博客-CSDN博客
ClickHouse与Kafak同步
同步流程图
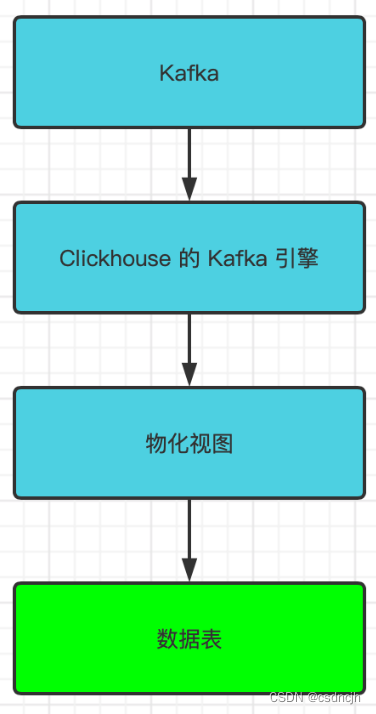
数据表
# 创建数据表
CREATE DATABASE IF NOT EXISTS data_sync;CREATE TABLE IF NOT EXISTS data_sync.test
(
name String DEFAULT 'lemonNan' COMMENT '姓名',
age int DEFAULT 18 COMMENT '年龄',
gongzhonghao String DEFAULT 'lemonCode' COMMENT '公众号',
my_time DateTime64(3, 'UTC') COMMENT '时间'
) ENGINE = ReplacingMergeTree()
PARTITION BY toYYYYMM(my_time)
ORDER BY my_time引擎表
# 创建 kafka 引擎表, 地址: 172.16.16.4, topic: lemonCode
CREATE TABLE IF NOT EXISTS data_sync.test_queue(
name String,
age int,
gongzhonghao String,
my_time DateTime64(3, 'UTC')
) ENGINE = Kafka
SETTINGS
kafka_broker_list = '172.16.16.4:9092',
kafka_topic_list = 'lemonCode',
kafka_group_name = 'lemonNan',
kafka_format = 'JSONEachRow',
kafka_row_delimiter = '\n',
kafka_schema = '',
kafka_num_consumers = 1注意:setting中还有两个重要参数
订阅Kafka数据的参数kafka_thread_per_consumer和kafka_num_consumers都与消费者线程的数量相关。具体作用如下:
-
kafka_thread_per_consumer参数:该参数表示每个Kafka消费者的线程数量。默认值为1,即每个消费者使用一个线程。如果需要提高消费速度,可以增加该参数的值以增加消费者线程数量。 -
kafka_num_consumers参数:该参数表示创建的Kafka消费者数量。默认值为1,即只创建一个消费者。如果需要提高消费速度,可以增加该参数的值以增加消费者数量。
需要注意的是,增加消费者线程的数量和消费者数量可能会提高消费速度,但也会增加ClickHouse服务器的负载。因此,在设置这些参数时需要根据实际情况进行权衡。同时,还需要根据Kafka的分区数量、数据量大小等因素进行适量的调整。
物化视图
# 创建物化视图
CREATE MATERIALIZED VIEW IF NOT EXISTS data_sync.test_mv TO data_sync.test AS
SELECT name, age, gongzhonghao, my_time FROM data_sync.test_queue;kafka订阅思路
1.可以将kafka数据发送到分布式表中,发挥集群存储的优势。
创建本地表:
CREATE TABLE data_sync.test ON CLUSTER clickhouse_cluster
(
name String NOT NULL COMMENT '姓名',
age int DEFAULT 18 COMMENT '年龄',
gongzhonghao String DEFAULT 'lemonCode' COMMENT '公众号',
my_time DateTime64(3, 'UTC') COMMENT '时间',
) ENGINE = ReplacingMergeTree()
PARTITION BY toYYYYMM(my_time)
ORDER BY name
创建分布式表:
CREATE TABLE data_sync.test_dist
ON CLUSTER clickhouse_cluster as test
engine = Distributed(clickhouse_cluster, data_sync, test, rand());创建引擎表:
CREATE TABLE IF NOT EXISTS data_sync.test_queue(
name String,
age int,
gongzhonghao String,
my_time DateTime64(3, 'UTC')
) ENGINE = Kafka
SETTINGS
kafka_broker_list = '172.16.16.4:9092',
kafka_topic_list = 'lemonCode',
kafka_group_name = 'lemonNan',
kafka_format = 'JSONEachRow',
kafka_row_delimiter = '\n',
kafka_schema = '',
kafka_num_consumers = 1物化视图:
注意其中的目标表指定到分布式表中。
CREATE MATERIALIZED VIEW IF NOT EXISTS data_sync.test_mv TO data_sync.test_dist AS
SELECT name, age, gongzhonghao, my_time FROM data_sync.test_queue;2.可以在多个节点创建引擎表和物化视图,多个节点同时接入kafka数据。
数据模拟
下面是开始模拟流程图的数据走向,已安装 Kafka 的可以跳过安装步骤。
安装 kafka
kafka 这里为了演示安装的是单机
# 启动 zookeeper
docker run -d --name zookeeper -p 2181:2181 wurstmeister/zookeeper
# 启动 kafka, KAFKA_ADVERTISED_LISTENERS 后的 ip地址为机器ip
docker run -d --name kafka -p 9092:9092 -e KAFKA_BROKER_ID=0 -e KAFKA_ZOOKEEPER_CONNECT=zookeeper:2181 --link zookeeper -e KAFKA_ADVERTISED_LISTENERS=PLAINTEXT://172.16.16.4:9092 -e KAFKA_LISTENERS=PLAINTEXT://0.0.0.0:9092 -t wurstmeister/kafka
使用kafka命令发送数据
# 启动生产者,向 topic lemonCode 发送消息
kafka-console-producer.sh --bootstrap-server 172.16.16.4:9092 --topic lemonCode
# 发送以下消息
{"name":"lemonNan","age":20,"gongzhonghao":"lemonCode","my_time":"2022-03-06 18:00:00.001"}
{"name":"lemonNan","age":20,"gongzhonghao":"lemonCode","my_time":"2022-03-06 18:00:00.001"}
{"name":"lemonNan","age":20,"gongzhonghao":"lemonCode","my_time":"2022-03-06 18:00:00.002"}
{"name":"lemonNan","age":20,"gongzhonghao":"lemonCode","my_time":"2022-03-06 23;59:59.002"}
查看 Clickhouse 的数据表
select * from data_sync.test;来源:
https://www.cnblogs.com/wuhaonan/p/15978470.html
其他命令
如果需要修改表结构或者其他目标表的调整,可以先停止数据订阅,更改好了以后再开始订阅。
注意如果多节点都有引擎表,每个节点都要执行。
#停止订阅
DETACH TABLE data_sync.test_queue;
#开始订阅
ATTACH TABLE data_sync.test_queue;
删除视图:
drop view data_sync.test_mv;