关于局部注意力和动态深度卷积之间的联系
paper题目:ON THE CONNECTION BETWEEN LOCAL ATTENTION AND DYNAMIC DEPTH-WISE CONVOLUTION
paper是南开大学发表在ICLR 2022的工作
paper地址:链接
ABSTRACT
Vision Transformer (ViT) 在视觉识别方面取得了最先进的性能,而变体 Local Vision Transformer 进一步改进。 Local Vision Transformer 中的主要组件,局部注意力,在小的局部窗口上分别执行注意力。将局部注意力重新表述为通道方式的局部连接层,并从稀疏连接和权重共享两种网络正则化方式以及动态权重计算来对其进行分析。作者指出,局部注意力类似于深度卷积及其在稀疏连接中的动态变体:通道之间没有连接,每个位置都连接到一个小的局部窗口内的位置。主要区别在于(i)权重共享 - depth-wise convolution 共享空间位置之间的连接权重(内核权重),attention 共享通道间的连接权重,以及(ii)动态权重计算方式 - 局部注意力是基于局部窗口中成对位置之间的点积,动态卷积基于对中心表示或全局池化表示进行的线性投影。
局部注意力和动态深度卷积之间的联系通过对Local Vision Transformer和(动态)深度卷积中权重共享和动态权重计算的消融研究进行了实验验证。凭实验观察到,基于深度卷积的模型和计算复杂度较低的动态变体在 ImageNet 分类、COCO 目标检测和 ADE 语义分割方面的表现与 Swin Transformer(Local Vision Transformer 的一个实例)相当或略好。代码地址:链接
1 INTRODUCTION
Vision Transformer在 ImageNet 分类中显示出可观的性能。改进的变体 Local Vision Transformer采用局部注意力机制,将图像空间划分为一组小窗口,并且同时将注意力转移到窗口上。局部注意力极大地提高了内存和计算效率,并使下游任务的扩展更容易和更有效,例如目标检测和语义分割。
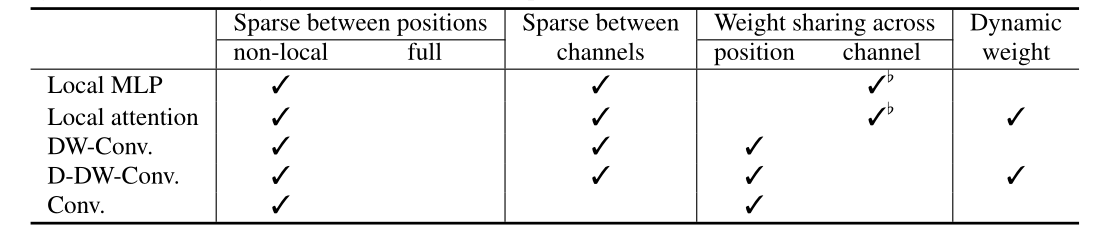
作者利用网络正则化方案、控制模型复杂性的稀疏连接、放宽增加训练数据规模和减少模型参数的要求的权重共享,以及增加的动态权重预测模型能力,研究局部注意力机制。将局部注意力重新表述为具有动态连接权重的通道方式空间局部连接层。主要性能总结如下。 (i) 稀疏连接:没有跨通道连接,每个输出位置只连接到局部窗口内的输入位置。 (ii) 权重共享:连接权重在通道之间或每组通道内共享。 (iii) 动态权重:根据每个图像实例动态预测连接权重。
将局部注意力与深度卷积及其动态变体联系起来,这些变体也是具有可选动态连接权重的通道空间局部连接层。它们在稀疏连接上是相似的。主要区别在于(i)权重共享 - depth-wise convolution 共享空间位置之间的连接权重(内核权重),attention 共享通道间的连接权重,以及(ii)动态权重计算方式 - 局部注意力是基于局部窗口中成对位置之间的点积,动态卷积基于对中心表示或全局池化表示进行的线性投影。
作者进一步提出了连接的实验验证。以最近开发的 Local Vision Transformer Swin Transformer为例,研究在与 Swin Transformer 相同的训练设置下局部注意力和(动态)深度卷积的实验性能。用(动态)深度卷积层替换局部注意力层,保持整体结构不变。
结果表明,基于(动态)深度卷积的方法在 ImageNet 分类和两个下游任务 COCO 目标检测和 ADE 语义分割方面实现了相当或略高的性能,并且(动态)深度卷积需要更低的计算复杂度。消融研究表明权重共享和动态权重提高了模型的能力。具体来说,(i) 对于 Swin Transformer,跨通道的权重共享主要有利于降低参数(注意力权重)复杂度,基于注意力的动态权重方案有利于学习特定于实例的权重和block-translation等价表示; (ii) 对于深度卷积,跨位置的权重共享有利于降低参数复杂度以及学习平移等效表示,并且基于线性投影的动态权重方案学习特定于实例的权重。
