1.软件版本
matlab2013b
2.本算法理论知识
帧差法
帧差法是最为常用的运动目标检测和分割方法之一,基本原理就是在图像序列相邻两帧采用基于像素的时间差分通过闭值化来提取出图像中的运动区域。首先,将相邻帧图像对应像素值相减得到差分图像,然后对差分图像二值化,在环境亮度变化不大的情况下,如果对应像素值变化小于事先确定的阂值时,可以认为此处为背景像素如果图像区域的像素值变化很大,可以认为这是由于图像中运动物体引起的,将这些区域标记为前景像素,利用标记的像素区域可以确定运动目标在图像中的位置。由于相邻两帧间的时间间隔非常短,用前一帧图像作为当前帧的背景模型具有较好的实时性,其背景不积累,且更新速度快、算法简单、计算量小。算法的不足在于对环境噪声较为敏感,闽值的选择相当关键,选择过低不足以抑制图像中的噪声,过高则忽略了图像中有用的变化。对于比较大的、颜色一致的运动目标,有可能在目标内部产生空洞,无法完整地提取运动目标。
然后我们使用不同的门限进行判决,得到如下的仿真结果:

对于帧差法,采用不同的门限值,可以获得不同清晰度的目标,当阈值较小的时候,其目标的清晰度就越大,但是同时也会包括进去一些噪声,而到阈值较大的时候,虽然噪声可以去除掉,但是目标也变得比较不清晰。他弄过分析,阈值1和阈值2比较合适。这里我们根据阈值1进行处理。
clc;
clear;
close all;
warning off;
%读取视频
PIX = VideoReader('vedios.avi');
PIX_Size = [PIX.Width,PIX.Height];
Num_Frame = floor(PIX.Duration * PIX.FrameRate);
%阈值
Level0 = 0.02;
Level1 = 0.05;
Level2 = 0.1;
Level3 = 0.3;
for Frm = 100:Num_Frame
Frm
I0 = read(PIX,Frm-1);
I1 = read(PIX,Frm);
%做差
diff = I1-I0;
Out0 = im2bw(diff,Level0);
Out1 = im2bw(diff,Level1);
Out2 = im2bw(diff,Level2);
Out3 = im2bw(diff,Level3);
figure(1);
subplot(231);
imshow(I0);
title('原始视频');
subplot(232);
imshow(diff);
title('前后两帧做差计算');
subplot(233);
imshow(Out0);
title('阈值0');
subplot(234);
imshow(Out1);
title('阈值1');
subplot(235);
imshow(Out2);
title('阈值2');
subplot(236);
imshow(Out3);
title('阈值3');
pause(0.01);
end
背景差分法
背景减除法是一种有效的运动对象检测算法,基本思想是利用背景的参数模型来近似背景图像的像素值,将当前帧与背景图像进行差分比较实现对运动区域的检测,其中区别较大的像素区域被认为是运动区域,而区别较小的像素区域被认为是背景区域。背景减除法必须要有背景图像,并且背景图像必须是随着光照或外部环境的变化而实时更新的,因此背景减除法的关键是背景建模及其更新。针对如何建立对于不同场景的动态变化均具有自适应性的背景模型,减少动态场景变化对运动分割的影响,研究人员已提出了许多背景建模算法,但总的来讲可以概括为非回归递推和回归递推两类。非回归背景建模算法是动态的利用从某一时刻开始到当前一段时间内存储的新近观测数据作为样本来进行背景建模。非回归背景建模方法有最简单的帧间差分、中值滤波方法、Toyama等利用缓存的样本像素来估计背景模型 的线性滤波器、Elg~al等提出的利用一段时间的历史数据来计算背景像素密度的非参数模型等。回归算法在背景估计中无需维持保存背景估计帧的缓冲区,它们是通过回归的方式基于输入的每一帧图像来更新某个时刻的背景模型。这类方法包括广泛应用的线性卡尔曼滤波法、Stauffe:与Grimson提出的混合高斯模型等.高斯混合模型,具体的原理如下所示:
高斯混合模型(GMM),顾名思义,就是数据可以看作是从数个高 斯分布中生成出来的。虽然我们可以用不同的分布来随意地构造 XX Mixture Model ,但是 GMM是 最为流行。另外,Mixture Model 本身其实也是可以变得任意复杂的,通过增加 Model 的个数,我们可以任意地逼近任何连续的概率密分布。
