学习来源:日撸 Java 三百行(51-60天,kNN 与 NB)_闵帆的博客-CSDN博客
kNN 分类器
一、算法概述
KNN 可以说是最简单的分类算法之一, 同时, 它也是最常用的分类算法之一. 注意 KNN 算法是有监督学习中的分类算法, 它看起来和另一个机器学习算法 Kmeans 有点像( Kmeans 是无监督学习算法), 但却是有本质区别的.
二、算法介绍
KNN 的全称是K Nearest Neighbors, 意思是 K 个最近的邻居, 从这个名字我们就能看出一些 KNN 算法的蛛丝马迹了. K 个最近邻居, 毫无疑问, K的取值肯定是至关重要的.那么最近的邻居又是怎么回事? 其实, KNN 的原理就是当预测一个新的值 x 的时候, 根据它距离最近的 K 个点是什么类别来判断 x 属于哪个类别.
1. 距离计算
有两种距离计算方式, 一种是欧式距离, 另一种是曼哈顿距离. 在本文中因为只使用了欧式距离那么我就在这个地方阐述一下. 这个式子其实就是之前求二维或者三维坐标系下两点距离的公式, 我们把这个公式推广到 n 维.
d i s t a n c e ( x , y ) = ( x 1 − y 1 ) 2 + ( x 2 − y 2 ) 2 + . . . + ( x n − y n ) 2 n distance(x,y) = \sqrt[n]{ {(x_1-y_1)}^{2} + {(x_2-y_2)}^{2} + ... +{(x_n-y_n)}^{2} } distance(x,y)=n(x1−y1)2+(x2−y2)2+...+(xn−yn)2
2. K值选择
在示例代码中我将 K 值默认为 7. 当然这不是一个固定的, K 值得选择还需要通过后期不断实验对比才能够最终确定.
三、KNN特点
KNN 是一种非参的, 惰性的算法模型. 什么是非参, 什么是惰性呢?
非参的意思并不是说这个算法不需要参数, 而是意味着这个模型不会对数据做出任何的假设, 与之相对的是线性回归(我们总会假设线性回归是一条直线).
也就是说 KNN 建立的模型结构是根据数据来决定的, 这也比较符合现实的情况, 毕竟在现实中的情况往往与理论上的假设是不相符的.
惰性又是什么意思呢?
想想看, 同样是分类算法, 逻辑回归需要先对数据进行大量训练(tranning), 最后才会得到一个算法模型. 而 KNN 算法却不需要, 它没有明确的训练数据的过程, 或者说这个过程很快.
四、代码分析
1. 流程
Step 1: 从特定文件 iris.arff 读入数据存放在一个特定的数据结构中, 我将它命名为 dataset.
Step 2: 获得一个混淆后的整数数组, 其中存放的是下标, 这个下标指的是数据在 dataset 里的下标.
Step 3: 将这个数组按照传入的参数分为两部分, 一部分做为训练集, 另一部分做为测试集. 至此数据处理的工作完成. 接下来就是预测的过程.
Step 4: 需要预测的个数和测试集中的个数是相同的, 因为在最后要两者对比来判断预测率. 在此对每一个点进行预测.
Step 4.1: 预测的过程很简单, 就是计算训练集中每个点到该点的欧式距离然后选择代码中定义的前 K 个点.
Step 4.2: 有了离该点最近的 K 个点, 接下来就进行 “投票” 的操作来对这个点进行分类. 先对那取得的 K 个点统计每个类别有多少个数. 然后选出个数最高的那个类别, 返回其在 dataset 中的下标. 至此对该点的预测完毕.
Step 5: 计算预测精度. 计算测试集和预测集有多少个值是相等的, 然后用这个值除以测试集或者预测集的总数, 这样就获得了预测精度.
2. 完整代码
package knn;
import java.io.FileReader;
import java.util.Arrays;
import java.util.Random;
import weka.core.*;
/**
* kNN classification.
*
* @author Shihuai Wen Email: [email protected].
*/
public class KnnClassification {
/**
* Manhattan distance.
*/
public static final int MANHATTAN = 0;
/**
* Euclidean distance.
*/
public static final int EUCLIDEAN = 1;
/**
* The distance measure.
*/
public int distanceMeasure = EUCLIDEAN;
/**
* A random instance;
*/
public static final Random random = new Random();
/**
* The number of neighbors.
*/
int numNeighbors = 7;
/**
* The whole dataset.
*/
Instances dataset;
/**
* The training set. Represented by the indices of the data.
*/
int[] trainingSet;
/**
* The testing set. Represented by the indices of the data.
*/
int[] testingSet;
/**
* The predictions.
*/
int[] predictions;
/**
* ********************
* The first constructor.
*
* @param paraFilename The arff filename.
