一、面向对象的概念
面向对象最重要的概念就是类(Class)和实例(Instance),必须牢记类是抽象的模板,比如Student类,而实例是根据类创建出来的一个个具体的“对象”,每个对象都拥有相同的方法,但各自的数据可能不同。
1、创建一个类
以Student类为例,在Python中,定义类是通过 class 关键字:
class Student(object):
pass
class后面紧跟的是类名,即Student,类名一般是由大写字母开头;紧接着是 (object) ,表示该类是从哪个类继承下来的,继承的概念我们后面再讲,通常,如果没有合适的继承类,就使用 object 类,这是所有类最终都会继承的类。2、创建类的实例
定义好了 Student 类,就可以根据 Student 类创建出 Student 的实例,创建实
例是通过类名+()实现的:
class Student(object):
pass
a = Student()
print(a)
print(Student)

可以看到,变量 a 指向的就是一个 Student 的实例,后面的 0x7fd1c6781550 是内存地址,每个object的地址都不一样,而 Student 本身则是一个类。
可以自由地给一个实例变量绑定属性,比如,给实例 a 绑定一个 name 属性:
a = Student() a.name = 'yutao' print(a.name)

3、类的属性
由于类可以起到模板的作用,因此,可以在创建实例的时候,把一些我们认为必须绑定的属性强制填写进去。通过定义一个特殊的 __init__ 方法,在创建实例的时候,就把 name ,age , score 等属性绑上去:
class Student(object):
def __init__(self,name,age,score):
self.name = name
self.age = age
self.score = score
注意到 __init__ 方法的第一个参数永远是 self ,表示创建的实例本身,因此,在 __init__ 方法内部,就可以把各种属性绑定到 self ,因为 self 就指向创建的实例本身。有了 __init__ 方法,在创建实例的时候,就不能传入空的参数了,必须传入与 __init__方法匹配的参数,但 self 不需要传,Python解释器自己会把实例变量传进去:
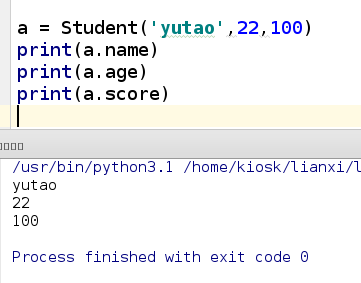
a = Student('yutao',22,100)
print(a.name)
print(a.age)
print(a.score)
和普通的函数相比,在类中定义的函数只有一点不同,就是第一个参数永远是实例变量 self ,并且,调用时,不用传递该参数。除此之外,类的方法和普通函数没有什么区别,所以,你仍然可以用默认参数、可变参数、关键字参数和命名关键字参数。
4、数据封装(类的方法)
面向对象编程的一个重要特点就是数据封装。在上面的Student 类中,每个实例就拥有各自的name 、age 和 score
这些数据。我们可以通过一般函数来访问这些数据,
比如打印一个学生的成绩:
def student_score(name,score):
print('姓名:%s 成绩:%s'%(name,score))
student_score('yutao',99)

但是,既然 student 实例本身就拥有这些数据,要访问这些数据,就没有必要从外面的函数去访问,可以直接在 Student 类的内部定义访问数据的函数,这样,就把“数据”给封装起来了。这些封装数据的函数是和 Student 类本身是关联起来的,我们称之为类的方法:
class Student(object):
def __init__(self,name,age,score):
self.name = name
self.age = age
self.score = score
def student_score(self):
print('姓名:%s 成绩:%s' % (self.name,self.score))
a = Student('yutao',22,100)
a.student_score()
要定义一个方法,除了第一个参数是 self 外,其他和普通函数一样。要调用一个方法,只需要在实例变量上直接调用,除了 self 不用传递,其他参数正常传入: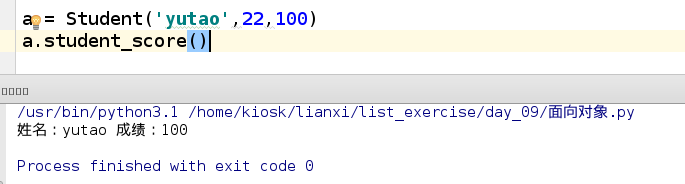
这样一来,我们从外部看 Student 类,就只需要知道,创建实例需要给出 name 、age 和 score ,而如何打印,都是在 Student 类的内部定义的,这些数据和逻辑被“封装”起来了,调用很容易,但却不用知道内部实现的细节。
5、封装的好处
这样一来,我们从外部看 Student 类,就只需要知道,创建实例需要给出 name 和 score ,而如何打印,都是在 Student 类的内部定义的,这些数据和逻辑被“封装”起来了,调用很容易,但却不用知道内部实现的细节。
封装的另一个好处是可以给Student类添加新的方法,比如student_grade:
class Student(object):
def __init__(self,name,age,score):
self.name = name
self.age = age
self.score = score
def student_score(self):
print('姓名:%s 成绩:%s' % (self.name,self.score))
def student_grade(self):
if 90 < self.score <=100:
return 'A'
elif 70 < self.score <= 90:
return 'B'
else:
return 'C'
a = Student('yutao',22,100)
a.student_score()
print(a.student_grade())

6、小结
类是创建实例的模板,而实例则是一个一个具体的对象,各个实例拥有的数据都互相独立,互不影响;
方法就是与实例绑定的函数,和普通函数不同,方法可以直接访问实例的数据;
通过在实例上调用方法,我们就直接操作了对象内部的数据,但无需知道方法内部的实现细节。
和静态语言不同,Python允许对实例变量绑定任何数据,也就是说,对于两个实例变量,虽然它们都是同一个类的不同实例,但拥有的变量名称都可能不同。
二、类的创建,属性及方法的练习
1、应用练习一
创建一个People类,拥有的方法为砍柴、娶媳妇 和 回家;
1)实例化对象,执行相应的方法;
2)示例如下:
老李,18岁,男,开车去娶媳妇;
老张,22岁,男,上山砍柴;
小王,8岁,女,辍学回家;
3)提示:
属性:name,age,gender
方法:gohome() kanchai() quxifu()
class People(object):
def __init__(self, name, age, gender):
self.name = name
self.age = age
self.gender = gender
def goHome(self):
print("%s,%s岁,%s, 辍学回家" % (self.name, self.age, self.gender))
def kanChai(self):
print("%s,%s岁,%s,上山砍柴" % (self.name, self.age, self.gender))
def quXiFu(self):
print("%s,%s岁,%s, 开车娶媳妇" % (self.name, self.age, self.gender))
p1 = People("小王", 8, '女')
p1.goHome()

2、应用练习二
栈的数据结构:
栈的方法:
1)入栈push
2)出栈pop
3)栈顶元素top
4)栈的长度lenght
5)判断栈是否为空isempty
6)显示栈中元素view
操作结果:
1)栈类的实例化
2)入栈两次、出栈一次
3)显示最终栈元素
import random
class Stuck(object):
def __init__(self):
self.stuck = []
def push(self,item):
self.stuck.append(item)
def pop(self):
if not self.isempty():
self.stuck.pop[-1]
def top(self):
if not self.isempty():
self.stuck[0]
return
def lenght(self):
return len(self.stuck)
def isempty(self):
return len(self.stuck) == 0
def view(self):
for i in self.stuck:
print(i,end=',')
st = Stuck()
for i in range(5):
st.push(random.randint(1,10))
print(st.view())
