嵌入式Linux驱动开发笔记(四)
四、I.MX6U开发基础
嵌入式Linux与单片机的区别:
因为嵌入式 Linux 和单片机的开发方式以及应用场合不同。单片机学名叫做 Microcontroller,也就是微控制器,主要用于控制相关的应用,因此单片机的外设都比较多,比如很多路的 IIC、 SPI、 UART、定时器等等。嵌入式 Linux 开发主要注重于高端应用场合,比如音视频处理、网络处理等等。
1.Cortex-A7 MPCore 架构
(1)Cortex-A7 MPCore 概述
Cortex-A7 MPcore 处理器支持 1~4 核,通常是和 Cortex-A15 组成 big.LITTLE 架构的,Cortex-A15 作为大核负责高性能运算,比如玩游戏啥的, Cortex-A7 负责普通应用,因为 CortexA7 省电 。
Cortex-A7 MPCore 的 L1 可选择 8KB、 16KB、 32KB、 64KB, L2 Cache 可以不配,也可以选择 128KB、 256KB、 512KB、 1024KB。 I.MX6UL 配置了 32KB 的 L1 指令 Cache 和 32KB 的L1 数据 Cache,以及 128KB 的 L2 Cache。 Cortex-A7MPCore 使用 ARMv7-A 架构,主要特性如下:
①、 SIMDv2 扩展整形和浮点向量操作。
②、提供了与 ARM VFPv4 体系结构兼容的高性能的单双精度浮点指令,支持全功能的
IEEE754。
③、支持大物理扩展(LPAE),最高可以访问 40 位存储地址,也就是最高可以支持 1TB 的
内存。
④、支持硬件虚拟化。
⑥、支持 Generic Interrupt Controller(GIC)V2.0。
⑦、支持 NEON,可以加速多媒体和信号处理算法。
(2)Cortex-A 处理器运行模型
以前的 ARM 处理器有 7 中运行模型: User、 FIQ、 IRQ、 Supervisor(SVC)、 Abort、 Undef和 System,其中 User 是非特权模式,其余 6 中都是特权模式。但新的 Cortex-A 架构加入了TrustZone 安全扩展,所以就新加了一种运行模式: Monitor,新的处理器架构还支持虚拟化扩展,因此又加入了另一个运行模式: Hyp,所以 Cortex-A7 处理器有 9 种处理模式 ,如下表:
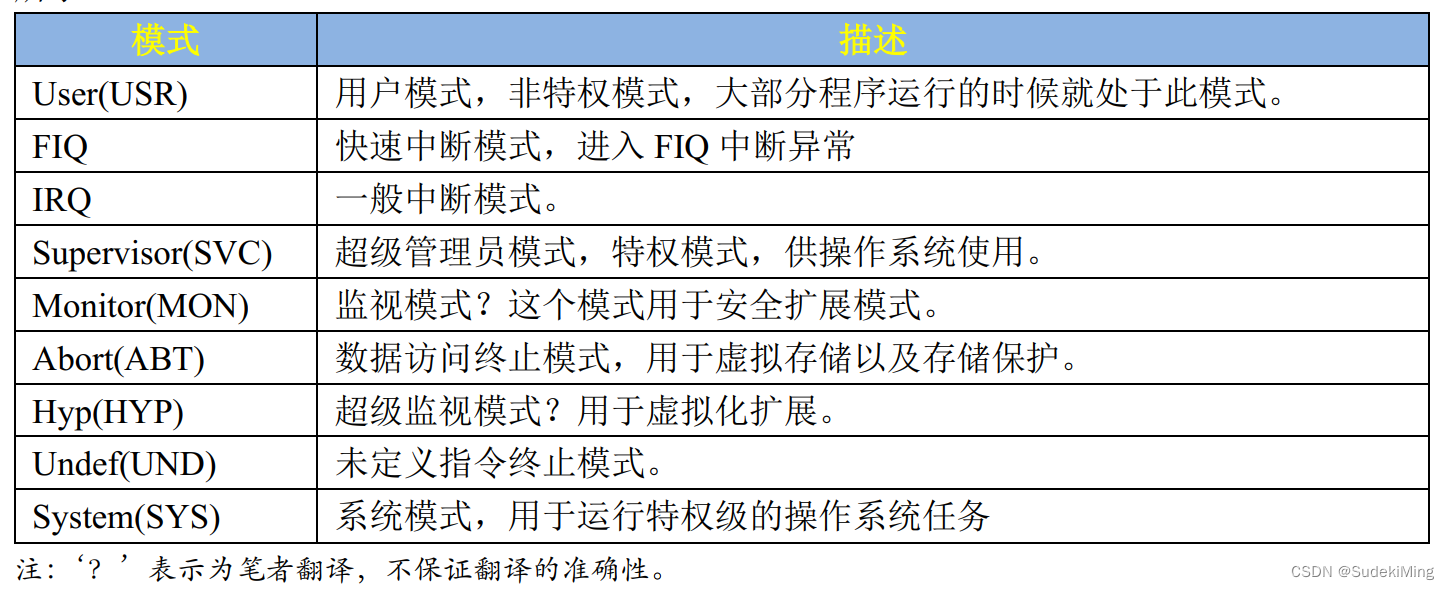