每个 GMM 由 K 个 Gaussian 分布组成,每个 Gaussian 称为一个“Component”,这些 Component 线性加成在一起就组成了 GMM 的概率密度函数:
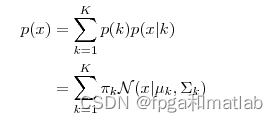
其中,πk表示选中这个component部分的概率,我们也称其为加权系数。
根据上面的式子,如果我们要从 GMM 的分布中随机地取一个点的话,实际上可以分为两步:
(1)首先随机地在这 K 个 Component 之中选一个,每个 Component 被选中的概率实际上就是它的系数 πk,选中了 Component 之后,再单独地考虑从这个 Component 的分布中选取一个点就可以了──这里已经回到了普通的 Gaussian 分布,转化为了已知的问题。假设现在有 N 个数据点,我们认为这些数据点由某个GMM模型产生,现在我们要需要确定 πk,μk,σk 这些参数。最大似然估计来确定这些参数,GMM的似然函数如下:
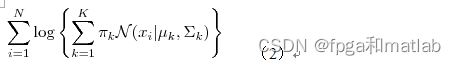
在最大似然估计里面,由于我们的目的是把乘积的形式分解为求和的形式,即在等式的左右两边加上一个log函数。
因为高斯混合模型的仿真速度较慢,这里我直接给出最佳参数:
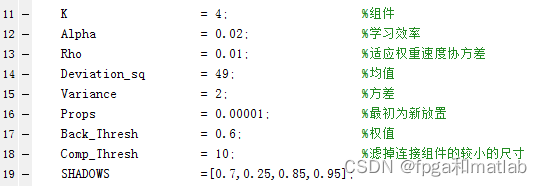
你写论文的时候,可以根据上面的注释,自己修改部分参数进行对比。
仿真结果如下所示:

从上面的结果可知,帧差法可以获得较为清晰目标检测效果。
clc;
clear;
close all;
warning off;
addpath 'func\'
%%
%参数初始化
RR = 240;%处理视频大小
CC = 320;
K = 4; %组件
Alpha = 0.02; %学习效率
Rho = 0.01; %适应权重速度协方差
Deviation_sq = 49; %均值
Variance = 2; %方差
Props = 0.00001; %最初为新放置
Back_Thresh = 0.6; %权值
Comp_Thresh = 10; %滤掉连接组件的较小的尺寸
SHADOWS =[0.7,0.25,0.85,0.95];
%%
%我们这里设计了一个算法,就是能够读取压缩后的AVI视频,从而使仿真速度更快
disp('正在读取视频...');
FileName_AVI = 'vedios.avi';
[pixel_gray,pixel_original,frameNum_Original] = func_vedio_process(FileName_AVI);
for i = 1:frameNum_Original
i
pixel_gray2(:,:,i) = imresize(pixel_gray(:,:,i),[RR,CC]);
pixel_original2(:,:,:,i) = imresize(pixel_original(:,:,:,i),[RR,CC]);
end
clear pixel_gray pixel_original;
disp('读取视频完毕...');
disp('正在进行高斯混合模型的仿真...');
[image_sequence,background_Update,Images0,Images2] = func_Mix_Gauss_Model(pixel_original2,frameNum_Original,RR,CC,K,Alpha,Rho,Deviation_sq,Variance,Props,Back_Thresh,Comp_Thresh,SHADOWS);
disp('高斯混合模型的仿真完毕...');
disp('正在显示效果...');
figure;
for tt = 1:frameNum_Original
tt
subplot(131)
imshow(image_sequence(:,:,:,tt));
title('原始图像');
subplot(132)
imshow(uint8(background_Update(:,:,:,tt)));
title('背景图像更新');
subplot(133)
imshow(Images0(:,:,tt));
title('运动目标检测');
pause(0.001);
end
disp('显示效果完毕...');
光流法
