文章目录
3.3 Spatial Attention
空间注意力可以看作是一种自适应的空间区域选择机制:关注哪里。如图 4 所示,RAM [31]、STN [32]、GENet [61] 和 Non-Local [15] 代表了不同种类的空间注意方法。 RAM 代表基于 RNN 的方法。 STN 代表那些使用子网络来明确预测相关区域的人。 GENet 代表那些隐式使用子网络来预测软掩码以选择重要区域的方法。 Non-Local 表示自注意力相关的方法。
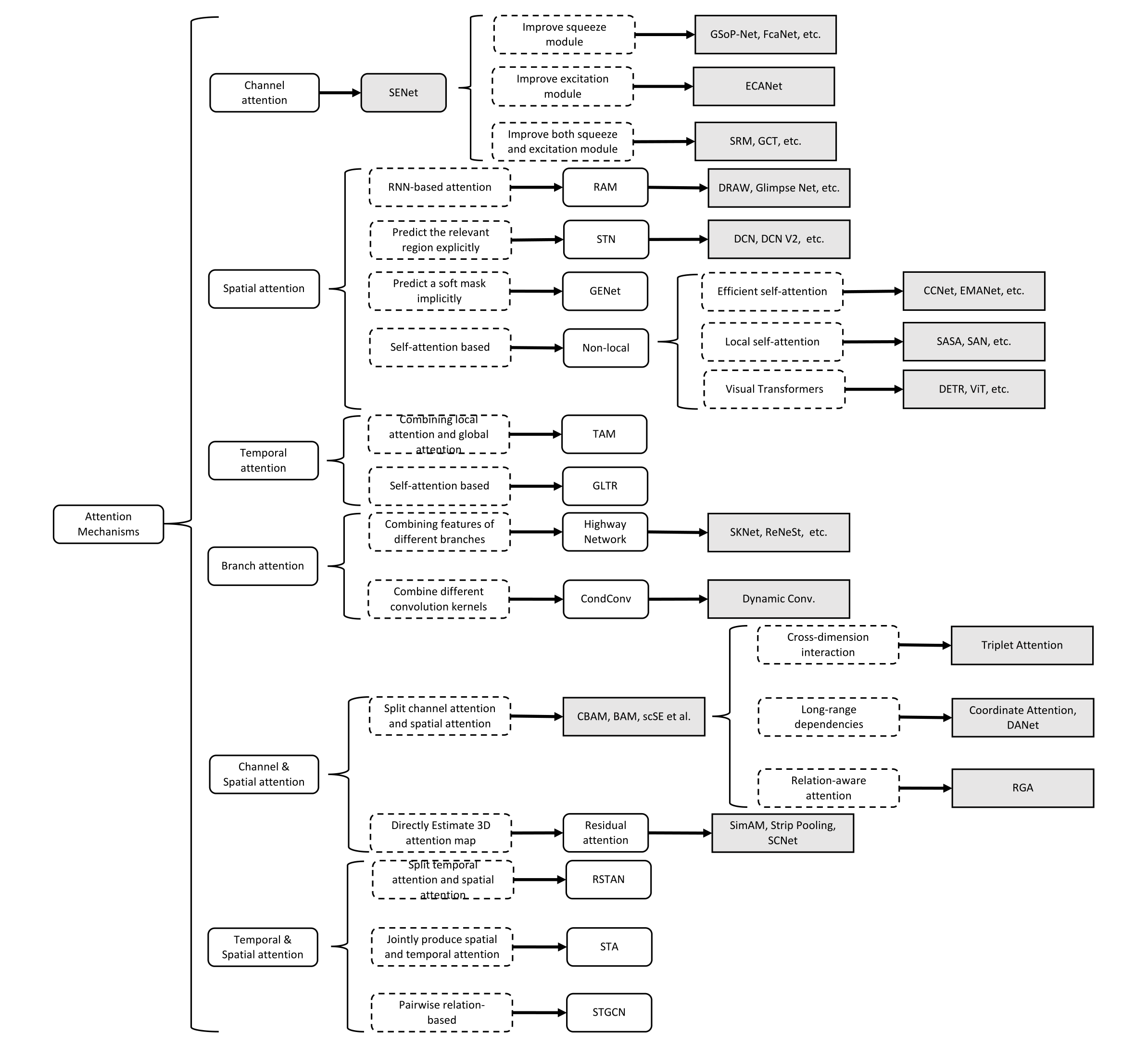
图 4. 视觉注意力的发展背景。
按类别和日期排序的代表性空间注意机制。应用领域包括:Cls = 分类,FGCls = 细粒度分类,Det = 检测,SSeg = 语义分割,ISeg = 实例分割,ST = 风格迁移,Action = 动作识别,ICap = 图像字幕。 Ranges 表示注意力图的范围。 S 或 H 表示软注意力或硬注意力。(A) 根据预测选择区域。 (B) 逐元素相乘,© 通过注意力图聚合信息。 (I) 将网络集中在判别区域,(II) 避免对大型输入图像进行过多计算,(III) 提供更多的变换不变性,(IV) 捕获远程依赖关系,(V) 去噪输入特征图 (VI) 自适应聚合邻域信息,(七)减少归纳偏差。
3.3.1 RAM
卷积神经网络具有巨大的计算成本,尤其是对于很大的输入。为了将有限的计算资源集中在重要区域,Mnih 等人提出了采用RNN和强化学习(RL)的循环注意模型(RAM)来使网络学习要注意的地方。 RAM 先使用 RNN 进行视觉注意力,随后出现了许多其他基于RNN的方法。
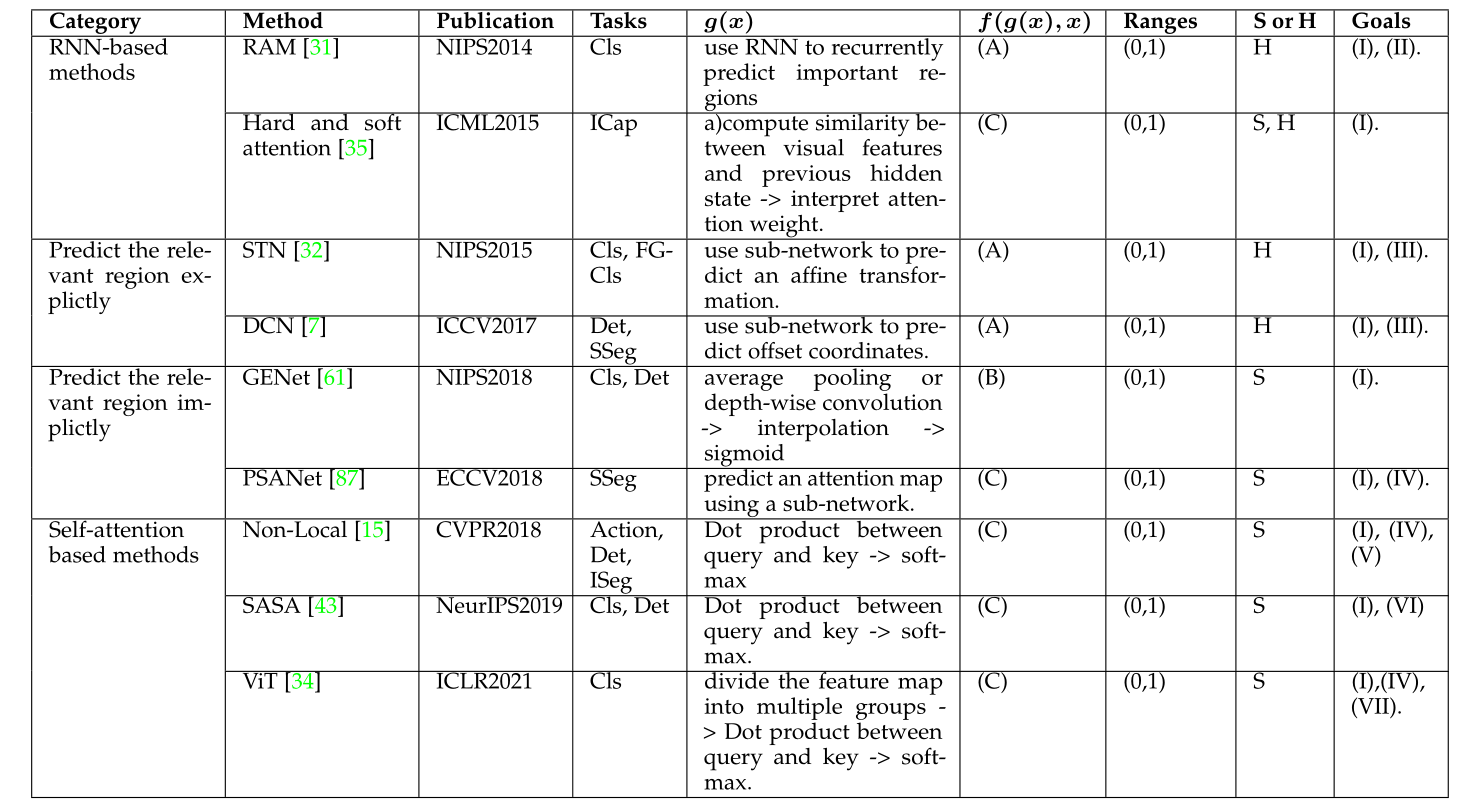
如图 6 所示,RAM 具有三个关键元素:(A)a glimpse 传感器,(B)a glimpse 网络和(C)一个 RNN 模型。 glimpse 传感器获取坐标 l t − 1 l_{t-1} lt−1和图像 X t X_{t} Xt。它输出以 l t − 1 l_{t-1} lt−1为中心的多个分辨率切片 ρ ( X t , l t − 1 ) \rho\left(X_{t}, l_{t-1}\right) ρ(Xt,lt−1)。 glimpse 网络 f g ( θ ( g ) ) f_{g}(\theta(g)) fg(θ(g))包括一个 glimpse 传感器,并输出输入坐标 l t − 1 l_{t-1} lt−1和图像 X t X_{t} Xt的特征表示 g t g_{t} gt。 RNN 模型考虑 g t g_{t} gt和内部状态 h t − 1 h_{t-1} ht−1并输出下一个中心坐标 l t l_{t} lt和动作 a t a_{t} at,例如softmax图像分类任务。由于整个过程不可微,因此在更新过程中应用了强化学习策略。
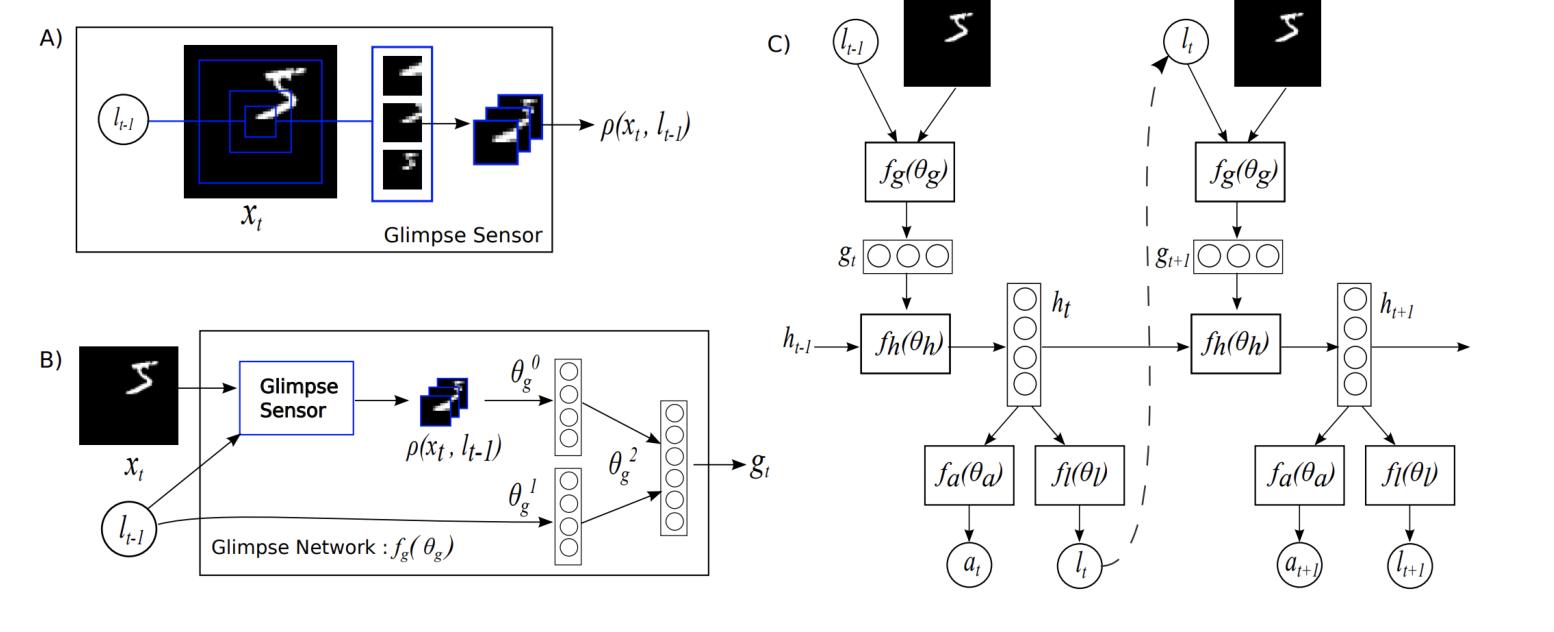
图 6. RAM中的注意力过程。 (A):a glimpse传感器将图像和中心坐标作为输入并输出多个分辨率补丁。 (B):a glimpse网络包括a glimpse传感器,以图像和中心坐标作为输入并输出特征向量。 © 整个网络循环使用一个 glimpse 网络,输出预测结果以及下一个中心坐标。
这提供了一种简单但有效的方法,可以将网络集中在关键区域,从而减少网络执行的计算次数,特别是对于大输入,同时改善图像分类结果。
