M竞赛是围绕时间序列预测的著名竞赛,每年举办一次,今年的M6是金融预测大赛,本文分享我们团队Q1预测第10名的方案,同时也包含赛题介绍和后续比赛可尝试方向(比赛还在持续进行中)。该量化比赛的评估方式和预测任务都很值得学习。关于此文,不足之处,还望批评指正,我们也希望之后能看到更多各位的高分方案。
一、比赛介绍
M6官网:https://m6competition.com/
赞助商:Google、Meta、J.P.Morgan等
M竞赛是围绕时间序列预测的著名竞赛,每年举办一次,今年的M6是金融预测大赛,侧重于股票价格(回报)和风险的预测,为 EMH(有效市场假设)提供新的视角。
有效市场假说●●
有效市场假说 (The efficient market hypothesis,EMH) 假设股价反映了所有相关信息,这意味着市场持续表现优异是不可行的。EMH 得到实证证据的支持,包括晨星的年度“主动/被动晴雨表(Active/Passive Barometer)”研究,该研究经常发现专业投资经理,平均不会击败随机的股票选择。另一方面,沃伦·巴菲特、彼得·林奇、乔治·索罗斯等传奇投资人,以及黑石、桥水、文艺复兴科技、德肖等知名企业,在很长一段时间内取得了惊人的成绩,积累了返回不可能仅仅靠偶然性来证明,并对 EMH 的有效性产生怀疑。[1]
1. 预测目标
一共100个资产,分为两大类:50个 S&P 500,50个全球ETF。我们要预测这100个资产在未来四周后最后一个交易日的收盘价(以收益排名Rank为目标)和每个资产的投资权重。
2. 提交格式
具体提交格式如下:
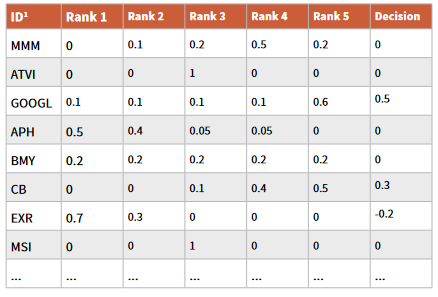
图1:M6提交格式样例
提交一个文件,包含100行*7列,其中,
● 第1列:资产ID,用对应的缩写表示;
● 第2-6列:Rank 1-5,分别代表最低收益率 ~ 最高收益率(具体间评估函数)。Rank 1-5之和要求必须为1,且均为非负,如果不等于1则记为无效。如果提交无效,可以重新提交;
● 第7列:投资决策,代表了对每个资产的投资权重,可以为负。正数代表看多,负数代表看空,0代表不买入。投资权重绝对值之和不大于1,且不能小于0.25,以图里为例,代表投资了0.5+0.3+0.2=1。如果大于1或小于0.25,则本次提交无效;
● 少于100行的提交无效。
做空做多●●
做多就是估计后市要涨,于是买入合约,日后价格涨了后,以高价卖出合约。赚取差额利润。做空就是估计后市要跌,于是卖出合约,日后价格跌了后,以低价买入合约。赚取差额利润。[4]
注:
● 如果在某个提交周期未提交预测和投资决策,赛方会延用上一周期提交的预测和决策;
● 若每个季度首月未提交,且之前没提交过,当季度取消资格;
● 只要某单季度被取消资格,年度奖项对应取消资格(获得年度奖项必须每个月都要提交预测和决策)。
3. 评估函数