* ********************
*/
public KnnClassification(String paraFilename) {
try {
FileReader fileReader = new FileReader(paraFilename);
dataset = new Instances(fileReader);
// The last attribute is the decision class.
dataset.setClassIndex(dataset.numAttributes() - 1);
fileReader.close();
} catch (Exception ee) {
System.out.println("Error occurred while trying to read ' " + paraFilename
+ " ' in KnnClassification constructor.\r\n" + ee);
System.exit(0);
} // Of try
}// Of the first constructor
/**
* ********************
* Get a random indices for data randomization.
*
* @param paraLength The length of the sequence.
* @return An array of indices, e.g., {4, 3, 1, 5, 0, 2} with length 6.
* ********************
*/
public static int[] getRandomIndices(int paraLength) {
int[] resultIndices = new int[paraLength];
// Step 1. Initialize.
for (int i = 0; i < paraLength; i++) {
resultIndices[i] = i;
} // Of for i
// Step 2. Randomly swap.
int tempFirst, tempSecond, tempValue;
for (int i = 0; i < paraLength; i++) {
// Generate two random indices.
tempFirst = random.nextInt(paraLength);
tempSecond = random.nextInt(paraLength);
// Swap.
tempValue = resultIndices[tempFirst];
resultIndices[tempFirst] = resultIndices[tempSecond];
resultIndices[tempSecond] = tempValue;
} // Of for i
return resultIndices;
}// Of getRandomIndices
/**
* ********************
* Split the data into training and testing parts.
*
* @param paraTrainingFraction The fraction of the training set.
* ********************
*/
public void splitTrainingTesting(double paraTrainingFraction) {
int tempSize = dataset.numInstances();
int[] tempIndices = getRandomIndices(tempSize);
int tempTrainingSize = (int) (tempSize * paraTrainingFraction);
trainingSet = new int[tempTrainingSize];
testingSet = new int[tempSize - tempTrainingSize];
System.arraycopy(tempIndices, 0, trainingSet, 0, tempTrainingSize);
if (tempSize - tempTrainingSize >= 0) {
System.arraycopy(tempIndices, tempTrainingSize, testingSet, 0, tempSize - tempTrainingSize);
} // Of for if
}// Of splitTrainingTesting
/**
* ********************
* Predict for the whole testing set. The results are stored in predictions.
* #see predictions.
* ********************
*/
public void predict() {
predictions = new int[testingSet.length];
for (int i = 0; i < predictions.length; i++) {
predictions[i] = predict(testingSet[i]);
} // Of for i
}// Of predict
/**
* ********************
* Predict for given instance.
*
* @return The prediction.
* ********************
*/
public int predict(int paraIndex) {
int[] tempNeighbors = computeNearests(paraIndex);
int resultPrediction;
resultPrediction = simpleVoting(tempNeighbors);
return resultPrediction;
}// Of predict
/**
* ********************
* The distance between two instances.
*
* @param paraI The index of the first instance.
* @param paraJ The index of the second instance.
* @return The distance.
* ********************
*/
public double distance(int paraI, int paraJ) {
double resultDistance = 0;
double tempDifference;
switch (distanceMeasure) {
case MANHATTAN:
for (int i = 0; i < dataset.numAttributes() - 1; i++) {
tempDifference = dataset.instance(paraI).value(i) - dataset.instance(paraJ).value(i);
if (tempDifference < 0) {
resultDistance -= tempDifference;
} else {
resultDistance += tempDifference;
} // Of if
} // Of for i
break;
case EUCLIDEAN:
for (int i = 0; i < dataset.numAttributes() - 1; i++) {
tempDifference = dataset.instance(paraI).value(i) - dataset.instance(paraJ).value(i);
resultDistance += tempDifference * tempDifference;
} // Of for i
break;
default:
System.out.println("Unsupported distance measure: " + distanceMeasure);
}// Of switch
return resultDistance;
}// Of distance
/**
* ********************
* Get the accuracy of the classifier.
*
* @return The accuracy.
* ********************
*/
public double getAccuracy() {
// A double divides an int gets another double.
double tempCorrect = 0;
for (int i = 0; i < predictions.length; i++) {
if (predictions[i] == dataset.instance(testingSet[i]).classValue()) {
tempCorrect++;
} // Of if
} // Of for i
return tempCorrect / testingSet.length;
}// Of getAccuracy
/**
* ***********************************
* Compute the nearest k neighbors. Select one neighbor in each scan. In
* fact, we can scan only once. You may implement it by yourself.
*
* @param paraCurrent current instance. We are comparing it with all others.
* @return the indices of the nearest instances.
