HTTP 协议
HTTP 是什么
HTTP (全称为 “超文本传输协议”) 是一种应用非常广泛的 应用层协议.
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Av5xuPpw-1654501679445)(media/3b6af4c7d8ce820919c5df01e74953c5.jpeg)]](https://img-blog.csdnimg.cn/6c298949341b45f983a83c3981c85037.jpeg)
HTTP 诞生与1991年. 目前已经发展为最主流使用的一种应用层协议.
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-z6O3Iu4Y-1654501679447)(media/a7c73e35adf92a9f43c980691056ba64.jpeg)]](https://img-blog.csdnimg.cn/d4f1f3d87edd4847a66db28ee96efaac.jpeg)
最新的 HTTP 3 版本也正在完善中, 目前 Google / Facebook 等公司的产品已经支持了.
HTTP 往往是基于传输层的 TCP 协议实现的. (HTTP1.0, HTTP1.1, HTTP2.0 均为TCP, HTTP3 基于 UDP实现)
目前我们主要使用的还是 HTTP1.1 和 HTTP2.0 . 当前课堂上讨论的 HTTP 以 1.1 版本为主.
我们平时打开一个网站, 就是通过 HTTP 协议来传输数据的.
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-qF1j13di-1654501679449)(media/45130ffcbb28c9ccdd6e53028a244be5.jpeg)]](https://img-blog.csdnimg.cn/ac52e88e343543eab6c3cde4a4ee63a1.jpeg)
当我们在浏览器中输入一个 搜狗搜索的 “网址” (URL) 时, 浏览器就给搜狗的服务器发送了一个 HTTP 请 求, 搜狗的服务器返回了一个 HTTP 响应.
这个响应结果被浏览器解析之后, 就展示成我们看到的页面内容. (这个过程中浏览器可能会给服务器发 送多个 HTTP 请求, 服务器会对应返回多个响应, 这些响应里就包含了页面 HTML, CSS, JavaScript, 图片, 字体等信息).
所谓 “超文本” 的含义, 就是传输的内容不仅仅是文本(比如 html, css 这个就是文本), 还可以是一些 其他的资源, 比如图片,视频, 音频等二进制的数据.
扫描二维码关注公众号,回复: 14246770 查看本文章
理解 “应用层协议”
我们已经学过 TCP/IP , 已经知道目前数据能从客户端进程经过路径选择跨网络传送到服务器端进程[ IP+Port ].
可是,仅仅把数据从A点传送到B点就完了吗?
这就好比,在淘宝上买了一部手机,卖家[ 客户端 ]把手机通过顺丰[ 传送+路径选择 ] 送到买家 [服务器 ] 手里就完了吗?
当然不是,买家还要使用这款产品,还要在使用之后,给卖家打分评论。
所以,我们把数据从A端传送到B端, TCP/IP 解决的是顺丰的功能,而两端还要对数据进行加工处理或 者使用,所以我们还需要一层协议,不关心通信细节,关心应用细节!
这层协议叫做应用层协议。而应用是有不同的场景的,所以应用层协议是有不同种类的,其中经典协议 之一的HTTP就是其中的佼佼者.
再回到我们刚刚说的买手机的例子,顺丰相当于 TCP/IP 的功能,那么买回来的手机都附带了说明书【产品介绍,使用介绍,注意事项等】,而该说明书指导用户该如何使用手机【虽然我们都不看,但是父母辈有部分是有看说明书的习惯的:)】,此时的说明书可以理解为用户层协议
理解 HTTP 协议的工作过程
当我们在浏览器中输入一个 “网址”, 此时浏览器就会给对应的服务器发送一个 HTTP 请求. 对方服务器收
到这个请求之后, 经过计算处理, 就会返回一个 HTTP 响应.
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-mKUsHuLU-1654501679450)(media/ead87d1dcd695b6f724147a7f93f48c2.jpeg)]](https://img-blog.csdnimg.cn/ff4c5ee0a0444ce18a8b40b7034cfd9a.jpeg)
事实上, 当我们访问一个网站的时候, 可能涉及不止一次的 HTTP 请求/响应 的交互过程. 可以通过 chrome 的开发者工具观察到这个详细的过程.
通过 F12 打开 chrome 的开发者工具, 切换到 Network 标签页. 然后刷新页面即可看到如下图效 果. 每一条记录都是一次HTTP 请求/响应
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-YFmYk91M-1654501679450)(media/034da23632e2ae70942f7f5fcdf18c47.jpeg)]](https://img-blog.csdnimg.cn/b72d681d447040559d0862daa89bb879.jpeg)
注意: 当前 搜狗主页 是通过 https 来进行通信的. https 是在 http 基础之上做了一个加密解密的工作, 后 面再介绍.
HTTP 协议格式
HTTP 是一个文本格式的协议. 可以通过 Chrome 开发者工具或者 Fiddler 抓包, 分析 HTTP 请求/响应的 细节.
抓包工具的使用
以 Fiddler 为例. (下载地址: https://www.telerik.com/fiddler/)
安装过程比较简单, 一路 next 即可.
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-F1XUSNJv-1654501679451)(media/d4368951f75b1ec54ac216c777222efe.jpeg)]](https://img-blog.csdnimg.cn/009b815ec87343a6ac836d4ba43d0c7e.jpeg)
- 左侧窗口显示了所有的 HTTP请求/响应, 可以选中某个请求查看详情.
- 右侧上方显示了 HTTP 请求的报文内容. (切换到 Raw 标签页可以看到详细的数据格式)
- 右侧下方显示了 HTTP 响应的报文内容. (切换到 Raw 标签页可以看到详细的数据格式)
- 请求和响应的详细数据, 可以通过右下角的 View in Notepad 通过记事本打开.
可以使用 ctrl + a 全选左侧的抓包结果, delete 键清除所有被选中的结果.
抓包工具的原理
Fiddler 相当于一个 “代理”.
浏览器访问 sogou.com 时, 就会把 HTTP 请求先发给 Fiddler, Fiddler 再把请求转发给 sogou 的服务器. 当 sogou 服务器返回数据时, Fiddler 拿到返回数据, 再把数据交给浏览器.
因此 Fiddler 对于浏览器和 sogou 服务器之间交互的数据细节, 都是非常清楚的.
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-vnamSekq-1654501679451)(media/bd6bfc744e29b780e064ac6e1f129964.png)]](https://img-blog.csdnimg.cn/53576db91bb24249b4dc462790dc9b56.png)
代理就可以简单理解为一个跑腿小弟. 你想买罐冰阔落, 又不想自己下楼去超市, 那么就可以把钱给 你的跑腿小弟,跑腿小弟来到超市把钱给超市老板, 再把冰阔落拿回来交到你手上. 这个过程中, 这 个跑腿小弟对于 “你” 和 “超市老板” 之间的交易细节,是非常清楚的.
抓包结果
以下是一个 HTTP请求/响应 的抓包结果.
HTTP请求
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-7XKWtWxQ-1654501679452)(media/687af2def51f73e4327630477f7d7d1f.jpeg)]](https://img-blog.csdnimg.cn/e940ae2e969d49feb74372217942e20b.jpeg)
- 首行: [方法] + [url] + [版本]
- Header: 请求的属性, 冒号分割的键值对;每组属性之间使用\n分隔;遇到空行表示Header部分结束
- Body: 空行后面的内容都是Body. Body允许为空字符串. 如果Body存在, 则在Header中会有一个Content-Length属性来标识Body的长度;
HTTP响应
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-LVakkHP4-1654501679452)(media/3121b28b65969efb2cd5f6273b03522a.jpeg)]](https://img-blog.csdnimg.cn/f310c8cd290943f6a47e8fecd8dcbe75.jpeg)
- 首行: [版本号] + [状态码] + [状态码解释]
- Header: 请求的属性, 冒号分割的键值对;每组属性之间使用\n分隔;遇到空行表示Header部 分结束
- Body: 空行后面的内容都是Body. Body允许为空字符串. 如果Body存在, 则在Header中会有一个Content-Length属性来标识Body的长度; 如果服务器返回了一个html页面, 那么html页 面内容就是在body中.
协议格式总结
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-AtYgkSSt-1654501679453)(media/048d65afc3021afa39c5dbb8851ce6cc.png)]](https://img-blog.csdnimg.cn/aecec6c001d342da8f1625491b10329c.png)
思考问题: 为什么 HTTP 报文中要存在 “空行”?
因为 HTTP 协议并没有规定报头部分的键值对有多少个. 空行就相当于是 “报头的结束标记”, 或者 是 “报头和正文之间的分隔符”.
HTTP 在传输层依赖 TCP 协议, TCP 是面向字节流的. 如果没有这个空行, 就会出现 “粘包问题”.
HTTP 请求 (Request)
认识 URL
URL 基本格式
平时我们俗称的 “网址” 其实就是说的 URL (Uniform Resource Locator 统一资源定位符). 互联网上的每个文件都有一个唯一的URL,它包含的信息指出文件的位置以及浏览器应该怎么处理它. URL 的详细规则由 因特网标准RFC1738 进行了约定. (https://datatracker.ietf.org/doc/html/rfc1738)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Fs0mDBzz-1654501679453)(media/c83127c96620a2e908f51af44d86f1ce.jpeg)]](https://img-blog.csdnimg.cn/ef636bcfb08b4a05934c42c3bd42255a.jpeg)
一个具体的 URL:
https://v.bitedu.vip/personInf/student?userId=10000&classId=100
可以看到, 在这个 URL 中有些信息被省略了.
https: 协议方案名. 常见的有 http 和 https, 也有其他的类型. (例如访问 mysql时用的jdbc:mysql)user:pass: 登陆信息. 现在的网站进行身份认证一般不再通过 URL 进行了. 一般都会省略v.bitedu.vip: 服务器地址. 此处是一个 “域名”, 域名会通过 DNS 系统解析成一个具体的 IP 地址. (通过ping 命令可以看到,v.bitedu.vip的真实 IP 地址为118.24.113.28)- 端口号: 上面的 URL 中端口号被省略了. 当端口号省略的时候, 浏览器会根据协议类型自动决定使用 哪个端口. 例如 http
协议默认使用 80 端口, https 协议默认使用 443 端口. /personInf/student: 带层次的文件路径.userId=10000&classId=100: 查询字符串(query string). 本质是一个键值对结构. 键值对之间使用 & 分隔. 键和值之间使用 = 分隔.- 片段标识: 此 URL 中省略了片段标识. 片段标识主要用于页面内跳转. (例如 Vue 官方文档:
https://cn.vuejs.org/v2/guide/#%E8%B5%B7%E6%AD%A5,
通过不同的片段标识跳转到文档的不同章节)
使用 ping 命令查看域名对应的 IP 地址.
1. 在开始菜单中输入
cmd, 打开 命令提示符2. 在 cmd 中输入
ping v.bitedu.vip, 即可看到域名解析的结果.
PS: 有的电脑上 ping 命令会报错
ping 不是内部或外部命令,也不是可运行的程序或批处理文件. 这种情况是因为有的Windows10 默认没有启用 ping 命令.百度搜索
windows10 启用 ping即可.
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-hWgagpZq-1654501679453)(media/aa6b370023235b0de654f8a4abc001ef.png)]](https://img-blog.csdnimg.cn/d453ed5779e341f18c67961c63b21701.png)
关于 query string
query string 中的内容是键值对结构. 其中的 key 和 value 的取值和个数, 完全都是程序猿自己约 定的.
我们可以通过这样的方式来自定制传输我们需要的信息给服务器.
URL 中的可省略部分
- 协议名: 可以省略, 省略后默认为 http://
- ip 地址 / 域名: 在 HTML 中可以省略(比如 img, link, script, a 标签的 src 或者 href 属性). 省 略后表示服务器的 ip / 域名与当前 HTML 所属的 ip / 域名一致.
- 端口号: 可以省略. 省略后如果是 http 协议, 端口号自动设为 80; 如果是 https 协议, 端口号自 动设为 443.
- 带层次的文件路径: 可以省略. 省略后相当于 / . 有些服务器会在发现 / 路径的时候自动访问/index.html
- 查询字符串: 可以省略
- 片段标识: 可以省略
关于 URL encode
像 / ? : 等这样的字符, 已经被url当做特殊意义理解了. 因此这些字符不能随意出现. 比如, 某个参数中需要带有这些特殊字符, 就必须先对特殊字符进行转义.
一个中文字符由 UTF-8 或者 GBK 这样的编码方式构成, 虽然在 URL 中没有特殊含义, 但是仍然需 要进行转义. 否则浏览器可能把UTF-8/GBK 编码中的某个字节当做 URL 中的特殊符号.
转义的规则如下: 将需要转码的字符转为16进制,然后从右到左,取4位(不足4位直接处理),每2位做一 位,前面加上%,编码成%XY格式
例如:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-RPCWtpks-1654501679454)(media/1f8ea4d97a695e91e2619ee13f9cf37c.jpeg)]](https://img-blog.csdnimg.cn/3aa65140ed6748ef8203725bd4b6eaaf.jpeg)
“+” 被转义成了 “%2B”
urldecode就是urlencode的逆过程;
认识 “方法” (method)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-HZziZsbi-1654501679454)(media/a070f7a9d37fc6502955196511d3dd21.jpeg)]](https://img-blog.csdnimg.cn/6460dba8adb34c9ba1c6c48864fb71e3.jpeg)
1. GET 方法
GET 是最常用的 HTTP 方法. 常用于获取服务器上的某个资源.
在浏览器中直接输入 URL, 此时浏览器就会发送出一个 GET 请求.
