今天我们来介绍一下几种图论中常用的求最短路的算法(来源:ACWING)
目录
1. 算法的选择
虽然接下来介绍的几个算法都是 解决最短路问题的,但是面对不同场景的差别,我们依旧要选择最合适的算法来解决,我们可以依据 单多源,是否存在负权边,是否存在负环等,对各个场景进行分类:
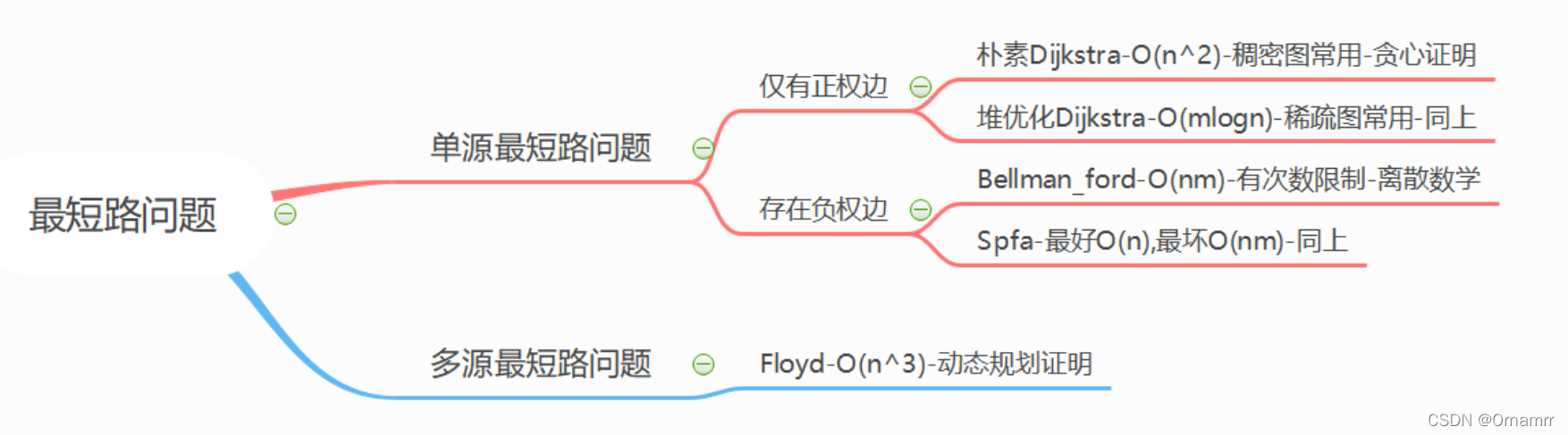
我们先对各个场景有一个大致的印象,接下来我会详细讲解各个算法以及它们之间的联系与区别。
2. 具体实现
2.1 Dijkstra算法
Dijlstra 算法 分为 朴素Dijkstra和 堆优化Djikstra两种,由于实现方式,其中朴素Dijkstra 更适合稠密图,堆优化Djikstra 更适合朴素图。
要求:单源头,无负权边。
2.2 朴素Dijkstra
模板题

思路模板

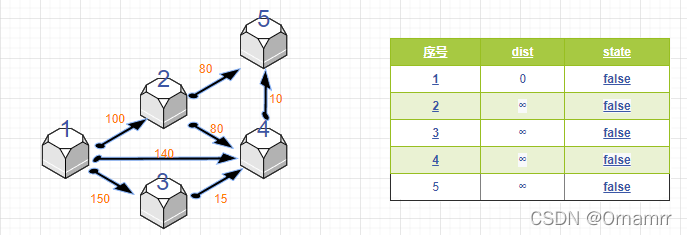
我们利用例子来讲解一下,我设置 :
- dist 距离数组保存源点到其余各个节点的距离,即 dist[i]表述 节点i到源点的距离。初始时,dist的各个元素为 +∞(除了源点设置为0)
- state 状态数组记录是否找到了源点到该节点的最短距离,如果state[i]==true,那么就表示已经找到了源点到节点i 的最短距离,反之就还没有找到。 初始时,dist的各个元素为 false.
