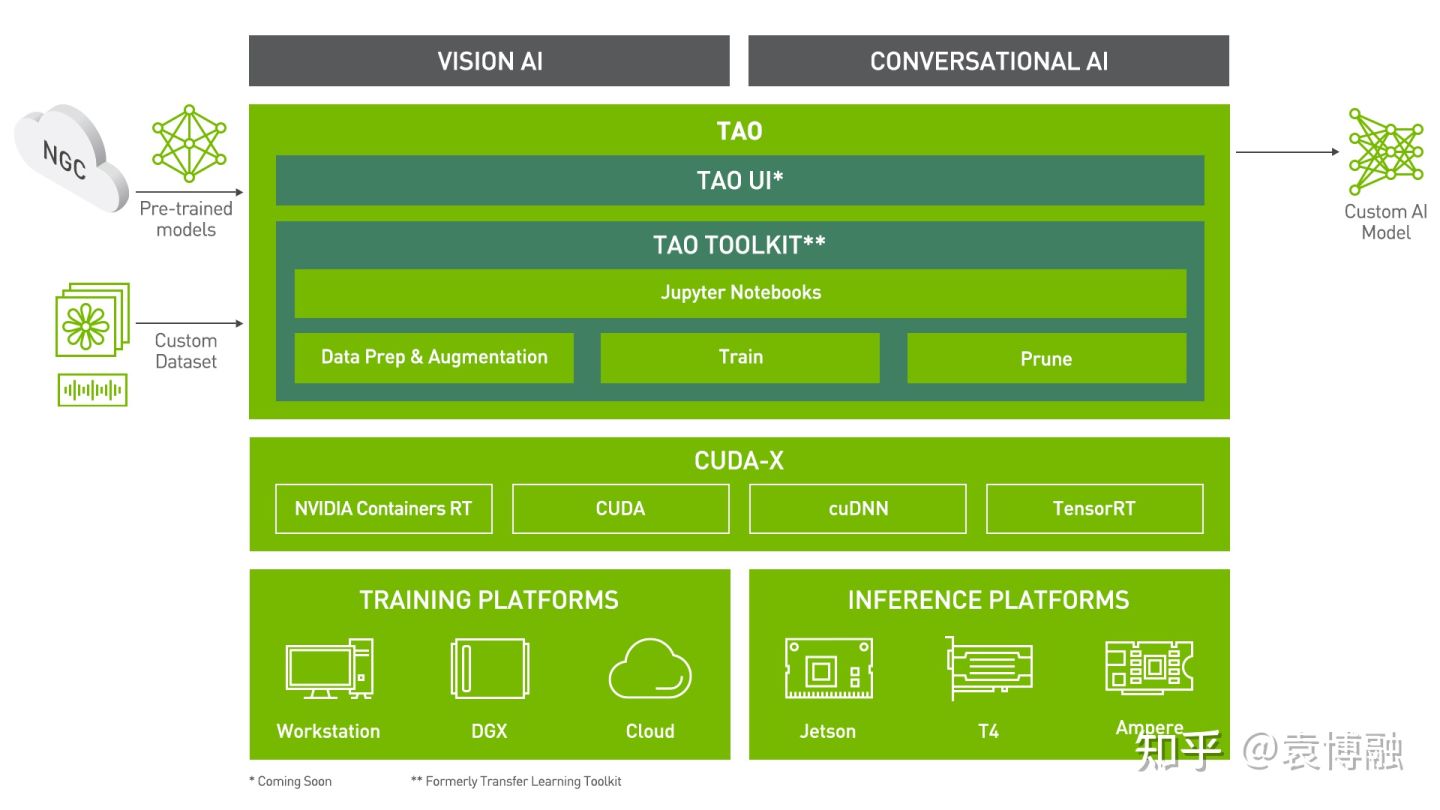
NVIDIA TAO工具套件是一个基于Python的简单易用的AI工具包,用于获取专用的AI模型并使用用户自己的数据对其进行定制。TAO为三个字母的缩写:Train, Adapt, Optimize,这是我们开发AI模型的常见步骤,也代表了其主要功能。
TAO的前身为TLT(Transfer Learning Toolkit)。我在去年也对其进行过介绍,并分享了一些示例。
用TAO工具套件打造超轻超快超准确的口罩检测模型,从训练到部署仅需1天24 赞同 · 4 评论文章正在上传…重新上传取消
近日,NVIDIA TAO又有了一波更新,包括全新和更新的视觉及语音预训练模型,ONNX模型权重导入,REST API和TensorBoard集成等新功能。我也在第一时间进行了体验,并做了一个新的示例分享给大家。这个示例包括了一些官方文档中有介绍,但教程没有覆盖到的内容,因此可以看作是对官方教程的补充。我也同样提供完整的Jupyter Notebook。
在这个示例中,我将展示如何使用最新版NVIDIA TAO快速构建一套用于仓库物流场景的目标检测模型。我们将使用慕尼黑工业大学发布的LOCO(Logistics Objects in COntext)数据集。
https://github.com/tum-fml/locogithub.com/tum-fml/loco
LOCO: Logistics Objects in Context
Mayershofer, C., Holm, D.-M., Molter, B., Fottner, J.
