文章目录
Controller Manager 简介
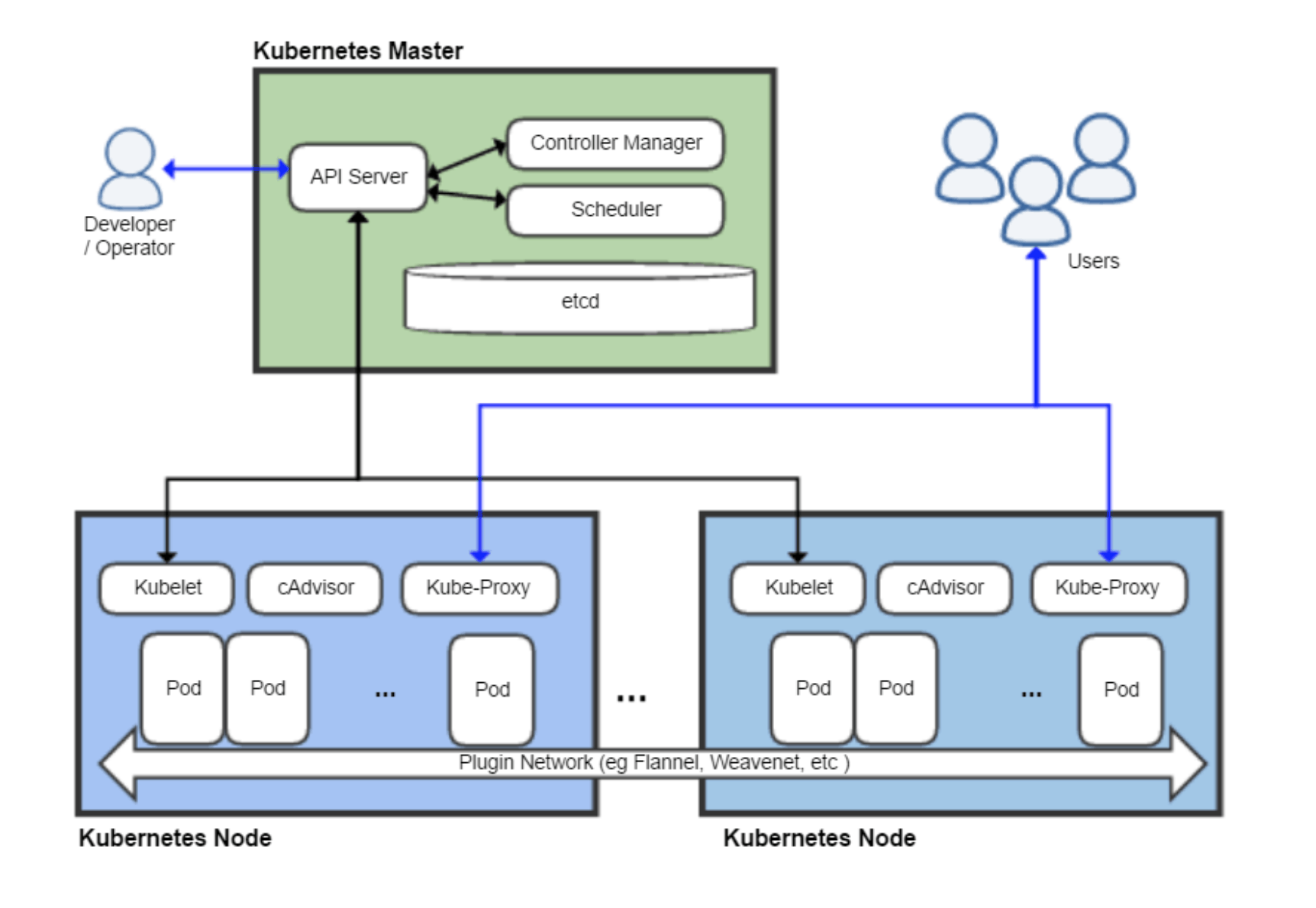
Controller Manager作为集群内部的管理控制中心,负责集群内的Node、Pod副本、服务端点(Endpoint)、命名空间(Namespace)、服务账号(ServiceAccount)、资源定额(ResourceQuota)的管理,当某个Node意外宕机时,Controller Manager会及时发现并执行自动化修复流程,确保集群始终处于预期的工作状态。
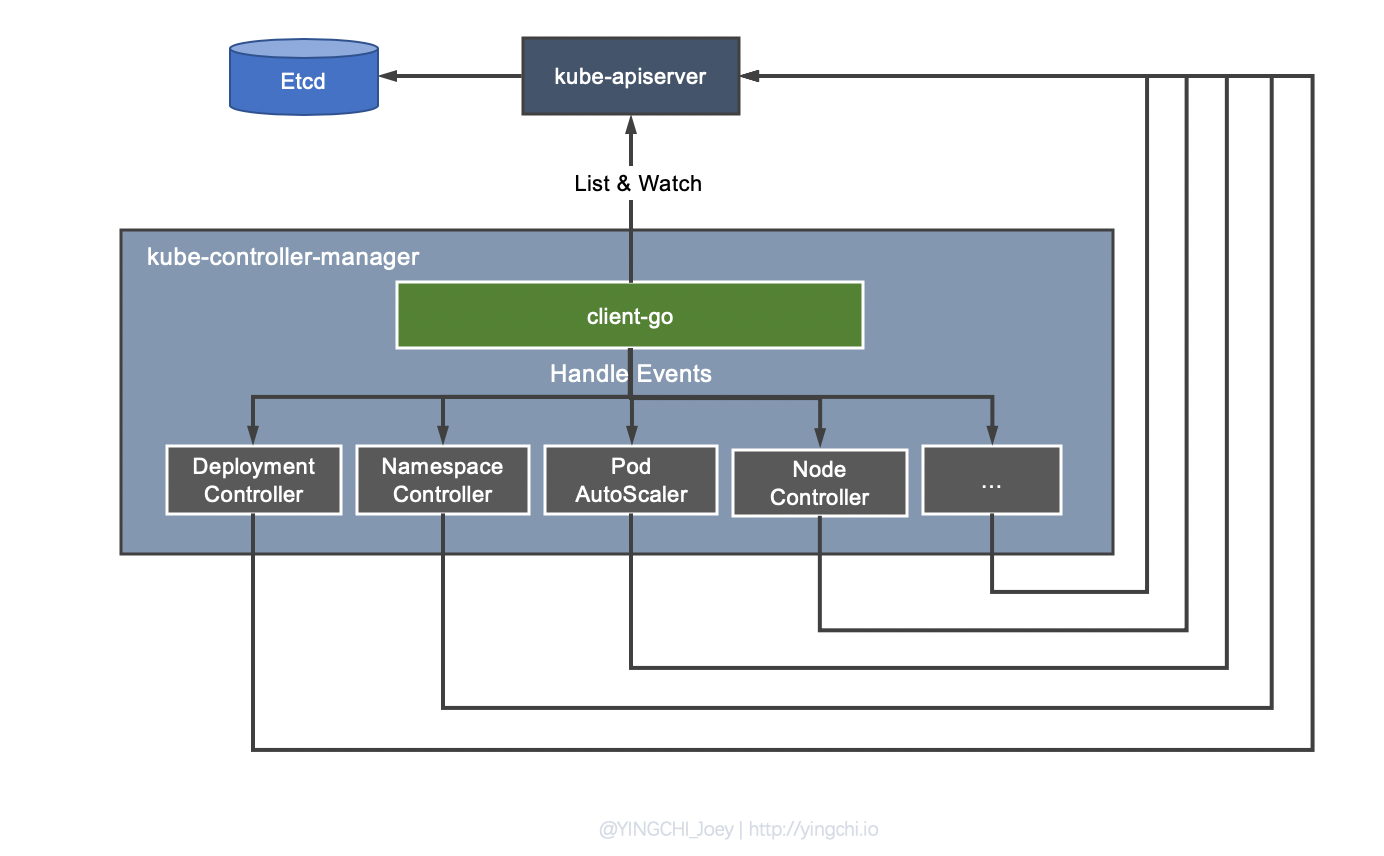
如图,Controller Manager 发现资源的实际状态和期望状态有偏差之后,会触发相应 Controller 注册的 Event Handler,让它们去根据资源本身的特点进行调整。
比如当通过 Deployment 创建的某个 Pod 发生异常退出时,Deployment Controller 便会接受并处理该退出的 Event,并创建新的 Pod 来维持期望副本数。这样设计的原因也很好理解,可以将 Controller Manager 与具体的状态管理工作相解耦,因为不同的资源对于状态的管理多种多样,Deployment Controller 关注 Pod 副本数,而 Service 则关注 Service 的 IP、Port 等等。
Controller Manager 架构设计
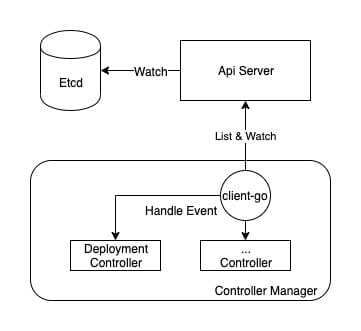
从比较高维度的视角看,Controller Manager 主要提供了一个分发事件的能力,而不同的 Controller 只需要注册对应的 Handler 来等待接收和处理事件。
辅助 Controller Manager 完成事件分发的是 client-go,而其中比较关键的模块便是 informer。
kubernetes 在 github 上提供了一张 client-go 的架构图,从中可以看出,Controller 正是下半部分(CustomController)描述的内容,而 Controller Manager 主要完成的是上半部分。
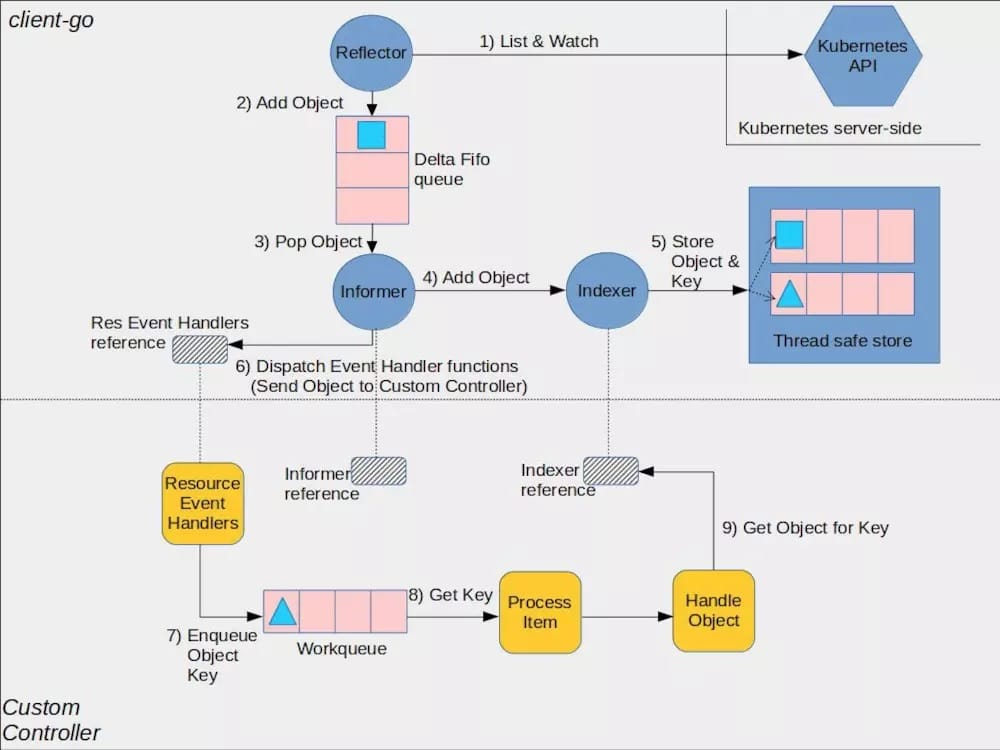
偏源码的讲解就先不看了,还没到那么深。
Reflactor
反射器,具有以下几个功能:
- 采用 List、Watch 机制与 kube-apiserver 交互,List 短连接获取全量数据,Watch 长连接获取增量数据;
- 可以 Watch 任何资源包括 CRD;
- Watch 到的增量 Object 添加到 Delta FIFO 队列,然后 Informer 会从队列里面取数据;
Informer
Informer 是 client-go 中较为核心的一个模块,其主要作用包括如下两个方面:
- 同步数据到本地缓存。Informer 会不断读取 Delta FIFO 队列中的 Object,在触发事件回调之前先更新本地的 store,如果是新增 Object,如果事件类型是 Added(添加对象),那么 Informer 会通过 Indexer 的库把这个增量里的 API 对象保存到本地的缓存中,并为它创建索引。之后通过 Lister 对资源进行 List / Get 操作时会直接读取本地的 store 缓存,通过这种方式避免对 kube-apiserver 的大量不必要请求,缓解其访问压力;
- 根据对应的事件类型,触发事先注册好的 ResourceEventHandler。client-go 的 informer 模块启动时会创建一个 shardProcessor,各种 controller(如 Deployment Controller、自定义 Controller…)的事件 handler 注册到 informer 的时候会转换为一个 processorListener 实例,然后 processorListener 会被 append 到 shardProcessor 的 Listeners 切片中,shardProcessor 会管理这些 listeners。
processorListener 的重要作用就是当事件到来时触发对应的处理方法,因此不停地从 nextCh 中拿到事件并执行对应的 handler。sharedProcessor 的职责便是管理所有的 Handler 以及分发事件,而真正做分发工作的是 distribute 方法。
梳理一下这中间的过程:
Controller 将 Handler 注册给 Informer;
Informer 通过 sharedProcessor 维护了所有转换为 processorListener 的 Handler;
Informer 收到事件时,通过 sharedProcessor.distribute 将事件分发下去;
Controller 被触发对应的 Handler 来处理自己的逻辑。
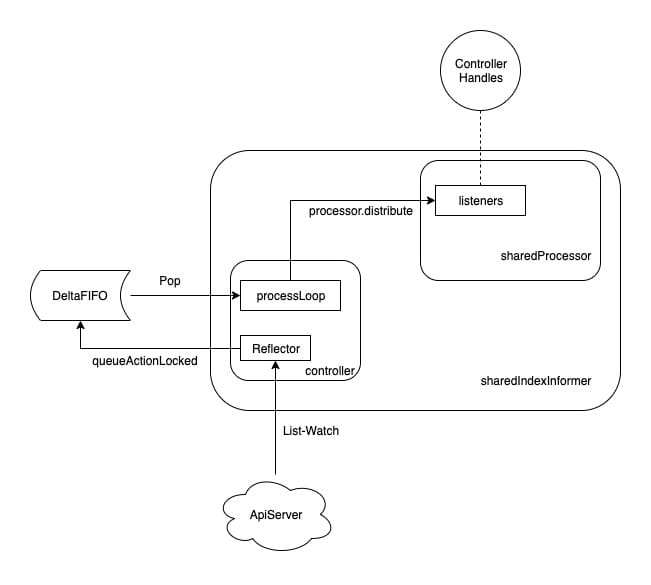
Reflactor 启动后会执行一个 processLoop 死循环,Loop 中不停地将 Delta FIFO 队列中的事件 Pop 出来,Pop 时会取出该资源的所有事件,并交给 sharedIndexInformer 的 HandleDeltas 方法(创建 controller 时赋值给了 config.Process,传递到 Pop 参数的处理函数中 Pop(PopProcessFunc(c.config.Process))),HandleDeltas 调用了 processor.distribute 完成事件的分发。
在注册的 ResourceEventHandler 回调函数中,只是做了一些很简单的过滤,然后将关心变更的 Object 放到 workqueue 里面。之后 Controller 从 workqueue 里面取出 Object,启动一个 worker 来执行自己的业务逻辑,通常是对比资源的当前运行状态与期望状态,做出相应的处理,实现运行状态向期望状态的收敛。
注意,在 worker 中就可以使用 lister 来获取 resource,这个时候不需要频繁的访问 kube-apiserver 了,对于资源的 List / Get 会直接访问 informer 本地 store 缓存,apiserver 中资源的的变更都会反映到这个缓存之中。同时,LocalStore 会周期性地把所有的 Pod 信息重新放到 DeltaFIFO 中。
Controller
Replication Controller
为了区分,资源对象Replication Controller简称RC,而本文是指Controller Manager中的Replication Controller,称为副本控制器。副本控制器的作用即保证集群中一个RC所关联的Pod副本数始终保持预设值。
- 只有当Pod的重启策略是Always的时候(RestartPolicy=Always),副本控制器才会管理该Pod的操作(创建、销毁、重启等)。
- RC中的Pod模板就像一个模具,模具制造出来的东西一旦离开模具,它们之间就再没关系了。一旦Pod被创建,无论模板如何变化,也不会影响到已经创建的Pod。
- Pod可以通过修改label来脱离RC的管控,该方法可以用于将Pod从集群中迁移,数据修复等调试。
- 删除一个RC不会影响它所创建的Pod,如果要删除Pod需要将RC的副本数属性设置为0。
- 不要越过RC创建Pod,因为RC可以实现自动化控制Pod,提高容灾能力。
Replication Controller的职责
确保集群中有且仅有N个Pod实例,N是RC中定义的Pod副本数量。
通过调整RC中的spec.replicas属性值来实现系统扩容或缩容。
通过改变RC中的Pod模板来实现系统的滚动升级。
Replication Controller使用场景
| 使用场景 | 说明 | 使用命令 |
|---|---|---|
| 重新调度 | 当发生节点故障或Pod被意外终止运行时,可以重新调度保证集群中仍然运行指定的副本数。 | |
| 弹性伸缩 | 通过手动或自动扩容代理修复副本控制器的spec.replicas属性,可以实现弹性伸缩。 | kubectl scale |
| 滚动更新 | 创建一个新的RC文件,通过kubectl 命令或API执行,则会新增一个新的副本同时删除旧的副本,当旧副本为0时,删除旧的RC。 | kubectl rolling-update |
Node Controller
kubelet在启动时会通过API Server注册自身的节点信息,并定时向API Server汇报状态信息,API Server接收到信息后将信息更新到etcd中。
Node Controller通过API Server实时获取Node的相关信息,实现管理和监控集群中的各个Node节点的相关控制功能。流程如下
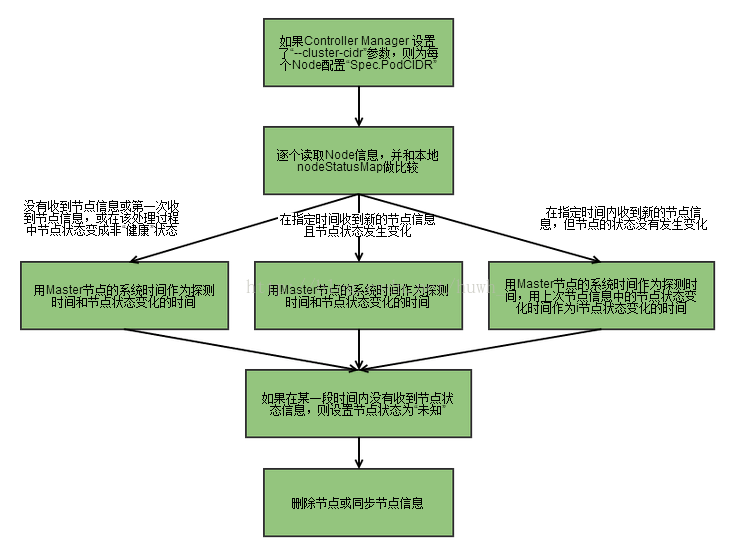
1、Controller Manager在启动时如果设置了–cluster-cidr参数,那么为每个没有设置Spec.PodCIDR的Node节点生成一个CIDR地址,并用该CIDR地址设置节点的Spec.PodCIDR属性,防止不同的节点的CIDR地址发生冲突。
2、具体流程见以上流程图。
3、逐个读取节点信息,如果节点状态变成非“就绪”状态,则将节点加入待删除队列,否则将节点从该队列删除。
ResourceQuota Controller
资源配额管理确保指定的资源对象在任何时候都不会超量占用系统物理资源。
支持三个层次的资源配置管理:
1)容器级别:对CPU和Memory进行限制
2)Pod级别:对一个Pod内所有容器的可用资源进行限制
3)Namespace级别:包括
Pod数量
Replication Controller数量
Service数量
ResourceQuota数量
Secret数量
可持有的PV(Persistent Volume)数量
说明:
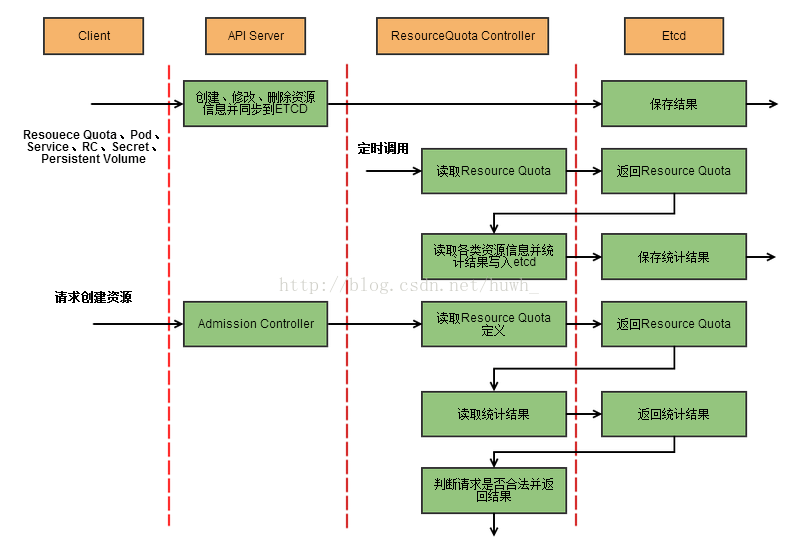
k8s配额管理是通过Admission Control(准入控制)来控制的;
Admission Control提供两种配额约束方式:LimitRanger和ResourceQuota;
LimitRanger作用于Pod和Container;
ResourceQuota作用于Namespace上,限定一个Namespace里的各类资源的使用总额。
ResourceQuota Controller流程图:
Namespace Controller
用户通过API Server可以创建新的Namespace并保存在etcd中,Namespace Controller定时通过API Server读取这些Namespace信息。
如果Namespace被API标记为优雅删除(即设置删除期限,DeletionTimestamp),则将该Namespace状态设置为“Terminating”,并保存到etcd中。同时Namespace Controller删除该Namespace下的ServiceAccount、RC、Pod等资源对象。
Endpoint Controller
Service、Endpoint、Pod的关系:

Endpoints表示了一个Service对应的所有Pod副本的访问地址,而Endpoints Controller负责生成和维护所有Endpoints对象的控制器。它负责监听Service和对应的Pod副本的变化。
如果监测到Service被删除,则删除和该Service同名的Endpoints对象;
如果监测到新的Service被创建或修改,则根据该Service信息获得相关的Pod列表,然后创建或更新Service对应的Endpoints对象。
如果监测到Pod的事件,则更新它对应的Service的Endpoints对象。
kube-proxy进程获取每个Service的Endpoints,实现Service的负载均衡功能。
Service Controller
Service Controller是属于kubernetes集群与外部的云平台之间的一个接口控制器。Service Controller监听Service变化,如果是一个LoadBalancer类型的Service,则确保外部的云平台上对该Service对应的LoadBalancer实例被相应地创建、删除及更新路由转发表。