遍历dist数组,找到一个节点,这个节点是:没有确定最短路径的节点中的距离源点最近的点。显然此时现在没有任何点确定了最短路径,我们找到节点1,同时 state[1]置true。
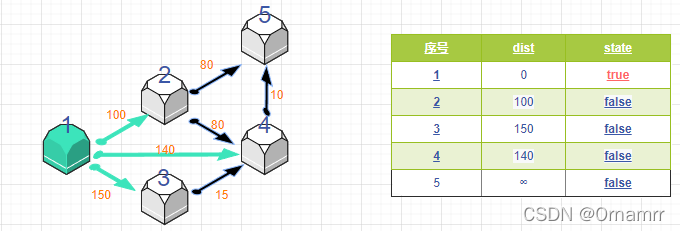
遍历i所有的可达节点j,如果dist[j] 大于 i->j 的距离,即 dist[j] > dist[i]+w[i][j](w[i][j]为i->j的距离), 则更新dist[j]=dist[i]+w[i][j]。
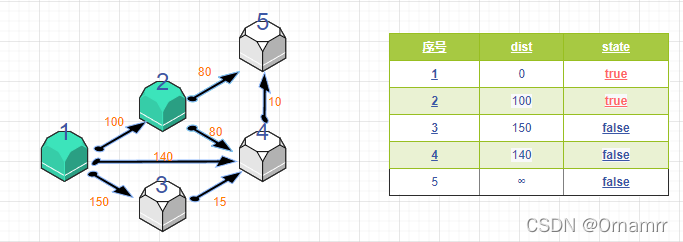
再次遍历 dist数组,找到一个节点,这个节点是:没有确定最短路径的节点中的距离源点最近的点。那么此时节点2距离源点为100,最短。设置 state[2]=1
遍历节点2所有的可达节点j,如果dist[j] 大于 i->j 的距离,即 dist[j] > dist[i]+w[i][j](w[i][j]为i->j的距离), 则更新dist[j]=dist[i]+w[i][j]。
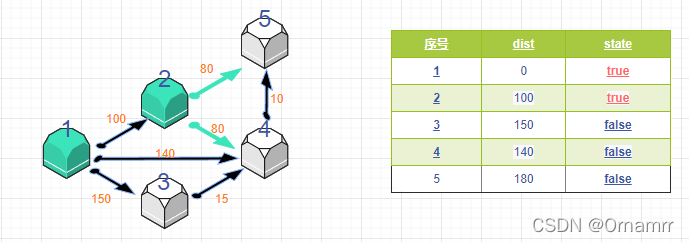
接下来就是不断重复这两步,知道所有state都为true,也就是所有的点到源点的最短距离都 确定了。
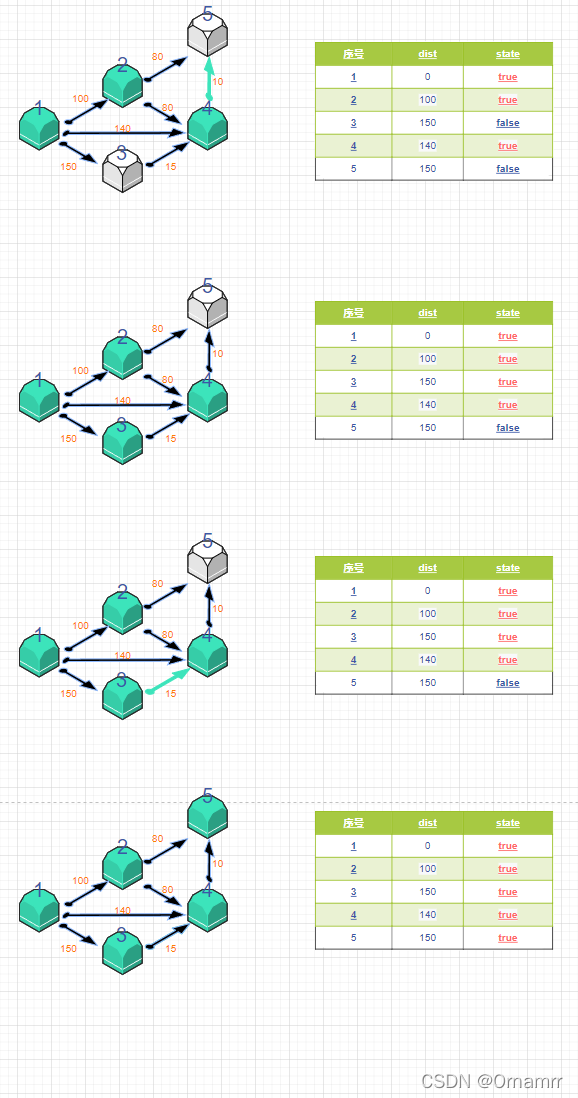
代码实现
#include<iostream>
#include<cstring>
using namespace std;
const int N = 510, M = 1e5;
int d[N][N]; // 使用邻接矩阵存储稠密图 ,领接矩阵由二维数组实现
int dist[N]; //距离数组
int st[N]; //状态数组
int n, m;
int Dijkstra()
{
//初始化dist,我们将无穷设置为0x3f即可,足够大。
memset(dist, 0x3f, sizeof dist);
dist[1] = 0;
for (int i = 1; i <= n; i++) {
//t为距离源点最近且不在集合s中的节点编号
int t = -1;//由于每一次都要找到还没有确定最短路距离的所有点中,距离当前的点最短的点。
//t = - 1是为了在st这个集合中找第一个点更新时候的方便所设定的
for (int j = 1; j <= n; j++) {
if (!st[j] && (t == -1 || dist[t] > dist[j])) {
t = j;
}
}
st[t] = true;//找到节点t之后将state[t]置true
//将节点t能够到达的节点j的dist[j]更新(如果变小,就更新)
for (int j = 1; j <= n; j++) {
if (dist[j] > dist[t] + d[t][j]) {
dist[j] = dist[t] + d[t][j];
}
}
}
//如果终点距离为无穷,那么就说明无法到达终点
if (dist[n] == 0x3f3f3f3f)return -1;
else return dist[n];
}
int main()
{
memset(d,0x3f,sizeof d);
cin >> n >> m;
//对于领接矩阵,我们要注意要去重边。
while (m--) {
int x, y, z;
cin >> x >> y >> z;
d[x][y] = min(d[x][y], z);
}
cout<<Dijkstra();
}
常见的疑问
这里我总结了一些我自己学习过程中的疑问以及一些普遍的问题,同学们可以问问自己,能否答上来。
- 关于这样选择节点可以求得最短路,是基于贪心的证明,有兴趣的同学可以自己研究。
- 0x3f为什么赋值的时候可以memset(dist,0x3f,sizeof dist)但是到后面验证的时候必须是if(dist[n]==0x3f3f3f3f)而不能是if(dist[n]==0x3f)
答: memset是按字节来初始化的,int包含4个字节,所以初始化之后的值就是0x3f3f3f3f
- 为什么要用memset(dist,0x3f,sizeof dist)来初始化
答:0x3f3f3f3f的十进制是1061109567,是1e9级别的(和0x7fffffff一个数量级,0x7fffffff代表了32-bit int的最大值),而一般场合下的数据都是小于1e9的,所以它可以作为无穷大使用而不致出现数据大于无穷大的情形。 另一方面,由于一般的数据都不会大于10^9,所以当我们把无穷大加上一个数据时,它并不会溢出(这就满足了“无穷大加一个有穷的数依然是无穷大”),事实上0x3f3f3f3f+0x3f3f3f3f=2122219134,这非常大但却没有超过32-bit int的表示范围,所以0x3f3f3f3f还满足了我们“无穷大加无穷大还是无穷大”的需求
- 我们使用二维数组存储邻接矩阵,面对最短路问题,一定要注意去重边,只保留两节点之间距离最短的一条即可
- 如果是问编号a到b的最短距离该怎么改呢? (好问题)
答:初始化时将 dist[a]=0,以及返回时return dist[b]。
- 自环和重边对 Dijkstrea算法有影响吗?