另外, HTML 中的 link, img, script 等标签, 也会触发 GET 请求.
后面我们还会学习, 使用 JavaScript 中的 ajax 也能构造 GET 请求.
使用 Fiddler 观察 GET 请求
打开 Fiddler, 访问 搜狗主页, 观察抓包结果.
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-5HmQyssR-1654501679460)(media/5af896d2a120788ae7640d988e15d5ed.jpeg)]](https://img-blog.csdnimg.cn/0819a5728b3a44bcb50cb340c1c6f797.jpeg)
在上面的结果中可以看到:
最上面的 ![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-VuvCttMJ-1654501679461)(media/957a07578dea7edacfc09aaaba5cb2dd.png)]](https://img-blog.csdnimg.cn/9273bceb5f3f4d76b391db4bcf2827a7.png)
是通过浏览器地址栏发送的 GET 请求. 下面的和 sogou 域名相关的请求, 有些是通过 html 中的 link/script/img 标签产生的, 例如
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-v2gG5G7O-1654501679463)(media/6d38044e7403457deb909c1b6cbb3428.png)]](https://img-blog.csdnimg.cn/65e5bbee52114ad1bee025f6e0a90543.png)
有些是通过 ajax 的方式产生的, 例如
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-pFJbYcLk-1654501679463)(media/740b28215d47178c13b5f673bbe18666.png)]](https://img-blog.csdnimg.cn/fd558d2ffff04d9abf0acd7a936eeef9.png)
选中第一条 
观察请求的详细结果
GET https://www.sogou.com/ HTTP/1.1
Host: www.sogou.com
Connection: keep-alive
Cache-Control: max-age=0
sec-ch-ua: " Not;A Brand";v="99", "Google Chrome";v="91", "Chromium";v="91"
sec-ch-ua-mobile: ?0
Upgrade-Insecure-Requests: 1
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML,
like Gecko) Chrome/91.0.4472.77 Safari/537.36
Accept:
text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,imag
e/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9
Sec-Fetch-Site: none
Sec-Fetch-Mode: navigate
Sec-Fetch-User: ?1
Sec-Fetch-Dest: document
Accept-Encoding: gzip, deflate, br
Accept-Language: zh-CN,zh;q=0.9,en;q=0.8
Cookie: SUID=19AA8B7B6E1CA00A000000005F9A2F76; SUV=1603940214073598;
pgv_pvi=2668946432; usid=dSCf7rQCZRKIwksQ;
CXID=4E2782F970F4344A90D6ED6240646C87; ssuid=8088681888;
wuid=AAG3v2WvMgAAAAqgFXQrvAAAkwA=; IPLOC=CN6101; ABTEST=0|1620624968|v17;
cd=1620907362&1c2f143be7a26fba5e494f96ebd8f163; browerV=3; osV=1;
sw_uuid=5799772160;
ad=@c$ookllll2kHAPdlllllpjL341llllltYvGDlllll9llllllylll5@@@@@@@@@@;
SNUID=D6B644B4CECB0AF639BBE267CF3AB1AD; taspeed=taspeedexist; sst0=13;
ld=Lkllllllll2kmmNTlllllpjM@rwlllllNSzaekllllGllllljllll5@@@@@@@@@@
GET 请求的特点
- 首行的第一部分为 GET
- URL 的 query string 可以为空, 也可以不为空.
- header 部分有若干个键值对结构.
- body 部分为空.
关于 GET 请求的 URL 长度问题
网上有些资料上描述: 这样的说法是错误的.
HTTP 协议由 RFC 2616 标准定义, 标准原文中明确说明: “Hypertext Transfer Protocol – HTTP/1.1,” does not specify any requirement for URL length.
没有对 URL 的长度有任何的限制.
实际 URL 的长度取决于浏览器的实现和 HTTP 服务器端的实现. 在浏览器端, 不同的浏览器最大长 度是不同的,但是现代浏览器支持的长度一般都很长; 在服务器端, 一般这个长度是可以配置的.
2.POST 方法
POST 方法也是一种常见的方法. 多用于提交用户输入的数据给服务器(例如登陆页面).
通过 HTML 中的 form 标签可以构造 POST 请求, 或者使用 JavaScript 的 ajax 也可以构造 POST 请求.
使用 Fiddler 观察 POST 方法
在比特教务系统的登陆页面, 输入用户名, 密码, 验证码之后, 点击登陆, 就可以看到 POST 请求.
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-SoMgffqI-1654501679464)(media/ebd07dab1aaa73b8506b349cb0d932e1.jpeg)]](https://img-blog.csdnimg.cn/6170338c6cd74d6bbd3e8b2d0b7e9ae4.jpeg)
点击这个请求, 查看请求详情
POST https://v.bitedu.vip/tms/login HTTP/1.1
Host: v.bitedu.vip
Connection: keep-alive
Content-Length: 105
sec-ch-ua: " Not;A Brand";v="99", "Google Chrome";v="91", "Chromium";v="91"
sec-ch-ua-mobile: ?0
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML,
like Gecko) Chrome/91.0.4472.77 Safari/537.36
Access-Control-Allow-Methods: PUT,POST,GET,DELETE,OPTIONS
Content-Type: application/json;charset=UTF-8
Access-Control-Allow-Origin: *
Accept: application/json, text/plain, */*
Access-Control-Allow-Headers: Content-Type, Content-Length, Authorization,
Accept, X-Requested-With , yourHeaderFeild
Origin: https://v.bitedu.vip
Sec-Fetch-Site: same-origin
Sec-Fetch-Mode: cors
Sec-Fetch-Dest: empty
Referer: https://v.bitedu.vip/login
Accept-Encoding: gzip, deflate, br
Accept-Language: zh-CN,zh;q=0.9,en;q=0.8
Cookie: username=123456789; rememberMe=true
{"username":"123456789","password":"xxxx","code":"jw7l","uuid":"d110a05ccde64b16
a861fa2bddfdcd15"}
POST 请求的特点
- 首行的第一部分为 POST
- URL 的 query string 一般为空 (也可以不为空)
- header 部分有若干个键值对结构.
- body 部分一般不为空. body 内的数据格式通过 header 中的
Content-Type指定. body 的长度由header 中的Content-Length指定.
经典面试题: 谈谈 GET 和 POST 的区别
-
语义不同: GET 一般用于获取数据, POST 一般用于提交数据.
-
GET 的 body 一般为空, 需要传递的数据通过 query string 传递, POST 的 query string 一般为空, 需要传递的数据通过 body 传递
-
GET 请求一般是幂等的, POST 请求一般是不幂等的. (如果多次请求得到的结果一样, 就视为 请求是幂等的).
-
GET 可以被缓存, POST 不能被缓存. (这一点也是承接幂等性).
补充说明:
- 关于语义: GET 完全可以用于提交数据, POST 也完全可以用于获取数据.
- 关于幂等性: 标准建议 GET 实现为幂等的. 实际开发中 GET 也不必完全遵守这个规则(主流网 站都有 “猜你喜欢” 功能,会根据用户的历史行为实时更新现有的结果.
- 关于安全性: 有些资料上说 “POST 比 GET 请安全”. 这样的说法是不科学的. 是否安全取决于前端在传输密码等敏感信息时是否进行加密, 和 GET POST 无关.
- 关于传输数据量: 有的资料上说 “GET 传输的数据量小, POST 传输数据量大”. 这个也是不科 学的, 标准没有规定 GET 的URL 的长度, 也没有规定 POST 的 body 的长度. 传输数据量多少, 完全取决于不同浏览器和不同服务器之间的实现区别.
- 关于传输数据类型: 有的资料上说 “GET 只能传输文本数据, POST 可以传输二进制数据”. 这 个也是不科学的. GET 的query string 虽然无法直接传输二进制数据, 但是可以针对二进制数 据进行 url encode.
3. 其他方法
- PUT 与 POST 相似,只是具有幂等特性,一般用于更新
- DELETE 删除服务器指定资源
- OPTIONS 返回服务器所支持的请求方法
- HEAD 类似于GET,只不过响应体不返回,只返回响应头
- TRACE 回显服务器端收到的请求,测试的时候会用到这个
- CONNECT 预留,暂无使用
这些方法的 HTTP 请求可以使用 ajax 来构造. (也可以通过一些第三方工具)
任何一个能进行网络编程的语言都可以构造 HTTP 请求. 本质上就是通过 TCP socket 写入一个符 合 HTTP 协议规则的字符串.
认识请求 “报头” (header)
header 的整体的格式也是 “键值对” 结构. 每个键值对占一行. 键和值之间使用分号分割.
报头的种类有很多, 此处仅介绍几个常见的.
Host
表示服务器主机的地址和端口.
Content-Length
表示 body 中的数据长度.
Content-Type
表示请求的 body 中的数据格式.
常见选项:
application/x-www-form-urlencoded: form表单提交的数据格式. 此时 body 的格式形如:
title=test&content=hello
multipart/form-data: form表单提交的数据格式(在 form 标签中加上enctyped="multipart/form-data". 通常用于提交图片/文件. body 格式形如:
Content-Type:multipart/form-data; boundary=----
WebKitFormBoundaryrGKCBY7qhFd3TrwA
------WebKitFormBoundaryrGKCBY7qhFd3TrwA
Content-Disposition: form-data; name="text"
title
------WebKitFormBoundaryrGKCBY7qhFd3TrwA
Content-Disposition: form-data;name="file";filename="chrome.png"
Content-Type: image/png
PNG ... content of chrome.png ...
------WebKitFormBoundaryrGKCBY7qhFd3TrwA--
application/json: 数据为 json 格式. body 格式形如:
{"username":"123456789","password":"xxxx","code":"jw7l","uuid":"d110a05ccde64b16a861fa2bddfdcd15"}
关于 Content-Type 的详细情况:
https://developer.mozilla.org/en-US/docs/Web/HTTP/Basics_of_HTTP/MIME_types
User-Agent (简称 UA)
表示浏览器/操作系统的属性. 形如
Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.77 Safari/537.36
其中 Windows NT 10.0; Win64; x64 表示操作系统信息
AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.77 Safari/537.36表示浏览器信息.
User-Agent 之所以是这个样子是因为历史遗留问题. 可以参考
User-Agent 的故事: http://www.nowamagic.net/librarys/veda/detail/2576
Referer
表示这个页面是从哪个页面跳转过来的. 形如
https://v.bitedu.vip/login
如果直接在浏览器中输入URL, 或者直接通过收藏夹访问页面时是没有 Referer 的.
Cookie
Cookie 中存储了一个字符串, 这个数据可能是客户端(网页)自行通过 JS 写入的, 也可能来自于服务器(服 务器在 HTTP 响应的 header 中通过 Set-Cookie 字段给浏览器返回数据).
往往可以通过这个字段实现 “身份标识” 的功能.
每个不同的域名下都可以有不同的 Cookie, 不同网站之间的 Cookie 并不冲突.
可以通过抓包观察页面登陆的过程(以码云为例):
1) 清除之前的 cookie
为了方便观察, 先清除掉之前登陆的 cookie
在码云页面上, 点击 url 左侧的图标, 选择 Cookie
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-QX9IHCzm-1654501679465)(media/6804afac9247a4c44bf680e73d73b7f3.png)]](https://img-blog.csdnimg.cn/d0444c4ce14a414fb59186ecfb66fb8a.png)
然后移除已经存在的 Cookie
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-kXxu3tay-1654501679465)(media/5564c5c9f5cae13b59b9d9a1bbb4cf63.png)]](https://img-blog.csdnimg.cn/fb1db669b42240089ba0293efd15eeea.png)
2) 登陆操作
登陆请求
POST https://gitee.com/login HTTP/1.1
Host: gitee.com
Connection: keep-alive
Content-Length: 394
Cache-Control: max-age=0
sec-ch-ua: " Not;A Brand";v="99", "Google Chrome";v="91", "Chromium";v="91"
sec-ch-ua-mobile: ?0
Upgrade-Insecure-Requests: 1
Origin: https://gitee.com
Content-Type: application/x-www-form-urlencoded
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML,
like Gecko) Chrome/91.0.4472.101 Safari/537.36
Accept:
text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,imag
e/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9
Sec-Fetch-Site: same-origin
Sec-Fetch-Mode: navigate
Sec-Fetch-User: ?1
Sec-Fetch-Dest: document
Referer: https://gitee.com/login
Accept-Encoding: gzip, deflate, br
Accept-Language: zh-CN,zh;q=0.9,en;q=0.8
encrypt_key=password&utf8=%E2%9C%93&authenticity_token=36ZqO9tglSN6EB6pF6f2Gt%2B
dalgkbpTDUsJC5OER7w8%3D&redirect_to_url=%2FHGtz2222&user%5Blogin%5D=HGtz2222&enc
rypt_data%5Buser%5Bpassword%5D%5D=Hy2gjJ60312Ss12jSe21GMLPEb766tAhCygL281FLRMpiz
xJVaWGOPlQF7lZhelab1HS2vBiwfBo5C7BnR5ospoBiK1hR6jNXv1lesaYifv9dP1iRC6ozLLMszo%2F
aRh5j5DeYRyKcE0QJjXRGEDg4emXEK1LHVY4M1uqzFS0W58%3D&user%5Bremember_me%5D=0
登陆响应
HTTP/1.1 302 Found
Date: Thu, 10 Jun 2021 04:15:58 GMT
Content-Type: text/html; charset=utf-8
Connection: keep-alive
Keep-Alive: timeout=60
Server: nginx
X-XSS-Protection: 1; mode=block
X-Content-Type-Options: nosniff
X-UA-Compatible: chrome=1
Expires: Sun, 1 Jan 2000 01:00:00 GMT
Pragma: must-revalidate, no-cache, private
Location: https://gitee.com/HGtz2222
Cache-Control: no-cache
Set-Cookie: oschina_new_user=false; path=/; expires=Mon, 10 Jun 2041 04:16:00
-0000
Set-Cookie: gitee_user=true; path=/
Set-Cookie: gitee-session-
n=M1Rhbk1QUUxQdWk1VEZVQ1BvZXYybG13ZUJFNGR1V0pSYTZyTllEa21pVHlBUE5QU2Qwdk44NXdEam
11T3FZYXFidGNYaFJxcTVDRE1xU05GUXN0ek1Uc08reXRTay9ueTV3OGl5bTdzVGJjU1lUbTJ4bTUvN1
l3RFl4N2hNQmI1SEZpdmVJWStETlJrdWtyU0lDckhvSGJHc3NEZDFWdHc5cjdHaGVtNThNcEVOeFZlaH
c0WVY5NGUzWjc2cjdOcCtSdVJ0VndzdVNxb3dHK1hPSDBDSFB6WlZDc3prUVZ2RVJyTnpTb1c4aFg1Mm
UxM1YvQTFkb1EwaU4zT3hJcmRrS3dxVFZJNXoxaVJwa1liMlplbWR5QXQxY0lvUDNic1hxN2o0WDg1Wk
E9LS10N0VIYXg4Vm5xdllHVzdxa0VlUEp3PT0%3D-
-2f6a24f8d33929fe88ed19d4dea495fbb40ebed6; domain=.gitee.com; path=/; HttpOnly
X-Request-Id: 77f12d095edc98fab27d040a861f63b1
X-Runtime: 0.166621
Content-Length: 92
<html><body>You are being <a href="https://gitee.com/HGtz2222">redirected</a>.