* ***********************************
*/
public int[] computeNearests(int paraCurrent) {
int[] resultNearests = new int[numNeighbors];
boolean[] tempSelected = new boolean[trainingSet.length];
double tempMinimalDistance;
int tempMinimalIndex = 0;
// Compute all distances to avoid redundant computation.
double[] tempDistances = new double[trainingSet.length];
for (int i = 0; i < trainingSet.length; i++) {
tempDistances[i] = distance(paraCurrent, trainingSet[i]);
}//Of for i
// Select the nearest paraK indices.
for (int i = 0; i < numNeighbors; i++) {
tempMinimalDistance = Double.MAX_VALUE;
for (int j = 0; j < trainingSet.length; j++) {
if (tempSelected[j]) {
continue;
} // Of if
if (tempDistances[j] < tempMinimalDistance) {
tempMinimalDistance = tempDistances[j];
tempMinimalIndex = j;
} // Of if
} // Of for j
resultNearests[i] = trainingSet[tempMinimalIndex];
tempSelected[tempMinimalIndex] = true;
} // Of for i
System.out.println("The nearest of " + paraCurrent + " are: " + Arrays.toString(resultNearests));
return resultNearests;
}// Of computeNearests
/**
* ***********************************
* Voting using the instances.
*
* @param paraNeighbors The indices of the neighbors.
* @return The predicted label.
* ***********************************
*/
public int simpleVoting(int[] paraNeighbors) {
int[] tempVotes = new int[dataset.numClasses()];
for (int paraNeighbor : paraNeighbors) {
tempVotes[(int) dataset.instance(paraNeighbor).classValue()]++;
} // Of for i
int tempMaximalVotingIndex = 0;
int tempMaximalVoting = 0;
for (int i = 0; i < dataset.numClasses(); i++) {
if (tempVotes[i] > tempMaximalVoting) {
tempMaximalVoting = tempVotes[i];
tempMaximalVotingIndex = i;
} // Of if
} // Of for i
return tempMaximalVotingIndex;
}// Of simpleVoting
/**
* ********************
* The entrance of the program.
*
* @param args Not used now.
* ********************
*/
public static void main(String[] args) {
KnnClassification tempClassifier = new KnnClassification("D:/Work/sampledata/iris.arff");
tempClassifier.splitTrainingTesting(0.8);
tempClassifier.predict();
System.out.println("The accuracy of the classifier is: " + tempClassifier.getAccuracy());
}// Of main
}// Of class KnnClassification
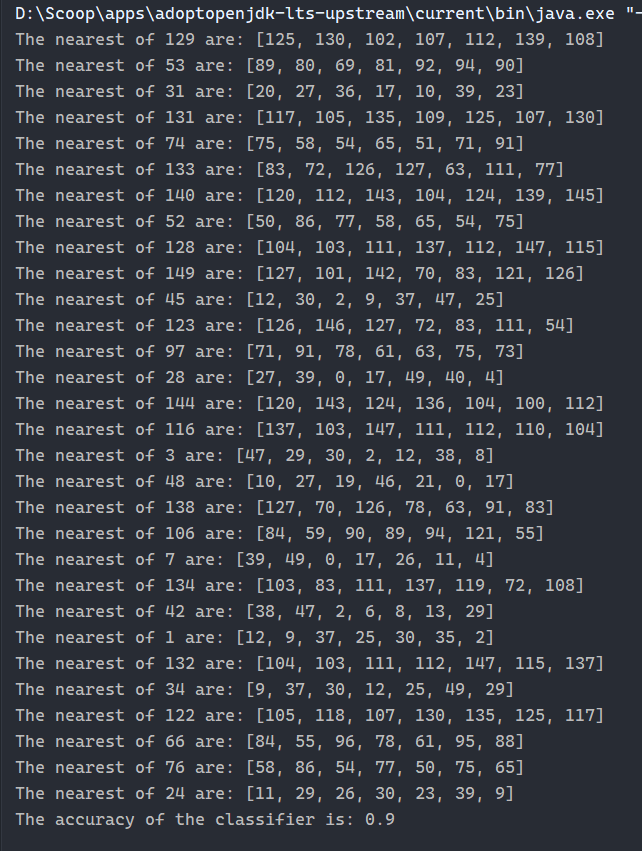
3. 运行截图
注: 为了方便调试和阅读代码我将 IDE 从 Eclipse 切换到了 IDEA.
总结
优点:
-
简单易用, 相比其他算法, KNN 算是比较简洁明了的算法. 即使没有很高的数学基础也能搞清楚它的原理.
-
模型训练时间快, 上面说到 KNN 算法是惰性的, 这里也就不再过多讲述.
-
预测效果好.
-
对异常值不敏感
缺点:
-
对内存要求较高, 因为该算法存储了所有训练数据
-
预测阶段可能很慢
-
对不相关的功能和数据规模敏感