除了 User(USR)用户模式以外,其它 8 种运行模式都是特权模式。这几个运行模式可以通过软件进行任意切换,也可以通过中断或者异常来进行切换。大多数的程序都运行在用户模式,用户模式下是不能访问系统所有资源的,有些资源是受限的,要想访问这些受限的资源就必须进行模式切换。但是用户模式是不能直接进行切换的,用户模式下需要借助异常来完成模式切换,当要切换模式的时候,应用程序可以产生异常,在异常的处理过程中完成处理器模式切换。当中断或者异常发生以后,处理器就会进入到相应的异常模式种,每一种模式都有一组寄存器供异常处理程序使用,这样的目的是为了保证在进入异常模式以后,用户模式下的寄存器不会被破坏。
(3)Cortex-A 寄存器组
ARM 架构提供了 16 个 32 位的通用寄存器(R0~R15)供软件使用,前 15 个(R0~R14)可以用作通用的数据存储, R15 是程序计数器 PC,用来保存将要执行的指令。 ARM 还提供了一个当前程序状态寄存器 CPSR 和一个备份程序状态寄存器 SPSR, SPSR 寄存器就是 CPSR 寄存器的备份
总结一下, CortexA 内核寄存器组成如下:
①、 34 个通用寄存器,包括 R15 程序计数器(PC),这些寄存器都是 32 位的。
②、 8 个状态寄存器,包括 CPSR 和 SPSR。
③、 Hyp 模式下独有一个 ELR_Hyp 寄存器。
【1】通用寄存器
R0~R15 就是通用寄存器,通用寄存器可以分为以下三类:
①、 未备份寄存器,即 R0~R7。
②、 备份寄存器,即 R8~R14。
③、程序计数器 PC,即 R15。
2.ARM 汇编基础
Cortex-A 芯片一上电 SP 指针还没初始化, C 环境还没准备好,所以肯定不能运行 C 代码,必须先用汇编语言设置好 C 环境,比如初始化 DDR、设置 SP指针等等,当汇编把 C 环境设置好了以后才可以运行 C 代码。所以 Cortex-A 一开始肯定是汇编代码,其实 STM32 也一样的,一开始也是汇编,以 STM32F103 为例,启动文件
startup_stm32f10x_hd.s 就是汇编文件,只是这个文件 ST 已经写好了,我们根本不用去修改。
I.MX6U-ALPHA 使用的是 NXP 的 I.MX6UL 芯片,这是一款 Cortex-A7 内核的芯片 。
(1)GNU 汇编语法
GNU 汇编语法适用于所有的架构,并不是 ARM 独享的, GNU 汇编由一系列的语句组成,每行一条语句,每条语句有三个可选部分,如下:
label: instruction @ comment