2 CONNECTING LOCAL ATTENTION AND DEPTH-WISE CONVOLUTION
2.1 LOCAL ATTENTION
Vision Transformer通过重复注意力层和随后的逐点 MLP(逐点卷积)形成网络。局部 Vision Transformer,如Swin Transformer和HaloNet,采用局部注意力层,将空间划分为一组小窗口并进行注意力操作每个窗口内同时进行,以提高内存和计算效率。
局部注意力机制在query所在的窗口中形成key和value。query x i ∈ R D \mathbf{x}_{i} \in \mathbb{R}^{D} xi∈RD在位置 i i i的注意力输出是局部窗口中相应值的集合, { x i 1 , x i 2 , … , x i N k } \left\{\mathbf{x}_{i 1}, \mathbf{x}_{i 2}, \ldots, \mathbf{x}_{i N_{k}}\right\} {
xi1,xi2,…,xiNk},由相应的注意力权重 { a i 1 , a i 2 , … , a i N k } 1 \left\{a_{i 1}, a_{i 2}, \ldots, a_{i N_{k}}\right\}^{1} {
ai1,ai2,…,aiNk}1的加权
y i = ∑ j = 1 N k a i j x i j ( 1 ) \mathbf{y}_{i}=\sum_{j=1}^{N_{k}} a_{i j} \mathbf{x}_{i j} \quad(1) yi=j=1∑Nkaijxij(1)
其中 N k = K w × K h N_{k}=K_{w} \times K_{h} Nk=Kw×Kh是局部窗口的大小。注意力权重 a i j a_{i j} aij被计算为query x i \mathbf{x}_{i} xi和key x i j \mathbf{x}_{i j} xij之间的点积的 softmax 归一化:
a i j = e 1 D x i ⊤ x i j Z i where Z i = ∑ j = 1 N k e 1 D x i ⊤ x i j ( 2 ) a_{i j}=\frac{e^{\frac{1}{\sqrt{D}} \mathbf{x}_{i}^{\top} \mathbf{x}_{i j}}}{Z_{i}} \text { where } Z_{i}=\sum_{j=1}^{N_{k}} e^{\frac{1}{\sqrt{D}} \mathbf{x}_{i}^{\top} \mathbf{x}_{i j}} \quad(2) aij=ZieD1xi⊤xij where Zi=j=1∑NkeD1xi⊤xij(2)
多头版本将 D D D维query、key和value向量划分为 M M M个子向量(每个子向量有 D M \frac{D}{M} MD个维度),并在相应的子向量上执行 M M M次注意力过程。整个输出是 M M M个输出的串联, y i = [ y i 1 ⊤ y i 2 ⊤ … y i M ⊤ ] ⊤ \mathbf{y}_{i}=\left[\begin{array}{llll}\mathbf{y}_{i 1}^{\top} & \mathbf{y}_{i 2}^{\top} & \ldots & \mathbf{y}_{i M}^{\top}\end{array}\right]^{\top} yi=[yi1⊤yi2⊤…yiM⊤]⊤。第 m m m个输出 y i m \mathbf{y}_{i m} yim由下式计算
y i m = ∑ j = 1 N k a i j m x i j m ( 3 ) \mathbf{y}_{i m}=\sum_{j=1}^{N_{k}} a_{i j m} \mathbf{x}_{i j m} \quad(3) yim=j=1∑Nkaijmxijm(3)