光流法的主要任务就是计算光流场,即在适当的平滑性约束条件下,根据图像序列的时空梯度估算运动场,通过分析运动场的变化对运动目标和场景进行检测与分割。通常有基于全局光流场和特征点光流场两种方法。最经典的全局光流场计算方法是L-K(Lueas&Kanada)法和H-S(Hom&Schunck)法,得到全局光流场后通过比较运动目标与背景之间的运动差异对运动目标进行光流分割,缺点是计算量大。特征点光流法通过特征匹配求特征点处的流速,具有计算量小、快速灵活的特点,但稀疏的光流场很难精确地提取运动目标的形状。总的来说,光流法不需要预先知道场景的任何信息,就能够检测到运动对象,可处理背景运动的情况,但噪声、多光源、阴影和遮挡等因素会对光流场分布的计算结果造成严重影响;而且光流法计算复杂,很难实现实时处理。
光流法的仿真比高斯还慢,这里,我们就对其中一部分帧进行仿真, 仿真结果如下所示:
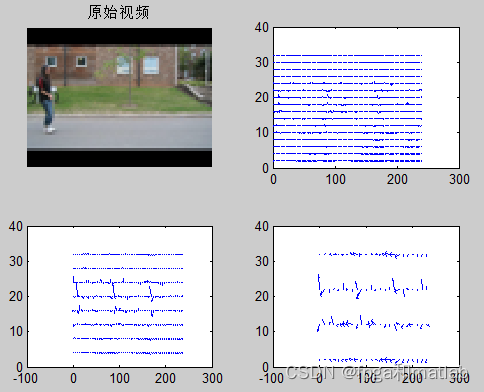
clc;
clear;
close all;
warning off;
addpath 'func\'
%读取视频
PIX = VideoReader('vedios.avi');
PIX_Size = [PIX.Width,PIX.Height];
Num_Frame = floor(PIX.Duration * PIX.FrameRate);
%阈值
Level0 = 2;
Level1 = 4;
Level2 = 10;
for Frm = [130]
Frm
I0 = imresize(read(PIX,Frm-2),1/8);
I1 = imresize(read(PIX,Frm),1/8);
[R,C,kk] = size(I0);
[Dx0,Dy0] = Lucas_Kanade(I0,I1,Level0);
[Dx1,Dy1] = Lucas_Kanade(I0,I1,Level1);
[Dx2,Dy2] = Lucas_Kanade(I0,I1,Level2);
figure(1);
subplot(221);
imshow(I0);
title('原始视频');
subplot(222);
[maxI,maxJ]=size(Dx0);
Dx0=Dx0(1:Level0:maxI,1:Level0:maxJ);
Dy0=Dy0(1:Level0:maxI,1:Level0:maxJ);
quiver(1:Level0:maxJ,(maxI):(-Level0):1,Dx0,-Dy0,1);
% axis([0,C,0,R]);
subplot(223);
[maxI,maxJ]=size(Dx1);
Dx1=Dx1(1:Level1:maxI,1:Level1:maxJ);
Dy1=Dy1(1:Level1:maxI,1:Level1:maxJ);
quiver(1:Level1:maxJ,(maxI):(-Level1):1,Dx1,-Dy1,1);
% axis([0,C,0,R]);
subplot(224);
[maxI,maxJ]=size(Dx2);
Dx2=Dx2(1:Level2:maxI,1:Level2:maxJ);
Dy2=Dy2(1:Level2:maxI,1:Level2:maxJ);
quiver(1:Level2:maxJ,(maxI):(-Level2):1,Dx2,-Dy2,1);
% axis([0,C,0,R]);
pause(0.01);
end
Meanshift
Meanshift的基本原理如下所示:
http://wenku.baidu.com/view/4f37261cfad6195f312ba6c7.html
具体仿真如下所示:

clc;
clear;
close all;
warning off;
addpath 'func\'
%读取视频
PIX = VideoReader('vedios.avi');
PIX_Size = [PIX.Width,PIX.Height];
Num_Frame = floor(PIX.Duration * PIX.FrameRate);
Start_frame = 120;
I0 = read(PIX,Start_frame);
[jishu,rect,a,b,m_wei,C,hist1,y,trace_x,trace_y] = select(I0);
for Frm = Start_frame:Num_Frame
Frm
Im = read(PIX,Frm);
jishu = jishu+1;
num = 0;
Y = [2,2];
%mean shift迭代
while((Y(1)^2+Y(2)^2>0.5)&num<20)
num = num+1;
temp1 = imcrop(Im,rect);
%计算侯选区域直方图
hist2 = zeros(1,4096);