label即标号,表示地址位置,有些指令前面可能会有标号,这样就可以通过这个标号得到
指令的地址,标号也可以用来表示数据地址。注意 label 后面的“:”,任何以“:”结尾的标识
符都会被识别为一个标号。
instruction 即指令,也就是汇编指令或伪指令。
@符号,表示后面的是注释,就跟 C 语言里面的“/”和“/”一样,其实在 GNU 汇编文
件中我们也可以使用“/”和“/”来注释。
comment就是注释内容。
比如如下代码:
add:
MOVS R0, #0X12 @设置 R0=0X12
上面代码中“add:”就是标号,“MOVS R0,#0X12”就是指令,最后的“@设置 R0=0X12”就是注释。
注意! ARM 中的指令、伪指令、伪操作、寄存器名等可以全部使用大写,也可以全部使用小写,但是不能大小写混用。
用户可以使用.section 伪操作来定义一个段,汇编系统预定义了一些段名:
.text 表示代码段。
.data 初始化的数据段。
.bss 未初始化的数据段。
.rodata 只读数据段。
我们当然可以自己使用.section 来定义一个段,每个段以段名开始,以下一段名或者文件结
尾结束,比如:
.section .testsection @定义一个 testsetcion 段
汇编程序的默认入口标号是_start,不过我们也可以在链接脚本中使用 ENTRY 来指明其它
的入口点,下面的代码就是使用 _start 作为入口标号:
global _start
_start:
ldr r0, =0x12 @r0=0x12
上面代码中.global 是伪操作,表示_start 是一个全局标号,类似 C 语言里面的全局变量一
样,常见的伪操作有:
.byte 定义单字节数据,比如.byte 0x12。
.short 定义双字节数据,比如.short 0x1234。
.long 定义一个 4 字节数据,比如.long 0x12345678。
.equ 赋值语句,格式为: .equ 变量名,表达式,比如.equ num, 0x12,表示 num=0x12。
.align 数据字节对齐,比如: .align 4 表示 4 字节对齐。
.end 表示源文件结束。
.global 定义一个全局符号,格式为: .global symbol,比如: .global _start。
GNU 汇编还有其它的伪操作,但是最常见的就是上面这些
GNU 汇编同样也支持函数,函数格式如下:
函数名:
函数体
返回语句
GNU 汇编函数返回语句不是必须的,如下代码就是用汇编写的 Cortex-A7 中断服务函数:
// 示例代码 7.1.1.1 汇编函数定义
/* 未定义中断 */
Undefined_Handler:
ldr r0, =Undefined_Handler
bx r0
/* SVC 中断 */
SVC_Handler:
ldr r0, =SVC_Handler
bx r0
/* 预取终止中断 */
PrefAbort_Handler:
ldr r0, =PrefAbort_Handler
bx r0
上述代码中定义了三个汇编函数: Undefined_Handler、 SVC_Handler 和PrefAbort_Handler。以函数 Undefined_Handler 为例我们来看一下汇编函数组成,“Undefined_Handler”就是函数名,“ldr r0, =Undefined_Handler”是函数体,“bx r0”是函数返回语句,“bx”指令是返回指令,函数返回语句不是必须的。
(2)Cortex-A7 常用汇编指令
【1】处理器内部数据传输指令
使用处理器做的最多事情就是在处理器内部来回的传递数据,常见的操作有:
①、将数据从一个寄存器传递到另外一个寄存器。
②、将数据从一个寄存器传递到特殊寄存器,如 CPSR 和 SPSR 寄存器。
③、将立即数传递到寄存器。
数据传输常用的指令有三个: MOV、 MRS 和 MSR,用法如下表

MOV 指令
MOV 指令用于将数据从一个寄存器拷贝到另外一个寄存器,或者将一个立即数传递到寄存器里面,使用示例如下:
MOV R0, R1 @将寄存器 R1 中的数据传递给 R0,即 R0=R1
MOV R0, #0X12 @将立即数 0X12 传递给 R0 寄存器,即 R0=0X12
MRS 指令
MRS 指令用于将特殊寄存器(如 CPSR 和 SPSR)中的数据传递给通用寄存器,要读取特殊寄存器的数据只能使用 MRS 指令!使用示例如下:
MRS R0, CPSR @将特殊寄存器 CPSR 里面的数据传递给 R0,即 R0=CPSR
MSR 指令
MSR 指令和 MRS 刚好相反, MSR 指令用来将普通寄存器的数据传递给特殊寄存器,也就是写特殊寄存器,写特殊寄存器只能使用 MSR,使用示例如下:
MSR CPSR, R0 @将 R0 中的数据复制到 CPSR 中,即 CPSR=R0
【2】存储器访问指令
ARM 不能直接访问存储器,比如 RAM 中的数据, I.MX6UL 中的寄存器就是 RAM 类型的,我们用汇编来配置 I.MX6UL 寄存器的时候需要借助存储器访问指令,一般先将要配置的值写入到 Rx(x=0~12)寄存器中,然后借助存储器访问指令将 Rx 中的数据写入到 I.MX6UL 寄存器中。读取 I.MX6UL 寄存器也是一样的,只是过程相反。常用的存储器访问指令有两种: LDR 和STR,用法如下表 所示:
 LDR 指令
LDR 指令
LDR 主要用于从存储加载数据到寄存器 Rx 中, LDR 也可以将一个立即数加载到寄存器 Rx中, LDR 加载立即数的时候要使用“=”,而不是“#”。在嵌入式开发中, LDR 最常用的就是读取 CPU 的寄存器值,比如 I.MX6UL 有个寄存器 GPIO1_GDIR,其地址为 0X0209C004,我们现在要读取这个寄存器中的数据,示例代码如下:
#示例代码 7.2.2.1 LDR 指令使用
LDR R0, =0X0209C004 @将寄存器地址 0X0209C004 加载到 R0 中,即 R0=0X0209C004
LDR R1, [R0] @读取地址 0X0209C004 中的数据到 R1 寄存器中
上述代码就是读取寄存器 GPIO1_GDIR 中的值,读取到的寄存器值保存在 R1 寄存器中,上面代码中 offset 是 0,也就是没有用到 offset。
STR 指令
LDR 是从存储器读取数据, STR 就是将数据写入到存储器中,同样以 I.MX6UL 寄存器GPIO1_GDIR 为例,现在我们要配置寄存器 GPIO1_GDIR 的值为 0X20000002,示例代码如下:
#示例代码 7.2.2.2 STR 指令使用
LDR R0, =0X0209C004 @将寄存器地址 0X0209C004 加载到 R0 中,即 R0=0X0209C004
LDR R1, =0X20000002 @R1 保存要写入到寄存器的值,即 R1=0X20000002
STR R1, [R0] @将 R1 中的值写入到 R0 中所保存的地址中
LDR 和 STR 都是按照字进行读取和写入的,也就是操作的 32 位数据,如果要按照字节、半字进行操作的话可以在指令“LDR”后面加上 B 或 H,比如按字节操作的指令就是 LDRB 和STRB,按半字操作的指令就是 LDRH 和 STRH。
【3】压栈和出栈指令
我们通常会在 A 函数中调用 B 函数,当 B 函数执行完以后再回到 A 函数继续执行。要想再跳回 A 函数以后代码能够接着正常运行,那就必须在跳到 B 函数之前将当前处理器状态保存起来(就是保存 R0~R15 这些寄存器值),当 B 函数执行完成以后再用前面保存的寄存器值恢复R0~R15 即可。保存 R0~R15 寄存器的操作就叫做现场保护,恢复 R0~R15 寄存器的操作就叫做恢复现场。在进行现场保护的时候需要进行压栈(入栈)操作,恢复现场就要进行出栈操作。压栈的指令为 PUSH,出栈的指令为 POP, PUSH 和 POP 是一种多存储和多加载指令,即可以一次