3.3.2 Glimpse Network
受人类如何顺序执行视觉识别的启发,Ba 等人提出了一种类似于RAM的深度循环网络,能够处理输入图像的多分辨率裁剪,称为a glimpse,用于多对象识别任务。所提出的网络使用a glimpse作为输入来更新其隐藏状态,然后在每一步预测一个新对象以及下一个a glimpse位置。a glimpse通常比整个图像小得多,这使得网络的计算效率很高。
所提出的深度循环视觉注意模型由上下文网络、glimpse网络、循环网络、发射网络和分类网络组成。首先,上下文网络将下采样的整个图像作为输入,为循环网络提供初始状态以及第一次瞥见的位置。然后,在当前时间步 t t t,给定当前 glimpse x t x_{t} xt及其位置元组 l t l_{t} lt,glimpse网络的目标是提取有用信息,表示为
g t = f image ( X ) ⋅ f loc ( l t ) g_{t}=f_{\text {image }}(X) \cdot f_{\text {loc }}\left(l_{t}\right) gt=fimage (X)⋅floc (lt)
其中 f image ( X ) f_{\text {image }}(X) fimage (X)和 f loc ( l t ) f_{\text {loc }}\left(l_{t}\right) floc (lt)是非线性函数,它们都输出具有相同维度的向量,并且 ⋅ \cdot ⋅表示元素乘积,用于融合来自两个分支的信息。然后,由两个堆叠的循环层组成的循环网络聚合从每个单独的a glimpse中收集的信息。循环层的输出是:
r t ( 1 ) = f rec ( 1 ) ( g t , r t − 1 ( 1 ) ) r t ( 2 ) = f rec ( 2 ) ( r t ( 1 ) , r t − 1 ( 2 ) ) \begin{aligned} r_{t}^{(1)} &=f_{\text {rec }}^{(1)}\left(g_{t}, r_{t-1}^{(1)}\right) \\ r_{t}^{(2)} &=f_{\text {rec }}^{(2)}\left(r_{t}^{(1)}, r_{t-1}^{(2)}\right) \end{aligned} rt(1)rt(2)=frec (1)(gt,rt−1(1))=frec (2)(rt(1),rt−1(2))
给定循环网络的当前隐藏状态 r t ( 2 ) r_{t}^{(2)} rt(2),发射网络预测下一次裁剪的位置。形式上,它可以写成
l t + 1 = f e m i s ( r t ( 2 ) ) l_{t+1}=f_{\mathrm{emis}}\left(r_{t}^{(2)}\right) lt+1=femis(rt(2))
最后,分类网络根据循环网络的隐藏状态 r t ( 1 ) r_{t}^{(1)} rt(1)输出对类别标签 y y y的预测。
y = f c l s ( r t ( 1 ) ) y=f_{\mathrm{cls}}\left(r_{t}^{(1)}\right) y=fcls(rt(1))
与对整个图像进行操作的 CNN 相比,所提出的模型的计算成本要低得多,并且它可以自然地处理不同大小的图像,因为它只处理每一步的a glimpse。循环注意机制进一步提高了鲁棒性,这也缓解了过拟合的问题。该管道可以合并到任何最先进的 CNN backbone或 RNN 单元中。