答:自环在朴素版dijkstra算法中是没有任何影响的,所以自环的权值是多少都可以,只要不是负数就行。而重边时,我们去取重边中的最小值 即代码h[x][y]=min(h[x][y],z)
- 为什么要用邻接矩阵去存贮,而不是邻接表?
答:这个还是要看题目给的数据范围,我们采用邻接矩阵还是采用邻接表来表示图,需要判断一个图是稀疏图还是稠密图。稠密图指的是边的条数|E|接近于|V|²,稀疏图是指边的条数|E|远小于于|V|²(数量级差很多)。本题是稠密图,显然稠密图用邻接矩阵存储比较节省空间,反之用邻接表存储。
- 时间复杂度怎么算的?
- 寻找路径中不在集合的最短距离的点 O(n^2)
- 加入集合 O(n)
- 更新距离 O(m) (邻接表实现) ,O(n^2)(邻接矩阵实现)
综合来说,时间复杂度 O(n^2)
2.3 堆优化Dijkstra
根据名字,我们显然知道 我们的朴素Dijkstra是可以优化的,那么我们该从哪里寻求突破呢?我们注意到在朴素版dijkstra中时间复杂度最高的寻找距离最短的点O(n^2)可以使用最小堆优化。
如果有对堆不熟悉的同学可以看这篇博客:
【C语言】堆
如果有对C++stl中的优先级队列 (priority_queue)不熟悉的同学可以看这篇博客:
【C++】手把手教你写出自己的Stack和Queue类
模板题

思路模板
由于加入了 小根堆来优化,我们的细节有一些变化,但是思路是一致的。

虽然思路一致,但是我还是画图来加深一下同学们的理解:
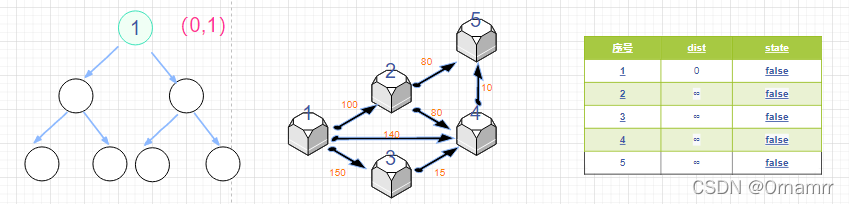
我依旧设置 :
- dist 距离数组保存源点到其余各个节点的距离,即 dist[i]表示 节点i到源点的距离。初始时,dist的各个元素为 +∞(除了源点设置为0)
- state 状态数组记录是否找到了源点到该节点的最短距离,如果state[i]==true,那么就表示已经找到了源点到节点i 的最短距离,反之就还没有找到。 初始时,dist的各个元素为 false.
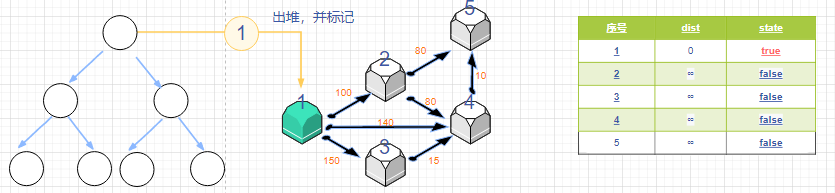
- 设置一个 小根堆 heap。heap一个节点内存储 (距离,编号),我们现将节点1入堆。
取堆头,即为不在s中的最小距离节点t,如果节点t不在堆中(可能出现同一节点多次入堆,之后会出现),则标记。
使用节点t去更新可达节点j的距离,如果有节点j的距离更新之后变小了,那么入堆。
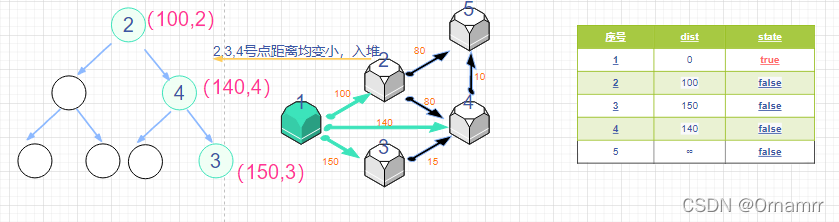
之后就循环这两步就可以了:
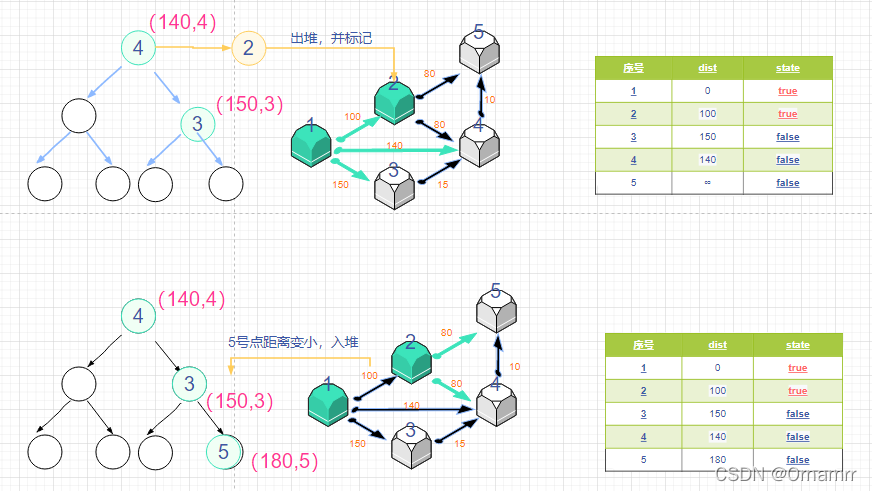
这里我们要注意一下,我们会发现,节点5两次入堆了,这并不反常,因为第一个节点5是节点2更新的结果,另一个是节点4更新的结果。
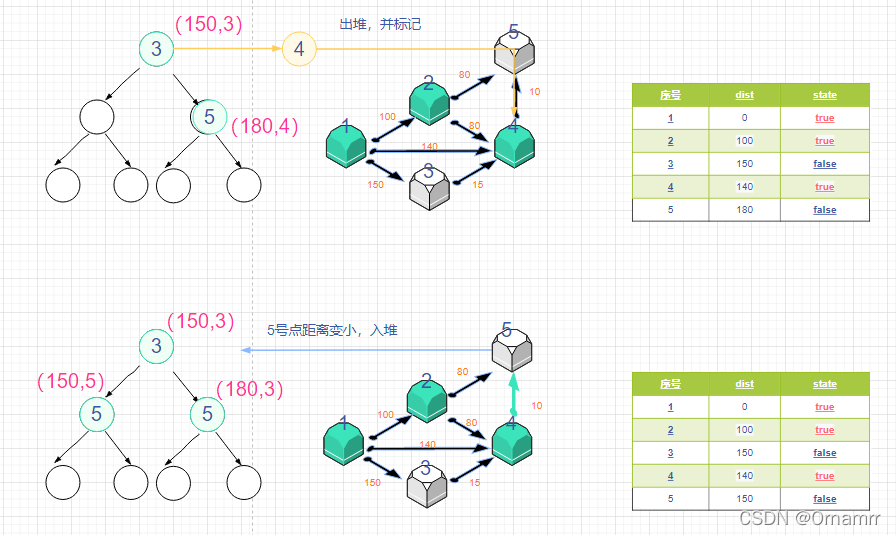
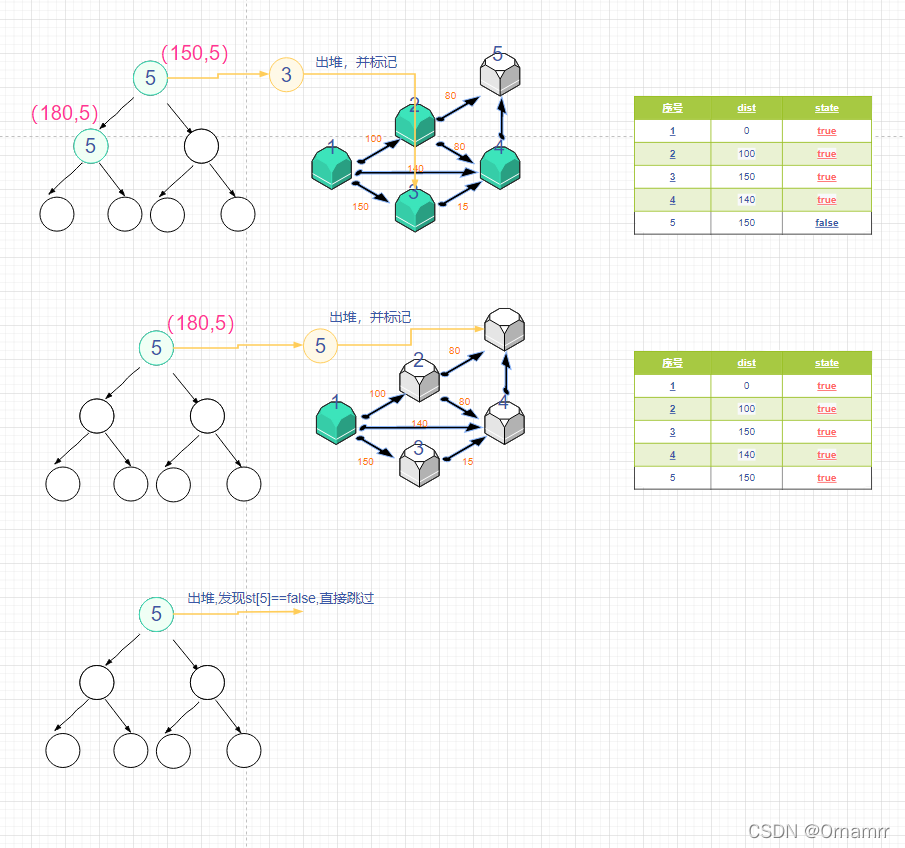
如果某个节点之前已经出过堆,那么代表我们一定已经把它更新为最短距离了,那么在堆中的相同节点我们就没有处理的必要,就算处理了也无济于事。比如就算我们让最后一个节点5出栈取更新,180也比150大,最终结果还是150.
代码实现
#include<iostream>
#include<cstring>
#include<vector>
#include<queue>
using namespace std;
//稀疏图 使用 邻接表 来存储
const int N=150010,M=N;
int h[N],e[M],ne[M],w[M],idx; //邻接表的链式向前星写法(数组模拟实现链表)
bool st[N]; //状态数组
int dist[N];//距离数组
int n,m;
//邻接表的添加元素接口
void add(int x,int y,int z){
w[idx]=z;
e[idx]=y;
ne[idx]=h[x];
h[x]=idx++;
}
int dijkstra()
{
memset(dist,0x3f,sizeof dist);
dist[1]=0;
priority_queue<pair<int,int>,vector<pair<int,int>>,greater<pair<int,int>>>heap;
heap.push({
0,1});
while(heap.size()){
pair<int,int>cur=heap.top();
heap.pop();
int distance=cur.first;
int point=cur.second;
//如果已经更新完成,直接跳过 (参见上图中的节点5)
if(st[point])continue;
st[point]=true;
//遍历可达点,并以尝试更新
for(int i=h[point];i!=-1;i=ne[i]){
int j=e[i];
if(dist[j]>w[i]+distance){
dist[j]=w[i]+distance;
heap.push({
dist[j],j});//节点距离变小,入堆
}
}
}
if(dist[n]==0x3f3f3f3f)return -1;
else return dist[n];
}
int main()
{
memset(h,-1,sizeof h);
cin>>n>>m;
while(m--){
int x,y,w;
cin>>x>>y>>w;
add(x,y,w);
}
cout<<dijkstra()<<endl;
return 0;
}
常见的疑问
- 这个数组模拟链表是啥意思?代码看不懂。
答: 没了解过的同学可能确实比较难理解,尤其是idx是啥。我之后可能会出一篇博客讲解,同学可以先搜搜其他讲解,或者使用链表也可以实现的,只是相对比较慢。
- 时间复杂度
- 寻找最短距离点 : 每次O(1),一共n次, O(N)
- 加入集合 O(N)
- 更新距离
每次找到最小距离的点沿着边更新其他的点,若dist[j] > distance + w[i],表示可以更新dist[j],更新后再把j点和对应的距离放入小根堆中。由于点的个数是n,边的个数是m,在极限情况下(稠密图m=n(n−1)/2),最多可以更新m回,每一回最多可以更新n个点(严格上是n - 1个点),有m回,因此最多可以把n^ 2 个点放入到小根堆中,因此每一次更新小根堆排序的情况是O(log(n^2)),一共最多m次更新,因此总的时间复杂度上限是O(mlog((n ^ 2))=O(2mlogn)=O(mlogn)
综上,O(MlogN)
- 为什么当图中存在负权边的时候,Dijkstra算法就失效了?
其实很好解释,直接画图即可:
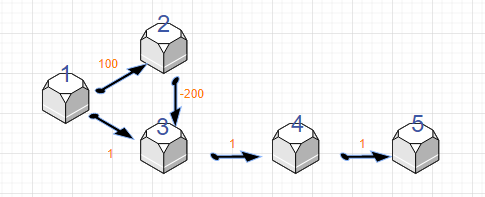
如果我们按照Diljstra的思路,显然会得到一个错误的结论:
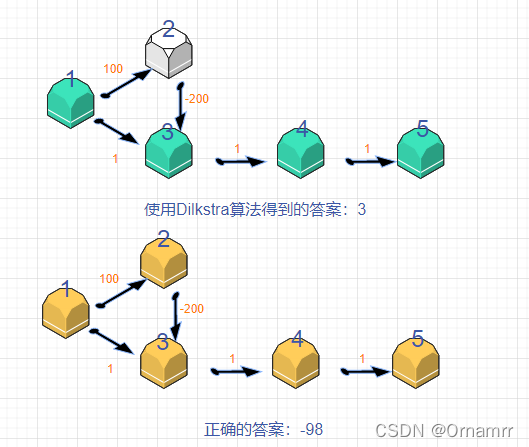
2.2 Bellman_ford算法
使用场景
当存在负边的时候,我们就需要考虑使用Bellman_ford,该算法概括起来就两个字,暴力。其实下一个算法SPFA也能处理负权边,且效率优于Bellman_ford。
但是,存在即合理,Bellman_ford并不是一无是处,当题目限制了最短路径的长度的时候(比如下面的模板题),此时我们只能选择Bellman_ford…
模板题

思路模板
- 初始化所有点到源点的距离为∞,把源点到自己的距离设置为0;
- 不管三七二十一,遍历n次;每次遍历m条边,用每一条边去更新各点到源点的距离。
我们依旧是画图来直观感受一下:
我们设置:
3. 定义结构体 数组e[M],把每条边的信息(两个节点编号,权值)存储下来。
truct Edge{
int a;
int b;
int w;
}e[M];//把每个边保存下来即可
- 设置距离数组 dist[N],保存源点到其余各个节点的距离,即 dist[i]表示 节点i到源点的距离。初始时,dist的各个元素为 +∞(除了源点设置为0)
- 设置备份数组 backup[N],备份数组防止串联(作用之后会讲)
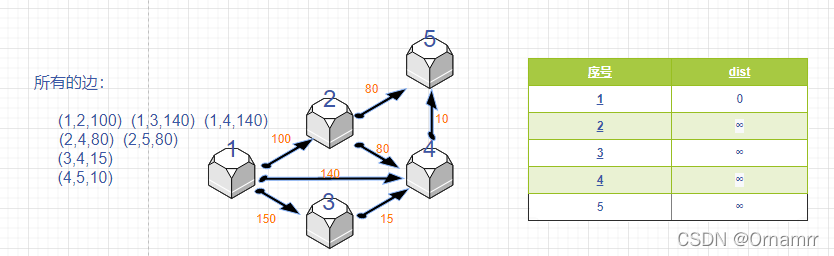
我们先看第一次循环:
这是我们的初始状态:
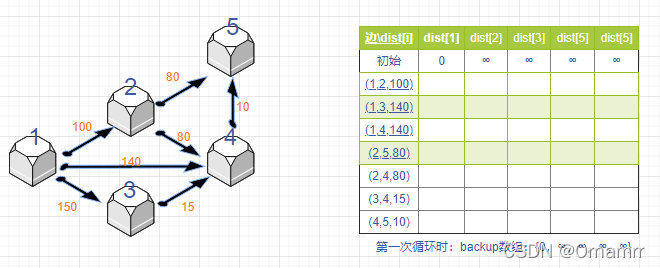
我们先用前3条边都更新一下dist:
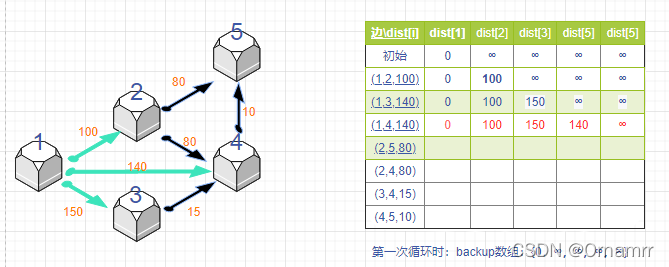
到此时位置都很简单,接下来我们需要思考一个问题:下一次更新之后节点5距离节点1的距离(即dist[5])是多少?
dist[5]=min(dist[5],dist[2]+80),那么dist[5]应该更新为 180,这样对吗?
如果这样想的同学,就没有理解好Bellman_ford算法 和 Dijkstra的区别,也没有理解为什么Bellon_ford就可以在限制边数的基础上得到答案。
我们设想这样一种状况:题目限制k=1,我们走一条边就结束,那就是总共我们只用遍历一遍所有边去更新。按照上面的更新方式,最终dist[5]=150,**这意味着什么呢:如果我们想在走不超过一条边的情况下到达节点5,最短距离是150.**这就显然错误了,只走一条边怎么可能到达节点5?答案应该是无穷远,也就是impossible.
这是一种串联式更新,如果没有步数限制,那么串联式更新是无妨的,但是如果有限制,我们就应该避免这种串联:不能使用同一循环中更新的点再去更新其他点,我们使用上一循环的点去更新即可: dist[5]=min(dist[5],backup[a]+w); 此时backup[2]=无穷,得到的dist[5]=无穷。
所以第一次循环结果如下:
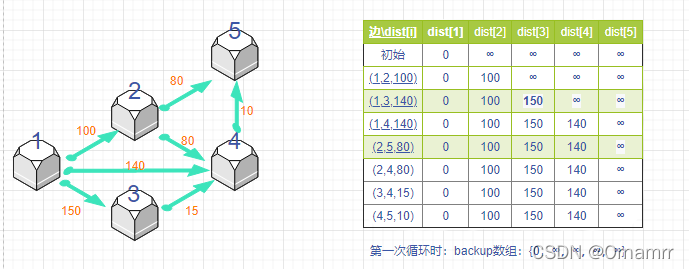
之后还有四次循环,基本一致,只要理解到backup数组的作用即可。
代码实现
#include<iostream>
#include<cstring>
using namespace std;
const int N=510,M=10010;
struct Edge{
int a;
int b;
int w;
}e[M];//把每个边保存下来即可
int dist[N];
int back[N];//备份数组放置串联
int n,m,k;//k代表最短路径最多包涵k条边
int bellman_ford(){
memset(dist,0x3f,sizeof dist);
dist[1]=0;
for(int i=0;i<k;i++){
//k次循环
memcpy(back,dist,sizeof dist);
for(int j=0;j<m;j++){
//遍历所有边
int a=e[j].a,b=e[j].b,w=e[j].w;
dist[b]=min(dist[b],back[a]+w);
//使用backup:避免给a更新后立马更新b,这样b一次性最短路径就多了两条边出来
}
}
if(dist[n]>0x3f3f3f3f/2) return -1;
else return dist[n];
}
int main(){
scanf("%d%d%d",&n,&m,&k);
for(int i=0;i<m;i++){
int a,b,w;
scanf("%d%d%d",&a,&b,&w);
e[i]={
a,b,w};
}
int res=bellman_ford();
if(res==-1) puts("impossible");
else cout<<res;
return 0;
}
常见问题
- 为什么返回判断的时候是:dist>0x3f3f3f3f/2?
