本专栏用于自学笔记的记录,如有不当,请谅解,喷子请绕道。
机器学习使计算机系统能够自动学习而无需明确编程。但是机器学习系统是如何工作的呢?所以,可以用机器学习的生命周期来描述。机器学习生命周期是构建高效机器学习项目的循环过程。生命周期的主要目的是找到问题或项目的解决方案。
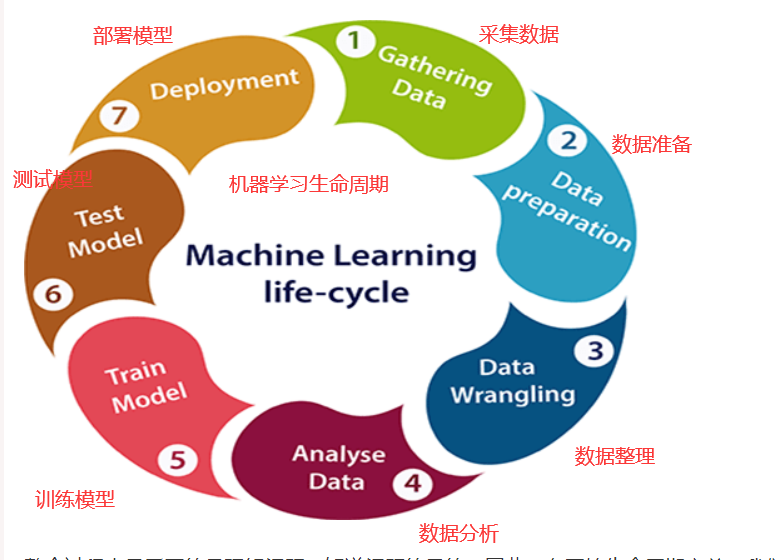
机器学习生命周期涉及七个主要步骤,如下所示:
- 采集数据(爬取)
- 数据准备(对采集到的数据
- 数据整理(包括:清洗)
- 分析数据
- 训练模型
- 测试模型
- 部署模型
下面对每一个步骤进行具体说明。
一、采集数据
数据收集是机器学习生命周期的第一步。此步骤的目标是识别和获取所有与数据相关的问题。(这一步一般是爬虫工程师来完成)
在这一步中,我们需要识别不同的数据源,因为数据可以从各种来源收集,例如文件、数据库、互联网或移动设备。这是生命周期中最重要的步骤之一。所收集数据的数量和质量将决定输出的效率。数据越多,预测就越准确。所以不要小瞧爬虫工程师,他们有着很大的作用。
此步骤包括以下任务:
- 收集各种数据源
- 收集数据
- 整合从不同来源获得的数据
通过执行上述任务,我们得到了一组连贯的数据,也称为数据集。它将在进一步的步骤中使用。
二、数据准备
收集数据后,我们需要为进一步的步骤做准备。数据准备是我们将数据放入合适的位置并准备将其用于机器学习训练的步骤。在这一步中,我们首先将所有数据放在一起,然后随机排列数据。
这一步可以进一步分为两个过程:
- 数据探索(它用于了解我们必须使用的数据的性质。我们需要了解数据的特征、格式和质量。更好地理解数据会带来有效的结果。在此,我们发现相关性、总体趋势和异常值。)
- 数据预处理(现在下一步是对数据进行预处理以进行分析。)
三、数据整理
数据整理是清理原始数据并将其转换为可用格式的过程。它是对数据进行清理、选择要使用的变量并将数据转换为适当格式以使其更适合下一步分析的过程。这是整个过程中最重要的步骤之一。需要对数据进行清理以解决质量问题。
我们收集的数据不一定总是供我们使用,因为某些数据可能没有用。在实际应用中,收集的数据可能存在各种问题,包括:
- 缺失值
- 重复数据
- 无效数据
- 噪音
这一步我认为依然归爬虫工程师来完成,自己找的数据自己处理。我们使用各种过滤技术来清理数据,必须检测并消除上述问题,因为它会对结果的质量产生负面影响。
四、 数据分析
现在,清理和准备好的数据被传递到分析步骤。此步骤涉及:
- 各种算法
- 建立模型
- 评估模型
此步骤的目的是建立一个机器学习模型,以使用各种分析技术分析数据并查看结果。它从确定问题的类型开始,我们选择分类、回归、聚类分析、关联等机器学习技术,然后使用准备好的数据建立模型,并对模型进行评估。
因此,在这一步中,我们获取数据并使用机器学习算法来建立模型。这开始就需要AI部门来完成。
五、 训练模型
现在下一步是训练模型,在这一步中,我们训练我们的模型以提高其性能以获得更好的问题结果。
我们使用数据集使用各种机器学习算法来训练模型。需要训练模型,以便它能够理解各种模式、规则和特征。这一步其实跟上一步很像。
六、测试模型
一旦我们的机器学习模型在给定的数据集上进行了训练,我们就可以测试该模型。在这一步中,我们通过向模型提供测试数据集来检查模型的准确性。
测试模型根据项目或问题的要求确定模型的百分比准确度。
七、部署模型
机器学习生命周期的最后一步是部署,我们将模型部署到现实世界的系统中。
如果上面准备的模型按照我们的要求以可接受的速度产生准确的结果,那么我们将模型部署到实际系统中。但在部署项目之前,我们将检查它是否正在使用可用数据提高其性能。部署阶段类似于为项目制作最终成果。
机器学习环境搭建(拓展)
学习机器学习,我们一般使用Jupyter,而不是pycharm,Jupyter安装请参考文章:jupyter安装
如果你Python基础不好,可以系统学习一下python基础,可以参考我的基础专栏,如果需要免费的刷题网站,可以使用网站:牛客