其中 x i j m \mathbf{x}_{i j m} xijm是第 m m m个值子向量, a i j m a_{i j m} aijm是从第 m m m个头计算的注意力权重,方法与公式 2 相同。
2.2 SPARSE CONNECTIVITY, WEIGHT SHARING, AND DYNAMIC WEIGHT
简要介绍了两种正则化形式,稀疏连接和权重共享,以及动态权重,以及它们的好处。将使用这三种形式来分析局部注意力并将其连接到动态深度卷积。
稀疏连通性意味着一层中的一些输出神经元(变量)和一些输入神经元之间没有连接。它在不减少神经元数量的情况下降低了模型复杂度,例如(隐藏)表示的大小。
权重共享表示某些连接权重是相等的。它减少了模型参数的数量并增加了网络大小,而无需相应增加训练数据。
动态权重是指为每个实例学习专门的连接权重。它通常旨在增加模型容量。如果将学习到的连接权重视为隐藏变量,则动态权重可以被视为引入增加网络能力的二阶操作。
2.3 ANALYZING LOCAL ATTENTION
局部注意力是一个通道方式的空间局部连接层,具有动态权重计算,并讨论了它的属性。图 1 © 说明了连接模式。
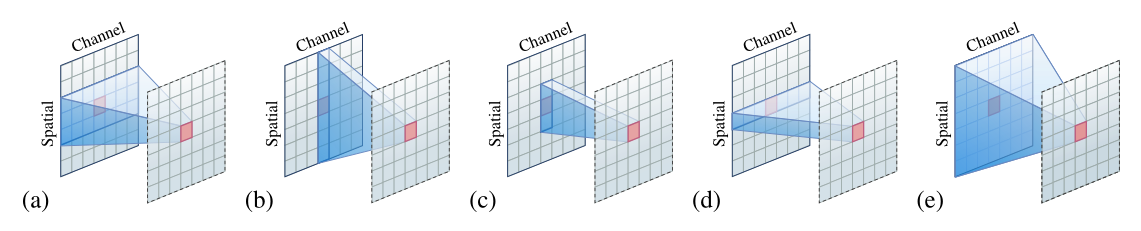
图 1:(a) 卷积、(b) 全局注意力和空间混合 MLP、© 局部注意力和深度卷积、(d) 逐点 MLP 或 1 × 1 1 \times 1 1×1卷积 (e) MLP(全连接层)。在空间维度上,为了清楚起见,使用一维来说明局部连接模式。
局部注意力的聚合过程(公式 1 和公式 3)可以等效地以元素乘法的形式重写:
y i = ∑ j = 1 N k w i j ⊙ x i j ( 4 ) \mathbf{y}_{i}=\sum_{j=1}^{N_{k}} \mathbf{w}_{i j} \odot \mathbf{x}_{i j} \quad (4) yi=j=1∑Nkwij⊙xij(4)
其中 ⊙ \odot ⊙是元素乘法算子, w i j ∈ R D \mathbf{w}_{i j} \in \mathbb{R}^{D} wij∈RD是注意力权重 a i j a_{i j} aij或 { a i j 1 , a i j 2 , … , a i j M } \left\{a_{i j 1}, a_{i j 2}, \ldots, a_{i j M}\right\} {
aij1,aij2,…,aijM}。
稀疏连接。局部注意力层在空间上是稀疏的:每个位置都连接到一个小的局部窗口中的 N k N_{k} Nk个位置。也没有跨通道的连接。公式 4 中的元素乘法表明,给定注意力权重,每个输出元素,例如 y i d y_{i d} yid(第 d d d个通道的第 i i i个位置)仅取决于窗口中来自同一通道的相应输入元素, { x i 1 d , x i 2 d , … , x i N k d } \left\{x_{i 1 d}, x_{i 2 d}, \ldots, x_{i N_{k} d}\right\} { xi1d,xi2d,…,xiNkd},与其他通道无关。
权重共享。权重是相对于通道共享的。在单头注意力的情况下,所有元素 { w i j 1 , w i j 2 , … , w i j D } \left\{w_{i j 1}, w_{i j 2}, \ldots, w_{i j D}\right\} { wij1,wij2,…,wijD}在权重向量 w i j \mathbf{w}_{i j} wij中是相同的: w i j d = a i j , 1 ⩽ d ⩽ D w_{i j d}=a_{i j}, 1 \leqslant d \leqslant D wijd=aij,1⩽d⩽D。在多头注意力的情况下,权重向量 w i j \mathbf{w}_{i j} wij在组内是相同的: w i j \mathbf{w}_{i j} wij被划分为 M M M个子向量,每个子向量对应一个注意头, { w i j 1 , w i j 2 , … , w i j M } \left\{\mathbf{w}_{i j 1}, \mathbf{w}_{i j 2}, \ldots, \mathbf{w}_{i j M}\right\} { wij1,wij2,…,wijM},每个子向量 w i j m \mathbf{w}_{i j m} wijm中的元素相同,都等于第 m m m个注意力权重 a i j m a_{i j m} aijm。