</body></html>
可以看到, 响应中包含了 3 个 Set-Cookie 属性.
其中我们重点关注第三个. 里面包含了一个 gitee-session-n这样的属性, 属性值是一串很长的加密之后的信息. 这个信息就是用户当前登陆的身份标识. 也称为 “令牌(token)”
3) 访问其他页面
登陆成功之后, 此时可以看到后续访问码云的其他页面(比如个人主页), 请求中就都会带着刚才获取到的
Cookie 信息
GET https://gitee.com/HGtz2222 HTTP/1.1
Host: gitee.com
Connection: keep-alive
Cache-Control: max-age=0
Upgrade-Insecure-Requests: 1
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML,
like Gecko) Chrome/91.0.4472.101 Safari/537.36
Accept:
text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,imag
e/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9
Sec-Fetch-Site: same-origin
Sec-Fetch-Mode: navigate
Sec-Fetch-User: ?1
Sec-Fetch-Dest: document
sec-ch-ua: " Not;A Brand";v="99", "Google Chrome";v="91", "Chromium";v="91"
sec-ch-ua-mobile: ?0
Referer: https://gitee.com/login
Accept-Encoding: gzip, deflate, br
Accept-Language: zh-CN,zh;q=0.9,en;q=0.8
Cookie: oschina_new_user=false; user_locale=zh-CN; yp_riddler_id=1ce4a551-a160-
4358-aa73-472762c79dc0; visit-gitee--2021-05-06%2010%3A12%3A24%20%2B0800=1;
sensorsdata2015jssdkcross=%7B%22distinct_id%22%3A%22726826%22%2C%22first_id%22%3
A%22175869ba5888b6-0ea2311dc53295-303464-2073600-
175869ba5899ac%22%2C%22props%22%3A%7B%22%24latest_traffic_source_type%22%3A%22%E
7%9B%B4%E6%8E%A5%E6%B5%81%E9%87%8F%22%2C%22%24latest_search_keyword%22%3A%22%E6%
9C%AA%E5%8F%96%E5%88%B0%E5%80%BC_%E7%9B%B4%E6%8E%A5%E6%89%93%E5%BC%80%22%2C%22%2
4latest_referrer%22%3A%22%22%7D%2C%22%24device_id%22%3A%22175869ba5888b6-
0ea2311dc53295-303464-2073600-175869ba5899ac%22%7D; remote_way=svn;
tz=Asia%2FShanghai;
Hm_lvt_24f17767262929947cc3631f99bfd274=1622637014,1622712683,1622863899,1623298
442; Hm_lpvt_24f17767262929947cc3631f99bfd274=1623298550; gitee_user=true;
gitee-session-
n=M1Rhbk1QUUxQdWk1VEZVQ1BvZXYybG13ZUJFNGR1V0pSYTZyTllEa21pVHlBUE5QU2Qwdk44NXdEam
11T3FZYXFidGNYaFJxcTVDRE1xU05GUXN0ek1Uc08reXRTay9ueTV3OGl5bTdzVGJjU1lUbTJ4bTUvN1
l3RFl4N2hNQmI1SEZpdmVJWStETlJrdWtyU0lDckhvSGJHc3NEZDFWdHc5cjdHaGVtNThNcEVOeFZlaH
c0WVY5NGUzWjc2cjdOcCtSdVJ0VndzdVNxb3dHK1hPSDBDSFB6WlZDc3prUVZ2RVJyTnpTb1c4aFg1Mm
UxM1YvQTFkb1EwaU4zT3hJcmRrS3dxVFZJNXoxaVJwa1liMlplbWR5QXQxY0lvUDNic1hxN2o0WDg1Wk
E9LS10N0VIYXg4Vm5xdllHVzdxa0VlUEp3PT0%3D-
-2f6a24f8d33929fe88ed19d4dea495fbb40ebed6
请求你中的 Cookie 字段也包含了一个 gitee-session-n 属性, 里面的值和刚才服务器返回的值
相同. 后续只要访问 gitee 这个网站, 就会一直带着这个令牌, 直到令牌过期/下次重新登陆
理解登陆过程
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-d4M4SpPq-1654501679466)(media/29ec0cf69f62c70b592554c1b446f851.jpeg)]](https://img-blog.csdnimg.cn/19cb2fbbb1e34074a818be9fa530e1ee.jpeg)
这个过程和去医院看病很相似.
1. 到了医院先挂号. 挂号时候需要提供身份证, 同时得到了一张 “就诊卡”, 这个就诊卡就相当于 患者的 “令牌”.
2. 后续去各个科室进行检查, 诊断, 开药等操作, 都不必再出示身份证了, 只要凭就诊卡即可识别 出当前患者的身份.
3. 看完病了之后, 不想要就诊卡了, 就可以注销这个卡. 此时患者的身份和就诊卡的关联就销毁 了. (类似于网站的注销操作)
4. 又来看病, 可以办一张新的就诊卡, 此时就得到了一个新的 “令牌”
认识请求 “正文” (body)
正文中的内容格式和 header 中的 Content-Type 密切相关. 上面也罗列了三种常见的情况. 下面可以通过抓包来观察这几种情况:
1) application/x-www-form-urlencoded
抓取码云上传头像请求
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-pX3ZF3at-1654501679466)(media/04663fd5304d3bb99e9374ce89394fc6.png)]](https://img-blog.csdnimg.cn/028700ccc42c4815baac36aa4a16118f.png)
POST https://gitee.com/profile/upload_portrait_with_base64 HTTP/1.1
Host: gitee.com
Connection: keep-alive
Content-Length: 107389
sec-ch-ua: " Not;A Brand";v="99", "Google Chrome";v="91", "Chromium";v="91"
Accept: */*
X-CSRF-Token: 6ROfZGr4Y7Qx8td1TuKCnrG8gbODLCSUqUBZSw2b+ac=
X-Requested-With: XMLHttpRequest
sec-ch-ua-mobile: ?0
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML,
like Gecko) Chrome/91.0.4472.101 Safari/537.36
Content-Type: application/x-www-form-urlencoded; charset=UTF-8
Origin: https://gitee.com
Sec-Fetch-Site: same-origin
Sec-Fetch-Mode: cors
Sec-Fetch-Dest: empty
Referer: https://gitee.com/HGtz2222
Accept-Encoding: gzip, deflate, br
Accept-Language: zh-CN,zh;q=0.9,en;q=0.8
Cookie: oschina_new_user=false; user_locale=zh-CN; yp_riddler_id=1ce4a551-a160-
4358-aa73-472762c79dc0; visit-gitee--2021-05-06%2010%3A12%3A24%20%2B0800=1;
sensorsdata2015jssdkcross=%7B%22distinct_id%22%3A%22726826%22%2C%22first_id%22%3
A%22175869ba5888b6-0ea2311dc53295-303464-2073600-
175869ba5899ac%22%2C%22props%22%3A%7B%22%24latest_traffic_source_type%22%3A%22%E
7%9B%B4%E6%8E%A5%E6%B5%81%E9%87%8F%22%2C%22%24latest_search_keyword%22%3A%22%E6%
9C%AA%E5%8F%96%E5%88%B0%E5%80%BC_%E7%9B%B4%E6%8E%A5%E6%89%93%E5%BC%80%22%2C%22%2
4latest_referrer%22%3A%22%22%7D%2C%22%24device_id%22%3A%22175869ba5888b6-
0ea2311dc53295-303464-2073600-175869ba5899ac%22%7D; remote_way=svn;
tz=Asia%2FShanghai;
Hm_lvt_24f17767262929947cc3631f99bfd274=1622637014,1622712683,1622863899,1623298
442; gitee_user=true; Hm_lpvt_24f17767262929947cc3631f99bfd274=1623298560;
gitee-session-
n=c0hXQ0I5SjR1bWg5M01IR3RYS3hLT0RhelN1aFVuMExKdEdSSmRaQWIwRy9QWFUwV0thdzV1alIzYj
RaOU9ZeDdkZEJZK2RtTVRNeTNFRHNYVW9ha2hEcWJyclIwS1NVRG1EL0xxTmJXSGxvSzh3c28zOHBia1
pIOFQrU3RYeWE0bE13S09DTm5MZWZ5WW5WUVFpSzFiMGFWbHRDQ0xRakc1Um5yY21HQllqeUpNLzBvZF
gxbHVhN09uK2h1VVVmRHZkS3BmVGEwcDhyNjJVb1p0RFRLY0VOem5vNEEvd0FuYzJJYlhZcGlyenZQc3
dSbXBNUWI3UUwrRDBrV2N0UHZRdjFBUXF5b0Y0L1Vrd09pQVBKNkdjZmY5cHlDTCtMWG4ya0tIaW5LcE
tBTkw4cGFGVjhUQ0djMWhkOXI0bUFteUY4VW80RHl2T2Q2YmxwR1d3M3Rad1RhZWhhdnNiTTNrcE1RV2
NyZ1dYeDRoR0dpanh4bERNMTBuenB1NkgxLS16QUdJS3NlZG9mTVBtYlVlREppck1BPT0%3D-
-898d1284181ca494918d29ac44f9a3a79d448a9b
avatar=data%3Aimage%2Fpng%3Bbase64%2CiVBORw0KGgoAAAANSUhEUgAAAPgAAAD4CAYAAADB0Ss
LAAAg......
实际的抓包结果比较长, 此处没有全部贴出.
2) multipart/form-data
抓取比特教务系统的 “上传简历” 功能
POST https://v.bitedu.vip/tms/oss/upload/file HTTP/1.1
Host: v.bitedu.vip
Connection: keep-alive
Content-Length: 293252
sec-ch-ua: " Not;A Brand";v="99", "Google Chrome";v="91", "Chromium";v="91"
Authorization: Bearer
eyJhbGciOiJIUzUxMiJ9.eyJsb2dpbl91c2VyX2tleSI6IjFiYThjMDM5LWUyN2UtNDdhZS04YTAzLTN
mNWMzY2UwN2YyNSJ9.VQWoqrrgWZpDNc81tYfSvna8A9uZP6QKqucnvGMuY8wbavHF30rx7NG9VxnAo1
78V0nOJBd75QxRvNRgpY6-Iw
sec-ch-ua-mobile: ?0
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML,
like Gecko) Chrome/91.0.4472.101 Safari/537.36
Content-Type: multipart/form-data; boundary=----
WebKitFormBoundary8d5Rp4eJgrUSS3wT
Accept: */*
Origin: https://v.bitedu.vip
Sec-Fetch-Site: same-origin
Sec-Fetch-Mode: cors
Sec-Fetch-Dest: empty
Referer: https://v.bitedu.vip/personInf/student?userId=665
Accept-Encoding: gzip, deflate, br
Accept-Language: zh-CN,zh;q=0.9,en;q=0.8
Cookie: rememberMe=true; username=18691491410; Admin-
Token=eyJhbGciOiJIUzUxMiJ9.eyJsb2dpbl91c2VyX2tleSI6IjFiYThjMDM5LWUyN2UtNDdhZS04Y
TAzLTNmNWMzY2UwN2YyNSJ9.VQWoqrrgWZpDNc81tYfSvna8A9uZP6QKqucnvGMuY8wbavHF30rx7NG9
VxnAo178V0nOJBd75QxRvNRgpY6-Iw
------WebKitFormBoundary8d5Rp4eJgrUSS3wT
Content-Disposition: form-data; name="file"; filename="李星亚 Java开发工程师.pdf"
Content-Type: application/pdf
%PDF-1.7
%³
1 0 obj
<</Names <</Dests 4 0 R>> /Outlines 5 0 R /Pages 2 0 R /Type /Catalog>>
endobj
3 0 obj
<</Author ( N v~N•) /Comments () /Company () /CreationDate
(D:20201122145133+06'51') /Creator ( W P S e [W) /Keywords () /ModDate
(D:20201122145133+06'51') /Producer () /SourceModified (D:20201122145133+06'51')
/Subject () /Title () /Trapped /False>>
endobj
13 0 obj
<</AIS false /BM /Normal /CA 1 /Type /ExtGState /ca 1>>
endobj
实际的抓包结果比较长, 此处没有全部贴出.
