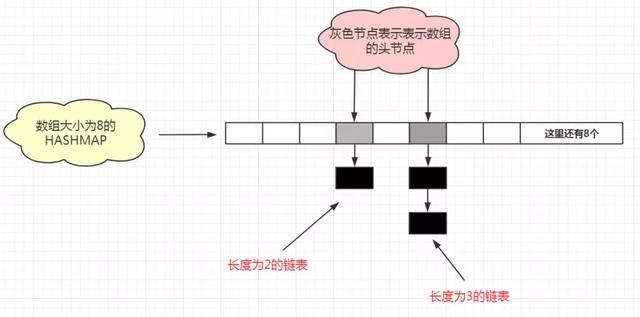
HashMap的实现原理图
本文所有内容皆围绕着HashMap1.7进行讲解。可能后续会省略1.7的版本号,望读者知晓。
在JDK1.7中,HASHMAP是由数组+链表实现的,原理图如下:
HashMap的设计初衷
在详细讲解HashMap之前,我依旧认为,要想彻底理解一种数据结构,必须要从它的存在意义的角度开始理解。它为什么产生,与它的产生带来了怎样的意义。因此,我们现在假设自己穿越了时空,回到那个还没有HashMap的时代。
假设,我们现在需要实现一个key-value键值对这种数据结构的集合,方便我们可以通过key去访问value。那么我们有那种方式去实现呢?
若以数组的形式实现
最简单易想的就是数组了。我们把每一个key,value都存在一个数组的槽位中。大家的第一反应肯定是,对啊,这个数组就能实现啊。但我们只是站在了获取元素方便的角度。当我们要存储元素的时候,麻烦接踵而至。
存储一组数据最快的数据结构便是数组,这也是数组仅存的优点, 同样数组的缺陷也很明显, 比如 需要大量的连续的内存空间, 对元素的插入操作代价高昂,不能随意地扩大容量....等等。
再说获取元素的效率问题。最常见的方式便是对 key 进行线性的 equals 查询, 从头查到尾, 这样的查询速度如此低下, 效率可想而知,
还有一个缺陷便就是数组与生俱来的, 需要太大的连续的内存空间, 所以通过数组来维持 HashMap 内部的数据缺陷太大,不值得。
经过简单的分析,发现数组可以实现我们的需求,然而缺点也相当得多
若以链表的形式实现
线性链表中的线性指的是链表中各个结点是线性存在的,而非存储空间,因此链表的节点都不需要是连续的存储空间,节点是通过指针连接的。因此链表似乎是解决了数组一个最致命的缺陷(需要大量的连续的内存空间), 但是链表仍然无法解决当我们用一个 key 去查询一个 value 的时候的低下的效率, 原因仍然是从头到尾的线性遍历。
Hash的诞生,为速度而散列
在上面我们说到用数组或者链表来维护内部的 键-值 对似乎效率都很低下,有没有一种能够结合数组和链表两者各自的优点然后又有着高效的查询速度的数据结构呢?
这便是 HashMap 内部维护数据的方式 --- 数组链表+散列机制
散列的价值便在于速度, 散列使得查询得以快速进行, 那么什么是数组链表,什么又是散列机制呢?
正所谓数组链表, 便是定义一个数组, 然后数组的每一个成员都是一条链表,数组只需要记载这条链表的引用即可, 这样不需要直接在数组内部存储 键-值 对而需要大量的连续的内存空间.
散列机制便是所谓的 hashCode 方法返回的 int 数, 他是通过对象的信息(默认是地址),通过某种散列的数学函数生成的一串 int 数字.
在经过数组和链表的各取所长后,我们的HashMap也随之诞生。
HashMap的延迟初始化
回忆我们HashMap的使用方式:
HashMap map = new HashMap(); // 伪初始化 map.put("键","值"); // 真初始化我们的常规思路是,在执行HashMap map = new HashMap();这一行代码时,数组也会初始化完毕。但实际上却并非如此。
HashMap的构造法方法在执行时会初始化一个数组table,大小为0。
HashMap的put方法在执行时,首先会判断table的大小是否为0.如果为0,则会进行真正的初始化,也被称为延迟加载。
当进行真正初始化时,数组的默认大小为16。当然也可以调用HASHMAP的有参构造,自己DIY一个数组的初始化容量。但是注意,这里的容量并不是你写多少就是多少的。
HashMap的数组生成长度可以随便指定么?
