目录
问题1:模型中断后继续训练出错
在有些时候我们需要保存训练好的参数为path文件,以防不测,下次可以直接加载该轮epoch的参数接着训练,但是在重新加载时发现类似报错:
size mismatch for block0.affine0.linear1.linear2.weight: copying a param with shape torch.Size([512, 256]) from checkpoint, the shape in current model is torch.Size([256, 256]).
size mismatch for block0.affine0.linear1.linear2.bias: copying a param with shape torch.Size([512]) from checkpoint, the shape in current model is torch.Size([256]).
问题原因:这是说明某个超参数出现了问题,可能你之前训练时候用的是64,现在准备在另外的机器上面续训的时候某个超参数设置的是32,导致了size mismatch
解决方案:查看size mismatch的模型部分,将超参数改回来。
问题2:模型中断后继续训练 效果直降
加载该轮epoch的参数接着训练,继续训练的过程是能够运行的,但是发现继续训练时效果大打折扣,完全没有中断前的最后几轮好。
问题原因:暂时未知,推测是续训时模型加载的问题,也有可能是保存和加载的方式问题
解决方案:统一保存和加载的方式,当我采用以下方式时,貌似避免了这个问题:
模型的保存:
torch.save(netG.state_dict(), 'models/%s/netG_%03d.pth' % (cfg.CONFIG_NAME, epoch))
模型的重新加载:
netD.load_state_dict(torch.load('models/%s/netD_300.pth' % (cfg.CONFIG_NAME), map_location='cuda:0'))
问题3:如何自动生成requirements.txt,如何根据requirements安装环境
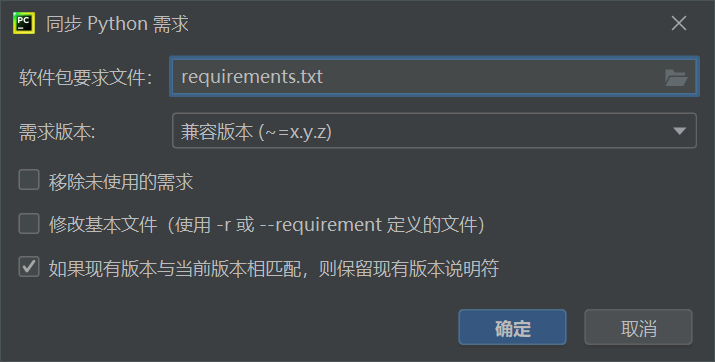
解决方案1(推荐):使用Python打开自己的工程,然后点击工具(Tools)———同步Python要求(Sync Python Requirements)

然后需求版本改为兼容(~=x.y.z),然后点击确定就可以自动生成requirements.txt了
根据requirements.txt自动安装对应环境:pip install -r requirements.txt
问题4:AttributeError: module ‘scipy.misc’ has no attribute ‘imread’
问题原因:scipy在1.2后的版本已经抛弃使用imread
解决方案1:降低scipy的版本(不推荐)
pip install scipy==1.2.1
解决方案2:使用imageio.imread来代替,在使用到imread加入如下代码:
import imageio
content_image = imageio.imread
问题5:No module named ‘tensorflow.compat’
问题原因:compat是TensorFlow的2.x里的模块,Tensorflow1.x版本里是没有的。(虽然)
解决方案:先卸载原版本Tensorflow:pip uninstall tensorflow
再重新安装Tensorflow就行了:pip install tensorflow
问题6:EOFError: Ran out of input
问题原因:使用pickle.load(f)加载pickle文件时,文件为空
解决方案:找到加载pickle文件的代码位置,检查文件内容和路径