1、本次爬虫目标
从网站中爬取数据,并分析整理,我的目标是完整复刻出一个webapp网站以作练手,所以会对输入如何存到MongoDB做思考。爬取的数据先暂时存到json文件中;当然在实际中可以直接存到自己的MongoDB中,这样复刻出来的网站就是一个完整的网站了,至于视频播放,可以把视频地址爬下来写到特定字段,用户调用是直接拿原来网站的视频就可以了(只爬取慕课免费课程的所有数据)。
运行完会的到另个json文件,结构如下
free.json(记录课程的方向和分类) 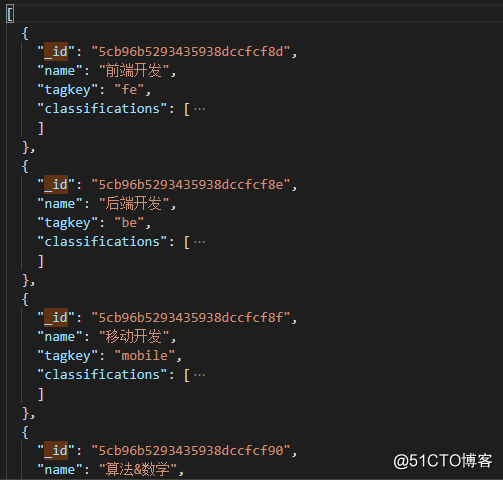
freeCourse.json(记录所有课程的文件,但数据会有id与free中的分类一一对应)
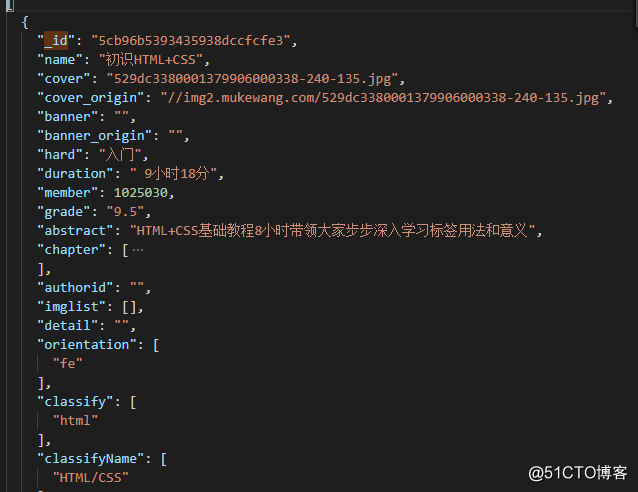
2、创建项目
1)创建craler目录,再新建index.js文件。在目录下执行npm init命令,然后一直回车。
2)安装npm包,执行npm install mongoose(生成MongoDB用的id),npm install https,npm install cheerio;得到以下目录结构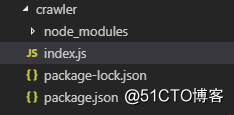
3、获取课程的分类和方向的数据
const mongoose = require('mongoose');
const https = require('https');
const fs = require('fs');
const cheerio = require('cheerio');
var courses = [],
totalPage = 0,
orientations = [],//课程方向
orientationMap = {},
classifyMap = {},//课程分类
baseUrl = 'https://www.imooc.com',
freeCourseUrl = 'https://www.imooc.com/course/list';//免费课程
function fetchPage(url){
getFreeType(url);
}
//类型获取
function getFreeType(url) {
https.get(url, function(res){
var html = '';
res.setEncoding('utf-8')//防止中文乱码
res.on('data' ,function(chunk){
html += chunk;
})
//监听end事件,如果整个网页内容的html都获取完毕,就执行回调函数
res.on('end',function(){
var $ = cheerio.load(html);
var orientationUrl = []//获取课程方向url
,orientationTag = $($('.course-nav-row')[0]);
orientationTag.find('.course-nav-item').each(function(index,ele){
if(index == 0){return}
//课程方向数据表
let orientationTemp ={
_id:new mongoose.Types.ObjectId(),
name: $(ele).find('a').text().trim(),
tagkey: $(ele).find('a').attr('href').split('=').pop(),
}
orientations.push(orientationTemp)
orientationUrl.push('https://m.imooc.com' + $(ele).find('a').attr('href'));
});
getOrientationPage(orientationUrl);//获取每个方向下的分类
})
})
}
//获取每个方向下的分类
function getOrientationPage(orientationUrl){
var promiseList = [];
orientationUrl.forEach((url,index) => {
var prom = new Promise(function(resolve,reject){
https.get(url,function(res){
var html = '';
res.setEncoding('utf-8');
res.on('data',function(chunk){
html += chunk;
});
res.on('end',function(){
var $ = cheerio.load(html);
var classifications = [];
$('.course-item-w a').each((ind,ele) => {
var classTemp = {
_id: new mongoose.Types.ObjectId(),
name: cheerio.load(ele)('.course-label').text().trim(),
tagkey: $(ele).attr('href').split('=').pop(),
img: $(ele).find('.course-img').css('background-image').replace('url(','').replace(')',''),
};
classifications.push(classTemp);
classifyMap[classTemp.name] = classTemp.tagkey;
orientationMap[classTemp.name] = orientations[index].tagkey;
})