3.3.3 Hard and soft attention
为了可视化图像说明生成模型应该关注的位置和内容,Xu 等人引入了一个基于注意力的模型以及两种不同的注意力机制,硬注意力和软注意力。
给定一组特征向量 a = { a 1 , … , a L } , a i ∈ R D \boldsymbol{a}=\left\{a_{1}, \ldots, a_{L}\right\}, a_{i} \in \mathbb{R}^{D} a={
a1,…,aL},ai∈RD从输入图像中提取,该模型旨在通过在每个时间步生成一个单词来生成标题。因此他们采用长短期记忆(LSTM)网络作为解码器;注意力机制用于生成以特征集 a \boldsymbol{a} a和先前隐藏状态 h t − 1 h_{t-1} ht−1为条件的上下文向量 z t z_{t} zt,其中 t t t表示时间步长。形式上,特征向量 a i a_{i} ai在第 t t t个时间步的权重 α t , i \alpha_{t, i} αt,i定义为
e t , i = f a t t ( a i , h t − 1 ) α t , i = exp ( e t , i ) ∑ k = 1 L exp ( e t , k ) \begin{aligned} e_{t, i} &=f_{\mathrm{att}}\left(a_{i}, h_{t-1}\right) \\ \alpha_{t, i} &=\frac{\exp \left(e_{t, i}\right)}{\sum_{k=1}^{L} \exp \left(e_{t, k}\right)} \end{aligned} et,iαt,i=fatt(ai,ht−1)=∑k=1Lexp(et,k)exp(et,i)
其中 f att f_{\text {att }} fatt 由以先前隐藏状态 h t − 1 h_{t-1} ht−1为条件的多层感知器实现。正权重 α t , i \alpha_{t, i} αt,i可以解释为位置 i i i是正确关注位置的概率(硬注意力),或位置 i i i对下一个词的相对重要性(软注意力)。为了获得上下文向量 z t z_{t} zt,hard attention 机制分配一个由 { α t , i } \left\{\alpha_{t, i}\right\} {
αt,i}参数化的 multinoulli 分布,并将 z t z_{t} zt视为随机变量:
p ( s t , i = 1 ∣ a , h t − 1 ) = α t , i z t = ∑ i = 1 L s t , i a i \begin{aligned} p\left(s_{t, i}\right.&\left.=1 \mid \boldsymbol{a}, h_{t-1}\right)=\alpha_{t, i} \\ z_{t} &=\sum_{i=1}^{L} s_{t, i} a_{i} \end{aligned} p(st,izt=1∣a,ht−1)=αt,i=i=1∑Lst,iai
另一方面,软注意力机制直接使用上下文向量 z t z_{t} zt的期望,
z t = ∑ i = 1 L α t , i a i z_{t}=\sum_{i=1}^{L} \alpha_{t, i} a_{i} zt=i=1∑Lαt,iai