3) application/json
抓取比特教务系统的登陆页面 https://v.bitedu.vip/login
POST https://v.bitedu.vip/tms/login HTTP/1.1
Host: v.bitedu.vip
Connection: keep-alive
Content-Length: 105
sec-ch-ua: " Not;A Brand";v="99", "Google Chrome";v="91", "Chromium";v="91"
sec-ch-ua-mobile: ?0
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML,
like Gecko) Chrome/91.0.4472.101 Safari/537.36
Access-Control-Allow-Methods: PUT,POST,GET,DELETE,OPTIONS
Content-Type: application/json;charset=UTF-8
Access-Control-Allow-Origin: *
Accept: application/json, text/plain, */*
Access-Control-Allow-Headers: Content-Type, Content-Length, Authorization,
Accept, X-Requested-With , yourHeaderFeild
Origin: https://v.bitedu.vip
Sec-Fetch-Site: same-origin
Sec-Fetch-Mode: cors
Sec-Fetch-Dest: empty
Referer: https://v.bitedu.vip/login
Accept-Encoding: gzip, deflate, br
Accept-Language: zh-CN,zh;q=0.9,en;q=0.8
Cookie: rememberMe=true; username=123456789
{"username":"123456789","password":"xxxx","code":"u58u","uuid":"9bd8e09ea27b48cd
acc6a6bc41d9f462"}
HTTP 响应详解
认识 “状态码” (status code)
状态码表示访问一个页面的结果. (是访问成功, 还是失败, 还是其他的一些情况…).
以下为常见的状态码.
200 OK
这是一个最常见的状态码, 表示访问成功. 抓包抓到的大部分结果都是 200 例如访问搜狗主页
HTTP/1.1 200 OK
Server: nginx
Date: Thu, 10 Jun 2021 06:07:27 GMT
Content-Type: text/html; charset=utf-8
Connection: keep-alive
Vary: Accept-Encoding
Set-Cookie: black_passportid=; path=/; expires=Thu, 01 Jan 1970 00:00:00
GMT; domain=.sogou.com
Pragma: No-cache
Cache-Control: max-age=0
Expires: Thu, 10 Jun 2021 06:07:27 GMT
UUID: 80022370-065c-49b0-a970-31bc467ff244
Content-Length: 14805
<!DOCTYPE html><html lang="cn"><head><meta name="viewport"
content="width=device-width,minimum-scale=1,maximum-scale=1,user-
scalable=no"><script>window._speedMark = new Date(); window.lead_ip =
'1.80.175.234';
......
注意: 在抓包观察响应数据的时候, 可能会看到压缩之后的数据, 形如:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-h75FF7HT-1654501679467)(media/0d16fffd923e4eedaf352d43aa7507ea.png)]](https://img-blog.csdnimg.cn/0b2b967dac584e5ba1bb03b07df7e191.png)
网络传输中 “带宽” 是一个稀缺资源, 为了传输效率更高往往会对数据进行压缩.
点击 Fiddler 中的
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-o7RL1DSS-1654501679467)(media/b2a9c982e3bcdeed8be1f79fe5fd79c5.png)]](https://img-blog.csdnimg.cn/339d0ba1ee0941e4aa51e8ceff890a64.png)
即可进行解压缩, 看到原始的内容.
404 Not Found
没有找到资源.
浏览器输入一个 URL, 目的就是为了访问对方服务器上的一个资源. 如果这个 URL 标识的资源不存 在, 那么就会出现 404
例如, 在浏览器中输入 www.sogou.com/index.html , 此时就在尝试访问 sogou 上的/index.html 这个资源.
如果输入正确, 则可以正确访问到. 但是如果输入错误, 比如 www.sogou.com/index2.html , 就 会看到 404 这样的响应.
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-0De1LJ12-1654501679467)(media/739e80a97b8fb5f5c7a80d3723a2f745.png)]](https://img-blog.csdnimg.cn/e6b5867cf2f941e4b7ba806d0dbbc262.png)
HTTP/1.1 404 Not Found
Server: nginx
Date: Thu, 10 Jun 2021 05:19:04 GMT
Content-Type: text/html
Connection: keep-alive
Vary: Accept-Encoding
Content-Length: 564
<html>
<head><title>404 Not Found</title></head>
<body bgcolor="white">
<center><h1>404 Not Found</h1></center>
<hr><center>nginx</center>
</body>
</html>
403 Forbidden
表示访问被拒绝. 有的页面通常需要用户具有一定的权限才能访问(登陆后才能访问). 如果用户没有登陆直接访问, 就容易见到 403.
例如: 查看码云的私有仓库, 如果不登陆, 就会出现 403. 参考链接: https://gitee.com/HGtz2222/b log_python
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-HtT0FegM-1654501679468)(media/7a74ec001fa7ba2a28488a107c4b249c.jpeg)]](https://img-blog.csdnimg.cn/60b61e081b8c4f6f986cd9a674f2b8e8.jpeg)
HTTP/1.1 403 Forbidden
Date: Thu, 10 Jun 2021 06:05:36 GMT
Content-Type: text/html; charset=utf-8
Connection: keep-alive
Keep-Alive: timeout=60
Server: nginx
Vary: Accept-Encoding
X-XSS-Protection: 1; mode=block
X-Content-Type-Options: nosniff
X-UA-Compatible: chrome=1
Expires: Sun, 1 Jan 2000 01:00:00 GMT
Pragma: must-revalidate, no-cache, private
Cache-Control: no-cache
Set-Cookie: oschina_new_user=false; path=/; expires=Mon, 10 Jun 2041
06:05:40 -0000
Set-Cookie: gitee-session-
n=ejEvQnYza2RlaXh0KzRaN3QrNWI2TzdLOE03bU5UNjRKdGlqWUFkMlJ2YktWYTRtcEtIVExOZ
EdJSFJFSkdiWmcxNmhjSTdneUZFaHFtalNKQUJWcDlUNDZYd2lBaElXNy9FaWRHQkl4d2RsS1RI
WnRCNFphQm5JUjZOdjdsSDh5TlNvZ3hZdTBXNXUrU2c2azN2UVNFOWwyQnJvQzZ6MEluaEFFYnR
oV0luOFlNWEEzWlR0K1g4WDlQRjNkSlNjZ1pUMGc0YkhreVNJMUV4YkVUUk0weXFqbGhQYzN5dj
A2bFJyc3o4MHRVWkkxcHdQVG5abmJ2NmlqV1dEYjlWaUpNNno3UGFpZ3lsb1RqeXAranFHRlE9P
S0tdU5JMGZ3UUpwODRYdjF1MXdyYmFKUT09-
-52babe9c2dcb63fa02bc32d25bc0e854f4065f5f; domain=.gitee.com; path=/;
HttpOnly
X-Request-Id: 82a740fb98838c305c4cc597ab6f48c0
X-Runtime: 0.020299
Content-Length: 7092
<!DOCTYPE html>
<html>
<head>
<meta http-equiv="Content-Type" content="text/html; charset=UTF-8" />
<title>您的访问受限 (403)</title>
......
405 Method Not Allowed
前面我们已经学习了 HTTP 中所支持的方法, 有 GET, POST, PUT, DELETE 等.
但是对方的服务器不一定都支持所有的方法(或者不允许用户使用一些其他的方法).
这种情况我们后面学习了 Servlet 再演示.
500 Internal Server Error
服务器出现内部错误. 一般是服务器的代码执行过程中遇到了一些特殊情况(服务器异常崩溃)会产生这个 状态码.
咱们平时常用的网站很少会出现 500 (但是偶尔也能看到).
这种情况我们后面学习了 Servlet 再演示.
504 Gateway Timeout
当服务器负载比较大的时候, 服务器处理单条请求的时候消耗的时间就会很长, 就可能会导致出现超时的 情况.
这种情况在双十一等 “秒杀” 场景中容易出现, 平时不太容易见到.
302 Move temporarily
临时重定向.
理解 “重定向”
就相当于手机号码中的 “呼叫转移” 功能.
比如我本来的手机号是 186-1234-5678, 后来换了个新号码 135-1234-5678, 那么不需要让我的朋 友知道新号码,
只要我去办理一个呼叫转移业务, 其他人拨打 186-1234-5678 , 就会自动转移到 135-1234-5678上.
在登陆页面中经常会见到 302. 用于实现登陆成功后自动跳转到主页. 响应报文的 header 部分会包含一个 Location 字段, 表示要跳转到哪个页面.
例如: 码云的登陆页面 https://gitee.com/login
抓包看到的响应结果:
HTTP/1.1 302 Found
Date: Thu, 10 Jun 2021 06:49:26 GMT
Content-Type: text/html; charset=utf-8
Connection: keep-alive
Keep-Alive: timeout=60
Server: nginx
X-XSS-Protection: 1; mode=block
X-Content-Type-Options: nosniff
X-UA-Compatible: chrome=1
Expires: Sun, 1 Jan 2000 01:00:00 GMT
Pragma: must-revalidate, no-cache, private
Location: https://gitee.com/HGtz2222
Cache-Control: no-cache
Set-Cookie: oschina_new_user=false; path=/; expires=Mon, 10 Jun 2041
06:49:24 -0000
Set-Cookie: gitee_user=true; path=/
Set-Cookie: gitee-session-
n=UG5CdVZQUkVUamxsWis3b0JoL2dyTDRLVTk1WXVCK2VwaGd0OGFKdjBjdjB4K0RiWTh2ZmhrZ
GM1cU0vOFN2VGdNcVY5dU5rSzZHeVFBcVZ3OTBaSmZmZzRYQUdsa2tHMnFIeU9SQlN4Z2pleDNM
Y3ExZUF6QWpHTHlVeTZOWFVHSVBxbTVuZGJpandHekdaRVBTUVd0ejZUNHNvTllSODBiNHd6NWN
CRUZ0UzZCZW1mRTBZUUdmOE5JTWVKdnJMMzdQcHFBMk5nUmNjMWpmc3daTElYU2hhbkEwQm41NH
NlZ2RwM3QxSjZMTndSNjcyNDd6YUVoS0ZmUWpLTDQ2KzlzZVowZTFLaUNPTmVDajVOb2k0MWFRc
GkzWVQ2QUxuWXJLeTRqL2JHaUE9LS0xYlVDOWVkc0JiM2xucVk0am1LRHFnPT0%3D-
-58854ce81d6c67bb7b9a0fdd6fe18a8ebdb3d753; domain=.gitee.com; path=/;
HttpOnly
X-Request-Id: d45ade01dbeffc99a3688d3411b3381f
X-Runtime: 0.133587
Content-Length: 92
<html><body>You are being <a
href="https://gitee.com/HGtz2222">redirected</a>.</body></html>
可以看到 header 中的Location: https://gitee.com/HGtz2222, 接下来浏览器就会自动发送GET 请求, 获取https://gitee.com/HGtz2222
301 Moved Permanently
永久重定向. 当浏览器收到这种响应时, 后续的请求都会被自动改成新的地址.
301 也是通过 Location 字段来表示要重定向到的新地址.
状态码小结
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-lsXGloM4-1654501679468)(media/22926528a7e6e9347c7fe12aa605e482.jpeg)]](https://img-blog.csdnimg.cn/383ea0e8c5cb4858b73cf23e3d09fb95.jpeg)
认识响应 “报头” (header)
响应报头的基本格式和请求报头的格式基本一致.
类似于 Content-Type , Content-Length 等属性的含义也和请求中的含义一致.
Content-Type
响应中的 Content-Type 常见取值有以下几种:
text/html : body 数据格式是 HTML
text/html: body 数据格式是 HTMLtext/css: body 数据格式是 CSSapplication/javascript: body 数据格式是 JavaScriptapplication/json: body 数据格式是 JSON
在教务系统主页, 通过 ctrl + F5 方式强制刷新, 这四种都能看到
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-dgw9w1hn-1654501679469)(media/0b236c4c7757d9325f3e648aa24e5841.jpeg)]](https://img-blog.csdnimg.cn/957307ae1d5d4b51b464099902a51897.jpeg)
关于 Content-Type 的详细情况: https://developer.mozilla.org/en-US/docs/Web/HTTP/Basics_of_HT TP/MIME_types
认识响应 “正文” (body)
正文的具体格式取决于 Content-Type. 观察上面几个抓包结果中的响应部分.
1) text/html
Server: nginx/1.17.3
Date: Thu, 10 Jun 2021 07:25:09 GMT
Content-Type: text/html; charset=utf-8
Last-Modified: Thu, 13 May 2021 09:01:26 GMT
Connection: keep-alive
ETag: W/"609ceae6-3206"
Content-Length: 12806
<!DOCTYPE html><html><head><meta charset=utf-8><meta http-equiv=X-UA-Compatible
content="IE=edge,chrome=1"><meta name=renderer content=webkit><meta
name=viewport content="width=device-width,initial-scale=1,minimum-
scale=1,maximum-scale=1,user-scalable=no"><link rel=icon href=/favicon.ico>
<title id=bodyTitle>比特教务管理系统</title><link
href=https://cdn.bootcss.com/jquery-
datetimepicker/2.5.20/jquery.datetimepicker.css rel=stylesheet><script
src=https://cdn.bootcss.com/highlight.js/9.1.0/highlight.min.js></script><script
src=https://cdn.bootcss.com/highlightjs-line-numbers.js/2.5.0/highlightjs-line-
numbers.min.js></script><style>html,
body,
#app {
height: 100%;
margin: 0px;
padding: 0px;
}
.chromeframe {
margin: 0.2em 0;
background: #ccc;
color: #000;
padding: 0.2em 0;
}
#loader-wrapper {
position: fixed;
top: 0;
left: 0;
width: 100%;
height: 100%;
z-index: 999999;
}
......