比如,我们现在想让数组的初始化容量为6,那么HASHMAP会生成一个大小为8的数组。如果我么初始化容量为20,那么HASHMAP会生成一个大小为32的数组。
诶?这好像有什么规律可寻。
没错,当你想初始化一个容量为n的数组,那么HASHMAP会自动帮你生成一个大小大于等于2的次幂的数组。至于为啥会这样呢?我们待会儿再解释。
HashMap中的数组下标如何生成
对于put方法,当无需对table进行初始化或已经初始化完了之后,它接下来的主要任务是将key和value存到数组或者链表中。那么,具体是如何将key和value存到数组中的呢?
刚才我们已经讲述了Hash算法,就是经过散列,将原本大于这个数组长度的元素存储在HashMap中。那么元素的存储逻辑必然不会像数组一样挨个往后存储就行了。那么put操作时,想往数组中存入数据,首先我们需要先获得数组下标。而我们在进行put操作的时候是不需要传这个下标的。那么下标是从哪儿来的呢?
答案是hash算法。HashMap中的key会通过Hash算法自动生成数组的下标。因此,数组的下标就与我们的key值息息相关了。这也是为什么它叫HashMap而不叫Map的原因了。
Hash冲突
对于Hash算法,了解过的人都知道他需要一个哈希函数。这个函数接受一个参数,返回一个HashCode值。在我们的HashMap中正是对key作为了这个参数。
哈希函数的特点是对于相同的参数,那么返回的HashCode肯定是相同的。对于不相同的参数,函数会尽可能地去返回不相同的HashCode。所以,换一个角度理解,我们要把大于数组长度的元素放入到这个数组中,必然会有下标重复的元素。这些key不相同,但却计算出了相同HashCode的现象,就被称为哈希冲突或哈希碰撞。
那么,假设我们现在不知道是对key值做的hash运算。有没有办法验证我们到底是对key做哈希运?算还是value做哈希运算?还是对key和value一起做哈希运算的呢?
从get方法验证hash的对象(key)
回忆我们HashMap的get方法,我们只需要传一个key作为参数,就可以获取到对应的value。这也再次印证了我们是根据key进行了哈希运算,快速地得到了数组下标,从而找到了key对应的value。所以对于put方法,虽然传入了两个参数,但是只能对key进行哈希运算得到数组下标,这样才能方便get方法快速查找。
hashcode能直接作为下标么?
HashCode通常是一个比较大的数字,比如
System.out.println("键".hashCode()); // 38190// 为什么是这个结果,大家自行去看String类中的hashCode方法我们的数组初始时只有16位,也就是下标仅仅支持0~15。我们如何把这么大的数压缩到0~15之内呢?
大家通常可能能想到的即时取模运算。但是HashMap并没有取模,而是:
static int indexFor(int h, int length) {// assert Integer.bitCount(length) == 1 : "length must be a non-zero power of 2";return h & (length-1);}这个方法就是JDK1.7中的HashMap的put方法0和get方法中获取数组下标的方法。这个方法中的h代表hashcode,length代表数组长度。我们发现它用的是逻辑与操作。那么问题来了。逻辑与操作能准确地把那么大的数字变为0~15么?
我们来算算,加入hashcode是01010101(二进制表示),length为00010000(16的二进制表示)。那么h&(length-1)则为:
h: 0101 010115: 0000 1111&0000 0101对于上面这个运行结果的取值方法,我们来讨论一下:因为15的高四位都是0,低四位都是1。而与操作的逻辑是两个运算位都是1结果才是1。所以对于上面这个运算结果的高四位肯定都是0(15高四位都是0),而低四位和h的低四位是一样的(15低四位都是1)。所以结果的取值范围就是h的低四位的一个取值范围:0000~1111,也就是0至15(把高位全部丢弃,压缩至低位)。所以这个结果是符合数组下标的取值范围的。
那么假设length为17(不是2的次幂)呢?那么h&(length-1)则为:
情况1:h: 0101 0101
h: 0101 010116: 0001 0000&0001 0000情况2:h: 0100 0101
h: 0100 010116: 0001 0000&0000 0000当length为17时,上面的运算结果取值范围已经算不上一个范围了,就只有两值了。要么是0000 0000,要么是0001 0000。也就是说你的所有元素都只能压入长度为2的数组当中。这肯定是不行的。因此,我们选择2的次幂作为数组长度,完全是借用了上述算法的特性而来的。
如果我们想把HashCode转换为覆盖数组下标取值范围的下标,跟我们的length是非常相关的。length如果是16,那么减一之后就是15(0000 1111),正是这种高位都是0,低位都是1的二进制数才保证了可以对任意一个hashcode进过逻辑与操作后,得到的结果使我们想要的数组下标。如果lenth是32同理,减一后的31(全面均为0.... 11111 11111)。
这也就是为什么在真初始化HashMap的时候,对于数组的长度一定要是2的次幂。这种运算往往比取模运算更加快速。
讲到这里,下一个问题也接着来了。经过了逻辑与操作得到相同的数组下标,那么HashMap是如何处理的呢?没错,我们的链表此时闪亮登场。
JDK1.7HashMap为啥用头插法
HashMap在put元素的过程中会发生冲突。而解决冲突的方式自然就是链表了。那么HashMap存储结构就衍变成了下面的结构:
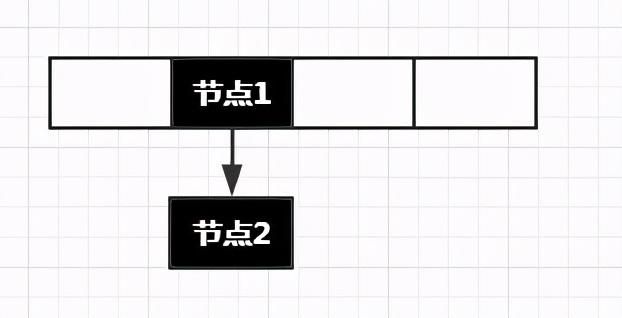
还是之前我们说的。博主浏览了许多讲解HashMap的博客。多数的人上来就开始:JDK1.7HashMap在遇到Hash冲突的时候,使用的是头插法对链表进行插入。具体的流程细节是......。
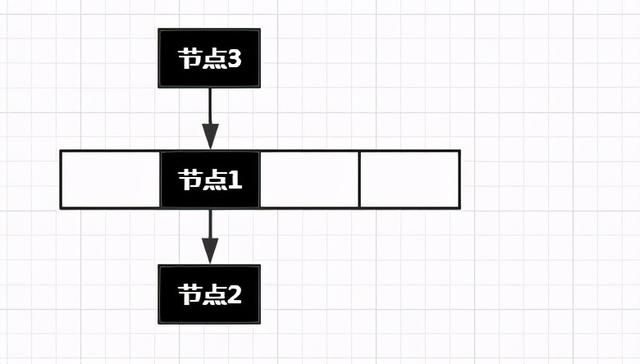
一开始作为新手的我,看到此处是非常难受的。因为即使是已经过去的技术,被淘汰的版本。但当时的设计师是怎么会想到用头插法这种反人类的操作方式进行插入呢?本文中,我先对这个问题进行解释。
假设我们同一个数组下标下挂着的链表不是1,2个。而是成百上千个。那么我们如果采用尾插法,在访问元素的时候就要从第一个元素,依次向后遍历每一个元素查到我们要的元素。查询的时间复杂度为O(n)。
此时,当时的设计师应该做过许多的统计,最后得出了这么一个结论:后插入的值往往伴随着更大被查找的可能性。
伴随着这个结论的产生,如果将链表的尾插法改为头插法,在链表的长度较长的情况下,访问的效率自然也伴随着大幅度提升。为了这个目的,最后选择头插法实现链表的插入。
哦~~~读到这里,大家应该理解了头插法这种现在看来匪夷所思的操作,也是包含了设计师的良苦用心的呀。这个例子中,我们除了理解为什么选择头插法外,也发现了一个问题。就是即使经过了Hash算法,但是一个链表依旧存在长度过长,访问效率较差的问题。那么这个后续的大牛是如何解决的呢?我们继续留到后面说。
头插法的实现细节
当我们使用头插法插入一个新元素时,效果图如下:
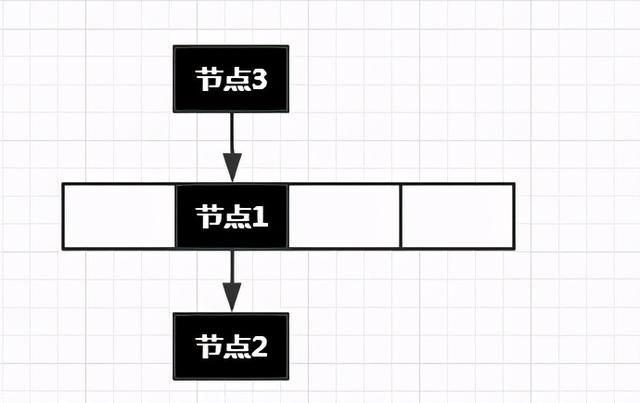
那么按照这种插入方式,会出现一个问题
- 获取节点2:当我们需要get(节点2)时,我们先将节点2的key进行哈希然后算出下标。拿到下标后可以定位到数组中的节点1。但是发现节点1不等于节点2,所以不是最终的结果,继续向下遍历,发现了节点2。这个步骤是成功的。
- 获取节点3:当我们需要get(节点3)时呢?我们就会发现找不到节点3了。这个步骤就失败了。
这时候我们有两种方式解决这个问题。
- 获取到了节点1,先向下查找,失败后返回节点1再向上查找(双向遍历)。
- 就是在头插完毕后,将这个该数组下标的所在链表向下移动一位。
我们的HashMap选择了第二种方式,移动后的结果如下:
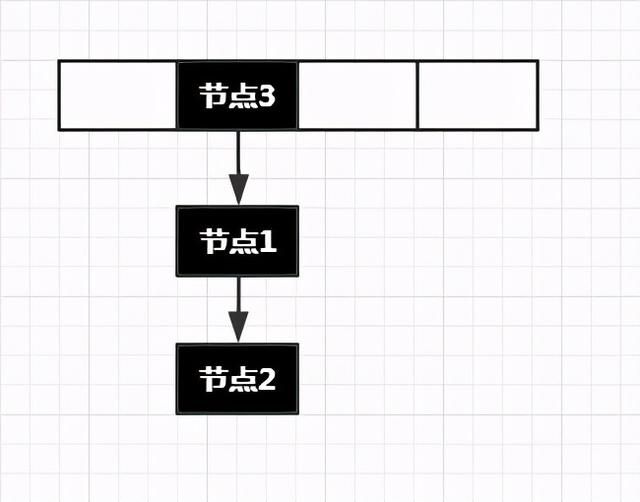
那么现在put元素的思路就是:将新节点插在链表的头部。此时新节点就是当前这个链表的头节点,接下来把头节点移动到数组位置即可。
HashMap中put一个已存在的key会怎样
当我们使用HashMap时,可能会出现put一个已存在的key:
HashMap<String, String> hashMap = new HashMap<>();hashMap.put("1", "2");String value = hashMap.put("1", "3");System.out.println(value);可以看到,第二行的put和第三行的put,他们的key都是1。这时候在HashMap里会将value覆盖。也就是key="1"对应的value最终为"3"。而第三行代码返回的value将会是2(被覆盖的值)。
我们现在来考虑这个put是如何实现的。
其实也很简单。第三行代码的逻辑也是对"1"计算哈希值以及对应的数组下标。有了下标后就可以找到对应的位置的链表,而将新节点插入链表之前,还需要判断一下当前新节点的key是否已经在这个链表上存在。所以需要先去遍历当前这个位置的链表,在遍历的过程中如果找到了相同的key则会覆盖value,并且返回oldvalue。
诶诶诶?刚不是说头插法就是为了少遍历么?怎么你每次插入还要完整遍历判断一次呢?
注意:头插法的目的是在获取元素时,新插入的元素被访问的频率更高。获取元素时的key一定是唯一的,因此访问到第一个符合的key值就不需要继续遍历了。
put方法的总结
写到了这里,我们对HashMap的put核心流程已经基本书里的差不多了,再总结一下:
- put(key , value);
- int hashcode = key.hashCode();
- int index = hashcode & (数组长度-1);
- 遍历index位置的链表,如果存在相同的key,则进行value覆盖,并且返回之前的value值;
- 将key,value封装为节点对象(Entry);
- 将节点插在index位置上的链表头部;
- 整个该节点的链表向下移动一位;
最核心的7步罗列完毕。在这个过程中还有一个重要的步骤,就是扩容。而扩容是发生在插入节点之前的。也就是步骤4和步骤5之前。
而扩容阶段,就会产生一个1.7版本的HashMap最大的问题——"死锁问题"。那么这个问题是如何产生的呢?
HashMap不适用于并发环境的原因
put元素时的元素覆盖
还是老话,太多的文章上来就讲死循环问题。我发现有一些开发反而忽略了HashMap本身造成线程不安全的原因。首先我们来先说多线程环境下的put一个元素,为什么会线程不安全。
假设我们的HashMap中只有一个元素A。此时线程1向HashMap中添加一个元素B。经过Hash运算后,元素B的索引值与A重复,因此要使用头插法向A插入B。在执行插入的过程中,线程2也开始向HashMap中添加一个C。同样,在经过Hash运算,元素B的索引值也与A重复。但此时,线程2在执行插入元素C的时,对线程1中插入元素B的操作是不可见的。
因此当线程1执行完插入操作后,线程1的链表B->A确实已经存在了,但是紧接着就被线程2的C->A所覆盖。这就是HashMap线程不安全的根本原因。
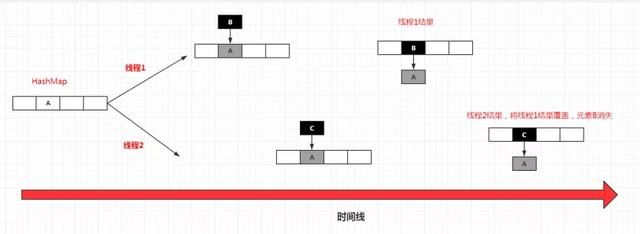
HashMap扩容时机
当HashMap中的元素越来越多的时候,碰撞的几率也就越来越高(因为数组的长度是固定的),所以为了提高查询的效率,就要对HashMap的数组进行扩容,数组扩容这个操作也会出现在ArrayList中,所以这是一个通用的操作,很多人对它的性能表示过怀疑,不过想想我们的“均摊”原理,就释然了,而在hashmap数组扩容之后,最消耗性能的点就出现了:原数组中的数据必须重新计算其在新数组中的位置,并放进去,这就是resize。
