前言
昨天跟小伙伴斗图,关于斗图这件事,我表示我从来没有输过。至于为什么不会输,这些都是男人的秘密,今天我想把这个小技
巧告诉大家。学会了记得挑战你最好的朋友,打赌让他输了请你吃大西瓜…

1、介绍
•平台:斗图啦
•语言:python
•技术:python多线程、python安全队列、python之Xpath、正则、request
以上我们使用的技术,都是之前整理过的对不对,那么我们就根据之前的学习内容来进行爬取斗图表情包吧。

2、python爬取流程梳理
我们刚开始学习的时候,是不是每次都需要梳理下爬取的流程呢,那么这次咱们还是和之前一样,首先我们需要找到我们爬取的平台的网址是什么:
https://dou.yuanmazg.com/doutu?page=1
访问这个界面之后,我们可以看到如下显示的内容:

然后我们往下滑之后,可以看到这里一共有1500+的页面,那么我们现在爬取前50页的内容吧,大概流程我觉得应该如下哈:
1.获取每个页面的url;
2.将获取到的url放置Queue中;
3.从Queue中获取一个Url,使用requests获取内容,使用xpath获取取该Url中每一个图片的Url;
4.然后将每个图片中的Url放入到另一个Queue中;
5.然后再从第二个Queue中获取图片的url;
6.根据Queue来下载并保存即可;
7.以上步骤我们使用多线程+Queue的形式来进行。

3、python爬取图片
3.1 框架
老样子,首先我们简简单单写一个框架;
import threading
class Producter(threading.Thread):
pass
class Consumer(threading.Thread):
pass
def main():
pass
if __name__ == '__main__':
main()
然后我们一步一步进行;

3.2 初步获取页面有效信息
python学习交流Q群:906715085###
import requests
from lxml import etree
Url = 'https://dou.yuanmazg.com/doutu?page=1'
Header = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36'}
Page_get = requests.get(url=Url, headers=Header)
Page_content = Page_get.text
Page_message = etree.HTML(Page_content)
Page_div = Page_message.xpath('//div[@class="page-content"]')[0]
Page_div = etree.tostring(Page_div, pretty_print=True, method='html').decode('utf-8')
print(Page_div)
3.3 提取每一个图片的url和name
import requests
from lxml import etree
Url = 'https://dou.yuanmazg.com/doutu?page=1'
Header = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36'}
Page_get = requests.get(url=Url, headers=Header)
Page_content = Page_get.text
Page_message = etree.HTML(Page_content)
Page_div = Page_message.xpath('//div[@class="page-content"]//a//img')
# Page_div = etree.tostring(Page_div, pretty_print=True, method='html').decode('utf-8')
# print(Page_div)
for i in Page_div:
# print(etree.tostring(i, pretty_print=True, method='html').decode('utf-8'))
Page_url = 'https://dou.yuanmazg.com' + i.xpath("@data-original")[0]
Page_name = i.xpath("@alt")[0]
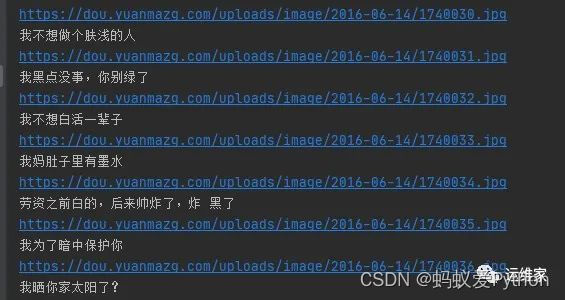
print(Page_url)
print(Page_name)
输出结果如下:

3.4 优化名字
我们可以看到我们获取的图片的名字中有特殊符号,但是我们的电脑上文件名字是不可以出现特殊符号的,那么我们是不是就需
要把名字给他处理一下呢,优化走起,优化之后的代码如下:
import requests
from lxml import etree
import re
Url = 'https://dou.yuanmazg.com/doutu?page=1'
Header = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36'}
Page_get = requests.get(url=Url, headers=Header)
Page_content = Page_get.text
Page_message = etree.HTML(Page_content)
Page_div = Page_message.xpath('//div[@class="page-content"]//a//img')
# Page_div = etree.tostring(Page_div, pretty_print=True, method='html').decode('utf-8')
# print(Page_div)
for i in Page_div:
# print(etree.tostring(i, pretty_print=True, method='html').decode('utf-8'))
Page_url = 'https://dou.yuanmazg.com' + i.xpath("@data-original")[0]
Page_name = i.xpath("@alt")[0]
Page_name = re.sub(r'[,。??,/\\·\*\ ]', '', Page_name)
print(Page_url)
print(Page_name)
随之我们又发现了另一个问题,那就是有些图片他是没有添加描述的,也就是无法获取该图片的名字,那么我们就随机给他一个
名字吧;
import requests
from lxml import etree
import re
import random
Url = 'https://dou.yuanmazg.com/doutu?page=1'
Header = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36'}
Page_get = requests.get(url=Url, headers=Header)
Page_content = Page_get.text
Page_message = etree.HTML(Page_content)
Page_div = Page_message.xpath('//div[@class="page-content"]//a//img')
# Page_div = etree.tostring(Page_div, pretty_print=True, method='html').decode('utf-8')
# print(Page_div)
for i in Page_div:
# print(etree.tostring(i, pretty_print=True, method='html').decode('utf-8'))
Page_url = 'https://dou.yuanmazg.com' + i.xpath("@data-original")[0]
Page_name = i.xpath("@alt")[0]
Page_name = re.sub(r'[,。??,/\\·\*\ ]', '', Page_name)
if Page_name == "":
Page_name = str(random.random())
print(Page_url)
print(Page_name)
到这里是不是名字这个事儿就完事儿了呢,当然不了,想一下,我们在电脑上创建文件的时候是不是还需要后缀名呢,那我们就
应该也把后缀名获取一下子,再次优化之后,代码如下:
import requests
from lxml import etree
import re
import random
import os
Url = 'https://dou.yuanmazg.com/doutu?page=1'
Header = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36'}
Page_get = requests.get(url=Url, headers=Header)
Page_content = Page_get.text
Page_message = etree.HTML(Page_content)
Page_div = Page_message.xpath('//div[@class="page-content"]//a//img')
# Page_div = etree.tostring(Page_div, pretty_print=True, method='html').decode('utf-8')
# print(Page_div)
for i in Page_div:
# print(etree.tostring(i, pretty_print=True, method='html').decode('utf-8'))
Page_url = 'https://dou.yuanmazg.com' + i.xpath("@data-original")[0]
Suffix = os.path.splitext(Page_url)[1]
Page_name = i.xpath("@alt")[0]
Page_name = re.sub(r'[,。??,/\\·\*\ ]', '', Page_name)
if Page_name == "":
Page_name = str(random.random()) + Suffix
else:
Page_name = Page_name + Suffix
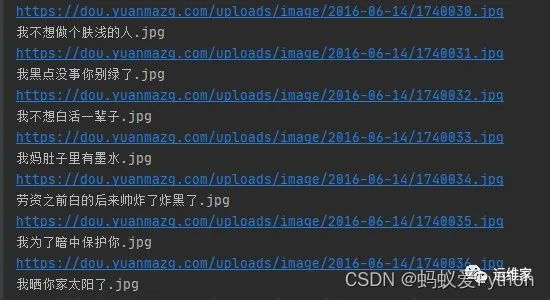
print(Page_url)
print(Page_name)
运行之后结果如下:
好的,这样子的话我们就成功的使用python获取了每一个页面中每一个图片的地址和名字

3.5 下载
当我们获取到了图片的下载地址,以及图片名字之后,我们就可以进行下载了,那么我们的代码就变成了下面的内容:
python学习交流Q群:906715085####
import requests
from lxml import etree
import re
import random
import os
from urllib import request
Url = 'https://dou.yuanmazg.com/doutu?page=1'
Header = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36'}
Page_get = requests.get(url=Url, headers=Header)
Page_content = Page_get.text
Page_message = etree.HTML(Page_content)
Page_div = Page_message.xpath('//div[@class="page-content"]//a//img')
# Page_div = etree.tostring(Page_div, pretty_print=True, method='html').decode('utf-8')
# print(Page_div)
for i in Page_div:
# print(etree.tostring(i, pretty_print=True, method='html').decode('utf-8'))
Page_url = 'https://dou.yuanmazg.com' + i.xpath("@data-original")[0]
Suffix = os.path.splitext(Page_url)[1]
Page_name = i.xpath("@alt")[0]
Page_name = re.sub(r'[,。??,/\\·\*\ ]', '', Page_name)
if Page_name == "":
Page_name = str(random.random()) + Suffix
else:
Page_name = Page_name + Suffix
# print(Page_url)
# print(Page_name)
request.urlretrieve(Page_url, 'doutula/' + Page_name)
print("{}下载完成了~~~".format(Page_name))
运行之后会输出哪个下载完成了,如下:
我不想做个肤浅的人.jpg下载完成了~~~
我黑点没事你别绿了.jpg下载完成了~~~
我不想白活一辈子.jpg下载完成了~~~
我妈肚子里有墨水.jpg下载完成了~~~
劳资之前白的后来帅炸了炸黑了.jpg下载完成了~~~
我为了暗中保护你.jpg下载完成了~~~
我晒你家太阳了.jpg下载完成了~~~
黑夜给了我一双黑色的眼睛可我却一不小心按了全选!.jpg下载完成了~~~
— 省略部分内容—
而且会在doutula这个文件夹下将下载的文件进行保存,如下图:

3.6 添加安全队列和多线程
为什么要使用多线程和安全队列都清楚吧,就是为了速度和数据的准确性啊。
既然我们实现了一个页面中的表情包下载,那么我们是不是只需要稍微改动一下,多启动几个线程,添加几个循环,就能搞定了
呢,经过我们的代码优化之后,成了下面的样子:
python学习交流Q群:906715085####
import requests
from lxml import etree
import re
import random
import os
from urllib import request
from queue import Queue
import threading
import time
class Producer(threading.Thread):
Header = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36'}
def __init__(self, Page_queue, Photo_queue, *args, **kwargs):
super(Producer, self).__init__(*args, **kwargs)
self.Page_queue = Page_queue
self.Photo_queue = Photo_queue
def run(self):
while True:
if self.Page_queue.empty():
break
url = self.Page_queue.get()
self.photo_down(url)
def photo_down(self, url):
Page_get = requests.get(url=url, headers=self.Header)
Page_content = Page_get.text
Page_message = etree.HTML(Page_content)
Page_div = Page_message.xpath('//div[@class="page-content"]//a//img')
for i in Page_div:
Page_url = 'https://dou.yuanmazg.com' + i.xpath("@data-original")[0]
Suffix = os.path.splitext(Page_url)[1]
Page_name = i.xpath("@alt")[0]
Page_name = re.sub(r'[,。??,/\\·\*\ ]', '', Page_name)
if Page_name == "":
Page_name = str(random.random()) + Suffix
else:
Page_name = Page_name + Suffix
self.Photo_queue.put((Page_url, 'doutula/' + Page_name))
class Consumer(threading.Thread):
def __init__(self, Page_queue, Photo_queue, *args, **kwargs):
super(Consumer, self).__init__(*args, **kwargs)
self.Page_queue = Page_queue
self.Photo_queue = Photo_queue
def run(self):
while True:
if self.Page_queue.empty() is True and self.Photo_queue.empty() is True:
break
else:
img_url, img_name = self.Photo_queue.get()
print(img_url)
print(img_name)
request.urlretrieve(img_url, img_name)
def main():
Page_queue = Queue(maxsize=100)
Photo_queue = Queue(maxsize=2000)
for i in range(1, 51): # 下载的页数
Page_url = 'https://dou.yuanmazg.com/doutu?page={}'.format(i)
Page_queue.put(Page_url)
for i in range(5): # 启动5个消费者
t1 = Producer(Page_queue, Photo_queue)
t1.start()
time.sleep(5) # 停留5秒是为了避免消费者的第一个页面都没请求下来的时候,生产者就直接判断无数据,从而自行终止程序。
for i in range(4): # 启动5个生产者
t2 = Consumer(Page_queue, Photo_queue)
t2.start()
if __name__ == '__main__':
main()
经过实验之后,下载速度快多了,结果如下:

这样子我们就可以实现多线程下载斗图表情包,下一次和朋友斗图,再也不怕没有表情包了。