2) text/css
HTTP/1.1 200 OK
Server: nginx/1.17.3
Date: Thu, 10 Jun 2021 07:25:09 GMT
Content-Type: text/css
Last-Modified: Thu, 13 May 2021 09:01:26 GMT
Connection: keep-alive
ETag: W/"609ceae6-3cfbe"
Content-Length: 249790
@font-face{font-family:element-icons;src:url(../../static/fonts/element-
icons.535877f5.woff) format("woff"),url(../../static/fonts/element-
icons.732389de.ttf) format("truetype");font-weight:400;font-style:normal}
[class*=" el-icon-"],
......
3) application/javascript
HTTP/1.1 200 OK
Server: nginx/1.17.3
Date: Thu, 10 Jun 2021 07:25:09 GMT
Content-Type: application/javascript; charset=utf-8
Last-Modified: Thu, 13 May 2021 09:01:26 GMT
Connection: keep-alive
ETag: W/"609ceae6-427d4"
Content-Length: 272340
(window["webpackJsonp"]=window["webpackJsonp"]||[]).push([["app"],
{0:function(t,e,n){t.exports=n("56d7")},"00b3":function(t,e,n){},"
......
4) application/json
HTTP/1.1 200
Server: nginx/1.17.3
Date: Thu, 10 Jun 2021 07:25:10 GMT
Content-Type: application/json;charset=UTF-8
Connection: keep-alive
X-Content-Type-Options: nosniff
X-XSS-Protection: 1; mode=block
Cache-Control: no-cache, no-store, max-age=0, must-revalidate
Pragma: no-cache
Expires: 0
vary: accept-encoding
Content-Length: 12268
{"msg":"操作成功","code":200,"permissions":[] }
通过 form 表单构造 HTTP 请求
form (表单) 是 HTML 中的一个常用标签. 可以用于给服务器发送 GET 或者 POST 请求.
不要把 form 拼写成 from!!
form 发送 GET 请求
form 的重要参数:
- action: 构造的 HTTP 请求的 URL 是什么.
- method: 构造的 HTTP 请求的 方法 是 GET 还是 POST (form 只支持 GET 和 POST).
input 的重要参数:
- type: 表示输入框的类型. text 表示文本, password 表示密码, submit 表示提交按钮.
- name: 表示构造出的 HTTP 请求的 query string 的 key. query string 的 value就是输入框的用户 输入的内容.
- value: input 标签的值. 对于 type 为 submit 类型来说, value 就对应了按钮上显示的文本.
<form action="http://abcdef.com/myPath" method="GET">
<input type="text" name="userId">
<input type="text" name="classId">
<input type="submit" value="提交">
</form>
页面展示的效果:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-AGShanp8-1654501679469)(media/b7e3efe921e4f45a087beb744bd31a50.png)]](https://img-blog.csdnimg.cn/e780505442ca4e80a491d429041054de.png)
在输入框随便填写数据,
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-AhfsLsWv-1654501679469)(media/4d54655a231a4397b701a5f9a4524e21.png)]](https://img-blog.csdnimg.cn/91a94cfc2bca4d63918aa993ddb7638b.png)
点击 “提交”, 此时就会构造出 HTTP 请求并发送出去.
构造的 HTTP 请求
GET http://abcdef.com/myPath?userId=100&classId=200 HTTP/1.1
Host: abcdef.com
Proxy-Connection: keep-alive
Upgrade-Insecure-Requests: 1
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML,
like Gecko) Chrome/91.0.4472.114 Safari/537.36
Accept:
text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,imag
e/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9
Accept-Encoding: gzip, deflate
Accept-Language: zh-CN,zh;q=0.9,en;q=0.8
注意: 由于我们的服务器的地址是随便写的, 因此无法获取到正确的 HTTP 响应.
体会 form 代码和 HTTP 请求之间的对应关系
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ybHuefIR-1654501679469)(media/81b2a1b8ec0e6e281ebb2b1bb96d0124.jpeg)]](https://img-blog.csdnimg.cn/d5513c1cfb1b44d2a39b74f21944f8b1.jpeg)
- form 的 action 属性对应 HTTP 请求的 URL
- form 的 method 属性对应 HTTP 请求的方法
- input 的 name 属性对应 query string 的 key
- input 的 内容 对应 query string 的 value
form 发送 POST 请求
修改上面的代码, 把 form 的 method 修改为 POST
<form action="http://abcdef.com/myPath" method="GET">
<input type="text" name="userId">
<input type="text" name="classId">
<input type="submit" value="提交">
</form>
页面效果不变.
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-IRBSJnDC-1654501679470)(media/b7e3efe921e4f45a087beb744bd31a50.png)]](https://img-blog.csdnimg.cn/873ee2e8324448a191eec06a7e88f4e6.png)
构造的 HTTP 请求
POST http://abcdef.com/myPath HTTP/1.1
Host: abcdef.com
Proxy-Connection: keep-alive
Content-Length: 22
Cache-Control: max-age=0
Upgrade-Insecure-Requests: 1
Origin: null
Content-Type: application/x-www-form-urlencoded
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML,
like Gecko) Chrome/91.0.4472.114 Safari/537.36
Accept:
text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,imag
e/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9
Accept-Encoding: gzip, deflate
Accept-Language: zh-CN,zh;q=0.9,en;q=0.8
userId=100&classId=200
主要的区别:
- method 从 GET 变成了 POST
- 数据从 query string 移动到了 body 中.
使用 form 还可以提交文件. 后面再介绍.
通过 ajax 构造 HTTP 请求
从前端角度, 除了浏览器地址栏能构造 GET 请求, form 表单能构造 GET 和 POST 之外, 还可以通过 ajax的方式来构造 HTTP 请求. 并且功能更强大.
ajax 全称 Asynchronous Javascript And XML, 是 2005 年提出的一种
JavaScript 给服务器发送HTTP 请求的方式. 特点是可以不需要 刷新页面/页面跳转 就能进行数据传输.
在 JavaScript 中可以通过 ajax 的方式构造 HTTP 请求.
注意: 为了验证 ajax 的功能, 需要提前准备好一份配套的服务器程序.
这个代码已经部署在
http://42.192.83.143:8080/AjaxMockServer/info.
同学们也可以通过这个链接来访问服务器.
发送 GET 请求
创建 test.html, 在<script>标签中编写以下代码.
// 1. 创建 XMLHttpRequest 对象
let httpRequest = new XMLHttpRequest();
// 2. 默认异步处理响应. 需要挂在处理响应的回调函数.
httpRequest.onreadystatechange = function () {
// readState 表示当前的状态.
// 0: 请求未初始化
// 1: 服务器连接已建立
// 2: 请求已接收
// 3: 请求处理中
// 4: 请求已完成,且响应已就绪
if (httpRequest.readyState == 4) {
// status 属性获取 HTTP 响应状态码
console.log(httpRequest.status);
// responseText 属性获取 HTTP 响应 body
console.log(httpRequest.responseText);
}
}
// 3. 调用 open 方法设置要访问的 url
httpRequest.open('GET', 'http://42.192.83.143:8080/AjaxMockServer/info');
// 4. 调用 send 方法发送 http 请求
httpRequest.send();
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-kt9XqQQn-1654501679470)(media/e7cfaa5a7b85fb49e656a29ceff63db8.png)]](https://img-blog.csdnimg.cn/01603119b25e4d03b87bbb220e5a8aff.png)
注意: 如果把 send 中的地址改成其他服务器的地址(比如 http://www.sogou.com/index.html 这 种), 大概率是会出错的.
错误形如:
这个错误是因为 ajax 默认不能 “跨域”, 也就是 “百度下面的 html 中的 ajax 不能访问 搜狗 的内 容”.
这样的设定也是完全合理的.如果想要强行进行跨域, 则需要服务器进行配合, 在服务器的响应中 “允许跨域” 才可以.
咱们的示例服务器
42.192.83.143:8080/AjaxMockServer/info进行了允许跨域设置, 因此我
们的页面才能访问到其中的数据.关于 跨域 这个话题, 此处不深入讨论.
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-mDwuPtZy-1654501679471)(media/f11b164f795c08d7665cf4260029685e.jpeg)]](https://img-blog.csdnimg.cn/7478c01940b04dc8a360ed1a8c699bbd.jpeg)
浏览器和服务器交互过程(引入 ajax 后):
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-8yYQsFka-1654501679471)(media/22a7477ea19224e279d3d8c52a367eef.png)]](https://img-blog.csdnimg.cn/8094b514e52745eeb2db8556162b65ca.png)
在我们当前的例子中, test.html 是通过本地文件的方式打开的, 这个环节不涉及 HTTP 交互.
后面我们把 test.html 放到 Tomcat 上, 就会产生上面的效果了.
发送 POST 请求
对于 POST 请求, 需要设置 body 的内容
- 先使用 setRequestHeader 设置 Content-Type 2.
- 再通过 send 的参数设置 body 内容.
发送 application/x-www-form-urlencoded 数据 (数据格式同 form 的 post)
// 1. 创建 XMLHttpRequest 对象
let httpRequest = new XMLHttpRequest();
// 2. 默认异步处理响应. 需要挂在处理响应的回调函数.
httpRequest.onreadystatechange = function () {
// readState 表示当前的状态.
// 0: 请求未初始化
// 1: 服务器连接已建立
// 2: 请求已接收
// 3: 请求处理中
// 4: 请求已完成,且响应已就绪
if (httpRequest.readyState == 4) {
// status 属性获取 HTTP 响应状态码
console.log(httpRequest.status);
// responseText 属性获取 HTTP 响应 body
console.log(httpRequest.responseText);
}
}
// 3. 调用 open 方法设置要访问的 url
httpRequest.open('POST', 'http://42.192.83.143:8080/AjaxMockServer/info');
// 4. 调用 setRequestHeader 设置请求头
httpRequest.setRequestHeader('Content-Type', 'application/x-www-form-
urlencoded');
// 5. 调用 send 方法发送 http 请求
httpRequest.send('name=zhangsan&age=18');
发送 application/json 数据
// 4. 调用 setRequestHeader 设置请求头
httpRequest.setRequestHeader('Content-Type', 'application/json');
// 5. 调用 send 方法发送 http 请求
httpRequest.send(JSON.stringify({
name: 'zhangsan',
age: 18
}));
其他代码不变, 只是改下方的代码.
封装 ajax 方法
原生的 XMLHTTPRequest 类使用并不方便. 我们可以在这个基础上进行简单封装.
// 参数 args 是一个 JS 对象, 里面包含了以下属性
// method: 请求方法
// url: 请求路径
// body: 请求的正文数据
// contentType: 请求正文的格式
// callback: 处理响应的回调函数, 有两个参数, 响应正文和响应的状态码
function ajax(args) {
var xhr = new XMLHttpRequest();
xhr.onreadystatechange = function () {
// 0: 请求未初始化
// 1: 服务器连接已建立
// 2: 请求已接收
// 3: 请求处理中
// 4: 请求已完成,且响应已就绪
if (xhr.readyState == 4) {
args.callback(xhr.responseText, xhr.status)
}
}
xhr.open(args.method, args.url);
if (args.contentType) {
xhr.setRequestHeader('Content-type', args.contentType);
}
if (args.body) {
xhr.send(args.body);
} else {
xhr.send();
}
}
// 调用该函数
ajax({
method: 'get',
url: '/info',
callback: function (body, status) {
console.log(status);
console.log(body);
}
});
附录: ajax 测试服务器代码 (后面再讲解)
基于 Java Servlet 实现的简单的服务器代码. 后面学习到 Servlet 部分再讲解.
@WebServlet("/info")
public class AjaxMock extends HttpServlet {
@Override
protected void doGet(HttpServletRequest req, HttpServletResponse resp)
throws ServletException, IOException {
setAccess(resp);
resp.setStatus(200);
resp.setContentType("text/plain; charset=utf-8");
resp.getWriter().write("ajax get 方法");
}
@Override
protected void doPost(HttpServletRequest req, HttpServletResponse resp)
throws ServletException, IOException {
setAccess(resp);
resp.setStatus(200);
resp.setContentType("text/plain; charset=utf-8");
resp.getWriter().write("ajax post 方法");
}
@Override
protected void doPut(HttpServletRequest req, HttpServletResponse resp)
throws ServletException, IOException {
setAccess(resp);
resp.setStatus(200);
resp.setContentType("text/plain; charset=utf-8");
resp.getWriter().write("ajax put 方法");
}
@Override
protected void doDelete(HttpServletRequest req, HttpServletResponse resp)
throws ServletException, IOException {
setAccess(resp);
resp.setStatus(200);
resp.setContentType("text/plain; charset=utf-8");
resp.getWriter().write("ajax delete 方法");
}
@Override
protected void doOptions(HttpServletRequest req, HttpServletResponse resp)
throws ServletException, IOException {
// 对于 PUT / DELETE 这样的请求 浏览器 会先发一个 OPTIONS 请求进行预检.