操作多个寄存器数据,他们利用当前的栈指针 SP 来生成地址, PUSH 和 POP 的用法如下表所示

处理器的堆栈是向下增长的,使用的汇编代码如下:
// 例:将 R0~R3 和 R12 这 5 个寄存器压栈
PUSH {
R0~R3, R12} @将 R0~R3 和 R12 压栈
如我们现在要再将 LR 进行压栈,汇编代码如下:
PUSH {
LR} @将 LR 进行压栈
如果我们要出栈的话就是使用如下代码:
POP {
LR} @先恢复 LR
POP {
R0~R3,R12} @在恢复 R0~R3,R12
出栈的就是从栈顶,也就是 SP 当前执行的位置开始,地址依次减小来提取堆栈中的数据到要恢复的寄存器列表中。 PUSH 和 POP 的另外一种写法是“STMFD SP!”和“LDMFD SP!”,
因此上面的汇编代码可以改为:
#示例代码 7.2.3.1 STMFD 和 LDMFD 指令
STMFD SP!,{
R0~R3, R12} @R0~R3,R12 入栈
STMFD SP!,{
LR} @LR 入栈
LDMFD SP!, {
LR} @先恢复 LR
LDMFD SP!, {
R0~R3, R12} @再恢复 R0~R3, R12
STMFD 可以分为两部分: STM 和 FD,同理, LDMFD 也可以分为 LDM 和 FD。 LDR 和 STR,这两个是
数据加载和存储指令,但是每次只能读写存储器中的一个数据。 STM 和 LDM 就是多存储和多加载,可以连续的读写存储器中的多个连续数据。
拓展
FD 是 Full Descending 的缩写,即满递减的意思。根据 ATPCS 规则,ARM 使用的 FD 类型
的堆栈, SP 指向最后一个入栈的数值,堆栈是由高地址向下增长的,也就是前面说的向下增长
的堆栈,因此最常用的指令就是 STMFD 和 LDMFD。 STM 和 LDM 的指令寄存器列表中编号
小的对应低地址,编号高的对应高地址。
【4】跳转指令
有多种跳转操作,比如:
①、直接使用跳转指令 B、 BL、 BX 等。
②、直接向 PC 寄存器里面写入数据。
上述两种方法都可以完成跳转操作,但是一般常用的还是 B、 BL 或 BX,用法如下表7.2.4.1:
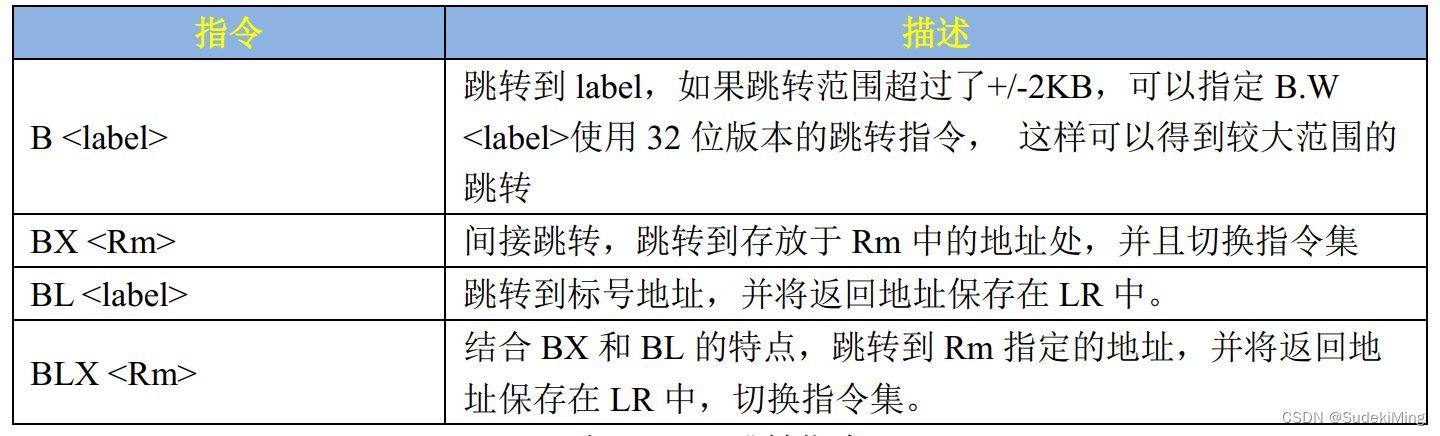 我们重点来看一下 B 和 BL 指令,因为这两个是我们用的最多的,如果要在汇编中进行函数调用使用的就是 B 和 BL 指令:
我们重点来看一下 B 和 BL 指令,因为这两个是我们用的最多的,如果要在汇编中进行函数调用使用的就是 B 和 BL 指令:
B 指令
这是最简单的跳转指令, B 指令会将 PC 寄存器的值设置为跳转目标地址, 一旦执行 B 指令, ARM 处理器就会立即跳转到指定的目标地址。如果要调用的函数不会再返回到原来的执行处,那就可以用 B 指令,如下示例:
#示例代码 7.2.4.1 B 指令示例
_start:
ldr sp,=0X80200000 @设置栈指针
b main @跳转到 main 函数
BL 指令
BL 指令相比 B 指令,在跳转之前会在寄存器 LR(R14)中保存当前 PC 寄存器值,所以可以通过将 LR 寄存器中的值重新加载到 PC 中来继续从跳转之前的代码处运行,这是子程序调用一个基本但常用的手段。比如 Cortex-A 处理器的 irq 中断服务函数都是汇编写的,主要用汇编来实现现场的保护和恢复、获取中断号等。但是具体的中断处理过程都是 C 函数,所以就会存在汇编中调用 C 函数的问题。而且当 C 语言版本的中断处理函数执行完成以后是需要返回到irq 汇编中断服务函数,因为还要处理其他的工作,一般是恢复现场。这个时候就不能直接使用B 指令了,因为 B 指令一旦跳转就再也不会回来了,这个时候要使用 BL 指令,示例代码如下:
#示例代码 7.2.4.2 BL 指令示例
push {
r0, r1} @保存 r0,r1
cps #0x13 @进入 SVC 模式,允许其他中断再次进去
bl system_irqhandler @加载 C 语言中断处理函数到 r2 寄存器中
cps #0x12 @进入 IRQ 模式
pop {
r0, r1}
str r0, [r1, #0X10] @中断执行完成,写 EOIR
【5】算术运算指令
汇编中也可以进行算术运算, 比如加减乘除,常用的运算指令用法如表 7.2.5.1 所示:
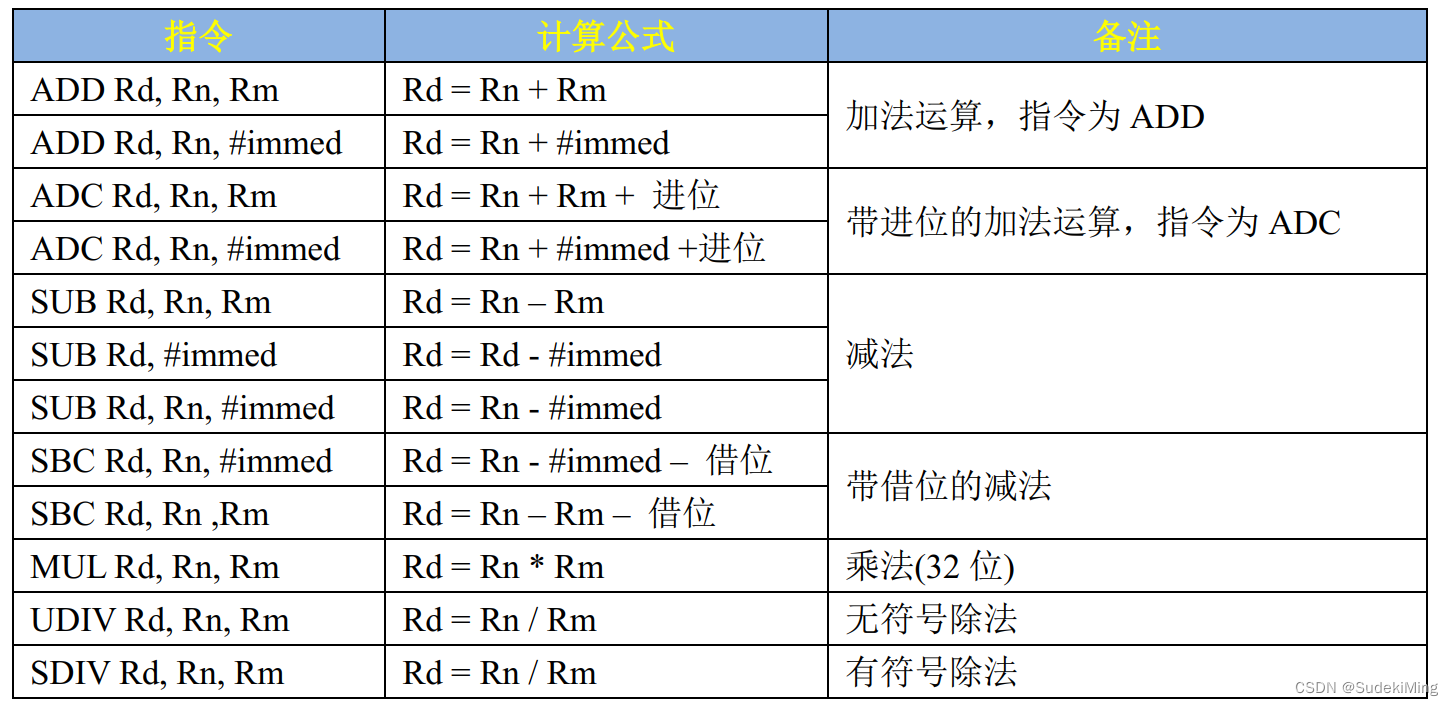
在嵌入式开发中最常会用的就是加减指令,乘除基本用不到。
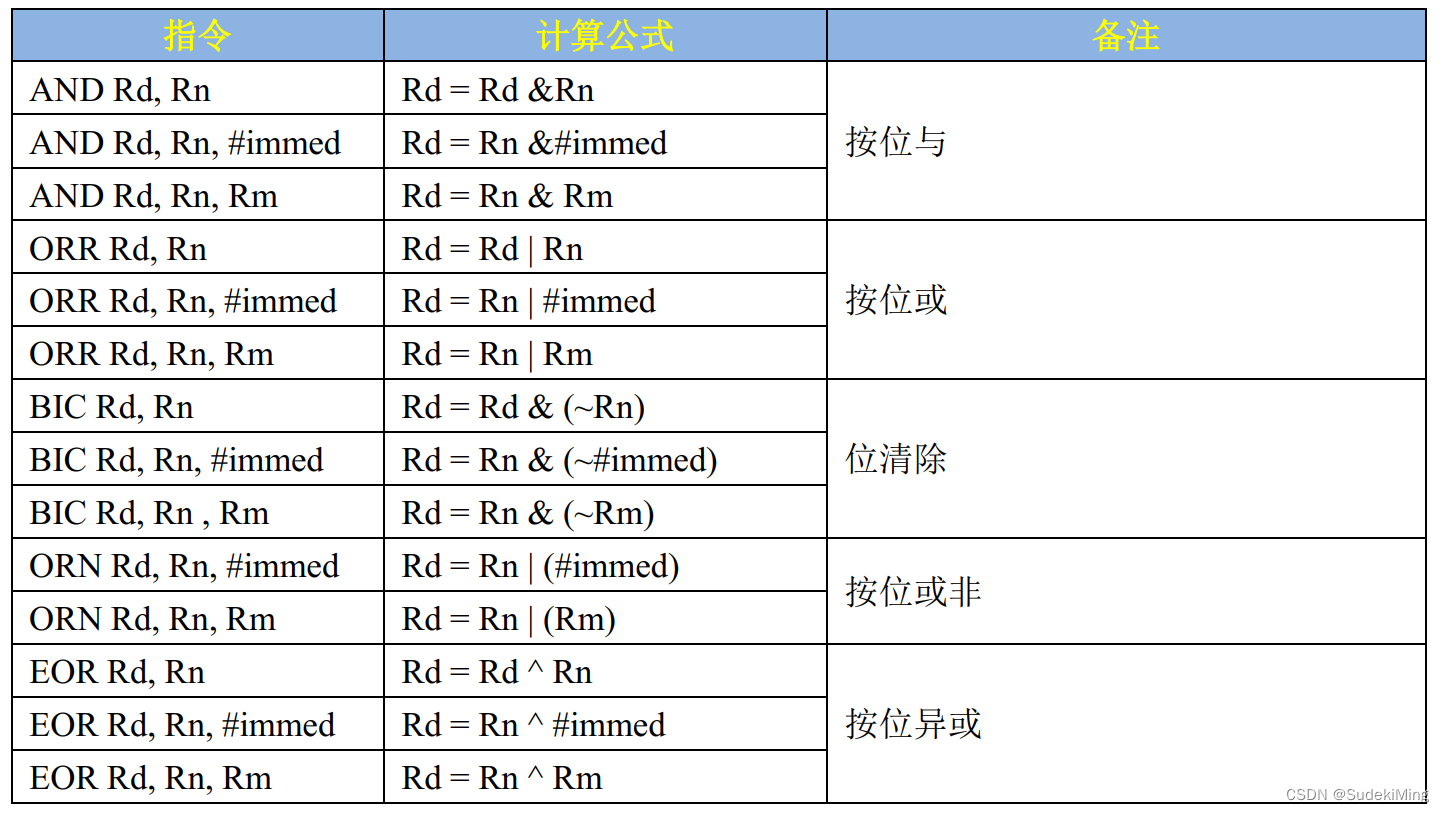
【6】逻辑运算指令
我们用 C 语言进行 CPU 寄存器配置的时候常常需要用到逻辑运算符号,比如“&”、“|”等 逻辑运算符。使用汇编语言的时候也可以使用逻辑运算指令,常用的运算指令用法如表 7.2.6.1所示: