从DPU开始到RDMA到CUDA
DPU是Data Processing Unit的简称,它是最新发展起来的专用处理器的一个大类,是继CPU、GPU之后,数据中心场景中的第三颗重要的算力芯片,为高带宽、低延迟、数据密集的计算场景提供计算引擎。
DPU将作为CPU的卸载引擎,释放CPU的算力到上层应用。以网络协议处理为例,要迅速处理10G的网络需要的大约4个Xeon CPU的核,也就是说,单是做网络数据包处理,就可以占去一个8核高端CPU的一半的算力。如果考虑40G、100G的高速网络,性能的开销就更加难以承受了。Amazon把这些开销都称之为“Datacenter Tax”——还未运行业务程序,先接入网络数据就要占去的计算资源。AWS Nitro产品家族旨在将数据中心开销(为虚机提供远程资源,加密解密,故障跟踪,安全策略等服务程序)全部从CPU卸载到Nitro加速卡上,将给上层应用释放30%的原本用于支付“Tax” 的算力。
参考文献链接
https://baike.baidu.com/item/DPU/11007035?fr=aladdin
https://baike.baidu.com/item/CUDA/1186262?fr=aladdin
https://baike.baidu.com/item/RDMA/1453093?fr=aladdin
https://mp.weixin.qq.com/s/l_7EYBRRHyAkuh7HmnE1xQ
https://mp.weixin.qq.com/s/ebOyILHjqsomFpfylgNdRw
https://github.com/xcyuyuyu/My-First-CUDA-Code
https://mp.weixin.qq.com/s/zwGdaqkvbc950LeT6ABxYA
https://developer.nvidia.com/blog/even-easier-introduction-cuda/
DPU将成为新的数据网关,将安全隐私提升到一个新的高度。在网络环境下,网络接口是理想的隐私的边界,但是加密、解密的算法开销都很大,例如国密标准的非对称加密算法SM2、哈希算法SM3和对称分组密码算法SM4。如果用CPU来处理,就只能做少部分数据量的加密。在未来,随着区块链承载的业务的逐渐成熟,运行共识算法POW,验签等也会消耗掉大量的CPU算力。而这些都可以通过将其固化在DPU中来实现,甚至DPU将成为一个可信根。
DPU将成为存储的入口,将分布式的存储和远程访问本地化。随着SSD性价比逐渐变得可接受,部分存储迁移到SSD器件上已经成为可能,传统的面向机械硬盘的SATA协议并不适用于SSD存储,所以,将SSD通过本地PCIE或高速网络接入系统就成为必选的技术路线。NVMe(Non Volatile Memory Express)就是用于接入SSD存储的高速接口标准协议,可以通过PCIe作为底层传输协议,将SSD的带宽优势充分发挥出来。同时,在分布式系统中,还可通过NVMe over Fabric协议扩展到InfiniBand、或TCP互连的节点中,实现存储的共享和远程访问。这些新的协议处理都可以集成在DPU中来实现对CPU的透明处理。进而,DPU将可能承接各种互连协议控制器的角色,在灵活性和性能方面达到一个更优的平衡点。
DPU将成为算法加速的沙盒,成为最灵活的加速器载体。DPU不完全是一颗固化的ASIC,在CXL, CCIX等标准组织所倡导CPU、GPU与DPU等数据一致性访问协议的铺垫下,将更进一步扫清DPU编程障碍,结合FPGA等可编程器件,可定制硬件将有更大的发挥空间,“软件硬件化”将成为常态,异构计算的潜能将因各种DPU的普及而彻底发挥出来。在出现“Killer Application”的领域都有可能出现与之相对应的DPU,诸如传统数据库应用如OLAP、OLTP, 或新兴应用如智能驾驶等。
CUDA(Compute Unified Device Architecture),是显卡厂商NVIDIA推出的运算平台。 CUDA™是一种由NVIDIA推出的通用并行计算架构,该架构使GPU能够解决复杂的计算问题。 它包含了CUDA指令集架构(ISA)以及GPU内部的并行计算引擎。 开发人员可以使用C语言来为CUDA™架构编写程序,所编写出的程序可以在支持CUDA™的处理器上以超高性能运行。CUDA3.0已经开始支持C++和FORTRAN。
CUDA 是 NVIDIA 发明的一种并行计算平台和编程模型。它通过利用图形处理器 (GPU) 的处理能力,可大幅提升计算性能。
目前为止基于 CUDA 的 GPU 销量已达数以百万计,软件开发商、科学家以及研究人员正在各个领域中运用 CUDA,其中包括图像与视频处理、计算生物学和化学、流体力学模拟、CT 图像再现、地震分析以及光线追踪等等。
计算行业正在从只使用CPU的“中央处理”向CPU与GPU并用的“协同处理”发展。为打造这一全新的计算典范,NVIDIA™(英伟达™)发明了CUDA(Compute Unified Device Architecture,统一计算设备架构)这一编程模型,是想在应用程序中充分利用CPU和GPU各自的优点。该架构已应用于GeForce™(精视™)、ION™(翼扬™)、Quadro以及Tesla GPU(图形处理器)上,对应用程序开发人员来说,这是一个巨大的市场。
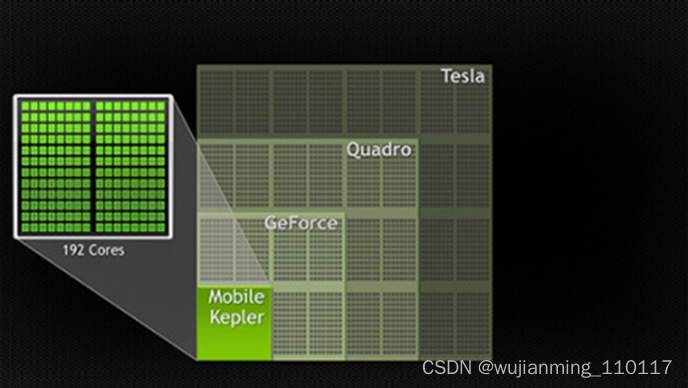
GPU架构
在消费级市场上,几乎每一款重要的消费级视频应用程序都已经使用CUDA加速或很快将会利用CUDA来加速,其中不乏Elemental Technologies公司、MotionDSP公司以及LoiLo公司的产品。
在科研界,CUDA一直受到热捧。例如,CUDA现已能够对AMBER进行加速。AMBER是一款分子动力学模拟程序,全世界在学术界与制药企业中有超过60,000名研究人员使用该程序来加速新药的探索工作。
在金融市场,Numerix以及CompatibL针对一款全新的对手风险应用程序发布了CUDA支持并取得了18倍速度提升。Numerix为近400家金融机构所广泛使用。
CUDA的广泛应用造就了GPU计算专用Tesla GPU的崛起。全球财富五百强企业已经安装了700多个GPU集群,这些企业涉及各个领域,例如能源领域的斯伦贝谢与雪佛龙以及银行业的法国巴黎银行。
随着微软Windows 7与苹果Snow Leopard操作系统的问世,GPU计算必将成为主流。在这些全新的操作系统中,GPU将不仅仅是图形处理器,它还将成为所有应用程序均可使用的通用并行处理器。
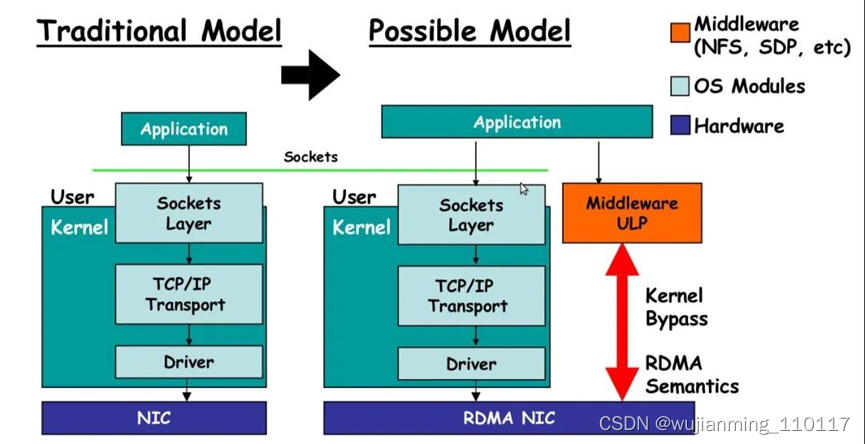
RDMA是Remote Direct Memory Access的缩写,意思是远程直接数据存取,就是为了解决网络传输中服务器端数据处理的延迟而产生的。
RDMA(Remote Direct Memory Access)技术全称远程直接数据存取,就是为了解决网络传输中服务器端数据处理的延迟而产生的。RDMA通过网络把资料直接传入计算机的存储区,将数据从一个系统快速移动到远程系统存储器中,而不对操作系统造成任何影响,这样就不需要用到多少计算机的处理功能。它消除了外部存储器复制和上下文切换的开销,因而能解放内存带宽和CPU周期用于改进应用系统性能。
传统意义上的DMA
直接内存访问(DMA) 方式,是一种完全由硬件执行I/O交换的工作方式.在这种方式中, DMA 控制器从CPU 完全接管对总线的控制,数据交换不经过CPU ,而直接在内存和IO设备之间进行.DMA工作时,由DMA 控制器向内存发出地址和控制信号,进行地址修改,对传送字的个数计数,并且以中断方式向CPU 报告传送操作的结束。
使用DMA 方式的目的是减少大批量数据传输时CPU 的开销.采用专用DMA 控制器(DMAC) 生成访存地址并控制访存过程.优点有操作均由硬件电路实现,传输速度快;CPU 基本不干预,仅在初始化和结束时参与, CPU 与外设并行工作,效率高。
RDMA工作原理
