一、准备工作:
1.机器准备:
我们准备了6台机器用来部署clickhouse,准备搭建一个3分片2副本集群,当然也可根据你自己实际情况选择机器数量。
2.在每台机器上安装clickhouse:
依次执行以下命令(来源于官网文档):
sudo yum install yum-utils
sudo rpm --import https://repo.clickhouse.tech/CLICKHOUSE-KEY.GPG
sudo yum-config-manager --add-repo https://repo.clickhouse.tech/rpm/stable/x86_64
sudo yum install clickhouse-server clickhouse-client
3.启动每台机器的clickhouse:
sudo systemctl start clickhouse-server
启动后可以查看状态:
sudo systemctl status clickhouse-server
启动成功后,可以使用命令连接clickhouse:
clickhouse-client
成功进入会显示下:
4.部署zookeeper集群:
为什么使用zookeeper?不用也可以,但建议还是使用。附上我搭建zookeeper的教程连接:
zookeeper集群部署教程
(一定要看,本人亲自搭建过,一步一步来,不会有问题)
二、clickhouse集群部署方式
ClickHouse提供了非常高级的基于zookeeper的表复制方式,同时也提供了基于Cluster的复制方式,分析一下这两种方式:
首先附上clickhouse的配置文件目录:
1.基于zookeeper的表复制方式:
打开这个配置文件:
/etc/clickhouse-server/config.xml
(1)配置 listen_host字段:
<listen_host>::1</listen_host>
<listen_host>127.0.0.1</listen_host>
(2)配置zookeeper字段:
host改成你自己的zookeeper 内网ip地址
<zookeeper>
<node index="1">
<host>172.31.36.230</host>
<port>2181</port>
</node>
<node index="2">
<host>172.31.36.231</host>
<port>2181</port>
</node>
<node index="3">
<host>172.31.36.232</host>
<port>2181</port>
</node>
</zookeeper>
3.配置 remote_server字段:
找到配置文件中的 remote_server标签,发现它里面有很多的内容,我们没有都用到,它只是给我一个例子,把里面的内容都删除,粘贴上我们自己想要的:
<remote_servers>
<!--ck_cluster是集群名字,自己命名就可以,建库建表需要用到-->
<ck_cluster>
<!-- 数据分片1 -->
<shard>
<internal_replication>true</internal_replication>
<replica>
<host>172.32.28.141</host>
<port>9000</port>
</replica>
<replica>
<host>172.32.28.142</host>
<port>9000</port>
</replica>
</shard>
<!-- 数据分片2 -->
<shard>
<internal_replication>true</internal_replication>
<replica>
<host>172.32.28.143</host>
<port>9000</port>
</replica>
<replica>
<host>172.32.28.144</host>
<port>9000</port>
</replica>
</shard>
<!-- 数据分片3 -->
<shard>
<internal_replication>true</internal_replication>
<replica>
<host>172.32.28.145</host>
<port>9000</port>
</replica>
<replica>
<host>172.32.28.146</host>
<port>9000</port>
</replica>
</shard>
</ck_cluster>
</remote_servers>
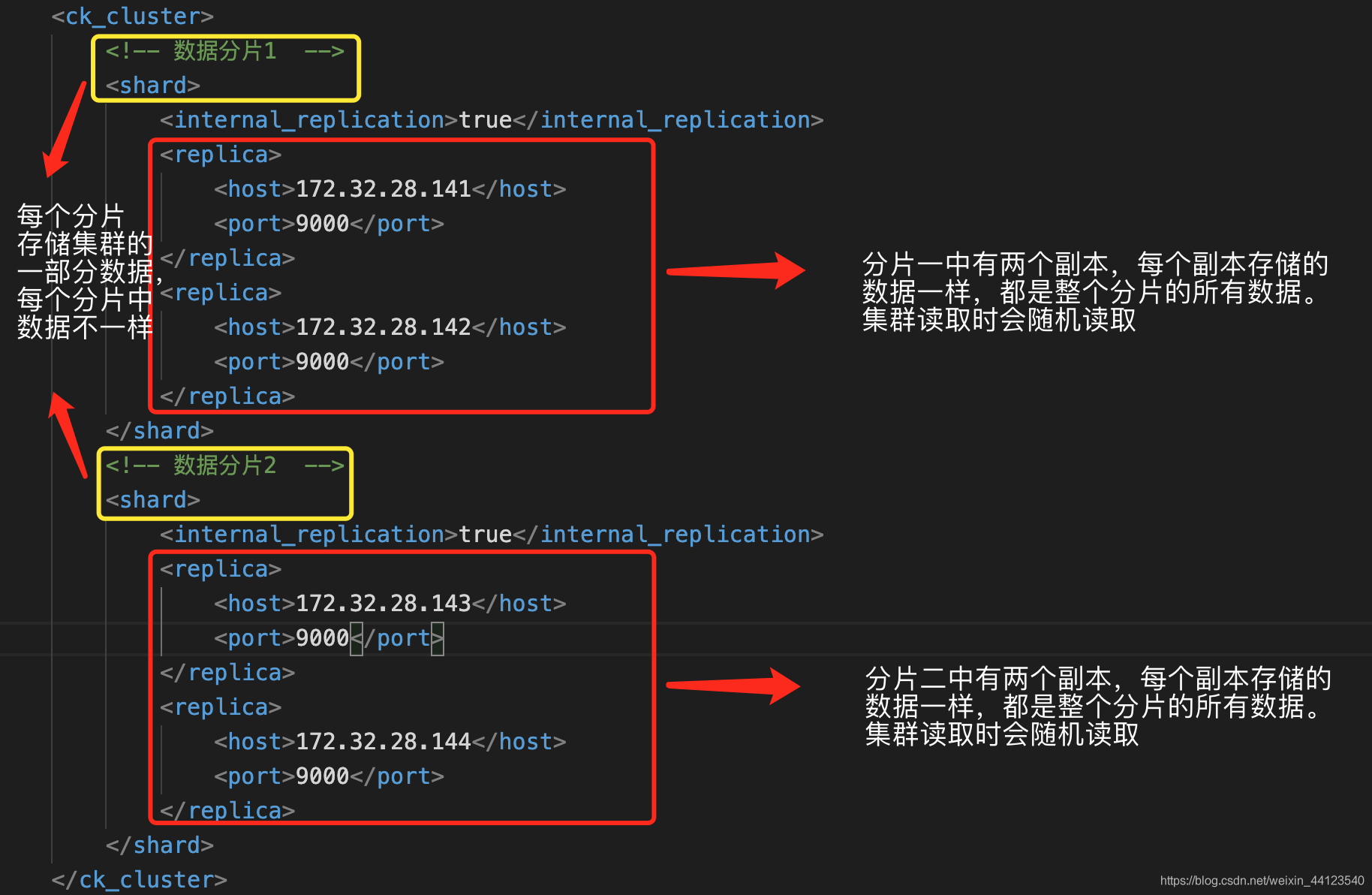
由于我们准备部署的是3分片2副本的集群,现在来解释一下配置参数的意思:
<shard></shard>
shard标签代表分片的意思,如上图我们有3个分片,clickhouse集群中每个分片会存储整个集群一部分的数据,每个分片中有这个标签:
<replica></replica>
代表副本的意思,什么是副本?比如我只有三台机器做三个分片,那么每个分片中只有这一台机器作为副本,这台机器存储这个分片的所有数据,若这台机器挂掉了,那么数据就丢了。那如果我们有6台机器或者更多,每个分片里就可以配置两个副本机器,这两个副本存储的数据是一摸一样的,集群读取数据时会随机从其中选择一个读取。这样即使一台机器挂掉了,也不会影响正常使用,而且对业务来说是无感的,数据一切正常。
还有最重要的这个标签:
<internal_replication>true</internal_replication>
因为我们和zookeeper配合使用,internal_replication必须设置为true,原因等下解释。
来张图,看起来更直观:
(4)配置macros字段:
根据每台机器的分片副本,配置。如:第3分片的第一副本这样配置:
<macros>
<shard>03</shard>
<replica>01</replica>
</macros>
比如:我们所有机器具体信息:
ck01: shard=01, replica=01
ck02: shard=01, replica=02
ck03: shard=02, replica=01
ck04: shard=02, replica=02
ck05: shard=03, replica=01
ck05: shard=03, replica=02
配置后可以再每台机器上用命令查看是否成功:
select * from system.macros
第一分片第一副本的机器会显示:
┌─macro───┬─substitution─┐
│ replica │ 01 │
│ shard │ 01 │
└─────────┴──────────────┘
配置文件是热更新的,所以修改配置后无需要重启服务,除非是首次启动 ClickHouse 。
(5)实验:
当我们配置完成以上之后,基于zookeeper的clickhouse集群就部署完成了,我们做几个简单的实验来验证:
查看集群状态:
随便选一台机器,连接clickhouse后,输入命令:
select * from system.clusters;
如果集群部署成功,你会看到所有机器的信息。
创建 ReplicatedMergeTree 测试表:
任选一台机器,创建一个 ReplicatedMergeTree 引擎的测试表,测试 ZooKeeper 同步功能
CREATE TABLE test_ck ON CLUSTER ck_cluster (EventDate DateTime, Number UInt32, id UInt32 ) ENGINE = ReplicatedMergeTree('/clickhouse/tables/{shard}/test_ck', '{replica}') PARTITION BY toYYYYMM(EventDate) ORDER BY (Number, EventDate, intHash32(id)) SAMPLE BY intHash32(id);
在其他机器节点show tables查看表结构是否同步成功;
验证同一分片不同副本数据备份是否生效:
-- ck01 登录执行
insert into test_ck values ('2021-02-01 00:00:01', 2, 2);
-- ck02 登录执行
select * from test
若数据存在,则表示数据同步配置成功!
创建 Distributed 引擎测试表:
创建一个分布式测试表测试数据分片是否正常。因为已经配置了zookeeper,所以创建表的DDL语句也会同步到其他节点上。
CREATE TABLE dis_test ON CLUSTER ck_cluster AS test_ck
ENGINE = Distributed(ck_cluster, default, test_ck, rand())
//参数含义:ck_cluster集群名称,default数据库,test_ck表,rand()分布式表采用的分配算法,除了这个还有sipHash64(字段名)
(注意:分布式表是基于已经存在的本地表来实现的,分布式表相当于视图,本身并不存储数据,写分布式表,分布式表会将数据发送到各个机器上。查分布式表,会聚合所有机器的数据显示)
插入分布式表几条数据:
insert into dis_test values ('2021-07-01 8:00:01', 1,10);
insert into dis_test values ('2021-07-01 8:00:02', 11,15);
insert into dis_test values ('2021-07-01 8:00:03', 10,15);
insert into dis_test values ('2021-07-01 8:00:04', 13,5);
insert into dis_test values ('2021-07-01 8:00:05', 1,5);
insert into dis_test values ('2021-07-01 8:00:06', 12,14);
直接查询分布式表可以看到这些数据:
select * from dis_test
可以在每个分片的一个机器上查看本地表test_ck,看每个分片都有几条数据:
select * from test_ck
至此,基于zookeeper的clickhouse集群部署方式完成!