注意力机制的使用通过允许用户了解模型关注的内容和位置来提高图像说明生成过程的可解释性。它还有助于提高网络的表示能力。
3.3.4 Attention Gate
以前的 MR 分割方法通常在特定的感兴趣区域 (ROI) 上运行,这需要过度和浪费地使用计算资源和模型参数。为了解决这个问题,Oktay 等人提出了一种简单而有效的机制,即注意力门 (AG),以专注于目标区域,同时抑制不相关区域的特征激活。
给定输入特征图 X X X和以粗略收集并包含上下文信息的门控信号 G ∈ R C ′ × H × W G \in \mathbb{R}^{C^{\prime} \times H \times W} G∈RC′×H×W,注意力门使用附加注意力来获得门控系数。输入 X X X和门控信号都首先线性映射到 R F × H × W \mathbb{R}^{F \times H \times W} RF×H×W维空间,然后在通道域中压缩输出以产生空间注意力权重图 S ∈ R 1 × H × W S \in \mathbb{R}^{1 \times H \times W} S∈R1×H×W。整个过程可以写成
S = σ ( φ ( δ ( ϕ x ( X ) + ϕ g ( G ) ) ) ) Y = S X \begin{aligned} S &=\sigma\left(\varphi\left(\delta\left(\phi_{x}(X)+\phi_{g}(G)\right)\right)\right) \\ Y &=S X \end{aligned} SY=σ(φ(δ(ϕx(X)+ϕg(G))))=SX
其中 φ , ϕ x \varphi, \phi_{x} φ,ϕx和 ϕ g \phi_{g} ϕg是实现为 1 × 1 1 \times 1 1×1卷积的线性变换。
注意力门将模型的注意力引导到重要区域,同时抑制不相关区域的特征激活。由于其轻量级设计,它大大增强了模型的表示能力,而不会显着增加计算成本或模型参数的数量。它是通用的和模块化的,使其易于在各种 CNN 模型中使用。
3.3.5 STN
平移等方差的特性使 CNN 适合处理图像数据。然而,CNN 缺乏其他变换不变性,例如旋转不变性、缩放不变性和翘曲不变性。为了在使 CNN 专注于重要区域的同时实现这些属性,Jaderberg 等人提出了空间变换网络(STN),它使用显式过程来学习对平移、缩放、旋转和其他更一般的扭曲的不变性,使网络受到关注到最相关的地区。 STN 是第一个明确预测重要区域并提供具有变换不变性的深度神经网络的注意力机制。
以 2D 图像为例,2D 仿射变换可以表述为:
[ θ 11 θ 12 θ 13 θ 21 θ 22 θ 23 ] = f l o c ( U ) ( x i s y i s ) = [ θ 11 θ 12 θ 13 θ 21 θ 22 θ 23 ] ( x i t y i t 1 ) \begin{aligned} {\left[\begin{array}{lll} \theta_{11} & \theta_{12} & \theta_{13} \\ \theta_{21} & \theta_{22} & \theta_{23} \end{array}\right] } &=f_{\mathrm{loc}}(U) \\ \left(\begin{array}{c} x_{i}^{s} \\ y_{i}^{s} \end{array}\right) &=\left[\begin{array}{lll} \theta_{11} & \theta_{12} & \theta_{13} \\ \theta_{21} & \theta_{22} & \theta_{23} \end{array}\right]\left(\begin{array}{c} x_{i}^{t} \\ y_{i}^{t} \\ 1 \end{array}\right) \end{aligned} [θ11θ21θ12θ22θ13θ23](xisyis)=floc(U)=[θ11θ21θ12θ22θ13θ23]⎝⎛xityit1⎠⎞
这里, U U U是输入特征图, f loc f_{\text {loc }} floc 可以是任何可微函数,例如轻量级的全连接网络或卷积神经网络。 x i s x_{i}^{s} xis和 y i s y_{i}^{s} yis是输出特征图中的坐标,而 x i t x_{i}^{t} xit和 y i t y_{i}^{t} yit是输入特征图中的对应坐标, θ \theta θ矩阵是可学习的仿射矩阵。获得对应关系后,网络可以使用对应关系对相关输入区域进行采样。为了保证整个过程是可微的并且可以以端到端的方式更新,使用双线性采样对输入特征进行采样。
STN 自动关注判别区域,并学习一些几何变换的不变性。
3.3.6 Deformable Convolutional Networks
出于与 STN 类似的目的,Dai 等人提出可变形卷积网络(deformable ConvNets)对几何变换保持不变,但他们以不同的方式关注重要区域。
具体来说,可变形卷积网络不学习仿射变换。他们将卷积分为两个步骤,首先从输入特征图中对规则网格 R \mathcal{R} R上的特征进行采样,然后使用卷积核通过加权求和来聚合采样的特征。过程可以写成:
Y ( p 0 ) = ∑ p i ∈ R w ( p i ) X ( p 0 + p i ) R = { ( − 1 , − 1 ) , ( − 1 , 0 ) , … , ( 1 , 1 ) } \begin{aligned} Y\left(p_{0}\right) &=\sum_{p_{i} \in \mathcal{R}} w\left(p_{i}\right) X\left(p_{0}+p_{i}\right) \\ \mathcal{R} &=\{(-1,-1),(-1,0), \ldots,(1,1)\} \end{aligned} Y(p0)R=pi∈R∑w(pi)X(p0+pi)={
(−1,−1),(−1,0),…,(1,1)}
可变形卷积通过引入一组可由轻量级 CNN 生成的可学习偏移量 Δ p i \Delta p_{i} Δpi来增强采样过程。使用偏移量 Δ p i \Delta p_{i} Δpi,可变形卷积可以表示为:
Y ( p 0 ) = ∑ p i ∈ R w ( p i ) X ( p 0 + p i + Δ p i ) . Y\left(p_{0}\right)=\sum_{p_{i} \in \mathcal{R}} w\left(p_{i}\right) X\left(p_{0}+p_{i}+\Delta p_{i}\right) . Y(p0)=pi∈R∑w(pi)X(p0+pi+Δpi).