我们看一下下面这个图:
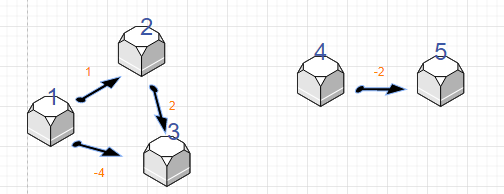
这个图很特殊,终点和起点不相连。根据我们的算法(会遍历到每条边,与连通性无关),4号点在经过更新之后可能会更新到节点5,节点会更新为 0x3f3f3f3f-2了,此时dist[5]!=0x3f3f3f3f,但是实际上我们也永远不可能到达节点5。
当然这个dist[n]也不可能无限的被减小,因为按题目给出:每条边权值为1e5, 最多有500个点,也就是说,最多更新到 0x3f3f3f3f-499*2e5。我们保险一点,取0x3f3f3f3f/2作为判定条件。
2.3 Spfa 算法
SPFA算法实际上是对Bellman_Ford算法的一个优化。所以它们两个的使用场景几乎相同,除了限定步数情况只有Spfa算法能做。由于大部分时候时间复杂度上不高,所以Spfa是可以平替Dijkstra算法的。
模板题

思路模板
相比于 Bellman_Ford的思路优化
bellman-ford算法操作如下:
for n次
for 所有边 a,b,w //该步骤别名叫松弛操作
dist[b] = min(dist[b],back[a] + w)
spfa 算法对于第二行所有边进行松弛操作进行了优化,原因在于在bellman_Ford苏算法中,就是改点的最短距离尚未更新过,但还是需要用尚未更新过的值取更新其他点,显然操作是必要的,我们只需要找到更新过的值取更新其他点即可。
比如对于之前的Bellman_Ford算法例子的第一次循环,其中边(2,5),(2,4),(3,4),(4,5),这些边的两个端点距离都是无穷 ,对它们做更新完全是浪费时间
spfa算法思路

我们依旧是看图说话:
我们设置:
- 距离数组dist[N]
- 状态数组 st[N],这里的st数组与diljstra中保存确定最短路点的功能不同,仅仅表示的是当前是否在队列中,是可逆的
- 队列que,存储节点。目的是记录发生更新(距离变小的)的点,再让这些变小的再去更新之后的点。
初始时:
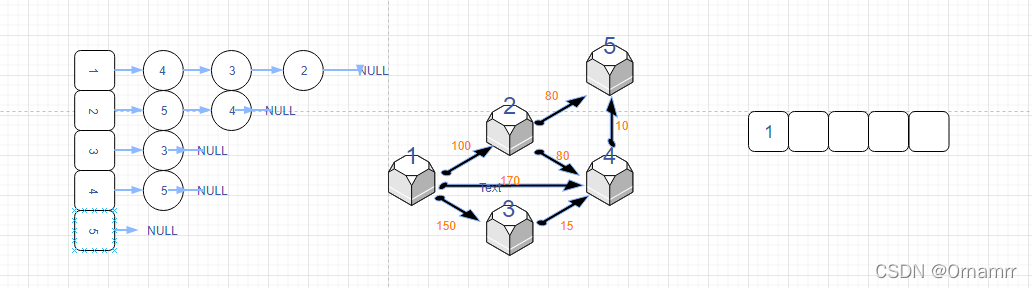
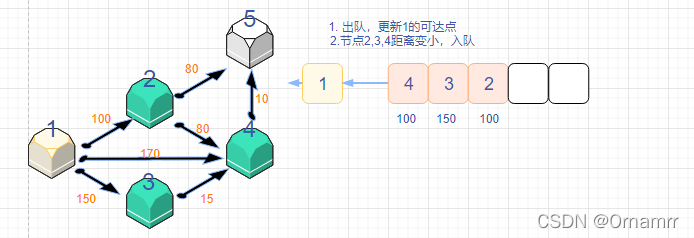
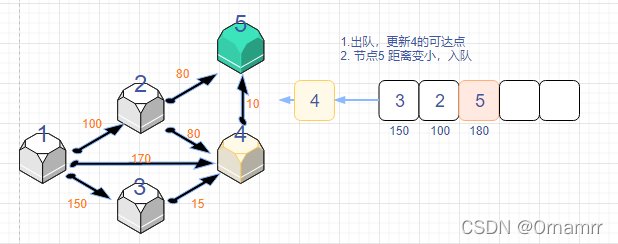
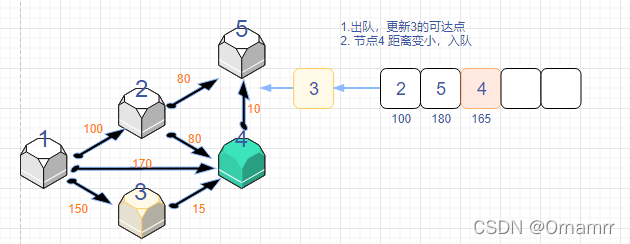
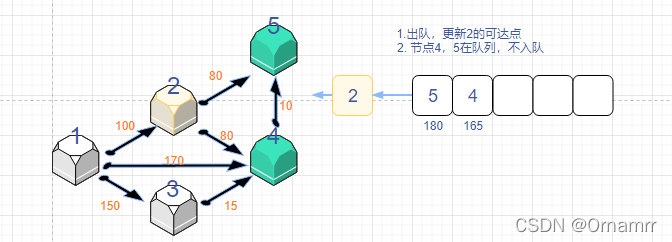
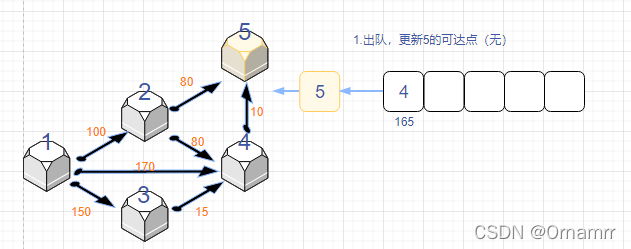
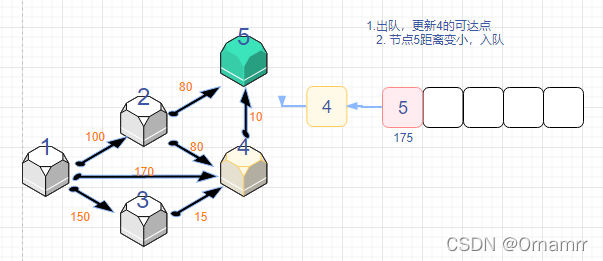
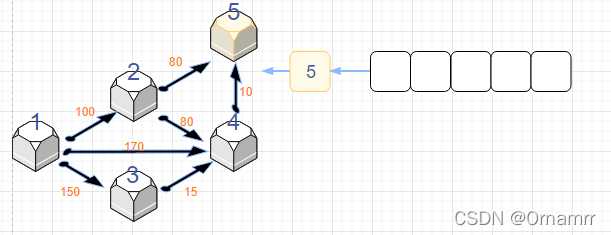
可以看见,这个算法和Dijkstra算法十分相似,我们一定要注意区别。
代码实现
#include<iostream>
#include<queue>
#include<cstring>
using namespace std;
const int N=1e5+10;
int h[N],e[N],ne[N],w[N],idx;
int dist[N];
bool st[N];
int n,m;
void add(int a,int b,int c){
w[idx]=c;
e[idx]=b;
ne[idx]=h[a];
h[a]=idx++;
}
int SPFA()
{
memset(dist,0x3f,sizeof dist);
dist[1]=0;
queue<int>que;
que.push(1);
st[1]=true;
while(!que.empty()){
int t=que.front();
que.pop();
st[t]=false;
//更新所有关联边
for(int i=h[t];i!=-1;i=ne[i]){
int j=e[i];
if(dist[j]>w[i]+dist[t]){
dist[j]=w[i]+dist[t];
if(!st[j]){
st[j]=true;
que.push(j);
}
}
}
}
return dist[n];
}
int main()
{
memset(h,-1,sizeof h);