// 如果拿到的结果没有允许跨域的头部信息, 则后续的发送就失败了.
setAccess(resp);
resp.setStatus(200);
resp.setContentType("text/plain; charset=utf-8");
resp.getWriter().write("ajax option 方法");
}
// 配置跨域
private void setAccess(HttpServletResponse resp) {
resp.setHeader("Access-Control-Allow-Origin", "*");
resp.setHeader("Access-Control-Allow-Headers", "*");
resp.setHeader("Access-Control-Allow-Methods", "*");
}
}
通过 Java socket 构造 HTTP 请求
所谓的 “发送 HTTP 请求”, 本质上就是按照 HTTP 的格式往 TCP Socket 中写入一个字符串.
所谓的 “接受 HTTP 响应”, 本质上就是从 TCP Socket 中读取一个字符串, 再按照 HTTP 的格式来解析.
我们基于 Socket 的知识, 完全可以构造出一个简单的 HTTP 客户端程序, 用来发送各种类型的 HTTP 请 求.
public class HttpClient {
private Socket socket;
private String ip;
private int port;
public HttpClient(String ip, int port) throws IOException {
this.ip = ip;
this.port = port;
socket = new Socket(ip, port);
}
public String get(String url) throws IOException {
StringBuilder request = new StringBuilder();
// 构造首行
request.append("GET " + url + " HTTP/1.1\n");
// 构造 header
request.append("Host: " + ip + ":" + port + "\n");
// 构造 空行
request.append("\n");
// 发送数据
OutputStream outputStream = socket.getOutputStream();
outputStream.write(request.toString().getBytes());
// 读取响应数据
InputStream inputStream = socket.getInputStream();
byte[] buffer = new byte[1024 * 1024];
int n = inputStream.read(buffer);
return new String(buffer, 0, n, "utf-8");
}
public String post(String url, String body) throws IOException {
StringBuilder request = new StringBuilder();
// 构造首行
request.append("POST " + url + " HTTP/1.1\n");
// 构造 header
request.append("Host: " + ip + ":" + port + "\n");
request.append("Content-Length: " + body.getBytes().length + "\n");
request.append("Content-Type: text/plain\n");
// 构造 空行
request.append("\n");
// 构造 body
request.append(body);
// 发送数据
OutputStream outputStream = socket.getOutputStream();
outputStream.write(request.toString().getBytes());
// 读取响应数据
InputStream inputStream = socket.getInputStream();
byte[] buffer = new byte[1024 * 1024];
int n = inputStream.read(buffer);
return new String(buffer, 0, n, "utf-8");
}
public static void main(String[] args) throws IOException {
HttpClient httpClient = new HttpClient("42.192.83.143", 8080);
String getResp = httpClient.get("/AjaxMockServer/info");
System.out.println(getResp);
String postResp = httpClient.post("/AjaxMockServer/info", "this is
body");
System.out.println(postResp);
}
}
使用 Java 构造的 HTTP 客户端不再有 “跨域” 限制了, 此时也可以用来获取其他服务器的数据了.
跨域只是浏览器的行为, 对于 ajax 有效. 对于其他语言来说一般都和跨域无关.
HttpClient httpClient = new HttpClient("www.sogou.com", 80);
String resp = httpClient.get("/index.html");
System.out.println(resp);
// 此时可以获取到 搜狗主页 的 html
HTTPS
HTTPS 是什么
HTTPS 也是一个应用层协议. 是在 HTTP 协议的基础上引入了一个加密层.
HTTP 协议内容都是按照文本的方式明文传输的. 这就导致在传输过程中出现一些被篡改的情况.
臭名昭著的 “运营商劫持”
下载一个 天天动听
未被劫持的效果, 点击下载按钮, 就会弹出天天动听的下载链接.
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-taapOnIw-1654501679471)(media/18479a1a02aed1ab73633bef4eaafdee.jpeg)]](https://img-blog.csdnimg.cn/a27f676c06334327baf8b8ca2779ada9.jpeg)
已被劫持的效果, 点击下载按钮, 就会弹出 QQ 浏览器的下载链接
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-q2oDH4ZF-1654501679472)(media/7614e0623ae5ad13cf3632f97887ea39.jpeg)]](https://img-blog.csdnimg.cn/8375d95ec1194e9aaa79b5a9fff4f03d.jpeg)
由于我们通过网络传输的任何的数据包都会经过运营商的网络设备(路由器, 交换机等), 那么运营商的网 络设备就可以解析出你传输的数据内容, 并进行篡改.
点击 “下载按钮”, 其实就是在给服务器发送了一个 HTTP 请求, 获取到的 HTTP 响应其实就包含了该 APP 的下载链接. 运营商劫持之后, 就发现这个请求是要下载天天动听, 那么就自动的把交给用户的响应给篡 改成 “QQ浏览器” 的下载地址了.
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Y3gvfLk4-1654501679472)(media/0d398e6cf26ad08f5010f7232d3b640d.jpeg)]](https://img-blog.csdnimg.cn/30d401b561904229bd33734f903160c9.jpeg)
思考下, 为啥运营商要进行劫持?
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-elqjwWfT-1654501679472)(media/a91a01318d06e934225bd1022e2d6a5d.jpeg)]](https://img-blog.csdnimg.cn/9e4339a2c01045f1a9852bbcc4f0a571.jpeg)
不止运营商可以劫持, 其他的 黑客 也可以用类似的手段进行劫持, 来窃取用户隐私信息, 或者篡改内容. 试想一下, 如果黑客在用户登陆支付宝的时候获取到用户账户余额, 甚至获取到用户的支付密码…
在互联网上, 明文传输是比较危险的事情!!!
HTTPS 就是在 HTTP 的基础上进行了加密, 进一步的来保证用户的信息安全~
“加密” 是什么
加密就是把 明文 (要传输的信息)进行一系列变换, 生成 密文 .
解密就是把 密文 再进行一系列变换, 还原成 明文 .
在这个加密和解密的过程中, 往往需要一个或者多个中间的数据, 辅助进行这个过程, 这样的数据称为 密 钥 (正确发音 yue 四声, 不过大家平时都读作 yao 四声) .
83 版 <<火烧圆明园>> , 有人要谋反干掉慈禧太后. 恭亲王奕䜣给慈禧递的折子. 折子内容只是扯 一扯家常,
套上一张挖了洞的纸就能看到真实要表达的意思.明文: “当心肃顺, 端华, 戴恒” (这几个人都是当时的权臣, 后来被慈禧一锅端). 密文: 奏折全文
密钥: 挖了洞的纸.
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-u5oiFCaM-1654501679472)(media/09a1c590352dae9489cbaa0db01bbc81.jpeg)]](https://img-blog.csdnimg.cn/ef27c5fa301d4e2c887434c7ed3ff77e.jpeg)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-GMD8yprR-1654501679473)(media/1e5c82669a8027b73de53375d625cbbe.jpeg)]](https://img-blog.csdnimg.cn/eb86e1a4e78e4552a594b4ebc5034639.jpeg)
加密解密到如今已经发展成一个独立的学科: 密码学. 而密码学的奠基人, 也正是计算机科学的祖师爷之一, 艾伦·麦席森·图灵
可能有的童鞋觉得画风不太对, 咋是如此帅气的小哥哥???
对比我们另一位祖师爷冯诺依曼
好像图灵大佬的头发有点多…
其实这是一个悲伤的故事. 图灵大佬年少有为, 不光奠定了计算机, 人工智能, 密码学的基础, 并且在 二战中大破德军的 Enigma 机,
使盟军占尽情报优势, 才能扭转战局反败为胜. 但是因为一些原因, 图灵大佬遭到英国皇室的迫害, 41岁就英年早逝了.计算机领域中的最高荣誉就是以他名字命名的 “图灵奖” .
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-JDrAlVmx-1654501679473)(media/fe69d236cc457dc4f43374a3540ad4e8.jpeg)]](https://img-blog.csdnimg.cn/c2bf5a90574f46bda68778791121042e.jpeg)

HTTPS 的工作过程
既然要保证数据安全, 就需要进行 “加密”. 网络传输中不再直接传输明文了, 而是加密之后的 “密文”. 加密的方式有很多, 但是整体可以分成两大类: 对称加密 和 非对称加密
引入对称加密
对称加密其实就是通过同一个 “密钥” , 把明文加密成密文, 并且也能把密文解密成明文.
一个简单的对称加密, 按位异或
假设 明文 a = 1234, 密钥 key = 8888
则加密 a ^ key 得到的密文 b 为 9834.
然后针对密文 9834 再次进行运算 b ^ key, 得到的就是原来的明文 1234. (对于字符串的对称加密也是同理,每一个字符都可以表示成一个数字)
当然, 按位异或只是最简单的对称加密. HTTPS 中并不是使用按位异或.
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-19kkHF8j-1654501679473)(media/0fe145e80fe9b9d731a1a098d43338ac.jpeg)]](https://img-blog.csdnimg.cn/0cd91b6db59441b293278133bb20e787.jpeg)
引入对称加密之后, 即使数据被截获, 由于黑客不知道密钥是啥, 因此就无法进行解密, 也就不知道请求的 真实内容是啥了.
但事情没这么简单. 服务器同一时刻其实是给很多客户端提供服务的. 这么多客户端, 每个人用的秘钥都 必须是不同的(如果是相同那密钥就太容易扩散了, 黑客就也能拿到了). 因此服务器就需要维护每个客户 端和每个密钥之间的关联关系, 这也是个很麻烦的事情~
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-BvOLH3ex-1654501679474)(media/63d5a31cebaab975cf54ad571739acf1.png)]](https://img-blog.csdnimg.cn/0e4d3130c55c49c3b39df9b27e8b7157.png)
比较理想的做法, 就是能在客户端和服务器建立连接的时候, 双方协商确定这次的密钥是啥~
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-4okmgI9W-1654501679474)(media/f3eeeb52f004091f97d7ad9c797fcdee.jpeg)]](https://img-blog.csdnimg.cn/08419852193b4d6c95bcf1c933d98820.jpeg)
但是如果直接把密钥明文传输, 那么黑客也就能获得密钥了~~ 此时后续的加密操作就形同虚设了.
因此密钥的传输也必须加密传输!
但是要想对密钥进行对称加密, 就仍然需要先协商确定一个 “密钥的密钥”. 这就成了 "先有鸡还是先有蛋"的问题了. 此时密钥的传输再用对称加密就行不通了.
就需要引入非对称加密.
引入非对称加密
非对称加密要用到两个密钥, 一个叫做 “公钥”, 一个叫做 “私钥”.
公钥和私钥是配对的. 最大的缺点就是运算速度非常慢,比对称加密要慢很多.
- 通过公钥对明文加密, 变成密文
- 通过私钥对密文解密, 变成明文
也可以反着用
- 通过私钥对明文加密, 变成密文
- 通过公钥对密文解密, 变成明文
非对称加密的数学原理比较复杂, 涉及到一些 数论 相关的知识. 这里举一个简单的生活上的例子. A 要给 B 一些重要的文件, 但是
B 可能不在. 于是 A 和 B 提前做出约定:B 说: 我桌子上有个盒子, 然后我给你一把锁, 你把文件放盒子里用锁锁上, 然后我回头拿着钥匙来 开锁取文件.
在这个场景中, 这把锁就相当于公钥, 钥匙就是私钥. 公钥给谁都行(不怕泄露), 但是私钥只有 B 自 己持有. 持有私钥的人才能解密.
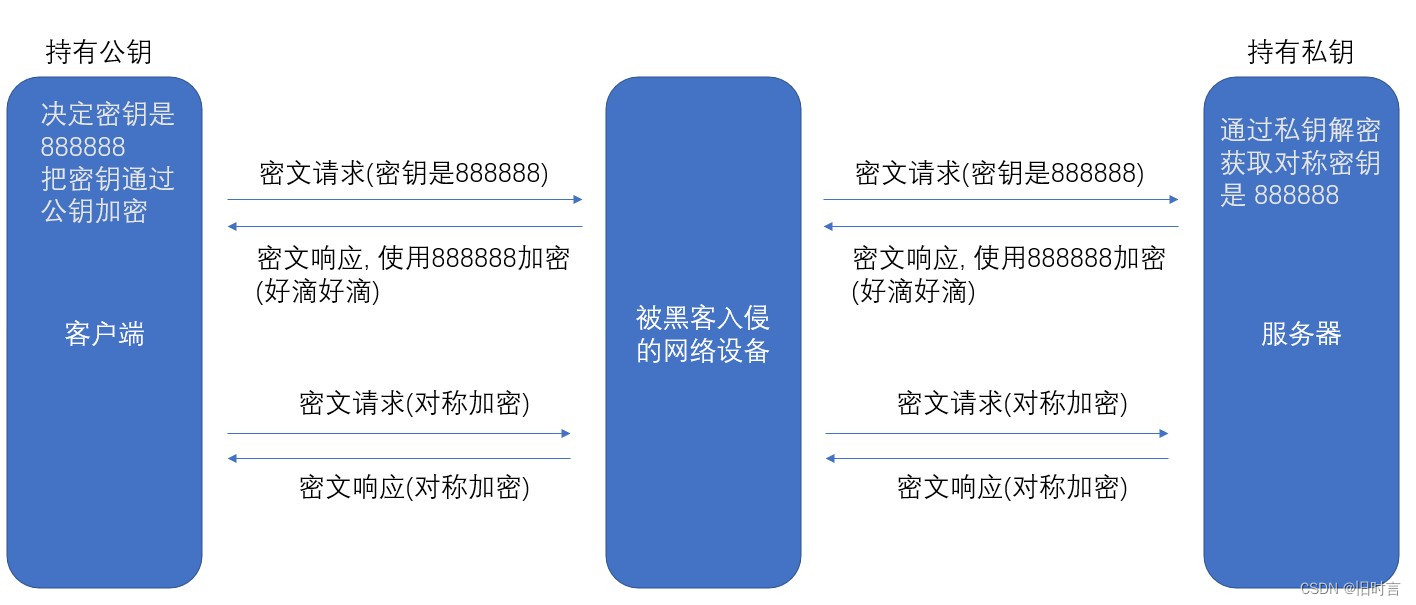
- 客户端在本地生成对称密钥, 通过公钥加密, 发送给服务器.
- 由于中间的网络设备没有私钥, 即使截获了数据, 也无法还原出内部的原文, 也就无法获取到对称密 钥
- 服务器通过私钥解密, 还原出客户端发送的对称密钥. 并且使用这个对称密钥加密给客户端返回的 响应数据.
- 后续客户端和服务器的通信都只用对称加密即可. 由于该密钥只有客户端和服务器两个主机知道, 其他主机/设备不知道密钥即使截获数据也没有意义.
由于对称加密的效率比非对称加密高很多, 因此只是在开始阶段协商密钥的时候使用非对称加密, 后续的传输仍然使用对称加密.
那么接下来问题又来了:
- 客户端如何获取到公钥?
- 客户端如何确定这个公钥不是黑客伪造的?
引入证书
在客户端和服务器刚一建立连接的时候, 服务器给客户端返回一个 证书.
这个证书包含了刚才的公钥, 也包含了网站的身份信息.
这个证书就好比人的身份证, 作为这个网站的身份标识. 搭建一个 HTTPS 网站要在CA机构先申请 一个证书.(类似于去公安局办个身份证).
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-UAIetXjg-1654501679474)(media/6bbeee2a70f1e8112f34c587899b45ee.jpeg)]](https://img-blog.csdnimg.cn/9f5f8b74c68b422eb2615f2e466c9758.jpeg)
这个 证书 可以理解成是一个结构化的字符串, 里面包含了以下信息:
- 证书发布机构
- 证书有效期
- 公钥
- 证书所有者
- 签名
…
当客户端获取到这个证书之后, 会对证书进行校验(防止证书是伪造的).
- 判定证书的有效期是否过期
- 判定证书的发布机构是否受信任(操作系统中已内置的受信任的证书发布机构).
- 验证证书是否被篡改: 从系统中拿到该证书发布机构的公钥, 对签名解密, 得到一个 hash 值(称为数据摘要), 设为hash1. 然后计算整个证书的 hash 值, 设为 hash2. 对比 hash1 和 hash2 是否相等. 如果相等,则说明证书是没有被篡改过的.
查看浏览器的受信任证书发布机构
Chrome 浏览器, 点击右上角,选择 “设置”, 搜索 “证书管理” , 即可看到以下界面.
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-DkZCO6r6-1654501679475)(media/732c427c091f33d0a318cf6219b0bbf9.png)]](https://img-blog.csdnimg.cn/382986fea6eb44ec958d3f832e973a9c.png)
理解数据摘要 / 签名
以后我们参加工作后, 经常会涉及到 “报销” 的场景. 你拿着发票想报销, 需要领导批准. 但是领导又 不能和你一起去找财务. 那咋办?
很简单, 领导给你签个字就行了. 财务见到领导的签字, “见字如见人”.
因为不同的人, “签名” 的差别会很大. 使用签名就可以一定程度的区分某个特定的人.
类似的, 针对一段数据(比如一个字符串), 也可以通过一些特定的算法, 对这个字符串生成一个 “签 名”. 并保证不同的数据, 生成的 “签名” 差别很大. 这样使用这样的签名就可以一定程度的区分不同的数据. 常见的生成签名的算法有: MD5 和 SHA 系列
以 MD5 为例, 我们不需要研究具体的计算签名的过程, 只需要了解 MD5 的特点:
- 定长: 无论多长的字符串, 计算出来的 MD5 值都是固定长度 (16字节版本或者32字节版本)
- 分散: 源字符串只要改变一点点, 最终得到的 MD5 值都会差别很大.
- 不可逆: 通过源字符串生成 MD5 很容易, 但是通过 MD5 还原成原串理论上是不可能的.
正因为 MD5 有这样的特性, 我们可以认为如果两个字符串的 MD5 值相同, 则认为这两个字符串相 同.
理解判定证书篡改的过程: (这个过程就好比判定这个身份证是不是伪造的身份证)
假设我们的证书只是一个简单的字符串 hello, 对这个字符串计算hash值(比如md5), 结果为BC4B2A76B9719D91
如果 hello 中有任意的字符被篡改了, 比如变成了 hella, 那么计算的 md5 值就会变化很大.BDBD6F9CF51F2FD8
然后我们可以把这个字符串 hello 和 哈希值 BC4B2A76B9719D91 从服务器返回给客户端, 此时 客户端如何验证 hello 是否是被篡改过?
那么就只要计算 hello 的哈希值, 看看是不是 BC4B2A76B9719D91 即可.
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-DscIWLgH-1654501679475)(media/9972751d0ebc24d995c81bd71fdc1b43.jpeg)]](https://img-blog.csdnimg.cn/c80217776bc746c384df7fb9b426fffb.jpeg)
但是还有个问题, 如果黑客把 hello 篡改了, 同时也把哈希值重新计算下, 客户端就分辨不出来了呀.
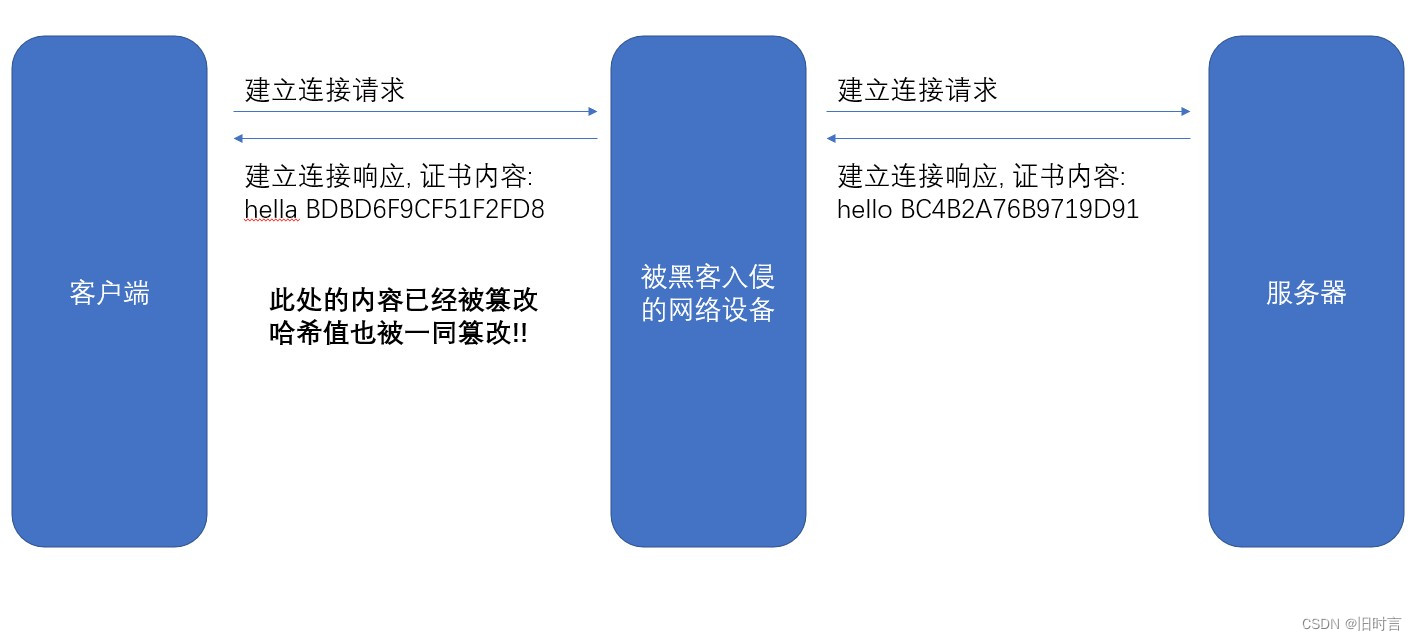
所以被传输的哈希值不能传输明文, 需要传输密文.
这个哈希值在服务器端通过另外一个私钥加密(这个私钥是申请证书的时候, 证书发布机构给服务 器的, 不是客户端和服务器传输对称密钥的私钥).
然后客户端通过操作系统里已经存的了的证书发布机构的公钥进行解密, 还原出原始的哈希值, 再 进行校验.
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-5BLyPYwE-1654501679476)(media/73fa521de812e9fe461a184e2f5b23c8.jpeg)]](https://img-blog.csdnimg.cn/51aaa80899684943bd016b4c3ae7161a.jpeg)
完整流程
左侧都是客户端做的事情, 右侧都是服务器做的事情.
![## [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-DPQIS7Bx-1654501679477)(media/58b9e54f618a20710f5496567e66b55d.png)]](https://img-blog.csdnimg.cn/69d0df754cd044588ac772404a6f61cb.png)
总结
HTTPS 工作过程中涉及到的密钥有三组.
第一组(非对称加密): 用于校验证书是否被篡改. 服务器持有私钥(私钥在注册证书时获得), 客户端持有公
钥(操作系统包含了可信任的 CA 认证机构有哪些, 同时持有对应的公钥). 服务器使用这个私钥对证书的 签名进行加密. 客户端通过这个公钥解密获取到证书的签名, 从而校验证书内容是否是篡改过.
第二组(非对称加密): 用于协商生成对称加密的密钥. 服务器生成这组 私钥-公钥 对, 然后通过证书把公钥 传递给客户端. 然后客户端用这个公钥给生成的对称加密的密钥加密, 传输给服务器, 服务器通过私钥解 密获取到对称加密密钥.
第三组(对称加密): 客户端和服务器后续传输的数据都通过这个对称密钥加密解密.
其实一切的关键都是围绕这个对称加密的密钥. 其他的机制都是辅助这个密钥工作的.
第二组非对称加密的密钥是为了让客户端把这个对称密钥传给服务器. 第一组非对称加密的密钥是为了让客户端拿到第二组非对称加密的公钥.
Tomcat
Tomcat 是什么
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-6QKH9shr-1654501679477)(media/ff46b9331d088bb4920f6f6691c97f1d.png)]](https://img-blog.csdnimg.cn/66c82b864d86492d926a1e5a52c88491.png)
Tomcat 是一个 HTTP 服务器.
前面我们已经学习了 HTTP 协议, 知道了 HTTP 协议就是 HTTP 客户端和 HTTP 服务器之间的交互数据 的格式.
同时也通过 ajax 和 Java Socket 分别构造了 HTTP 客户端.
HTTP 服务器我们也同样可以通过 Java Socket 来实现. 而 Tomcat 就是基于 Java 实现的一个开源免费, 也是被广泛使用的 HTTP 服务器.
下载安装
在 Tomcat 官网下载即可. Tomcat 版本很多, 我们课堂上使用 Tomcat 8.
https://tomcat.apache.org/download-80.cgi
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-t7sUGkwK-1654501679478)(media/c98c5f2dbb46df0bda7c1d0f2a04ff7c.jpeg)]](https://img-blog.csdnimg.cn/734a1967d9a54a69aa00f606408318e0.jpeg)
选择其中的 zip 压缩包, 下载后解压缩即可.
解压缩的目录最好不要带 “中文” 或者 特殊符号.
目录结构
针对 tomcat 目录解压缩之后, 可以看到如下结构
apache-tomcat-8.5.47\
bin\ 存放各种启动、停止脚本的。*.sh 是以后在 linux 上用的,*.bat 是在 windows
上用的
startup.bat 启动服务,双击即可使用
conf\ 相关的配置文件,目前我们不用关心
lib\ 运行 tomcat 需要的类库,我们不关心
logs\ 运行时的日志文件,我们有时需要查看日志,来发现定位一些问题
temp\ 临时文件夹,不关心
webapps\ 存放我们要运行的 web application 的文件夹,对于我们最常用的一个文件夹
work\ Tomcat 内部进行预编译的文件夹,我们不关心
下面都是一些文档,有兴趣的同学可以自行阅读
BUIDING.txt
CONTRIBUTING.md
LICENSE
NOTICE
README.md
RELEASE-NOTES
RUNNING.txt
其中我们最关注的目录就是 webapps 目录. web applications 的简称, 意思是用来存放 web 应用的文 件夹.
理解 “web 应用”
一个具有独立完整功能的 “网站”, 我们就可以称为一个 “web 应用”.
例如 搜狗搜索 实现了独立完整的 “搜索引擎功能”, 淘宝网 实现了独立完整的 “电商功能” .
一个 Tomcat 服务器上是可以同时部署多个这样的 web 应用的. 这些 web 应用以目录的形式被放 到 webapps 目录中.
进入 webapps 目录
webapps\
docs\
examples\
host-manager\
manager\
ROOT\
每个文件夹都对应着一个 web 应用, 可以在浏览器中分别访问每个 web 应用.
启动服务器
在 bin 目录中, 双击 startup.bat 即可启动 Tomcat 服务器 看到形如以下内容的日志, 说明启动成功.
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-OEluoYAf-1654501679478)(media/7550f072fded2b85924198189cf5ef70.jpeg)]](https://img-blog.csdnimg.cn/5141936622fb48a581b06dfa8bb62333.jpeg)
注意: 在 Windows 上通过 cmd 方式启动 Tomcat 会出现乱码. 但是不影响 Tomcat 的使用.