通过上述方法,实现了自适应采样。然而, Δ p i \Delta p_{i} Δpi是一个不适合网格采样的浮点值。为了解决这个问题,使用了双线性插值。还使用了可变形 RoI 池化,大大改进了目标检测。
Deformable ConvNets 自适应选择重要区域,扩大卷积神经网络的有效感受野;这在目标检测和语义分割任务中很重要。
3.3.7 Self-attention and variants
自注意力被提出并在自然语言处理(NLP)领域取得了巨大成功。最近,它还显示出成为计算机视觉领域主导工具的潜力。通常,自注意力被用作一种空间注意力机制来捕获全局信息。现在总结一下自注意力机制及其在计算机视觉中的常见变体。
由于卷积运算的局部化,CNN 固有地具有狭窄的感受野,这限制了CNN全局理解场景的能力。为了增加感受野,Wang等人将自注意力引入计算机视觉。
以 2D 图像为例,给定一个特征图 F ∈ R C × H × W F \in \mathbb{R}^{C \times H \times W} F∈RC×H×W,self-attention 首先通过线性投影计算查询、键和值 Q , K , V ∈ R C ′ × N , N = H × W Q, K, V \in \mathbb{R}^{C^{\prime} \times N}, N=H \times W Q,K,V∈RC′×N,N=H×W和重塑操作。那么self-attention可以表述为:
A = ( a ) i , j = Softmax ( Q K T ) Y = A V \begin{aligned} A=(a)_{i, j} &=\operatorname{Softmax}\left(Q K^{T}\right) \\ Y &=A V \end{aligned} A=(a)i,jY=Softmax(QKT)=AV
其中 A ∈ R N × N A \in \mathbb{R}^{N \times N} A∈RN×N是注意力矩阵, α i , j \alpha_{i, j} αi,j是第 i i i个和第 j j j个元素之间的关系。整个过程如图7(左)所示。自注意力是一种强大的全局信息建模工具,在许多视觉任务中很有用。
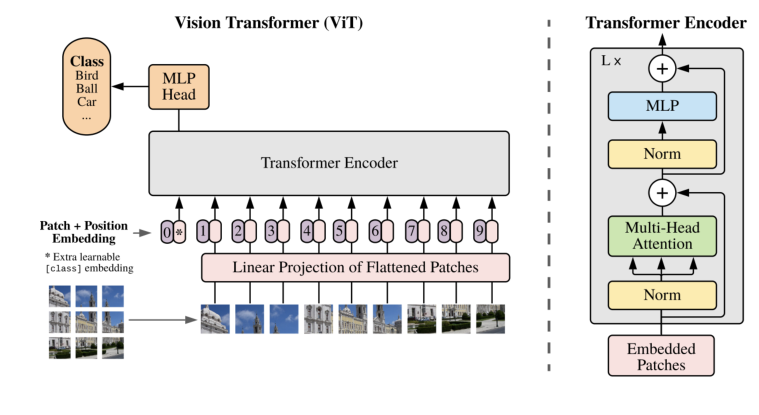
图 7. 视觉Transformer。左:架构。视觉Transformer首先将图像分割成不同的块并将它们投影到特征空间中,在特征空间中,Transformer编码器对其进行处理以产生最终结果。右图:具有多头注意力核心的基本视觉Transformer模块。
然而,自注意力机制有几个缺点,特别是它的二次复杂性,这限制了它的适用性。已经引入了几种变体来缓解这些问题。分解的非局部方法提高了自注意力的准确性和有效性,但大多数变体都专注于降低其计算复杂性。
CCNet将self-attention操作看作图卷积,将self-attention处理的密集连接图替换为几个稀疏连接图。为此,它提出了交叉注意力,它反复考虑行注意力和列注意力以获取全局信息。 CCNet 将 self-attention 的复杂度从 O ( N 2 ) O\left(N^{2}\right) O(N2)降低到 O ( N N ) O(N \sqrt{N}) O(NN)。
EMANet根据期望最大化(EM)来看待自注意力。提出了EM attention,采用EM算法得到一组紧凑的基,而不是使用所有的点作为重构基。这将复杂度从 O ( N 2 ) O\left(N^{2}\right) O(N2)降低到 O ( N K ) O(N K) O(NK),其中 K K K是紧凑基的数量。
ANN提出使用所有位置特征作为键和向量是冗余的,并采用空间金字塔池化来获得一些具有代表性的键和值特征来代替,以减少计算量。
GCNet分析了selfattention中使用的attention map,发现selfattention得到的全局上下文对于同一图像中的不同查询位置是相似的。因此,它首先提出预测所有查询点共享的单个注意力图,然后根据该注意力图从输入特征的加权和中获取全局信息。这类似于平均池化,但它是一个更通用的收集全局信息的过程。
A 2 A^{2} A2受到 SENet 的启发,使用两种不同的注意力将注意力分为特征收集和特征分布过程。第一个通过二阶注意力池化聚合全局信息,第二个通过软选择注意力分布全局描述符。
GloRe从图学习的角度理解自注意力。它首先将 N N N个输入特征收集到 M ≪ N M \ll N M≪N个节点中,然后学习节点之间全局交互的邻接矩阵。最后,节点将全局信息分配给输入特征。在LatentGNN、MLP-Mixer和ResMLP中可以找到类似的想法。
OCRNet提出了目标上下文表示的概念,它是同一类别中所有目标区域表示的加权聚合,例如所有汽车区域表示的加权平均。它用这种目标上下文表示替换了键和向量,从而成功地提高了速度和有效性。
Yin等人深入分析了self-attention机制,产生了将self-attention解耦为pairwise term和unary term的核心思想。成对项侧重于建模关系,而一元项侧重于显着边界。这种分解防止了两个术语之间不必要的交互,极大地改进了语义分割、目标检测和动作识别。
HamNet模型将全局关系捕获为低秩完成问题,并设计了一系列白盒方法来使用矩阵分解捕获全局上下文。这不仅降低了复杂性,而且增加了 self-attention 的可解释性。
EANet提出,self-attention 应该只考虑单个样本中的相关性,而应该忽略不同样本之间的潜在关系。为了探索不同样本之间的相关性并减少计算量,它利用了采用可学习、轻量级和共享键值向量的外部注意力。它进一步表明,使用 softmax 对注意力图进行归一化并不是最优的,并提出双重归一化作为更好的选择。
除了作为 CNN 的补充方法之外,self-attention 还可以用来代替卷积操作来聚合邻域信息。卷积运算可以表示为输入特征 X X X和卷积核 W W W之间的点积:
Y i , j c = ∑ a , b ∈ { 0 , … , k − 1 } W a , b , c X a ^ , b ^ Y_{i, j}^{c}=\sum_{a, b \in\{0, \ldots, k-1\}} W_{a, b, c} X_{\hat{a}, \hat{b}} Yi,jc=a,b∈{
0,…,k−1}∑Wa,b,cXa^,b^
其中
a ^ = i + a − ⌊ k / 2 ⌋ , b ^ = j + b − ⌊ k / 2 ⌋ , \hat{a}=i+a-\lfloor k / 2\rfloor, \quad \hat{b}=j+b-\lfloor k / 2\rfloor, a^=i+a−⌊k/2⌋,b^=j+b−⌊k/2⌋,
k k k是内核大小, c c c表示通道。上述公式可以看作是通过卷积核使用加权和聚合邻域信息的过程。聚合邻域信息的过程可以更一般地定义为:
Y i , j = ∑ a , b ∈ { 0 , … , k − 1 } Rel ( i , j , a ^ , b ^ ) f ( X a ^ , b ^ ) Y_{i, j}=\sum_{a, b \in\{0, \ldots, k-1\}} \operatorname{Rel}(i, j, \hat{a}, \hat{b}) f\left(X_{\hat{a}, \hat{b}}\right) Yi,j=a,b∈{
0,…,k−1}∑Rel(i,j,a^,b^)f(Xa^,b^)
其中 Rel ( i , j , a ^ , b ^ ) \operatorname{Rel}(i, j, \hat{a}, \hat{b}) Rel(i,j,a^,b^)是位置(i,j)和位置 ( a ^ , b ^ ) (\hat{a}, \hat{b}) (a^,b^)之间的关系。有了这个定义,局部自注意力是一个特例。
例如,SASA将其写为
Y i , j = ∑ a , b ∈ N k ( i , j ) Softmax a b ( q i j T k a b + q i j r a − i , b − j ) v a b Y_{i, j}=\sum_{a, b \in \mathcal{N}_{k}(i, j)} \operatorname{Softmax}_{a b}\left(q_{i j}^{T} k_{a b}+q_{i j} r_{a-i, b-j}\right) v_{a b} Yi,j=a,b∈Nk(i,j)∑Softmaxab(qijTkab+qijra−i,b−j)vab
其中 q , k q, k q,k和 v v v是输入特征 x x x的线性投影, r a − i , b − j r_{a-i, b-j} ra−i,b−j是 ( i , j ) (i, j) (i,j)和 ( a , b ) (a, b) (a,b)的相对位置嵌入。
现在考虑使用局部自注意力作为基本神经网络块的几个具体工作
SASA提出使用自注意力来收集全局信息的计算量太大,而是采用局部自注意力来代替 CNN 中的所有空间卷积。作者表明,这样做可以提高速度、参数数量和结果质量。他们还探索了位置嵌入的行为,并表明相对位置嵌入是合适的。他们的工作还研究了如何将局部自注意力与卷积结合起来。
LR-Net与SASA同时出现。它还研究了如何使用局部自注意力对局部关系进行建模。一项综合研究探讨了位置嵌入、内核大小、外观可组合性和对抗性攻击的影响。
SAN探索了两种利用注意力进行局部特征聚合的模式,成对和切片。它提出了一种新的内容和通道自适应的向量注意,并从理论和实践上评估了它的有效性。除了在图像域中提供显著改进外,它还被证明在3D点云处理中很有用。
3.3.8 Vision T ransformers
Transformers 在自然语言处理方面取得了巨大成功。最近,iGPT和DETR展示了基于Transformer的模型在计算机视觉中的巨大潜力。受此启发,Dosovitskiy 等人提出了视觉Transformer(ViT),这是第一个用于图像处理的纯Transformer架构。它能够达到与现代卷积神经网络相当的结果。
如图 7 所示,ViT 的主要部分是多头注意力(MHA)模块。 MHA 将序列作为输入。它首先将一个类标记与输入特征 F ∈ R N × C F \in \mathcal{R}^{N \times C} F∈RN×C连接起来,其中 N N N是像素数。然后通过线性投影得到 Q , K ∈ R N × C ′ Q, K \in \mathcal{R}^{N \times C^{\prime}} Q,K∈RN×C′和 V ∈ R N × C V \in \mathcal{R}^{N \times C} V∈RN×C。接下来, Q , K Q, K Q,K和 V V V在通道域中被划分为 H 个头,并分别对其应用自注意力。 MHA 方法如图 8 所示。ViT 将许多 MHA 层与全连接层、层归一化和GELU激活函数堆叠在一起。

图 8. 左:自注意力。右图:多头自注意力。
ViT 证明纯基于注意力的网络可以比卷积神经网络获得更好的结果,尤其是对于大型数据集,如 JFT-300和ImageNet-21K。
在 ViT 之后,许多基于Transformer的架构,在包括图像在内的多种视觉任务中取得了优异的成绩分类、目标检测、语义分割、点云处理、动作识别和自监督学习。
3.3.9 GENet