(1) 预测评估指标:Ranked Probability Score (RPS)
资产当月真实收益排序的计算方法:
● 100个标的资产按实际收益从低到高排序,均分为1-5组。例:收益最低的20个标的,rank=1,收益最高的20个标的,rank=5;
● 若存在相同收益的标的,采用average rank。例:如果有4个标的资产同时排在第18位,那这四个资产的 rank=(5+5+5+4)/4=4.75。有3个资产可以排在前20,有1个资产排在21-40,所以公式中有3个5分,1个4分;
● 每个标的资产的收益ranking,可以用 来表示, 的维度为 1x5。其中i代表第i个标的,T代表第T个月;
● 如果不存在相同收益的标的,那么对于某个资产来说,在对应的分位中为1,其余为0。例:某个资产的收益在T周期处于第3个分位,则对应的 ;
● 如果存在相同收益的标的,则用小数来表示 ,使其加权和等于其average rank。例:上面4个标的资产同时排在第18位,则其rank=4.75,对应的 ,加权rank的计算方法为 。
单个资产的评估: 其中 代表真实收益排序, 代表选手提交的排序。
对于T月份,选手提交的 为100个资产 的平均数:
对于多个月( 月至 月)的提交结果评估, 则为 月至 月每个月的 平均数: 理论上RPS越低越好,0代表完美预测。
例:在某时刻T,选手提交的资产 i 的排序为 ,该资产的实际排序 ,那么 计算公示如下:
(2) 投资决策评估指标:Information Ratio (IR)
IR为: 其中ret代表投资组合的累计收益,sdp代表投资组合收益(按日)的标准差standard deviation。
单日投资组合的收益: N代表组合投资的标的个数, 为标的在投资组合中的权重,S为收盘价(adjusted closing price)。
累计收益为每日收益(%)的加和, 到 之间的总收益和其对应的标准差可以计算为,注意下面的计算都是年化收益率和年化波动率:
例:计算选手提交的IR,首先周期内获得20个交易日的实际收益 ,计算20天的总收益 ,20天的波动率 ,则 。我们可以简单理解如下:我们现在知道t在第一天累计到第20天的收益率为0.01,那么平摊到每天,日收益率为0.01/20,一个月有21个交易日,那么一年的收益率为: ,另外,一年的交易日数量为252天,所以年波动率= *日波动率。
(3) 总体评估指标:Overall Rank (OR)
OR为: 这里的rank是选手在当次所有参赛者中的排名。
二、数据探查