IEEE International Conference on Machine Learning and Applications (ICMLA) 2020
该数据集包括了在多家公司仓库中采集的39101张图片,其中5593张完成了5类目标,151428个实例的标注。目标包括托盘、料箱、仓储笼三种常见容器,及叉车、地牛两种常见运输工具。检测这些目标对于仓库物流场景是非常有价值的,既能帮我开发更智能的AGV/AMR,又有助于提高仓库的安全性。

之前的专栏文章中已经展示过如何使用NVIDIA的DetectNet_v2来开发口罩检测模型。这此我使用大家更为熟悉的YOLOv4-tiny在LOCO数据集上进行训练。这也便于我们将使用TAO的训练结果与LOCO论文中的YOLO实验进行对比。
首先我们需要安装TAO。最简单的方式是使用我们Jupyter Notebook第1节的脚本,但我更建议根据你自己的开发环境来手动安装,同时也看一下新版TAO的架构。相较于去年TLT 2.0最大的变化是,我们使用TAO时不再直接在Docker容器内操作,而是在主机上通过TAO Launcher Python包和Docker进行交互。
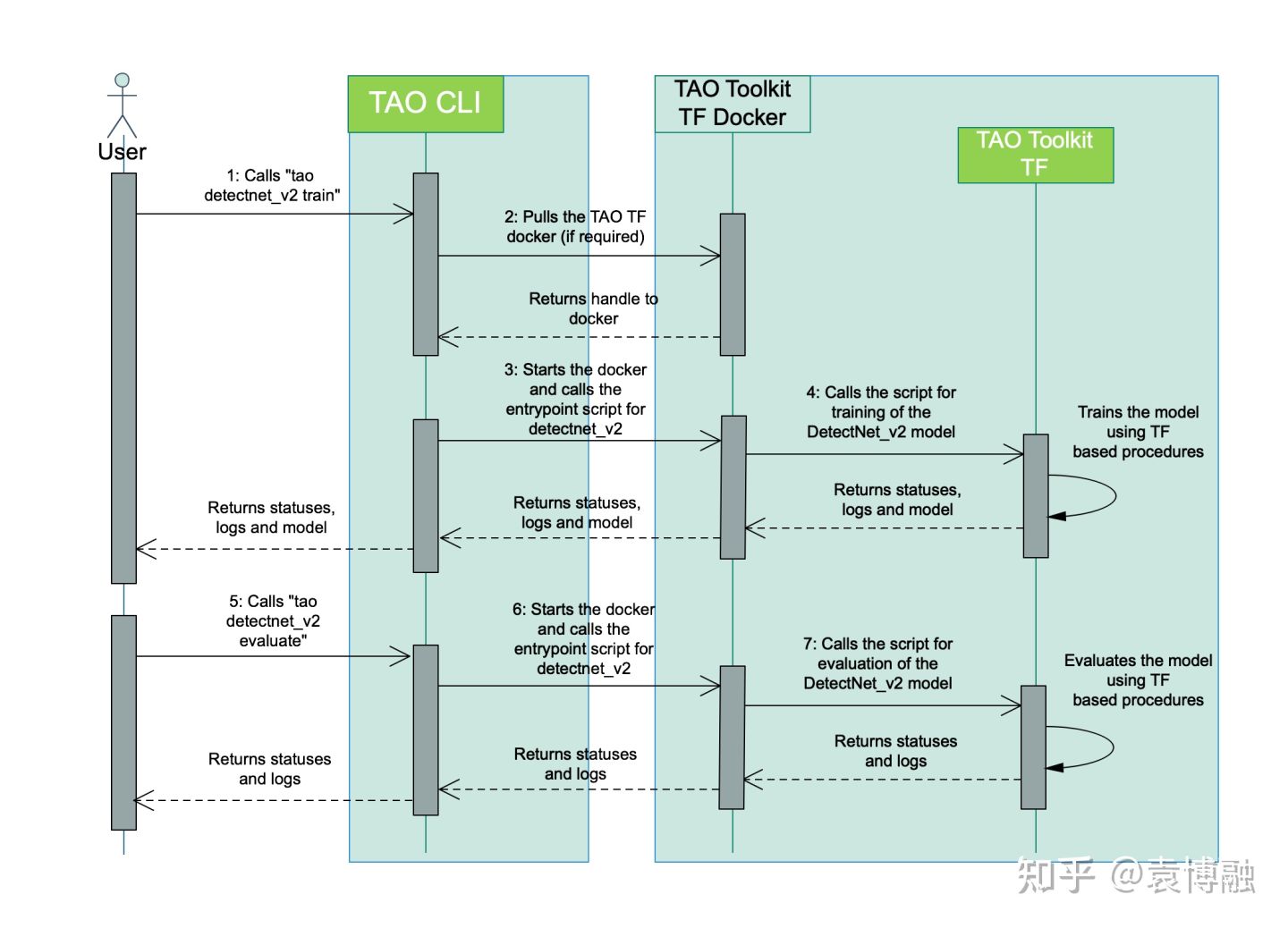
因此我们在主机上运行Jupyter Notebook,参数配置也在主机上,运行容器时只需挂载数据目录和实验目录。而容器运行也通过TAO Launcher来管理。TAO Launcher还会根据任务的需要自动从NGC上拉取所需容器镜像。这些改变进一步减少了开发时配置和命令的代码量,也更好地避免了潜在的版本和依赖问题。