for i = 1:a
for j = 1:b
q_r = fix(double(temp1(i,j,1))/16);
q_g = fix(double(temp1(i,j,2))/16);
q_b = fix(double(temp1(i,j,3))/16);
q_temp1(i,j) = q_r*256+q_g*16+q_b;
hist2(q_temp1(i,j)+1) = hist2(q_temp1(i,j)+1)+m_wei(i,j);
end
end
hist2 = hist2*C;
w = weights(hist1,hist2);
%变量初始化
sum_w = 0;
xw = [0,0];
for i=1:a
for j=1:b
sum_w = sum_w+w(uint32(q_temp1(i,j))+1);
xw = xw+w(uint32(q_temp1(i,j))+1)*[i-y(1)-0.5,j-y(2)-0.5];
end
end
Y = xw/sum_w;
%中心点位置更新
rect(1)=rect(1)+Y(2);
rect(2)=rect(2)+Y(1);
end
v1=rect(1);
v2=rect(2);
v3=rect(3);
v4=rect(4);
trace_x = [trace_x v1 + v3/2];
trace_y = [trace_y v2 + v4/2];
%显示跟踪结果
figure(2);
imshow(uint8(Im))
hold on;
plot([v1,v1+v3],[v2,v2],[v1,v1],[v2,v2+v4],[v1,v1+v3],[v2+v4,v2+v4],[v1+v3,v1+v3],[v2,v2+v4],'LineWidth',1,'Color','g')
if jishu>2
plot(trace_x(1:jishu-1),trace_y(1:jishu-1),'LineWidth',2,'Color','r');
end
end
Camshift
Meanshift的基本原理如下所示:
http://wenku.baidu.com/view/59596ac42cc58bd63186bd37.html
它是MeanShift算法的改进,称为连续自适应的MeanShift算法,CamShift算法的全称是"Continuously Apaptive Mean-SHIFT",它的基本思想是视频图像的所有帧作MeanShift运算,并将上一帧的结果(即Search Window的中心和大小)作为下一帧MeanShift算法的Search Window的初始值,如此迭代下去。
具体仿真如下所示:

clc;
clear;
close all;
warning off;
addpath 'func\'
%读取视频
PIX = VideoReader('vedios.avi');
PIX_Size = [PIX.Width,PIX.Height];
Num_Frame = floor(PIX.Duration * PIX.FrameRate);
Start_frame = 120;
I0 = read(PIX,Start_frame);
[jishu,rect,a,b,m_wei,C,hist1,y,trace_x,trace_y] = select(I0);
for Frm = Start_frame:Num_Frame
Frm
Im = read(PIX,Frm);
jishu = jishu+1;
num = 0;
Y = [2,2];
%将前一的结果作为下一次的初始值
rect = func_meanshift(Y,Im,rect,a,b,num,m_wei,C,hist1,y);
v1=rect(1);
v2=rect(2);
v3=rect(3);
v4=rect(4);
trace_x = [trace_x v1 + v3/2];
trace_y = [trace_y v2 + v4/2];
%显示跟踪结果
figure(2);
imshow(uint8(Im))
hold on;
plot([v1,v1+v3],[v2,v2],[v1,v1],[v2,v2+v4],[v1,v1+v3],[v2+v4,v2+v4],[v1+v3,v1+v3],[v2,v2+v4],'LineWidth',1,'Color','g')
if jishu>2
plot(trace_x(1:jishu-1),trace_y(1:jishu-1),'LineWidth',2,'Color','r');
end
end
A10-27