由于组织方只提供关于资产的元数据,不提供详细资产的市场数据,所以需要选手自行使用外部数据集(在数据、特征和模型上给了充分自由度)。在首月,组织方使用了Yahoo Finance[4]的数据作为真实标签评估选手的预测结果,所以我们一开始便选用了雅虎的数据,分别尝试selenium爬虫和调用pandas读雅虎的接口,都无果后,首2月还是采用了低效的人工的采集方式。其中,使用selenium,模拟浏览器点击download按钮,但browser.find_element(by=By.XPATH,value=[XPATH]),只返回一个含ELEMENTS键的字典,怀疑是反爬虫机制。另外,直接调用pandas_datareader.data.web接口直接读取yahoo数据,但也存在反爬机制,每次爬几个asset后便会报错:MaxRetryError,好像也是有爬虫访问限制。
在第二个月,人工下载yahoo数据时,发现yahoo数据存在以下问题:
● 时间格式不统一,例如2022-04-01和2022/04/01;
● 出现空值。
● 与历史爬取的数据对不齐,Adjusted Close收盘价有超过5%的偏差(可能是股票分红分割导致调整收盘价的计算受到影响),集中在资产代码后缀为.L的资产(该类资产不在美国交易所,都在欧洲交易所),如图2所示。
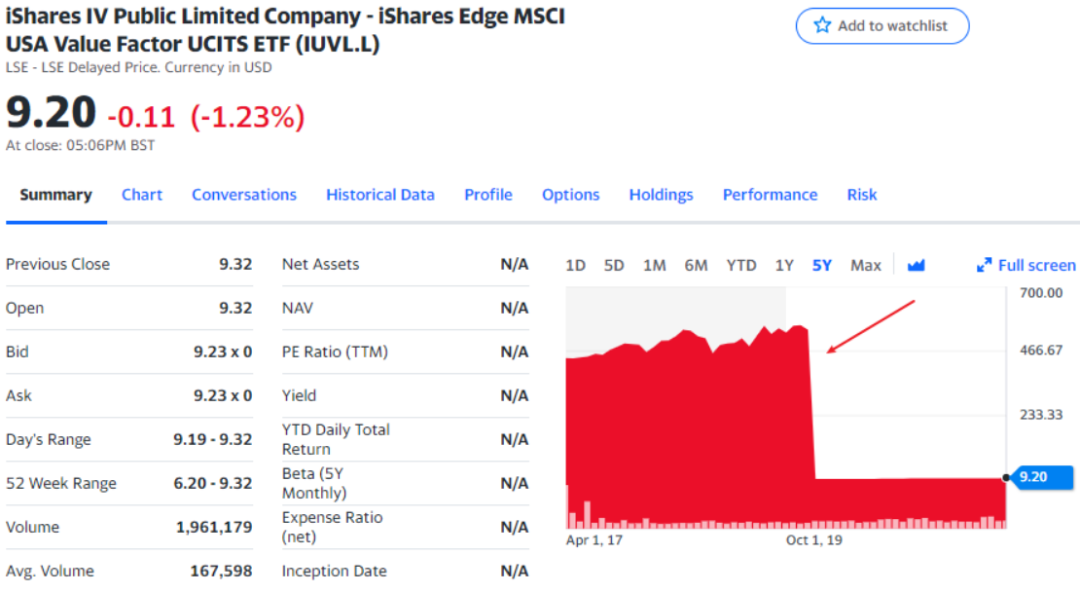
图2:Adjusted Close收盘价异常
后面,M6官网faq(Frequently Asked Questions)做出更新,赛方指出:Originally, the “Yahoo! finance” API was used for that purpose but was later replaced by the “EOD Historical Data” one since the former was unreliable for part of the assets. 起初是用Yahoo finance数据,但发现部分资产的数据不可靠,后面更换为EOD Historical Data(EOD)[5]作为数据源。
EOD的数据接入要付费,试用版只支持每日请求20次,且只能读取过去一年的数据。基于我们的需求,第3个月,我们购买了$19.99的付费数据接入服务,只获取基础的历史数据(开盘、收盘、最高/低价和股本数量)。

图3:EOD产品价目表(EOD Historical Data:最基础的历史数据;EOC+Intraday:日内数据;Fundamentals Data:基本面数据;ALL-IN-ONE:包括基础历史数据、日内交易数据和基本面数据)
对于EOD Historical Data的数据,他们有提供Python基础版API[6]可以直接调用,3-4分钟便能获取到100个资产近5年的历史数据。
由于时间有限,并未过多开展数据探查工作,只是初步查看了下资产的分布情况,大部分单日下,有超过80个asset,但也有极端少的情况,例如2017年9月4日,只有7个资产。一方面可能是不同交易所的节假日开/休市有所区别,另一方面,早期有些资产还没上市,中间也有可能存在资产被交易所停牌。
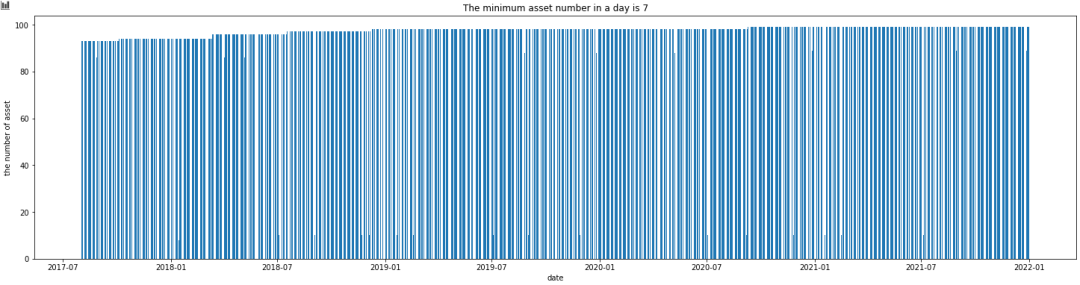
图4:近5年的资产数量分布
不同行业大类和子类下,资产数量分布呈长尾状态。其中,大类有15个,小类有60个。

图6:各类下的资产数量分布
三、特征工程
因为我们原始数据很简单,所以挖掘稳健的特征因子,对于量化模型来说很重要。一方面基于先验挖掘新特征,能提高模型学习能力和表现,决定模型的上限,另一方面,选择合适的特征,能有效避免模型在不可见数据集上与本地表现不一致。我们原始数据如下:
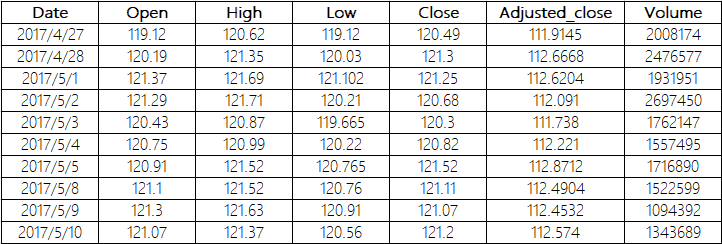
图7:原始数据样例
1. 特征生成
我们特征工程挖掘的特征如下图所示:
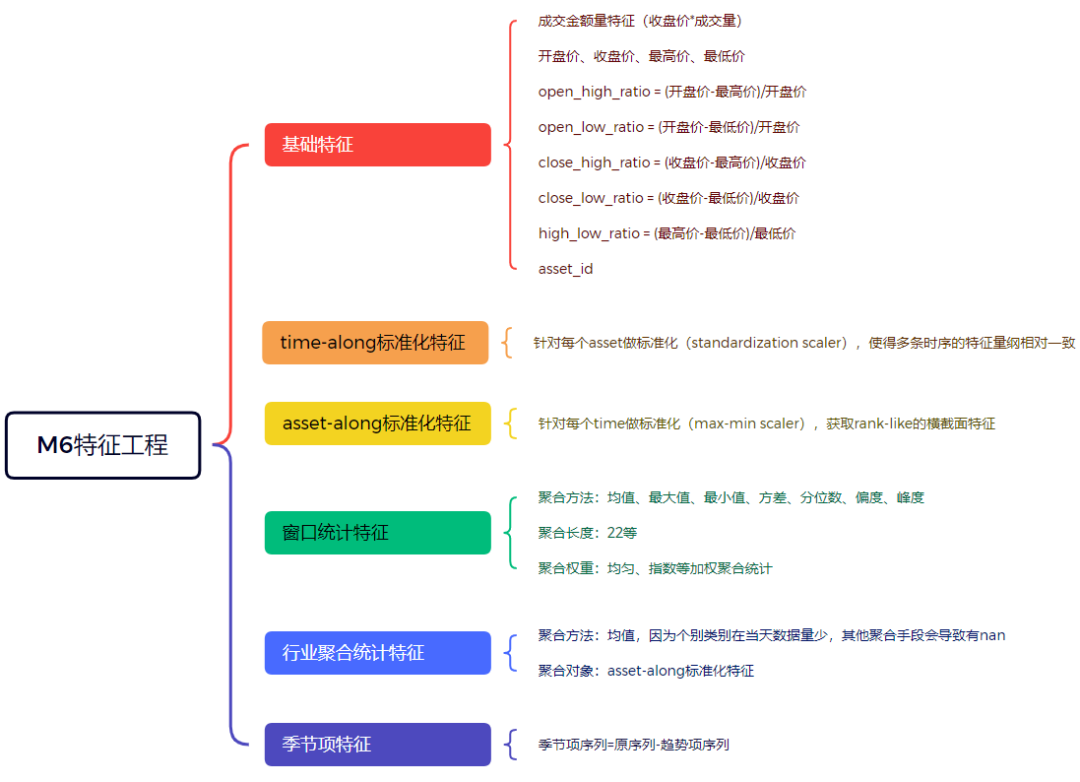
图7:M6生成的特征
(1) 基础特征
对于原始特征,我们做了特征交互,扩充了基础特征库,例如成交量(元)特征(成交规模)和价格波动比率(一定程度反应市场情绪波动),后期在输出LGBM特征重要性也发现,价格波动比率还是比较重要的。
(2) time-along标准化特征
针对每个资产,用训练集日期下的数据拟合标准化scaler,再对验证集和测试集做标准化转换,尽可能使多条时序的特征值量纲差异不大,更利于模型学习。
(3) asset-along标准化特征
由于预测的多分类(Rank1-5)目标本质上是asset-along的横截面变量,所以我们也针对每个时间点下,最大最小缩放不同资产的特征值,以获取rank-like的横截面特征。同时,因为考虑特征稳定性,max-min标准化的目标是针对窗口聚合统计后的特征值。
(4) 窗口统计特征
这里暴力对扩充后的基础特征,进行窗口聚合统计,聚合方法有:均值、最大/小值,方差、分位数(0.2/0.5/0.8),偏度和峰度,另外,我们也支持多个聚合长度,例如11,22和44天。实验发现,短中长期特征合并后,若不做特征选择,模型效果会变差。自变量相关性分析发现,短中长期特征相关性很强,可能会导致特征多重共线性问题。对此分别尝试PCA特征降维和特征选择,模型效果跟在中期特征下的模型表现差不多。
(5) 行业聚合统计特征
官方提供100个资产的元数据,其中含有各资产的第一类别和第二类别,我们针对不同行业类别,对同一时间点下的聚合均值统计的特征(包括time-along和asset-along的特征)做进一步的聚合均值统计,获取行业聚合均值统计特征。但聚合时,发现个别类别下的只有单个资产,导致无法做出了均值统计外的其他统计,而且单资产的行业做聚类统计没有意义,反而容易带来特征冗余。
此外,直接将行业特征embedding加入模型,会使模型过拟合,对测试集的泛化性产生负面影响。
(6)季节项特征
原序列减去当前时间点下历史滑窗的平均值,便等于季节项特征(当然这里不太严谨,因为里面还有残差项序列的成分)。
2. 特征筛选
在时序中,特征也许是具有时效性的,比如在某些市场环境下,股票的收益更看重公司的市盈率,另外的行情时,有看重换手率。本质上,可以反映为:在时间上,特征与目标变量之间相关性的不稳定,为此,我们做了一些相关性分析,帮我们找到这些时间上不稳定的特征,剔除它们,并让模型更加鲁棒。
基于相关性的稳定性,特征筛选工作如下:
● 先对训练集数据,每月统计各特征与target的相关性;
● 统计各个特征的月度相关性的标准差;
● 设置相关性的标准差的阈值,提出top不稳定性特征。
图8展示的是随时间变化下,各特征与target的相关性变化:
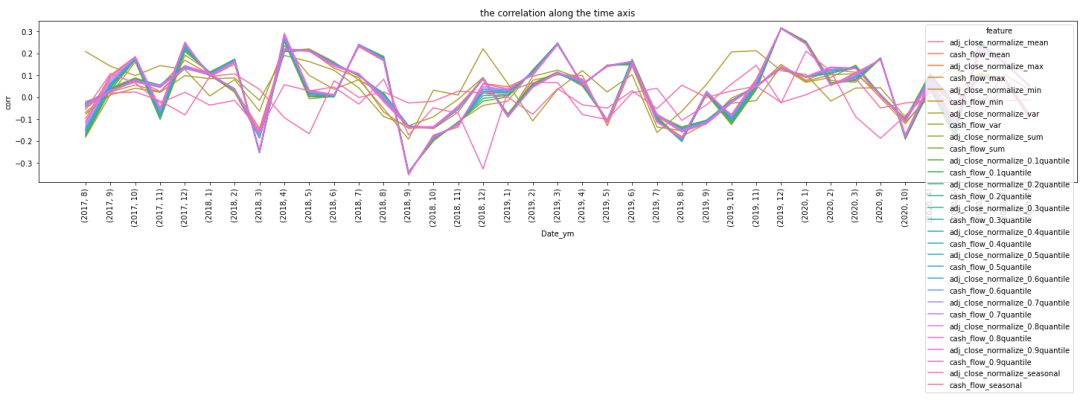
图8:各特征与target的相关性变化(这里是旧的特征工程下,特征相关性展示,仅供思路参考)
图9展示的是各特征与target的月度相关性的箱线图(即,相关性的稳定性):
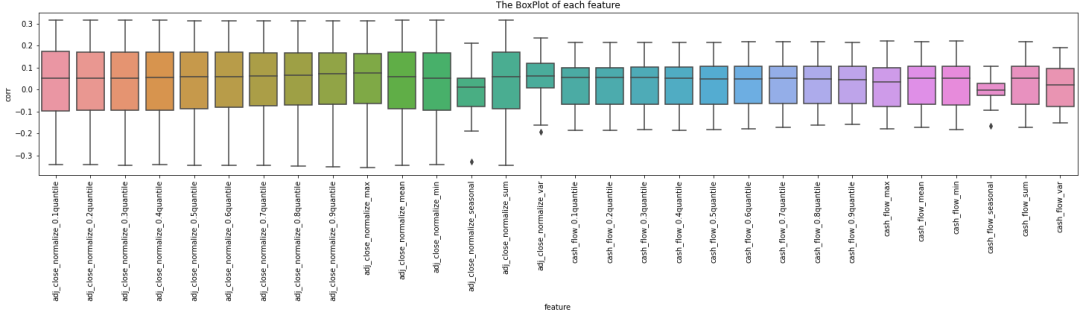
图9:各特征与target的月度相关性的箱线图(这里是旧的特征工程下,特征相关性展示,仅供思路参考)
实验发现,剔除相关性不稳定的特征,能提高预测表现。
四、模型
在正式讨论模型前,我们先介绍下,我们采用了Time Series Split的数据划分方式,保证训练集、验证集和测试集不会出现时间穿越。注意,由于我们标签是四周后的收益率,所以训练集和验证集之前,为了避免训练集的标签含有验证集的信息,这里中间隔开了四周交易日。
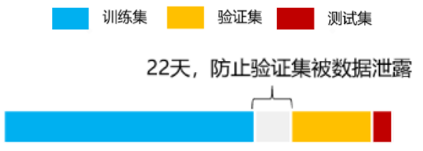
图10:Time Series Split
模型这块,我们尝试了统计模型、逻辑回归、树模型、DNN和Transformer。
1. 统计模型
如果我们对Rank1-5直接均匀分配0.2,overalRPS为0.16,而采用直接取历史所有的return统计平均值和方差,然后高斯采样后,对采样结果求均值,再Rank。结果在0.160+-0.0058,跟随机预测的效果没什么差异。
2. 逻辑回归
使用逻辑回归做多分类任务预测,且单资产建模。实验结果反映明显出现过拟合现象。对比预测Rank和真实Rank分布,预测严重有偏。
3. 树模型
关于树模型,使用LightGBM,基于验证集表现,做早停。我们对比了针对asset单独建模和不针对asset单独建模,在不针对asset单独建模下,在lgb.Dataset中声明categorical_feature='asset',给模型引入资产id信息。
单独建模存在过拟合风险,在单独建模训练时也发现,由于单asset的数据长度比较短(训练集大概600-700个样本),基本1-3轮就早停结束了。另外,由于单独建模比较耗时,所以后面我们便没有单独建模。
除了,将预测目标当做多分类任务要预测,我们还尝试预测第四周的收益均值和标准差,思路如下:
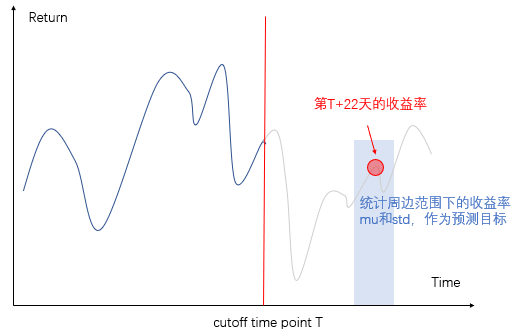
图11:获取新预测目标-收益率均值和标准差
之后基于预测的mu和sigma,高斯正态采样多次return,并对多次采样的return,转为rank再取平均值,作为最终提交结果。而建模时,我们采用MT-GBM(多任务梯度提升树)[7],进行多任务学习。
实验中发现:
1. 使用跟作者开源回归代码中的RMSE作为目标和评估函数,比KL Loss更好些,但RPS远不如直接预测rank的表现好。
2. 在训练模型时,第一轮模型会用0初始化预测结果,在KL loss求导时,sigma一阶梯度(grad_sigma)会因此变很大,人工对mu和sigma梯度进行加权平衡,也没起到作用。
3. 多目标任务学习看重两个点:(1)任务之间的相关性 和 (2)不同任务对应loss的量纲,loss要尽量保证在一个范围内,不然loss范围大的loss自然就会更被模型青睐。为此专门看了mu和sigma的相关性是0.03左右,很低。所以mu和sigma不适合用于多任务学习的目标。
总结来说,MT-GBM效果不好的主要原因还是多目标之间的相关性弱,即使后面我们针对mu和sigma单独建模,虽然比不上多分类任务,但结果更好些。
4. DNN
DNN的模型代码如下,代码参考了Kaggle九坤比赛[8],网络设计思路很简单:
● asset_id → id embedding;
● feature → feature embedding;
● id embedding + feature embedding → decision making。
效果比LGBM好。此外,由于金融数据信噪比较低,为了提取出真正有价值的信息(即特征),尝试加入AutoEncoder对数据降噪,模型参考Kaggle Jane比赛 [9],模型结构示意图如下:
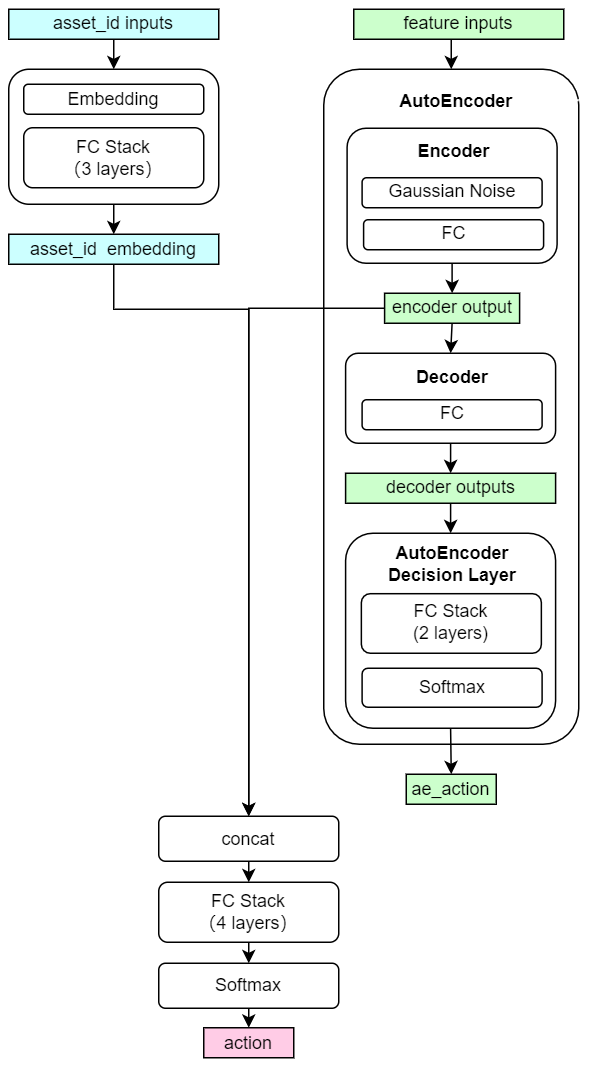
图12:DNN with AutoEncoder
模型效果跟不加AutoEncoder的DNN,略好一些。
5. Transformer
将Transformer最后一层映射层改为多分类输出,效果不好,我们还针对不同参数做了调整。其中dr是dropout rate,e_layers是encoder层数,seq_len是输入的时序长度,temporal_embedding是时间embedding,d_model是特征抽取后的维度。
实验中发现:
(1) Transformer很容易过拟合训练集,seq_len越小,越容易过拟合。减少e_layers不能起到很好的效果,但适当增加dropout rate还行。
(2) Transformer会对Date抽取时间特征,其中freq='d'下的特征是:DayOfWeek, DayOfMonth, DayOfYear,得到特征后会做embedding后喂入模型。在删去temporal_embedding后,过拟合有所缓解。
(3) d_model和n_head的减少,虽然在训练和测试都减缓了过拟合,但测试集表现不行。
总体来说,Transformer过拟合严重,不适用于M6量化数据集。
6. 模型融合
模型融合方案,对DNN、LGB、DNN和DNN with AutoEncoder采用平均求和融合方式,验证集和测试集没啥提升,当前特征下,模型有些到瓶颈了。
五、投资组合决策
在投资组合决策上,我们考虑了两种方法:
● Markowitz:马科维茨组合模型;
● DE:差分进化算法。
1. 马科维茨组合模型
资产配置主要解决的问题是:如何分散投资从而在风险最小化的同时收益最大化。本次比赛投资决策的评估函数,计算组合收益的return和sd比值,本质上可以理解为是maximize夏普比例。
关于夏普比例,金工里有一个很经典的的理论,即Markowitz theory。简单来说,马科维茨组合模型认为,过去的平均风险和收益,代表了未来的波动和收益。所以,在给定一定风险的情况下,可以结出给出预期最高的收益组合;反之,在收益一定的情况下,可以解出风险最小的组合,详见[10]。
其中,限定收益的情况下,求最小的风险,可以表示为下式:

w代表组合的权重,C代表组合的协方差矩阵,求最小的风险需要满足三个条件:权重之和等于1,资产组合收益大于 。
在允许看空的情况下,不同权重下的资产组合的平均收益与方差为下图中蓝色的点,其中橙色的部分组成了有效前沿efficient frontier,根据不同的风险承受能力,选取橙色曲线上的点。
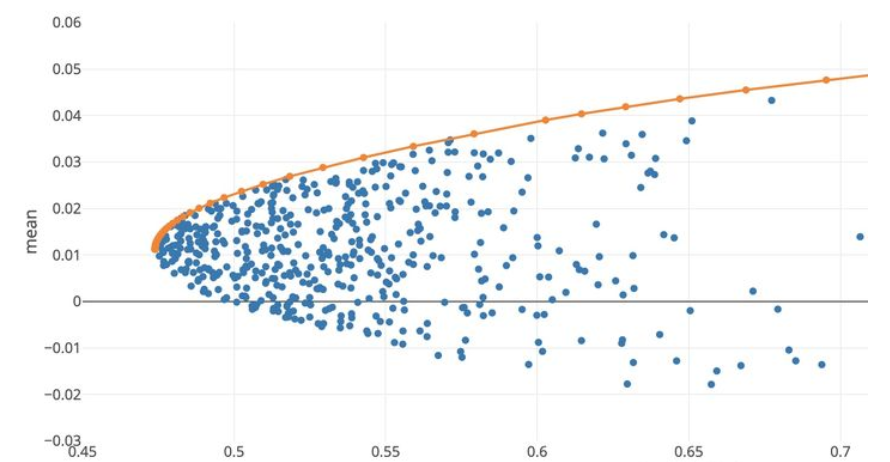
图13:有效前沿(横坐标:风险,纵坐标:收益)
2. 差分进化算法
针对最小化问题,经典DE在求解过程中,一般包含4个步骤:初始化(initialization)、变异(Mutation)、交叉(Crossover)和选择(Selection)。详见[11]。

图14:经典DE,生成试验向量示意图
初始化的种群内每个x就是一组所有资产的决策权重组合:
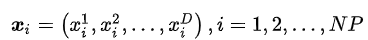
变异时,先随机挑选两个向量,然后做差分获取差分向量,乘上缩放因子后,加上基向量:
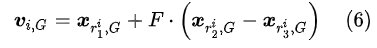
交叉时,在交叉概率下,随机交叉变异向量和目标向量,最后获取试验向量:
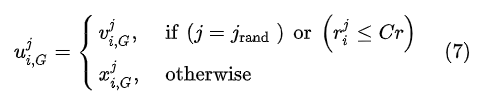
选择时,比较试验向量和目标向量对应的目标函数,目标函数较小的对应向量可以保留到下一代:
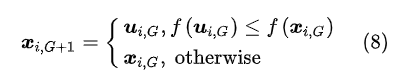
经典DE优化2维Schwefel函数时,变量向量演化图如下:
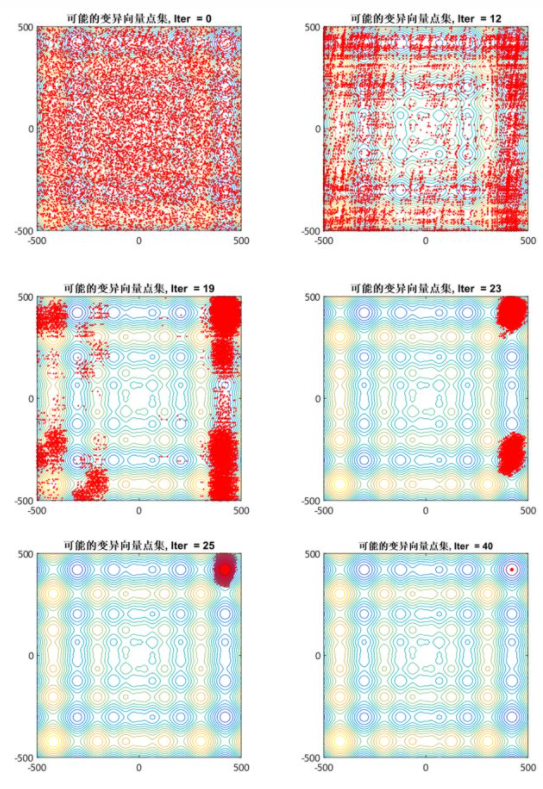
图15:经典DE优化2维Schwefel函数时,变量向量演化图
在决策时,我们一方面会考虑组合的在过去几个月的IR稳定性,另一方面也考虑近期IR的表现是否较为优异。
六、总结
M6三个月比赛下来,感觉更依赖于特征和决策。关于特征部分,当前基础特征不够丰富,导致特征工程即使暴力做,给模型带来的提升还是有限,模型侧再怎么做优化,也带来不了明显的提升。关于决策部分,决策在线上LearderBoard的波动方差很大,基于目前的表现来看,预测表现相对可控,但决策总体表现都不太好,反而在第2个月表现还不错。后续可以深入的方向是:挖掘更多的因子和优化现有投资组合策略。
出于公平性考虑,本篇文章不公开代码和具体实验的分数结果,只分享思路,仅供参考。同时,也感谢团队成员对该比赛的付出,祝参赛的朋友都取得令自己满意的成绩~
参考资料
[1] M6 官网 - M6,网站:[https://m6competition.com/
[2] M6 Guidelines - M6,文档:https://mofc.unic.ac.cy/wp-content/uploads/2022/02/M6-Guidelines-1.pdf
[3] 做多做空 - 百度百科,百科:https://baike.baidu.com/item/做多做空/2775670?fr=aladdin
[4] Yahoo Finance,官网:https://finance.yahoo.com/
[5] EOD,官网:https://eodhistoricaldata.com/
[6] EOD python基础版API,文档:https://github.com/femtotrader/python-eodhistoricaldata
[7] MT-GBM,论文:https://arxiv.org/abs/2201.06239
[8] Kaggle Ubiquant Market Prediction with DNN,代码:https://www.kaggle.com/code/lonnieqin/ubiquant-market-prediction-with-dnn
[9] Kaggle:Jane Street 1st on LeaderBoard Notebook,代码:https://www.kaggle.com/code/vikazrajpurohit/jane-street-1st-on-leaderboard-notebook
[10] 深入理解马科维茨投资组合(已更新) - sleepywyn,文章:https://zhuanlan.zhihu.com/p/353421604
[11] 特邀嘉宾 | 科普差分进化算法(创新奇智运筹优化算法工程师朱小龙博士),文章:https://zhuanlan.zhihu.com/p/332351949
推荐阅读:
公众号:AI蜗牛车
保持谦逊、保持自律、保持进步

发送【蜗牛】获取一份《手把手AI项目》(AI蜗牛车著)
发送【1222】获取一份不错的leetcode刷题笔记
发送【AI四大名著】获取四本经典AI电子书