受 SENet 启发,Hu 等人设计 GENet 通过在空间域中提供重新校准功能来捕获远程空间上下文信息。
GENet 结合了部分收集和激发操作。第一步,它聚合大邻域的输入特征,并对不同空间位置之间的关系进行建模。在第二步中,它首先使用插值生成与输入特征图大小相同的注意力图。然后通过乘以注意力图中的相应元素来缩放输入特征图中的每个位置。这个过程可以描述为:
g = f gather ( X ) s = f excite ( g ) = σ ( Interp ( g ) ) Y = s X \begin{aligned} g &=f_{\text {gather }}(X) \\ s &=f_{\text {excite }}(g)=\sigma(\operatorname{Interp}(g)) \\ Y &=s X \end{aligned} gsY=fgather (X)=fexcite (g)=σ(Interp(g))=sX
在这里, f gather f_{\text {gather}} fgather可以采用任何捕捉空间相关性的形式,例如全局平均池化或一系列深度卷积;Interp ( ⋅ ) (\cdot) (⋅)表示插值。
Gather-excite 模块是轻量级的,可以像 SE 块一样插入到每个残差单元中。它在抑制噪音的同时强调重要特征。
3.3.10 PSANet
受成功捕获卷积神经网络中的远程依赖关系的启发,Zhao 等人提出了新的 PSANet 框架来聚合全局信息。它将信息聚合建模为信息流,并提出双向信息传播机制,使信息在全局范围内流动。
PSANet 将信息聚合公式化为:
z i = ∑ j ∈ Ω ( i ) F ( x i , x j , Δ i j ) x j ( 55 ) z_{i}=\sum_{j \in \Omega(i)} F\left(x_{i}, x_{j}, \Delta_{i j}\right) x_{j}\quad(55) zi=j∈Ω(i)∑F(xi,xj,Δij)xj(55)
其中 Δ i j \Delta_{i j} Δij表示 i i i and j j j之间的位置关系。 F ( x i , x j , Δ i j ) F\left(x_{i}, x_{j}, \Delta_{i j}\right) F(xi,xj,Δij)是一个考虑 x i , x j x_{i}, x_{j} xi,xj和 Δ i j \Delta_{i j} Δij来控制从 j j j到 i i i的信息流的函数。 Ω i \Omega_{i} Ωi表示位置 i i i的聚合邻域;如果希望捕获全局信息, Ω i \Omega_{i} Ωi应该包括所有空间位置。
由于计算函数 F ( x i , x j , Δ i j ) F\left(x_{i}, x_{j}, \Delta_{i j}\right) F(xi,xj,Δij)的复杂性,将其分解为一个近似值:
F ( x i , x j , Δ i j ) ≈ F Δ i j ( x i ) + F Δ i j ( x j ) F\left(x_{i}, x_{j}, \Delta_{i j}\right) \approx F_{\Delta_{i j}}\left(x_{i}\right)+F_{\Delta_{i j}}\left(x_{j}\right) F(xi,xj,Δij)≈FΔij(xi)+FΔij(xj)
于是公式55可以简化为:
z i = ∑ j ∈ Ω ( i ) F Δ i j ( x i ) x j + ∑ j ∈ Ω ( i ) F Δ i j ( x j ) x j z_{i}=\sum_{j \in \Omega(i)} F_{\Delta_{i j}}\left(x_{i}\right) x_{j}+\sum_{j \in \Omega(i)} F_{\Delta_{i j}}\left(x_{j}\right) x_{j} zi=j∈Ω(i)∑FΔij(xi)xj+j∈Ω(i)∑FΔij(xj)xj
第一项可以看作是在位置 i i i收集信息,而第二项在位置 j j j分布信息。函数 F Δ i j ( x i ) F_{\Delta_{i j}}\left(x_{i}\right) FΔij(xi)和 F Δ i j ( x j ) F_{\Delta_{i j}}\left(x_{j}\right) FΔij(xj)可以看作是自适应注意力权重。
上述过程在强调相关特征的同时聚合了全局信息。它可以添加到卷积神经网络的末端,作为有效的补充,大大提高语义分割。
参考文献
[15] X. Wang, R. Girshick, A. Gupta, and K. He, “Non-local neural networks,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), June 2018.
[31] V . Mnih, N. Heess, A. Graves, and K. Kavukcuoglu, “Recurrent models of visual attention,” 2014.
[32] M. Jaderberg, K. Simonyan, A. Zisserman, and K. Kavukcuoglu, “Spatial transformer networks,” 2016.
[61] J. Hu, L. Shen, S. Albanie, G. Sun, and A. V edaldi, “Gather-excite: Exploiting feature context in convolutional neural networks,” 2019.