动态权重。权重 { w i 1 , w i 2 , … , w i N k } \left\{\mathbf{w}_{i 1}, \mathbf{w}_{i 2}, \ldots, \mathbf{w}_{i N_{k}}\right\} {
wi1,wi2,…,wiNk}, 是从query x i \mathbf{x}_{i} xi和key { x i 1 , x i 2 , … , x i N k } \left\{\mathbf{x}_{i 1}, \mathbf{x}_{i 2}, \ldots, \mathbf{x}_{i N_{k}}\right\} {
xi1,xi2,…,xiNk}在局部窗口中,如公式 2 所示。将其重写为:
{ w i 1 , w i 2 , … , w i N k } = f ( x i ; x i 1 , x i 2 , … , x i N k ) \left\{\mathbf{w}_{i 1}, \mathbf{w}_{i 2}, \ldots, \mathbf{w}_{i N_{k}}\right\}=f\left(\mathbf{x}_{i} ; \mathbf{x}_{i 1}, \mathbf{x}_{i 2}, \ldots, \mathbf{x}_{i N_{k}}\right) {
wi1,wi2,…,wiNk}=f(xi;xi1,xi2,…,xiNk)
每个权重都可以在一个头中获得跨所有通道的信息,并充当将跨通道信息传递到每个输出通道的桥梁。
Translation equivalence。与通过跨位置共享权重来满足平移等价性的卷积不同,局部注意力的平移等价性取决于key/value是否改变,即,当特征图平移时,注意力权重是否改变。
在稀疏采样窗口的情况下(为了提高运行时效率),例如局部attention等价于按块平移,即平移是一个块或多个块,块大小与窗口大小 K w × K h K_{w} \times K_{h} Kw×Kh相同,否则不等价(因为key/value发生了变化)。在窗口被密集采样的情况下,局部注意力相当于平移。
集合表示。一个query的key/value收集为一组集合,空间顺序信息丢失。这导致没有利用跨窗口的key/value之间的空间对应关系。通过将位置编码为嵌入或学习所谓的相对位置嵌入,部分补救了顺序信息丢失其中空间顺序信息被保存为局部窗口中的key/value,被收集为向量。
2.4 CONNECTION TO DYNAMIC DEPTH-WISE CONVOLUTION
深度卷积是一种对每个通道应用单个卷积滤波器的卷积: X ‾ d = C d ⊗ X d \overline{\mathbf{X}}_{d}=\mathbf{C}_{d} \otimes \mathbf{X}_{d} Xd=Cd⊗Xd,其中 X d \mathbf{X}_{d} Xd和 X ‾ d \overline{\mathbf{X}}_{d} Xd是第 d d d个输入和输出通道图, C d ∈ R N k \mathbf{C}_{d} \in \mathbb{R}^{N_{k}} Cd∈RNk是相应的核权重,并且 ⊗ \otimes ⊗是卷积运算。它可以等效地写成每个位置的元素乘法:
y i = ∑ j = 1 N k w offset ( i , j ) ⊙ x i j ( 6 ) \mathbf{y}_{i}=\sum_{j=1}^{N_{k}} \mathbf{w}_{\operatorname{offset}(i, j)} \odot \mathbf{x}_{i j} \quad (6) yi=j=1∑Nkwoffset(i,j)⊙xij(6)