那么HashMap什么时候进行扩容呢?当hashmap中的元素个数超过数组大小loadFactor时,就会进行数组扩容,loadFactor的默认值为0.75,也就是说,默认情况下,数组大小为16,那么当hashmap中元素个数超过160.75=12的时候,就把数组的大小扩展为2*16=32,即扩大一倍,然后重新计算每个元素在数组中的位置,而这是一个非常消耗性能的操作,所以如果我们已经预知hashmap中元素的个数,那么预设元素的个数能够有效的提高hashmap的性能。
比如说,我们有1000个元素new HashMap(1000), 但是理论上来讲new HashMap(1024)更合适,不过上面annegu已经说过,即使是1000,hashmap也自动会将其设置为1024。但是new HashMap(1024)还不是更合适的,因为1000 > 1024 * 0.75 = 768, 也就是说当元素添加到768的时候,依旧会触发自动扩容。因此我们必须这样new HashMap(2048)才最合适,避免了resize的问题。
扩容导致的死循环
死循环的现象
如果是在单线程下使用HashMap,自然是没有问题的,如果后期由于代码优化,这段逻辑引入了多线程并发执行,在一个未知的时间点,会发现CPU占用100%,居高不下,通过查看堆栈,你会惊讶地发现,线程都Hang在hashMap的get()方法上,服务重启之后,问题消失,过段时间可能又复现了。
死循环的造成原理
成环的代码在扩容时的transfer方法里,代码如下:
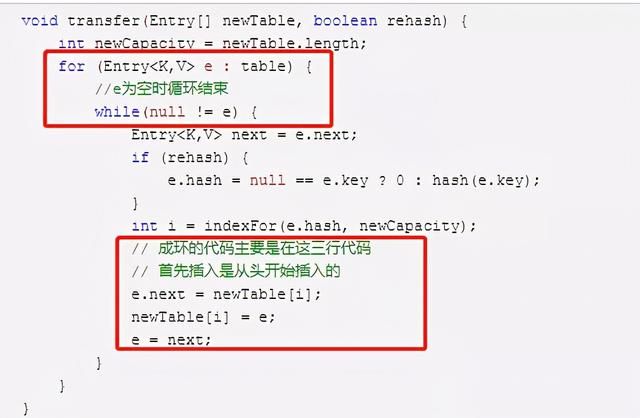
我们简单分析一下代码,可以知道外层for循环控制着数组遍历,内存的while循环控制着链表的遍历。
模拟单线程扩容操作
首先,HashMap的扩容思路,就是生成一个数组长度为oldTable数组长度2倍的newTable,然后将原本oldTable上的元素一次依照transfer方法的逻辑,添加至newTable中。
第一步:执行e.next = newTable[i];
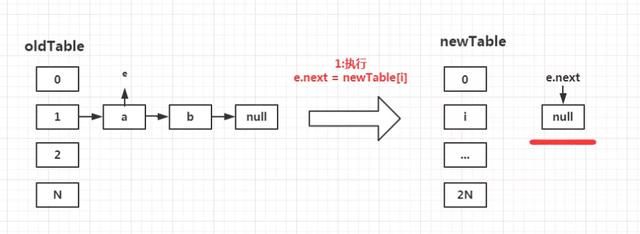
我们的e经过外层for循环定位到了数组下标为1的链表中。并且指向链表的第一个元素,也就是a。此时的newTable作为一个新生成的容器,并没有任何元素。因此e.next = newTable[i] = null;
注意:此时并没有向这个newTable上存放任何元素。