cin>>n>>m;
for(int i=0;i<m;i++){
int x,y,w;
cin>>x>>y>>w;
add(x,y,w);
}
int ret=SPFA();
if(ret==0x3f3f3f3f)cout<<"impossible"<<endl;
else cout<<ret;
return 0;
}
常见的疑问
- 为什么Spfa算法的返回条件写的是 dist[n]==0x3f3f3f3f,与Bellman_Ford不一样?
其原因在于Bellman_ford算法会遍历所有的边,因此不管是不是和源点相联通,它都会得到更新。但是SPFA算法不同,它相当于采取了BFS,因此遍历到的节点都是与源点联通的,因此非联通节点不会得到更新,还是保持0x3f3f3f3f.
- Bellman_ford算法 可以存在负权回路。这是由于其两层循环是固定的,不会发生死循环。但是对于SPFA算法来说,由于使用队列来存储,只要发生了更新机会不断的入队,如果存在负权回路的话就会陷入死循环。
- SPFA算法最坏的情况下时间复杂度与 Bellman_Ford相同。其他时候可以代替Dijkstra.
- 求是否有负环一般使用SPFA,方法是用一个cnt数组记录每一个点到源点的边数,一个点被更新一次就+1,一旦有 点的边数达到了n就说明存在负环(抽屉原理)。
2.4 Floyd 算法
Floyd 是基于 动态规划 得出的一种 求解多起点的最短路问题的算法。也十分暴力,直接三循环,时间复杂度是O(n^3).
模板题:

思路模板
理解状态公式是如何推导而来的是理解Floyd的关键:
假设节点序号是从1到n。
假设f[0][i][j]是一个n*n的矩阵,第i行第j列代表从i到j的权值,如果i到j有边,那么其值就为ci,j(边ij的权值)。
如果没有边,那么其值就为无穷大。
f[k][i][j]代表(k的取值范围是从1到n),在考虑了从1到k的节点作为中间经过的节点时,从i到j的最短路径的长度。
比如,f[1][i][j]就代表了,在考虑了1节点作为中间经过的节点时,从i到j的最短路径的长度。
分析可知,f[1][i][j]的值无非就是两种情况,而现在需要分析的路径也无非两种情况,i=>j,i=>1=>j:
- f[0][i][j]:i=>j这种路径的长度,小于,i=>1=>j这种路径的长度
- f[0][i][1]+f[0][1][j]:i=>1=>j这种路径的长度,小于,i=>j这种路径的长度
形式化说明如下,f[k][i][j]可以从两种情况转移而来:
- 从f[k−1][i][j]转移而来,表示i到j的最短路径不经过k这个节点
- 从f[k−1][i][k]+f[k−1][k][j]转移而来,表示i到j的最短路径经过k这个节点=
总结就是:f[k][i][j]=min(f[k−1][i][j],f[k−1][i][k]+f[k−1][k][j])
从总结上来看,发现f[k]只可能与f[k−1]有关。
代码实现
#include<iostream>
using namespace std;
const int N=210,INF=1e9;
int d[N][N];
int n,m,k,x,y,z;
void Floyd()
{
for(int k=1;k<=n;k++){
for(int i=1;i<=n;i++){
for(int j=1;j<=n;j++){
d[i][j]=min(d[i][j],d[i][k]+d[k][j]);
}
}
}
}
int main()
{
cin>>n>>m>>k;
for(int i=1;i<=n;i++){
for(int j=1;j<=n;j++){
if(i==j)d[i][j]=0;
else d[i][j]=INF;
}
}
while(m--){
cin>>x>>y>>z;
d[x][y]=min(d[x][y],z);
}
Floyd();
while(k--){
cin>>x>>y;
if(d[x][y]>INF/2)cout<<"impossible"<<endl;
else cout<<d[x][y]<<endl;
}
return 0;
}
3. 结语
本篇博客讲的仅仅是一些“模板题”,最短路径乃至于图论问题的另一大挑战在于如何将题目抽象为一张图,只有这样,我们才能套用模板。