这里,offset ( i , j ) (i, j) (i,j)是从位置 j j j的 2D 坐标到中心位置 i i i的 2D 坐标的相对偏移量。权重 { w offset ( i , j ) ∈ R D ; j = 1 , 2 , … , N k } \left\{\mathbf{w}_{\text {offset }(i, j)} \in \mathbb{R}^{D} ; j=1,2, \ldots, N_{k}\right\} {
woffset (i,j)∈RD;j=1,2,…,Nk}由 C 1 , C 2 , … , C D \mathbf{C}_{1}, \mathbf{C}_{2}, \ldots, \mathbf{C}_{D} C1,C2,…,CD重塑。 N k N_{k} Nk个权重向量是模型参数并为所有位置共享。
作者还考虑了深度卷积的两种动态变体:同质和非同质。同质动态变体使用来自通过全局池化特征图获得的特征向量的线性投影来预测卷积权重:
{ w 1 , w 2 , … , w N k } = g ( GAP ( x 1 , x 2 , … , x N ) ) \left\{\mathbf{w}_{1}, \mathbf{w}_{2}, \ldots, \mathbf{w}_{N_{k}}\right\}=g\left(\operatorname{GAP}\left(\mathbf{x}_{1}, \mathbf{x}_{2}, \ldots, \mathbf{x}_{N}\right)\right) {
w1,w2,…,wNk}=g(GAP(x1,x2,…,xN))
这里, { x 1 , x 2 , … , x N } \left\{\mathbf{x}_{1}, \mathbf{x}_{2}, \ldots, \mathbf{x}_{N}\right\} {
x1,x2,…,xN}是图像响应。 GAP() \text{GAP()} GAP()是全局平均池化算子。 g ( ) g() g()是一个基于线性投影的函数:一个线性投影层用 BN 和 ReLU 降低通道维度,然后是另一个线性投影来生成连接权重。
非均匀动态变体根据位置(窗口中心)的特征向量 x i \mathbf{x}_{i} xi分别预测每个位置的卷积权重:
{ w i 1 , w i 2 , … , w i N k } = g ( x i ) \left\{\mathbf{w}_{i_{1}}, \mathbf{w}_{i_{2}}, \ldots, \mathbf{w}_{i_{N_{k}}}\right\}=g\left(\mathbf{x}_{i}\right) {
wi1,wi2,…,wiNk}=g(xi)
这意味着权重不会跨位置共享。以类似于多头注意力机制的方式在通道之间共享权重,以降低复杂性。
作者描述了(动态)深度卷积和局部注意力之间的异同。图 1 © 说明了连接模式,表 1 显示了局部注意力和深度卷积以及各种其他模块之间的属性。
相似。深度卷积类似于稀疏连接中的局部注意力。没有跨通道的连接。每个位置仅连接到每个通道的小局部窗口中的位置。
不同。一个主要区别在于权重共享:深度卷积在空间位置之间共享连接权重,而局部注意力在通道之间或每组通道内共享权重。局部注意力使用适当的跨通道权重共享来获得更好的性能。深度卷积受益于跨位置的权重共享,以降低参数复杂度并提高网络能力。
第二个区别是深度卷积的连接权重是静态的并且作为模型参数学习,而局部注意力的连接权重是动态的并且从每个实例预测。深度卷积的动态变体也受益于动态权重。
另一个区别在于窗口表示。局部注意力通过使用丢失空间顺序信息的集合形式来表示窗口中的位置。它使用位置嵌入隐含地探索空间顺序信息,或使用学习的所谓的相对位置嵌入显式探索空间顺序信息。深度卷积利用向量形式:聚合局部窗口内的表示,权重由相对位置索引(参见公式 6);保持不同窗口位置之间的空间对应关系,从而明确地探索空间顺序信息。
表1:注意力、局部MLP(局部注意力的非动态版本,注意力权重作为静态模型参数学习)、局部注意力、卷积、深度卷积(DW-Conv.)和动态变体( D-DW-Conv.) 在稀疏连接、权重共享和动态权重的模式方面。有关连接模式的说明,请参阅图 1。