普通网卡集成了支持硬件校验的功能,并对软件进行了改进,从而减少了发送数据的拷贝量,但无法减少接收数据的拷贝量,而这部分拷贝量要占用CPU 的大量计算周期.普通网卡的工作过程如下:先把收到的数据包缓存到系统上,数据包经过处理后,相应数据被分配到一个TCP 连接;然后,接收系统再把主动提供的TCP 数据同相应的应用程序联系起来,并将数据从系统缓冲区拷贝到目标存储地址.这样,制约网络速率的因素就出现了:应用通信强度不断增加和主机CPU 在内核与应用存储器间处理数据的任务繁重使系统要不断追加主机CPU 资源,配置高效的软件并增强系统负荷管理.问题的关键是要消除主机CPU 中不必要的频繁数据传输,减少系统间的信息延迟。
RDMA 是通过网络把资料直接传入计算机的存储区,将数据从一个系统快速移动到远程系统存储器中,而不对操作系统造成任何影响,这样就不需要用到多少计算机的处理功能.它消除了外部存储器复制和文本交换操作,因而能腾出总线空间和CPU 周期用于改进应用系统性能. 通用的做法需由系统先对传入的信息进行分析与标记,然后再存储到正确的区域。
RDMA 的工作过程如下:
1)当一个应用执行RDMA 读或写请求时,不执行任何数据复制.在不需要任何内核内存参与的条件下, RDMA 请求从运行在用户空间中的应用中发送到本地NIC( 网卡)。
2) NIC 读取缓冲的内容,并通过网络传送到远程NIC。
3) 在网络上传输的RDMA 信息包含目标虚拟地址、内存钥匙和数据本身.请求完成既可以完全在用户空间中处理(通过轮询用户级完成排列) ,或者在应用一直睡眠到请求完成时的情况下通过内核内存处理.RDMA 操作使应用可以从一个远程应用的内存中读数据或向这个内存写数据。
4) 目标NIC 确认内存钥匙,直接将数据写入应用缓存中.用于操作的远程虚拟内存地址包含在RDMA 信息中。
• 3.RDMA中零拷贝技术
零拷贝网络技术使NIC 可以直接与应用内存相互传输数据,从而消除了在应用内存与内核内存之间复制数据的需要.内核内存旁路使应用无需执行内核内存调用就可向NIC 发送命令.在不需要任何内核内存参与的条件下, RDMA 请求从用户空间发送到本地NIC,并通过网络发送给远程NIC ,这就减少了在处理网络传输流时内核内存空间与用户空间之间环境切换的次数。
右边是传统TCP/IP 协议以及普通网卡进行的通信操作过程.很明显,当应用层想从网卡获得数据报文时需要经过2 个缓冲区和正常TCP/IP 协议栈,其中由软中断负责从第一个接收队列缓冲区读取数据报文,再拷贝到MSGBuff 中,最后由应用层通过系统调用将数据报文读到用户态.而左边则是利用RDMA来实现的零拷贝过程,规则如下:
- RDMA 及其LLP( Lower Layer Protocol)可以在NIC 上实现(称为RNIC)。
- 在1)中所说的2 种实现都是经过以下步骤:将收发的数据缓存到一个已经标记好的存储空间中,然后根据LLP 和RDMA 双方协商的规则直接将此存储空间映射到应用空间,这样就减少了传统实现方法中的至少2次内存拷贝,即实现零拷贝.其中细线表示数据流动方向,其实标记缓存就是通过RDMA 直接映射成为用户缓存空间的。
从DPU的崛起谈谈计算体系变革
围绕为什么数据中心要变革、数据中心面临的问题和技术发展趋势、DPU的技术细节以及为什么芯片会催生新的计算架构等方面进行了系统分析系统分析。推荐给大家。
最近DPU概念异常火爆,从Mellanox、Fungible、NVIDIA到Intel,各路诸侯纷纷加入战场,各种概念Smart NIC、DPU、IPU层出不穷,各种SDK,FunOS、DOCA、IPDK令人眼花缭乱,比当年AI还要火爆。

围绕为什么数据中心要变革、数据中心面临的问题和技术发展趋势、DPU的技术细节以及为什么芯片会催生新的计算架构等方面进行了系统分析系统分析。推荐给大家。
为什么现在数据中心要变革?
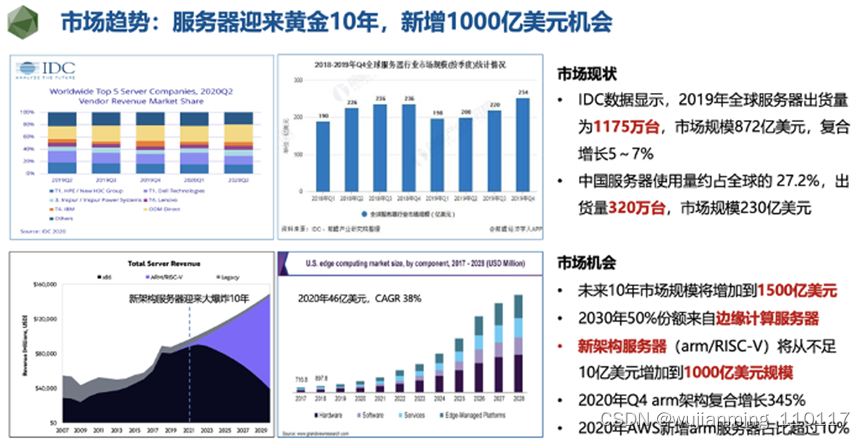
数据中心的核心支柱服务器是一个非常有意思和残酷的产业,容易垄断,淘汰又非常快,一不留神就退出了历史的舞台。
和20年前x86通过占领个人PC市场反攻数据中心/大型机市场这种“农村包围城市”的打法一样,今天的arm/risc-v架构通过占领手机,物联网等终端设备,开始进入数据中心市场。但和20年前不一样的是,Intel面对的竞争不是来自同行,而是客户“自下而上”的竞争。例如2020年苹果宣布2年内替换Intel CPU到自研Apple Silicon;AWS云服务中新增服务器中自研arm架构比例也已经超过10%了。这种“不对称”竞争将加速x86架构的衰落,所以ARK预测这次架构的变革可能只需要10年。如果按照两三年一代的迭代速度,留给Intel的机会可能也就3代产品的时间了。
在这次服务器架构变革还有一个非常有意思的地方,通常大家忽视的一个地方,未来10年服务器的增量大头会发生在边缘计算领域,预计2029年边缘服务器将达到700-900亿美元规模,将占据服务器市场规模的50%左右。所以我们认为“第三颗”大芯片的机会应该更快的在边缘计算领域发生。
数据为中心的计算时代
最早提出“数据为中心”Data-centric计算时代这个概念的是硅谷创业公司Fungible。在数据为中心的架构中,计算更加靠近网络,即流量产生或者到达的地方,通过增加一个SoC的方式卸载host CPU对流量处理的开销。
根据Fungible和AWS的统计,在大型数据中心中,流量处理占到了计算的30%左右,即数据中心中30%的计算是在作流量处理,这个开销被形象的叫做数据中心税(Datacenter Tax)。借用某某资本的总结,数据为中心的计算架构的好处是降低了CPU到加速卡的路径,是数据传输效率更高,性能更好。
最早提出这个概念的Fungible同时给自己的芯片取了一个特有的名字“DPU”,同时认为DPU将成为计算机仅次于CPU、GPU的“第三颗”大芯片出现。Fungible认为自己的使命是解决数据为中心的时代的网络流量问题。DPU的出现是为了解决数据中心中存在三个方面共五大问题:

按照技术出现的时间顺序和特点,我们将DPU的发展分为三个阶段:
第一阶段:Smart NIC(智能设备)
这个可以称为DPU的史前时代。解决节点间流量问题的最简单的方式是增加网卡的处理能力,通过在网卡上面引入SoC或者FPGA的方式加速某些特定流量应用,从而加强网络的可靠性,降低网络延迟,提升网络性能。其中Xilinx和Mellanox在这个领域进行的比较早,可惜由于战略能力不足,错失了进一步发展的机会,逐渐被DPU取代,最终被淘汰。其中Mellanox被Nvidia收购,Xilinx被AMD拿下。智能网卡成为DPU的应用产品而存在。(Marvell会如何选择我们拭目以待)
第二阶段:DPU(数据处理芯片)
这个阶段是数据芯片真正开始被重视的阶段。最开始由Fungible在2019年提出,但没有引起太多反响。Nvidia将收购来的Mellanox重新包装之后,2020年10月重新定义了DPU这个概念,DPU这个概念一炮而红。有意思的是Nvidia对DPU的定义完全不同于Fungible,在Nvidia的博客上有一段非常有意思的评价。

虽然Fungible号称DPU是要解决很多网络问题。但回归本质,一个性能强大的x86都没有解决的问题,为什么一个嵌入式SoC可以干得更加好呢?这个是一个非常严肃也是一个需要正面回答的问题。显然Fungible回避了这个本质问题,而是用了一个120瓦的SoC来处理流量问题。然而Nvidia却从另一个纬度回答了这个问题,那就是DPU只应该处理网络路径(network data path initialization)和异常(exception processing),而不是其他的(nothing more)。
Nvidai的做法非常简单同时也非常容易理解,毕竟卖GPU比卖DPU更加赚钱,而Nvidia不会放过一切增加GPU销量的机会。但仔细看一下这句话,其实暗含了一个Nvidia的技术路线exception processing!
第三阶段:IPU(基础设施芯片)
对于“第三颗”芯片这么重要的战场,自然少不了Intel的加入。Intel的解决方案非常简单粗暴。DPU的存在不就是为了解决流量卸载问题么,我用FPGA就好了!DPU不就是想管理云平台么?那好,我再送一个CPU就好了。于是乎Intel的方案变成了FPGA+Xeon-D的模式,通过PCB版的方式放在一个智能网卡上(估计功耗要超过200瓦)。
同时Intel给这个方案取了一个非常有意思的名字“基础设施处理器”。显然Intel将IPU定位成host CPU上面一个“外挂”的小CPU,而且未来这个“外挂”CPU和FPGA会封装到一个芯片中,形成一个奇怪的通过PCIe总线互联的两个CPU系统。这种一个总线多个CPU的架构,Intel在GPU Phi中已经用过。
从系统上来看,这个架构非常简洁,我们觉得应该也是DPU应该发展的方向。但同时IPU引发了一个架构性的问题,“这个架构中到底IPU是中心,还是host CPU是中心?”。目前Intel只给出了一个非常模棱两可的介绍,回避了这个问题。我们认为真正解决了这个问题的芯片才能成为未来真正的“第三颗”大芯片,甚至是主要芯片。
显然Intel和Nvidia都看到了这个机会,DPU/IPU真正有价值而且极具价值的在于,谁处理exception?到底是host CPU还是DPU?如果是DPU?那么其他设备比如GPU的exception谁处理呢?
经过几年的发展,数据芯片(DPU/IPU)的地位一直在提升,正在成为“第三颗”大芯片。
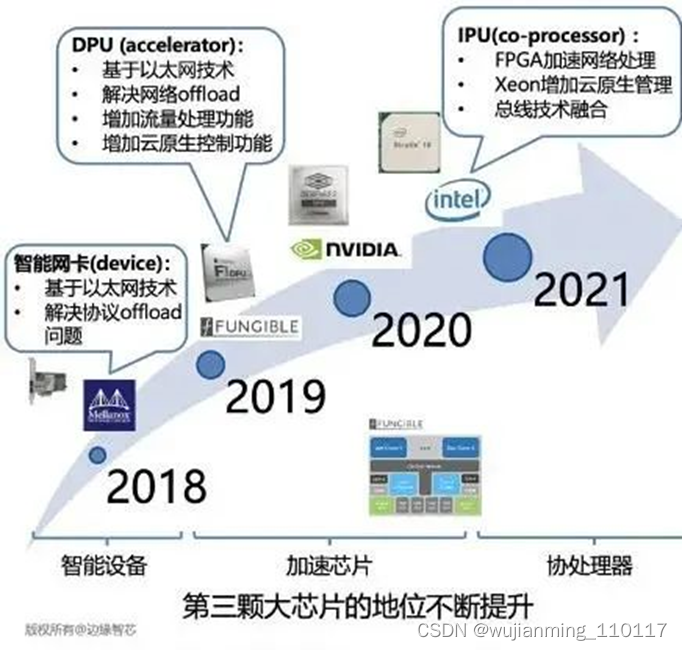
对比一下当前Fungible、Nvidia和Intel的技术路线我们总结如下:
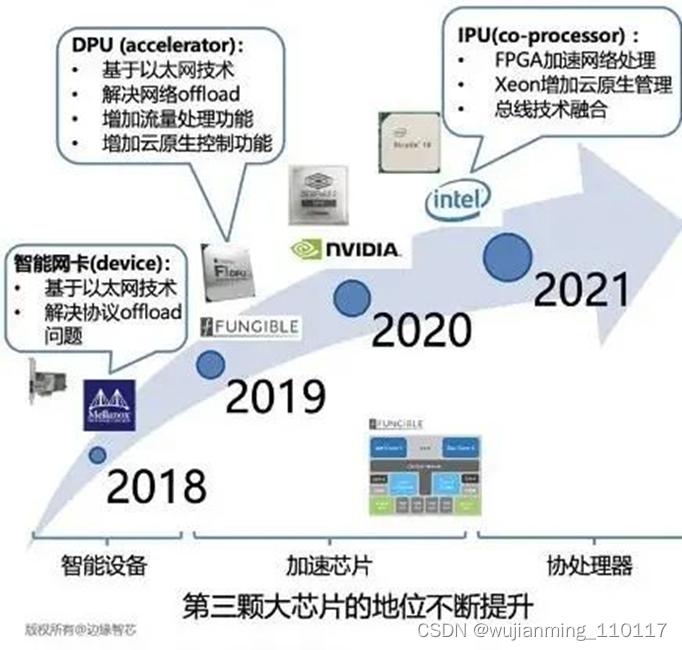
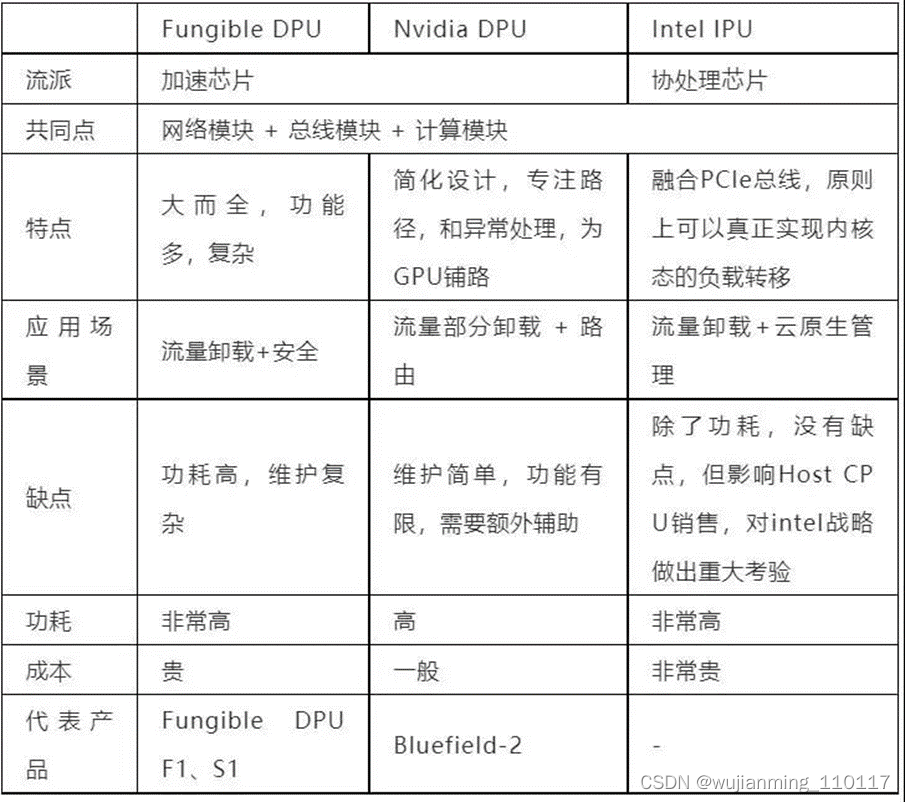
DPU/IPU的重要性已经达成了共识。但围绕DPU的定位存在一些争论,不同的公司根据自己技术特点选择不同技术路线。
数据中心的问题和技术发展的趋势需求
01 数据中心有什么问题?
数据中心作为当前信息化的基石,在过去50年发展相当迅猛。随着算力的提升,数据中心的能耗也越来越大,通常从广义上讲,数据中心面对三个核心问题:
• 性能问题(scale-up):如何提升计算性能,简单说就是单台服务器越算越快,这个有点难度,目前性能最强大的CPU应该是ARM架构的富岳(Fugaku);
• 规模问题(scale-out):第二个问题就是系统效率问题,如果一台服务器算力不够(大部分数据中心应用一台服务器是不够的),那么我们就需要多台服务器组成集群进行集群计算。如何接入更加多的服务器?并高效率的统筹各个服务器的运行状态和效率也是一个非常复杂和需要解决的问题,通常这个问题是一个系统架构和网络问题;
• 能耗问题(power):第三个问题是能耗问题。如何降低能耗、提升计算效率,从传统追求性能的技术路线,变成追求效能的技术路线?中国在这一方面战略上远远领先其他国家,特别是“碳达峰、碳中和3060”基本方针的提出。如果中国能早日实现计算上的“碳中和”,让CPU可以仅仅消耗极小的能耗即可运转的话,对能源安全和信息格局将发生巨大影响。
性能和能耗问题是一个非常复杂又有趣的问题,但不是我们DPU的重点,未来我们将介绍一篇如何用DPU和低功耗CPU也可以达到高性能高吞吐量计算的架构,今天我们接着DPU的技术路线继续。
按照DPU开始的定义,DPU核心是解决数据中心第二问题:“如何解决多节点服务器互联效率问题”。按照Fungible的结论,当前数据中心互联架构无法适应超大型数据中心(mega datacenter)和超小型数据中心(edge datacenter),所以Fungible提出用DPU和TrueFabric技术解决这个问题。的确有些数据中心非常大,几万台甚至十几万台服务器互联组成集群;有些特别小,可能只有十几台服务器互联。那么Fungible这种技术路线是不是可以解决这个问题呢?有没有更加友好的技术路线呢?