2.基于Cluster的复制方式:
大致说一下这种方式,包括官方在内都不推荐这种方式。这种方式不需要配置zookeeper。
如果我们想使用这种方式,需要打开配置文件:
/etc/clickhouse-server/config.xml
找到<remote_servers>这个标签,下面的所有信息就是我们配置集群的配置信息,和上边基本一致,但这个标签<internal_replication>false</internal_replication>不一样,里面要写false
详细说一下:
(1)internal_replication=false时:
往分布式表(注意分布式表只是本地表的view,是不存放任何实体数据的)里面写入数据时,表层面自动同步开启,数据会写入所有备份中(同属一个shard内的表数据相同),但是这个时候是不校验数据一致性的(比如说写入server1的时候成功了,但是写入server1的备份server2的时候有一些没有写入成功,那么这两个互为备份的表就不一致了),也就是说,有可能出现两个备份数据略微不一致的情况,虽然这种可能性很小,另外出现了不一致的时候表之间不会自动同步需要自己手动。这种被官方称为poor man’s replication,如果喜欢简单而且特别讨厌配置zookeeper的话可以使用
(2)internal_replication=true,且没有zookeeper的配合:
不使用zookeeper,那么往分布式表写入数据时,是只写入一组备份中的(也就是说同一个shard内部只有一个表写入了数据,其他的表均不会写入数据,除非有一个宕机另外的作为补充下入,但是这个时候表之间的数据就不同了,需要人工手动统一(备份合并就是shard总体)。实际测试中,当向分布式表写入数据时,replica group 1 被写入了数据,replica group 2 没有被写入数据。在此种条件下(internal_replication=true时且不使用zookeeper),存在海量风险,极其不建议使用: 实际测试中,所有节点均正常工作的情况下,使用分布式表查询,同样的sql语句会出现前后结果不一致的情况 当有节点挂掉时候,那么挂掉之前的数据是写入备份A,挂掉之后数据写入了备份B(此时集群还是正常工作的),当你去使用分布表查询数据时,是肯定会得到错误结果的,因为分布表的查询方式是每个shard中选取一个表来查询并合并结果,由于备份A和备份B之间没同步,那么你查询的只是一部分数据。这种方法切记不能使用!
(3)internal_replication=true时:
使用ReplicatedMergeTree表引擎+zookeeper,这种方案看起来配置很多但是也是最稳定的方案。
三、总结:
对比clickhouse集群部署提供的两种方案,基于zookeeper的部署方案更稳重更安全。所以建议采用这种。
另外在搭建完成后,我们创建了分布式表和本地表,在上述实验中,我们是直接写分布式表,分布式表会将数据发送到其他机器的本地表上。有人建议不要直接这么做,我查阅了很多文章,总结一下原因:
1.数据量很大时:
当每天数据量很大时,比如每天上亿级别或以上。
由于分布式表的逻辑简单,仅仅是转发请求,所以在转发安全性上,会有风险,并且rand的方式,可能会造成不均衡,而且Distributed表在写入时会在本地节点生成临时数据,会产生写放大,所以会对CPU及内存造成一些额外消耗,分布式表接收到数据后会将数据拆分成多个parts, 并转发数据到其它服务器, 会引起服务器间网络流量增加、服务器merge的工作量增加, 导致写入速度变慢, 并且增加了Too many parts的可能性.因此数据量大时建议通过轮询的方式写本地表,这样最保险和均衡,这也是很多人建议使用的。
1.数据量并不大时:
直接写分布式表和轮询写本地表都差不多,想用哪种方式都可以。
其实分布式表的本质就是一个视图,设计的目的就是为了查询的,虽然数据量不大时没有什么影响。
2.综上所述,我觉得集群部署使用的最佳建议:
(1)采用基于zookeeper的方式部署集群
(2)每个分片最少有两个副本来保证数据一致性
(3)读分布式表,分布式表只做查询
(4)通过负载均衡的方式写本地表
(5)尽量做1000条以上批量的写入,避免逐行insert或小批量的insert,update,delete操作,因为ClickHouse底层会不断的做异步的数据合并,会影响查询性能。
大家如果有什么问题直接给我留言~