orientations[index].classifications = classifications;
resolve('done');
})
}).on('error',function(err){
reject(err)
})
})
promiseList.push(prom);
});
Promise.all(promiseList).then(arr => {
console.log('类型数据收集完毕');
getFreeCourses(freeCourseUrl);
fs.writeFile('./free.json',JSON.stringify(orientations),function(err){
if(err){
console.log(err);
}else{
console.log('free.json文件写入成功!');
}
});
});
}4、获取所有课程
因为本次获取的课程足足有800多个课程,其中也有分页;所以不可能一次同时获取所有的课程。一开始我使用递归请求,每请求处理完一个课程就接着请求下一个课程,这样也可以实现,但是这样的话就处理的太慢了;完全没有发挥出Ajax异步的优势,所以我就用了es6的语法,使用promise.all解决了这个问题。一次请求10个页面(多了node服务就处理不来了,就报各种错,目前没有想到其他好的办法,忘各位大神多指教)。每处理完成10个请求就就接着请求下一页,直至完成。这样把800多个课程数据处理完,也需要大概3分钟左右。
//获取课程
function getFreeCourses(url,pageNum) {
https.get(url, function(res){
var html = '';
if(!pageNum){
pageNum = 1;
}
res.setEncoding('utf-8')//防止中文乱码
res.on('data' ,function(chunk){
html += chunk;
})
//监听end事件,如果整个网页内容的html都获取完毕,就执行回调函数
res.on('end',function(){
let $ = cheerio.load(html);
if(pageNum == 1){
let lastPageHref = $(".page a:contains('尾页')").attr('href');
totalPage = Number(lastPageHref.split('=').pop());
}
$('.course-card-container').each(function(index,ele){
let $ele = cheerio.load(ele);
let cover_origin = $ele('img.course-banner').attr('src');
let cover = cover_origin.split('/').pop();
let classifyName = [];
let classify = [];
let orientation = [];
let hardAndMember = $ele('.course-card-info span');
$ele('.course-label label').each((index,item) => {
var typeTxt = cheerio.load(item).text();
classifyName.push(typeTxt);
classify.push(classifyMap[typeTxt]);
orientation.push(orientationMap[typeTxt])
});
let obj ={
_id: new mongoose.Types.ObjectId(),
name: $ele("h3.course-card-name").text(),
cover: cover,
cover_origin: cover_origin,
banner:'',
banner_origin:'',
hard: cheerio.load(hardAndMember[0]).text(),//难度
duration: '',//时长
member: Number(cheerio.load(hardAndMember[1]).text()),//人数
grade: '',//评分
abstract: $ele('.course-card-desc').text(),//简介
chapter: [],
authorid: '',//作者
imglist: [],//图片详情
detail: '',//详情
orientation: orientation,
classify: classify,
classifyName: classifyName,
detailUrl: baseUrl + $ele('a.course-card').attr('href')
};
courses.push(obj);
});
if(pageNum == totalPage){
console.log('课程总长度'+courses.length);
pageGetDetail();
}else{
let nextPageNum = pageNum + 1;
let urlParams = freeCourseUrl + '?page=' + nextPageNum;
getFreeCourses(urlParams,nextPageNum);
}
})
})
}
function pageGetDetail(startPage){
if(!startPage)startPage = 0;
let page = 10;
let eachArr = courses.slice(startPage*page,(startPage+1)*page);