02 数据中互联面临的题?
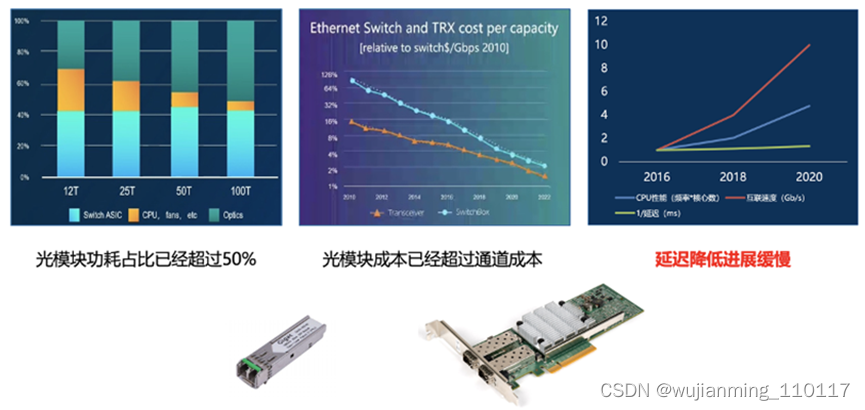
数据中心互联通常采用光通信方式,随着容量的提升在100T当量下,光模块的功耗占比超过了互联整体成本的50%,并且光模块成本也已经超过了通道成本(也就是说光模块加起来比交换机盒子贵了),但是随着吞吐率的激增,互联延迟缺没有明显降低。
03 云计算产业下游的需求是什么?
那一方面数据中心的用户,下游云计算产业的需求是对设备越来越颗粒化的管理和资源调配。在云计算3.0架构下,云管理平台(IaaS)希望对设备(CPU、GPU、FPGA、AI、NIC等)继续更加细致的管理,最好可以对每个设备进行独立操作(远程替换、升级、资源分配)。当然这种管理最好基于TCP/IP协议的Restful API接口。如果进一步,希望每个微服务(CPU运行应用)之间的TCP/IP通讯也可以在新型网络架构中加速。
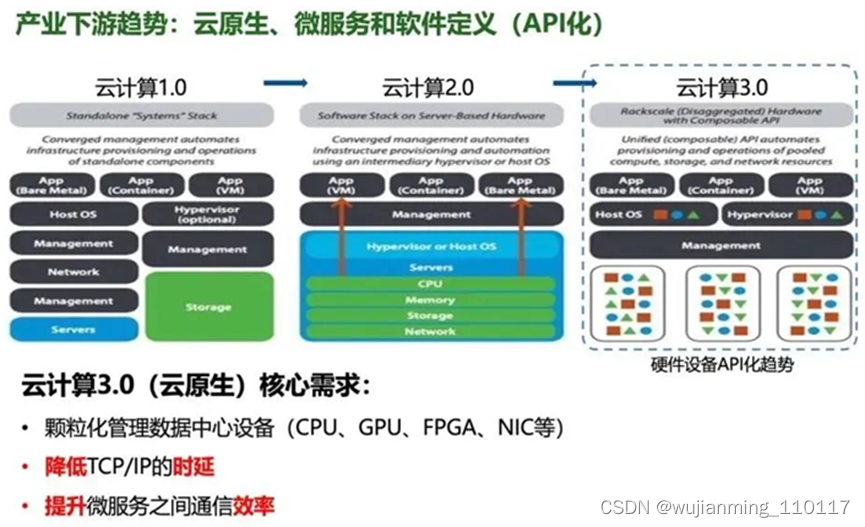
云计算2.0以服务器为单元,实现计算资源的软件定义,IaaS软件通过对服务器CPU的控制,实现CPU、内存、储存、网络的资源分配。而云计算3.0时代,设备单元将以“个体”、“独立”的方式被云平台(IaaS)管理和控制,整个设备单元以机柜(rackscale disaggregated hardware)方式存在。同时一切以API调用为主!
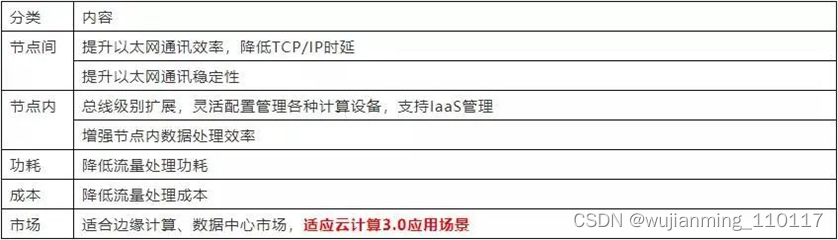
04 DPU需要解决的问题
在Fungible的基础上,我们总结了数据中心互联DPU芯片需要解决的几大问题如下:
DPU的技术细节
接下来我们将从系统角度分析当前DPU做的什么事情,解决了哪些问题。
01 传统云计算的网络模型
服务器互联和网络架构是一个非常复杂并且涉及到非常多的环节,为了简化问题,我只将DPU会涉及到的环节显示出来,如下图:
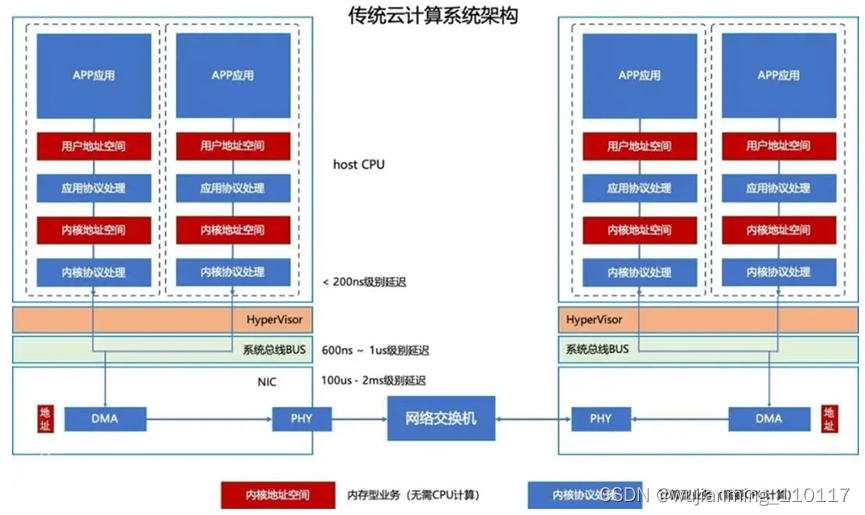
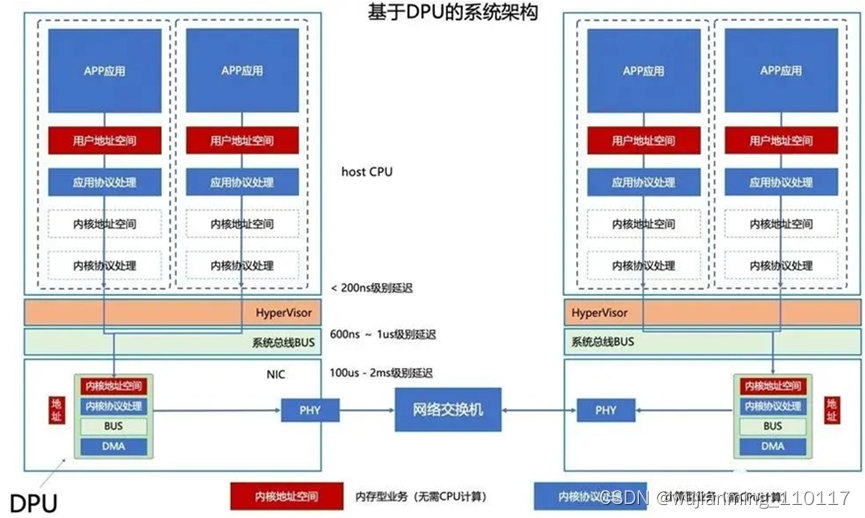
计算模块:主要由host CPU承担(部分由网卡上面的DMA小芯片承担)。当一个微服务(APP应用)和另外一个微服务(APP应用)通讯的时候,按照节点内(同一个host CPU上),和节点间(不同host CPU)上,数据流涉及的环节分别如下:
01.1节点间数据流动:
这是传统服务器和服务器互联的应用场景,这种场景中数据主要经历用户空间、内核空间、hypervisor、总线、网卡、PHY、交换机等一些列路径。在这些路径中:
• host CPU环节:现代CPU计算非常快,延迟一般由计算量确定。如果协议复杂、延迟就高,主频高,延迟就低。由于大部分协议都在host CPU上处理,所以传统意义上提高主频可以降低延迟;
• HyperVisor路径:HyperVisor和系统OS一般深度耦合,是IaaS计算平台的核心,计算量不大,主要工作是资源调度和计算切换(context switch)。一般云计算应用场景,资源(CPU、内存等)存在一定量的超售(也就是一个CPU卖了2-4个用户,用户通过分时间使用CPU)。由于内存的速率和CPU存在一个数量级的差异,频繁的计算切换将严重影响CPU的效率,使得CPU处于等待数据读取和写入阶段。同时因为网络需要考虑状态(TCP时序等),一旦切换发生很有可能需要重新开始计算一部分数据,导致了无形中浪费了计算资源,也增加了延迟。
• 系统总线模块:这个模块开始就是纯硬件模块了,一般的软件架构师不关注这一块,一般的网络芯片架构师也不设计这一块,是被忽视的部分。我们列出来是因为我们DPU+将在这一块上做文章,同时在DPU中也得包含这个部分。技术提升比较简单,提升总线频率即可。
• 网卡模块:这个是重头戏,工作内容却非常简单,就是将网络报文转化成光电信号发出去。由于CPU需要处理大量的工作,所以增加一个DMA(一个小的MCU做简单的网络协议处理功能)协助CPU干活。基本上现在Smart NIC和DPU就是对这个模块进行升级,让一个MCU干更多复杂的事情。
PHY、网络交换机部分:这一块就是以太网协议的设备了。
01.2 节点内数据流动:
这种数据模式是微服务的基本通讯方式。基本路径和节点间互联一样,唯一的区别是路由由Hypervisor(NAT或者端口,软路由)或者网卡(Bridge,硬路由)处理,即网络报文不需要额外交换机设备即可处理。这种方式是云计算的基本处理方式。