乱码的原因是 Tomcat 默认按照 UTF-8 的编码方式处理中文. 而 windows 的 cmd 默认是 GBK 编 码.
如果使用 Linux 或者 IDEA 中的终端来启动 Tomcat, 则没有乱码问题. 因此此处的乱码我们暂时不 处理.
在浏览器中输入 127.0.0.1:8080 即可看到 Tomcat 的默认欢迎页面.
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-H5vbUMq2-1654501679478)(media/b2fc82224f4877ce31e9387ff7f249d4.jpeg)]](https://img-blog.csdnimg.cn/d8fc5bda40e440198da63c7c52c5e514.jpeg)
如果看不到欢迎页面, 检查 URL 的 IP 地址以及端口号是否正确, 同时也要检查 Tomcat 是否启动成功.
如果启动失败怎么办?
最常见的启动失败原因是端口号被占用.
Tomcat 启动的时候默认会绑定 8080 和 8005 端口.
如果有其他进程已经绑定了这两个端口中的任意一个, 都会导致 Tomcat 不能启动.
在命令行中使用 netstat -ano \| findstr 8080 确定看 8080 是否被其他进程绑定, 把对方进程干掉, 再重新启动 Tomcat 一般就可以解决问题.
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-A9CIVSb0-1654501679479)(media/785b77a1584f36d2ce1ba98350fe4e0f.png)]](https://img-blog.csdnimg.cn/3f1bc64926a14339b4ea105b4b87fe29.png)
形如这样的结果说明 8080 端口已经被占用. 占用的进程是 13348 这个进程. 然后就可以在任务管理器中找到这个进程, 并干掉这个进程.
部署静态页面
理解 “静态”
静态页面也就是内容始终固定的页面. 即使 用户不同/时间不同/输入的参数不同 , 页面内容也不会发生 变化. (除非网站的开发人员修改源代码, 否则页面内容始终不变).
对应的, 动态页面指的就是 用户不同/时间不同/输入的参数不同, 页面内容会发生变化. 举个栗子:
Tomcat 的主页 https://tomcat.apache.org/ 就是一个静态页面.
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-b0Vrn1wK-1654501679479)(media/2a807bade58db443573640b31a2c20c9.jpeg)]](https://img-blog.csdnimg.cn/361801b4c1d44516baea2392f28a112e.jpeg)
而 B 站的主页 https://www.bilibili.com/ 则是一个动态页面.
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-NHUSftXm-1654501679479)(media/dc44f1a00091d11b40f2c86634da1da4.jpeg)]](https://img-blog.csdnimg.cn/5709e7c4f6904fd78934f462200723f8.jpeg)
前面咱们写的 HTML, 都是写成固定的内容, 就可以理解成是 “静态页面”.
1. 部署单个 HTML
我们可以把自己写好的 HTML 部署到 Tomcat 中.
1)创建 hello.html
<!doctype html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport"
content="width=device-width, user-scalable=no, initial-scale=1.0,
maximum-scale=1.0, minimum-scale=1.0">
<meta http-equiv="X-UA-Compatible" content="ie=edge">
<title>hello</title>
</head>
<body>
<div>hello</div>
</body>
</html>
2)把 hello.html 拷贝到 Tomcat 的 webapps/ROOT 目录中.
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-0G2nfHtM-1654501679480)(media/05eb0da603e06a30c361c6876bd7b3be.png)]](https://img-blog.csdnimg.cn/e556711f01fb47a0849ff56eecf0349f.png)
- 在浏览器中通过 URL
http://127.0.0.1:8080/hello.html来访问
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-eBj7XgFM-1654501679480)(media/183aee2619772886c8e85180fa44e9dc.png)]](https://img-blog.csdnimg.cn/4ee1d94e7194486dba2c3a85645362fd.png)
注意: 127.0.0.1 为环回 IP, 表示当前主机. 此时同学们无法通过这个 IP 访问到老师电脑上的页面.
2. 部署带有 CSS / JavaScript / 图片 的 HTML
实际开发时我们的 HTML 不仅仅是单一文件, 还需要依赖一些其他的资源: CSS, JavaScript, 图片等. 这些资源也要一起部署过去.
1)创建 hello2.html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>静态页面</title>
<link rel="stylesheet" href="style.css">
</head>
<body>
<img src="doge.jpg" alt="">
<script src="app.js"></script>
</body>
</html>
2)创建 style.css
img {
width: 500px;
height: 500px;
}
3)创建 app.js
console.log("hello");
4)准备一个 doge.jpg
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-pSCv9pEP-1654501679480)(media/7addcb20d54dc3e828c60d745b5849e6.jpeg)]](https://img-blog.csdnimg.cn/7121d7c58a0844e8949c8739d3c85282.jpeg)
- 把以上四个文件都拷贝到 Tomcat 的
webapps/ROOT中.
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-c6awXImW-1654501679481)(media/7c191912eceacbf4276f56ba579428aa.jpeg)]](https://img-blog.csdnimg.cn/89244df3bed5418fa45d3a7b5e01bbfa.jpeg)
- 在浏览器中通过
http://127.0.0.1:8080/hello2.html来访问页面
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-un2n9AbZ-1654501679481)(media/a3a2366f385303c1f27c00ac7ed2c486.jpeg)]](https://img-blog.csdnimg.cn/17921b1e670f4ee2a9575164e7877acf.jpeg)
通过 Fiddler 抓包, 可以发现此时浏览器和服务器之间有 4 个 HTTP 请求/响应的交互.
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-oA6zDICl-1654501679481)(media/54b28f04f41397220fe0bba142d7b4bc.png)]](https://img-blog.csdnimg.cn/2e14909bcffd4e658cd88effac547afa.png)
- 在浏览器地址栏里输入
http://127.0.0.1:8080/hello2.html会触发一次 GET 请求. 这个请求 会拿到hello2.html 的内容. - 浏览器解析 hello2.html, 其中的 link 标签, img 标签, script 标签都会分别触发一次 GET 请求. 请求的路径 分别为
/style.css,/doge.jpg,/app.js
3. 部署 HTML 到单独的目录中
实际开发中我们的 HTML 可能不止一个, 依赖的 CSS / JavaScript 文件也可能比较多. 这个时候就不适合 全都拷贝到 webapps/ROOT 目录中了(这就会显的比较乱).
我们可以创建一个单独的目录, 和 ROOT 并列, 来存放我们要部署的内容.
1)在 webapps 中创建目录 HelloApp, 和 ROOT 目录并列.
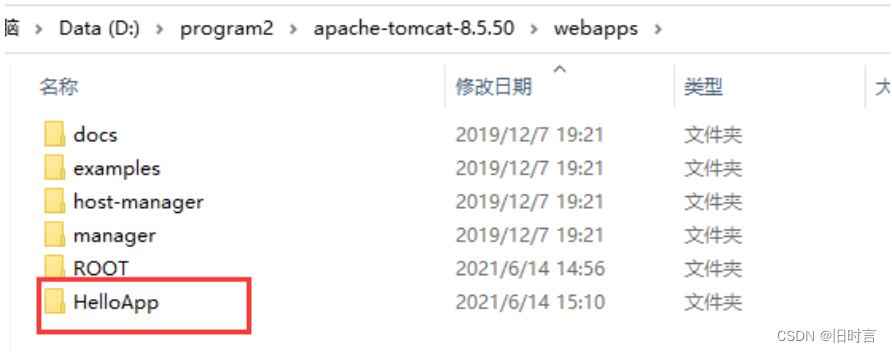
2)把刚才创建的 hello2.html, style.css, doge.jpg, app.js 拷贝到 HelloApp 目录中.
为了结构更清楚, 我们在 HelloApp 中又创建了一些子目录, css , img , js 来分别放 css , 图片,JavaScript 文件.
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-fIoiwlAL-1654501679483)(media/ad48c656323c8e7fc8400538be7bfba1.jpeg)]](https://img-blog.csdnimg.cn/3abcfcc9ff0d493794c0d2b12b5690b0.jpeg)
3)调整 hello2.html 的代码, 把引用 css, js, 图片的路径进行微调
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>静态页面</title>
<link rel="stylesheet" href="css/style.css">
</head>
<body>
<img src="img/doge.jpg" alt="">
<script src="js/app.js"></script>
</body>
</html>
形如
img/doge.jpg这样的路径为相对路径.相对路径需要向确定当前路径, 然后再找到目标路径.
其中 “当前路径” 是根据当前的 HTML 文件确定的. hello2.html 这个文件和 js/css/img 这些目录
处在统计目录中. 因此就直接通过img/doge.jpg这样的方式来进行访问了.
4)在浏览器中通过 http://127.0.0.1:8080/HelloApp/hello2.html
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ffTZE906-1654501679483)(media/1a7356e491e333ac6b47350db3998398.jpeg)]](https://img-blog.csdnimg.cn/2bb9926911fd40c780fac3633a880b05.jpeg)
通过抓包可以看到, 浏览器和服务器之间同样是 4 次 HTTP 请求/响应 的交互.
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-1C37B9RP-1654501679484)(media/d26b43dd7e490e57302d28061376c966.png)]](https://img-blog.csdnimg.cn/4671f050feb3402e9293553919068c16.png)
但是可以看到路径上和之前发生了变化.
由于我们把这些文件都放到了 HelloApp 目录中, 通过 GET 请求访问这些文件时的路径也要带上HelloApp
此处的 HelloApp 称为 Application Path (应用路径) 或者 Context Path (上下文路径)
理解 “相对路径” vs “绝对路径”
绝对路径以 / 开头. 没有 / 开头的路径就是相对路径.
刚才的 hello2.html 代码中
<img src="img/doge.jpg" alt="">这个是相对路径的写法.
浏览器在真正访问这个图片时会基于当前路径/HelloApp生成绝对路径:/HelloApp/img/doge.jpg
也可以在 hello2.html 中直接写成绝对路径的方式<img src="/HelloApp/img/doge.jpg">. 效果和上面是相同的.
但是一般我们还是建议写成相对路径. 这样如果修改了 Context Path, 代码仍然可以正常运行
4. 部署 博客系统 页面
之前我们学习前端的时候编写了一个博客系统的前端页面. 此处我们可以把这些页面部署到 Tomcat 服 务器上.
- 创建目录 blog
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-OdyVQPJK-1654501679484)(media/c676a3b9a5116fc50c0399db43628ad1.png)]](https://img-blog.csdnimg.cn/5a29c45653d74cb995b786bc03d1b405.png)
- 把 html / css / js / 图片等资源都拷贝过来
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-UIYic3r7-1654501679485)(media/2b1bb43ffb37c764e5a40be19ca19cb3.png)]](https://img-blog.csdnimg.cn/27598a74b2b640099aefeb60daf07612.png)
- 在浏览器通过
http://127.0.0.1:8080/blog/blog_list.html即可访问博客列表页.
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ZlQf9uXk-1654501679485)(media/a78cb8d665727e55e2f8c264c032912e.jpeg)]](https://img-blog.csdnimg.cn/5ab5e0a3260e4cb492230a630a59df84.jpeg)
5. 部署 博客系统 到云服务器
经历了前面几个回合的部署, 可能有同学会有疑问:
这些 HTML 页面, 在本地文件的方式也能打开呀, 为啥非要部署到 Tomcat 上? 原因主要有两方面:
通过本地文件的方式只能打开静态页面, Tomcat 既可以处理静态页面, 也可以处理动态页面.
本地文件的方式只能打开你自己机器上的 HTML, 无法访问别人机器的 HTML. 而通过 Tomcat,
配合云服务器, 则可以让别人也访问到你的页面.
此处我们简单演示把静态页面部署到远端的云服务器上. 这样其他人也能访问我们的页面了.
注意1: 部署在本机 Tomcat 上的页面只能在局域网内部访问. 而云服务器上的 Tomcat 可以被整个 互联网访问.
注意2: 云服务器往往使用 Linux 作为操作系统. 关于 Linux 操作的详细方法, 后面的课程再介绍.
1)先把要部署的目录打一个 zip 压缩包 (用 rar 也行. 但是 Linux 解压缩 zip 更方便)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-nPPhb3Oe-1654501679485)(media/f16867c177c0edf42e48e101c023acc4.jpeg)]](https://img-blog.csdnimg.cn/8dc2265e53b4460a8270c13621efe69c.jpeg)
2)使用 xshell 连上云服务器, 并切换到 Tomcat 的 webapps 目录
Linux 版本的 Tomcat 和 Windows 版本的 Tomcat 完全一致.
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-y6JWDH2Y-1654501679486)(media/1ab1949fbd0e399c79a7e580b26e90f7.jpeg)]](https://img-blog.csdnimg.cn/39c94132fdc74153bf6c4c0d30eee48e.jpeg)
3)把 blog.zip 拖拽到 xshell 中 (此时通过 rz 命令传输)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-zHS7FXGh-1654501679486)(media/be1462c08e223a255d6bcd20ef4030e5.jpeg)]](https://img-blog.csdnimg.cn/2a684ce03d8141c9a72af9d6d0ffb50c.jpeg)
4)解压缩 blog.zip
5)在浏览器通过 http://42.192.83.143:8080/blog/blog_list.html 访问页面
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Sw2aSOnu-1654501679486)(media/79d61fadd877413b85ee3755e74fcc50.jpeg)]](https://img-blog.csdnimg.cn/d205539ffa9d479f91a98c68a22c58c9.jpeg)
此时其他同学也可以通过
http://42.192.83.143:8080/blog/blog_list.html访问页面.