let promiseList = [];
eachArr.forEach((course,index)=> {
var promise = new Promise(function(resolve,reject){
https.get(course.detailUrl,res =>{
let html = '';
res.setEncoding('utf-8');
res.on('data',function(chunk){
html += chunk;
});
res.on('end',function(){
let $ = cheerio.load(html);
let chapter = [];
let chapterEle = $('.course-chapters .chapter');
let teacherEle = $('.teacher-info');
var element = courses[startPage*page+index];
chapterEle.each(function(ind,ele){
let $ele = cheerio.load(ele);
let chapterList = [];
$ele('.video .J-media-item').each(function(ind,item){
let txt = cheerio.load(item).text();
txt = txt.replace('开始学习');
txt = txt.trim();
chapterList.push({
txt: txt.replace(/[ \r\n]/g, ""),
type:'vedio'
});
})
let tempObj ={
header: $ele('h3').text().replace(/[ \r\n]/g, ""),
desc: $ele('.chapter-description').text().replace(/[ \r\n]/g, ""),
list: chapterList
}
chapter.push(tempObj);
})
element.duration = $('.static-item')[1] ? cheerio.load($('.static-item')[1])(".meta-value").text() : '';
element.grade = $('.score-btn .meta-value')[0] ? cheerio.load($('.score-btn .meta-value')[0]).text() : '';
element.intro = $('.course-description').text().replace(/[ \r\n]/g, "");
element.notice = $('.course-info-tip .first .autowrap').text();
element.whatlearn = $('.course-info-tip .autowrap')[1] ? cheerio.load($('.course-info-tip .autowrap')[1]).text() : "";
element.chapter = chapter;
element.teacher = {
name: teacherEle.find('.tit').text().trim(),
job: teacherEle.find('.job').text(),
imgSrc: 'http' + $('.teacher-info>a>img').attr('src'),
img: $('.teacher-info>a>img').attr('src')?$('.teacher-info>a>img').attr('src').split('/').pop():''
};
element.teacherUrl = baseUrl + $('.teacher-info>a').attr('href'),
element.questionUrl = baseUrl + $('#qaOn').attr('href');
element.noteUrl = baseUrl + $('#noteOn').attr('href');
element.commentUrl = baseUrl + $('#commentOn').attr('href');
delete element.detailUrl;
resolve('done');
})
})
});
promiseList.push(promise);
});
Promise.all(promiseList).then(arr => {
if( startPage * 10 > courses.length){
fs.writeFile('./freeCourses.json',JSON.stringify(courses),function(err){
if(err){
console.log(err);
}else{
console.log('freeCourses.json文件写入成功!');
}
});
}else{
let currentPage = startPage + 1;
pageGetDetail(currentPage);
}
})
}
getFreeType(freeCourseUrl);5、执行程序
代码写完,直接在crawler目录下执行node index就可以了。我用的是vscode,贼方便。如果打印出以下的结果就说明成功了。
6、总结
写完这次爬虫感觉挺有成就感的,数据也成功的写到数据库里作为网站的后台数据。过程的难点就是对数据的处理,因为这次虽然是练手,但是我还是把它当做一个正常的项目来做,数据是要提供前端使用的,所以在整理的时候就要小心。总之作为一个码农,不断学习是必要的