第二步:执行newTable[i]=e;
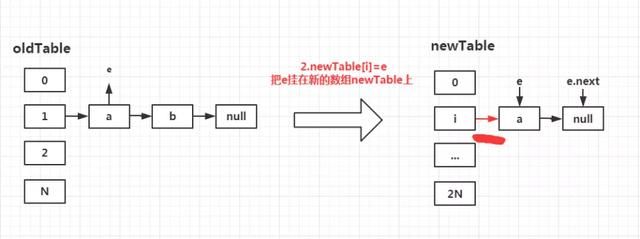
我们都知道,e指向的是a,因此newTable[i]=e,也就是把元素a挂在了newTable下标为i的链表中。
第三步:执行e=next;

仔细观察代码,我们发现在while循环进入时,我们执行了Entry<K,V> next = e.next;也就是说,我们提前将节点b保存在了next字段中。此时执行e = next;相当于a的指针向后移动至b。结束第一轮循环。
第四步:再次执行e.next = newTable[i];
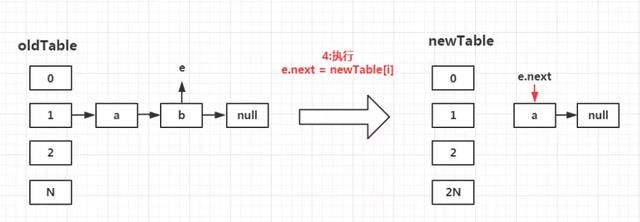
此时的newTable[i]已经不再是null了,而是经过第一次循环变为了a。因此此步骤相当于e.next=a;
第五步:再次执行newTable[i]=e;
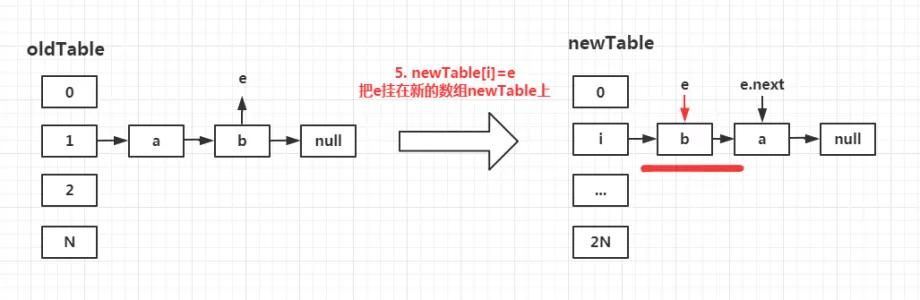
将b用头插法插入newTable[i]中。
第六步:再次执行e=next;
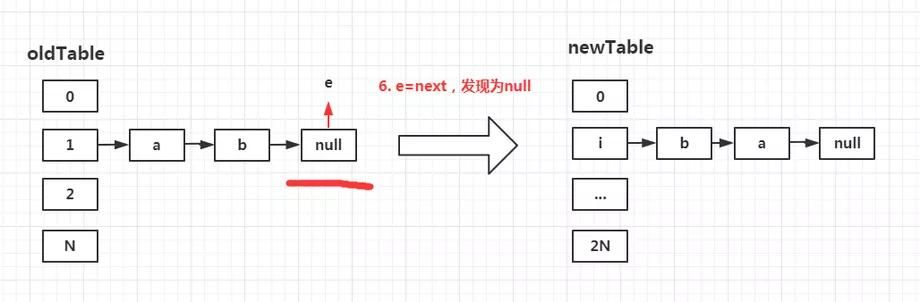
此时再次从元素b开始向后移动指针。发现后续元素已经为null。从而结束整个oldTable[1]的链表遍历。
总结
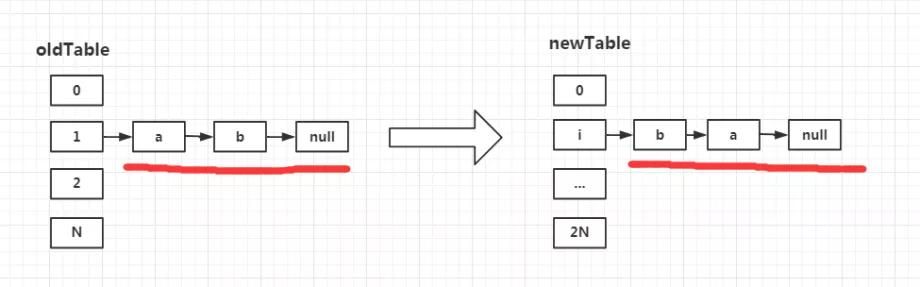
整个操作仔细看下来,我们发现头插法的一个特性。就是在扩容过程中再次使用头插法,数据就会出现和原先HashMap链表逆序的现象
多线程下扩容导致死循环
诶?单线程下跑得好好的,多线程你就能出问题?博主对此仔细地画了一张多线程下出问题的流程图:
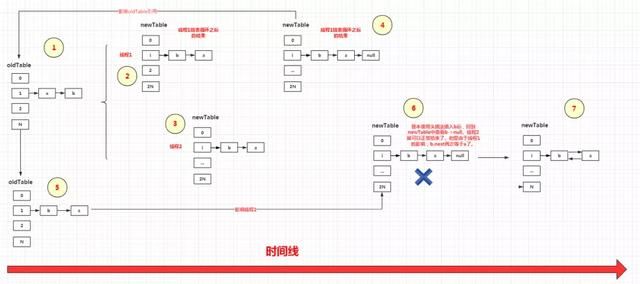
总结发生死循环的原因,便是第一个线程导致了oldTable中的链表倒序。当其他线程也执行倒序操作的最后一步e=next时,造成了循环链表导致死循环。具体细节已仔细画在图中,就不再做赘述。
JDK1.8解决死循环问题
JDK1.7用的是头插法,而JDK1.8及之后使用的都是尾插法,那么他们为什么要这样做呢?因为JDK1.7是用单链表进行的纵向延伸,当采用头插法时会容易出现逆序且环形链表死循环问题。但是在JDK1.8之后是因为加入了红黑树使用尾插法,能够避免出现逆序且链表死循环的问题,也能更加高效的对链表进行遍历(以代替为了热点数据出现频率而强行使用的反人类头插法)。