安装TAO非常容易,其依赖有两部分:TAO Launcher所需的Python依赖和NVIDIA容器栈。从Python包的wheel文件可以发现,尽管相对于上一版只有小版本号的变化,但Python依赖精简了很多。因此可以不必像官方文档那样创建Python虚拟环境,直接用下方命令在主机Python环境中安装即可,基本不会影响其它Python包的版本。
pip3 install --upgrade nvidia-tao关于NVIDIA容器栈,我在之前的专栏文章中也介绍过其架构和安装。不过除了NVIDIA的官方仓库,我们安装还有另一个选择,使用Lambda Labs推出的Lambda Stack。这是一套方便在Ubuntu上安装的AI全家桶,包含了NVIDIA驱动、CUDA、cuDNN、NVIDIA容器栈、TensorFlow、Keras、PyTorch、Caffe、Caffe 2等一系列组件。当我们之后需要TensorBoard可视化时,就可以从Lambda Stack中安装。
然后我们需要准备一下训练数据。对于目标检测任务,NVIDIA TAO目前支持两种标注格式,KITTI和COCO。LOCO数据集使用了COCO标注,因此是被支持的。我们只需使用Jupyter Notebook第2节的脚本将其转换为TFRecords即可。LOCO数据集已经被划分为了5个子集,其中2、3、5为训练集,1、4为验证集。我们直接沿用这样的划分。当然,大家也可以根据自己的需要重新处理这套数据或使用其它数据。在AI模型生产过程中,数据集的生产、管理、维护也是非常重要的一个环节。NVIDIA之前也介绍了多种可以和TLT集成的工具。
除了链接中所提到的工具,如今热门的还有Diffgram,CVAT,Roboflow等。我们可以先将LOCO导入Roboflow看一下。Roboflow便于我们查看和整理数据,重新标注、划分,在多种标注格式间转换,添加预处理及增广等。
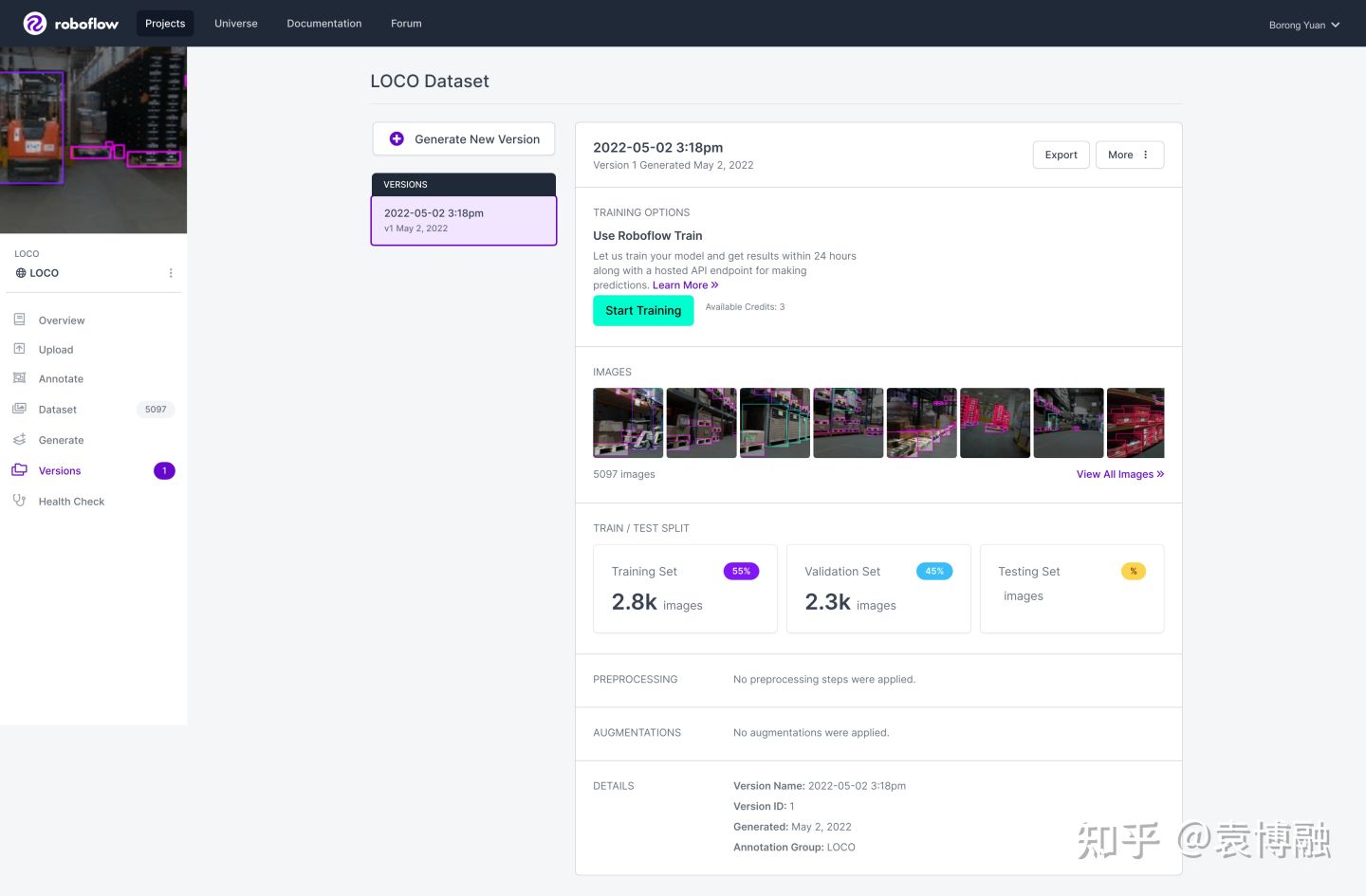
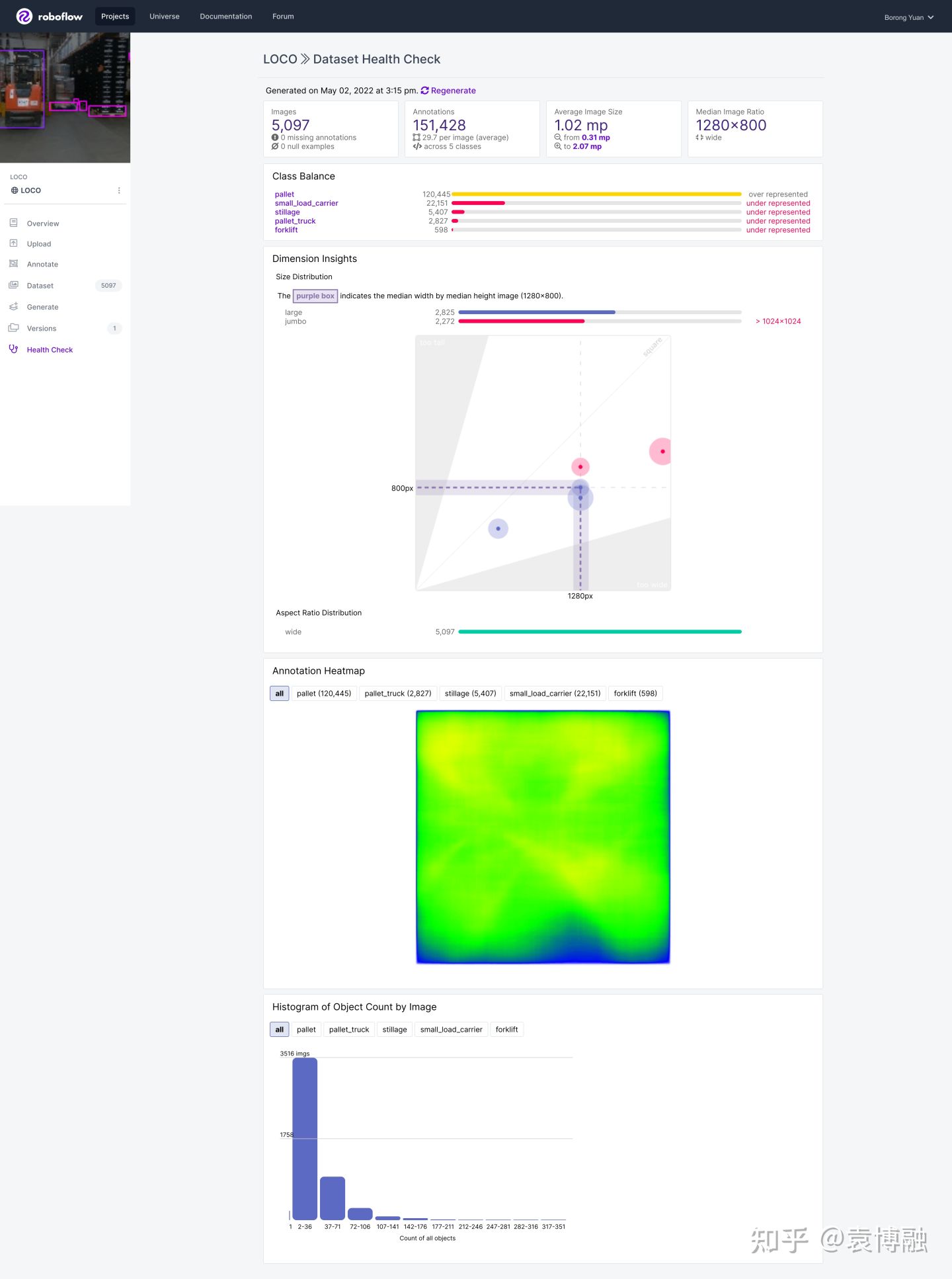
可以看到有2.8k张训练集图片和2.3k张验证集图片。样本有明显的不均衡,仓库中的托盘显然比其它目标要多不少。这对模型也提出了一定的挑战。LOCO数据集使用了5种不同的相机来采集,以提高数据的丰富性,分辨率中位数为1280×800。因此我们训练模型时使用640×384的输入,保证长和宽是32的倍数且接近样本图像的比例。
接下来我们还需要准备预训练模型。在Jupyter Notebook中会先下载NGC Registry CLI,然后再通过其下载cspdarknet_tiny。
TAO中YOLOv4-tiny的训练参数与Darknet中的基本一致,我也基本没有做修改,只是重新计算了anchor shapes。我们希望最终得到一个用于INT8推理的模型,因此使用量化感知训练(QAT)。需要注意的是,在使用QAT的过程中,模型中的很多节点会被替换为支持权重伪量化的节点,并插入量化和反量化(QDQ)节点,而激活函数除了输出节点外都会被替换为ReLU-6。YOLOv4的Trick之一就是使用了Mish激活函数,因此QAT的操作可能会对模型精度略有影响。但从另一方面来说,这对模型性能是有好处的。首先,Mish的计算量更大。其次,这里相当于使用了force_relu参数,如果模型最终部署在Jetson平台上使用NVDLA,保证了激活函数都是DLA所支持的,不会出现Fallback影响性能。为了提高Volta及后续架构显卡上的训练性能,我们还使用了自动混合精度训练(AMP)。我们也开启了可视化功能,当训练启动后就会在实验目录下生成logs。然后我们就可以在主机上启动TensorBoard。
tensorboard--logdir=/path/to/logs


在TensorBoard中可以看到训练损失、mAP、经过增广的图像、权重直方图等信息。需要说明的是,这里看到的图像经过了Mosaic增广。而目前使用TFRecords格式时,Mosaic增广会减慢训练速度并消耗大量内存,因此在训练参数中默认将其关闭。相信NVIDIA会在之后解决这个问题。但我们也可以预先做离线数据增广,TAO也提供了这部分功能。也可以在之前提到的Roboflow中做Mosaic增广。
经过训练,我们最终得到的mAP如下:
| Darknet YOLOv4 | Darknet YOLOv4-tiny | TAO YOLOv4-tiny | |
|---|---|---|---|
| [email protected] | 41.0% | 22.1% | 21.0% |
| 料箱 | 27.7% | 18.1% | 12.7% |
| 托盘 | 65.0% | 36.2% | 35.0% |
| 仓储笼 | 53.1% | 31.3% | 26.6% |
| Forklift | 31.3% | 11.6% | 15.6% |
| Pallet truck | 28.1% | 13.3% | 15.0% |
可以看到这和论文中的实验结果是相近的。考虑到我们没有使用Mish激活函数和Mosaic增广,略有些损失是正常的。
最后,我们尝试对模型进行剪枝,进一步压缩其大小。由于YOLOv4-tiny本来就是小模型,可压缩的程度没有ResNet那么大。当剪枝阈值设为0.8时,仍能剪掉大约1/4。对剪枝后的模型再进行训练,最终达到的mAP如下:
| Darknet YOLOv4-tiny | TAO YOLOv4-tiny | Pruned YOLOv4-tiny | |
|---|---|---|---|
| [email protected] | 22.1% | 21.0% | 20.5% |
| 料箱 | 18.1% | 12.7% | 12.6% |
| 托盘 | 36.2% | 35.0% | 34.7% |
| 仓储笼 | 31.3% | 26.6% | 23.6% |
| 叉车 | 11.6% | 15.6% | 17.7% |
| 地牛 | 13.3% | 15.0% | 14.1% |
剪枝后的模型经过重训练依然能恢复到与原模型相当的精度。训练好的模型可以导出为etlt文件,使用DeepStream部署,或进一步导出为TensorRT engine。
在这个示例中,我们使用了LOCO的标注直接在TAO中进行训练,代码量非常小。我们也在为这套数据进行重新标注,以开发机器人自动识别对接这些常见容器的功能。欢迎有兴趣的朋友前来咨询。而NVIDIA TAO除了目前的低代码工具套件,也将在之后推出有图形界面的零代码方案。有兴趣的朋友可以申请提前试用。我们之后可能也会跟大家再分享这部分内容。
NVIDIA TAO (GUI VERSION) - EARLY ACCESSdeveloper.nvidia.com/tao-early-access