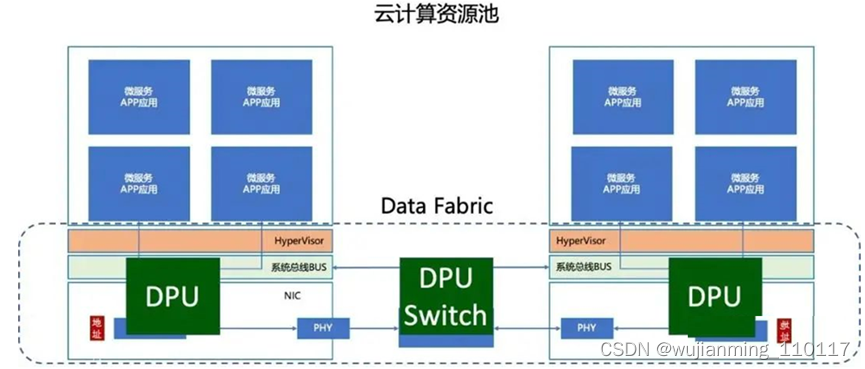
01.3 云计算资源池:
在分布式系统中(云计算、分布式数据库、分布式存储等),微服务同时存在多节点上,所以节点间、节点内通讯共存。在这种模式上,每个微服务相当于一个跨服务器间的“进程”。这种情况下,多台服务器互联成为一个“大服务器”。其中网络形成一个网络拓扑,称为Fabric。所以DPU的目标就是构建一个快速的Fabric网络,用于云计算应用。
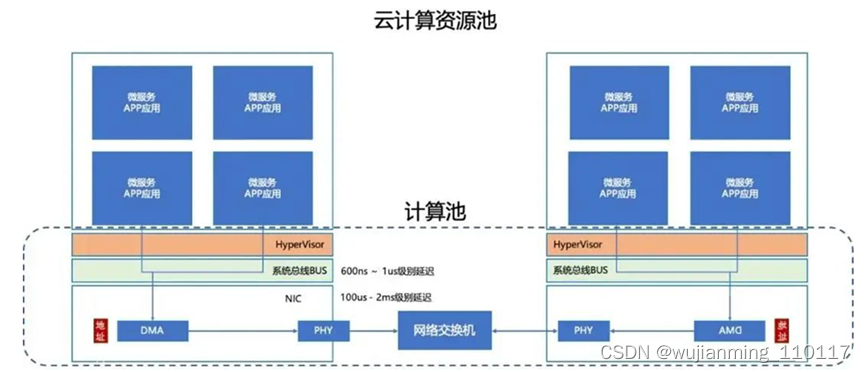
图:网络Fabric、计算池、微服务构成云计算技术IaaS
综上可以看到当前数据中心(包括小型集群)都构建在一个网络Fabric基础上,在这个Fabric上提供统一基于TCP/IP协议的微服务架构。构成这个网络Fabric的基础就是以太网技术,而技术发展目标就是提升吞吐率和降低延迟。
02 DPU构建下的云计算架构
上面已经介绍了网络Fabric是微服务和云计算发展的必然趋势。这个网络Fabric就像一张数据网,数据在中间流动。所以Fungible和Nvidia把组成这个Fabric的芯片命名为DPU,数据处理芯片。那DPU如何构建这个Fabric?如何降低网络延迟呢?
02.1 DPU的创新
DPU如何创新?刚刚介绍了在数据流中,内核协议处理部分和微服务应用相关性很小。所以一个想法就是将内核模块下沉到DMA上,这样就需要一个更加强大的MCU。最开始Xillinx和Intel都用FPGA来替代传统的DMA(网络芯片),达到应用加速的目的。在这种架构下,数据处理发生在host CPU之前,所以可以改善应用通讯的延迟,主要原因是:
• 网络处理发生在中断前,这个没有改进延迟,但节省了CPU的等待时间
• FPGA是独占式处理网络任务,不需要context switch,极大降低了高负载应用情况下的切换带来的延迟,极大的降低了网络抖动
• 可以把一些需要硬件加速的通用计算用FPGA加速,进一步释放CPU
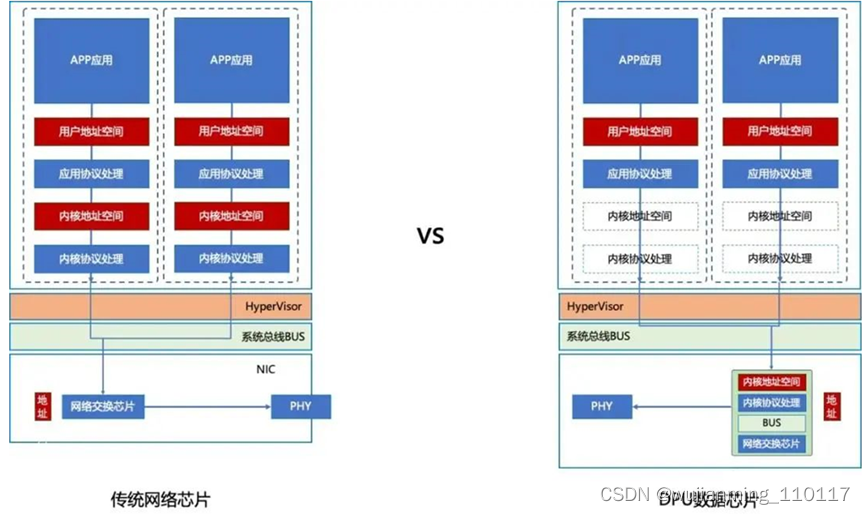
通过DPU互联我们可以有效的降低网络延迟和抖动,构建一个网络Fabric。

02.2 当前DPU的问题:过热
由于上述创新和Nvidia的大V效应,DPU很快热了起来。现在DPU最大的问题就是“过热”,功耗太高了。以前一个网络DMA芯片功耗才5瓦左右,现在一个DPU动则100瓦以上(Fungible F1 120瓦)。大部分应用场景无法用承受这么大功耗的网络设备。尤其是在100/200G以上,光模块功耗已经超过网络设备的情况下,再增加一个100瓦的网络DPU,会极大的提升网络的能源消耗。所以必须解决DPU功耗问题。
02.3 当前DPU的问题:架构臃肿
另外一个问题和架构有关,如果仔细看看DPU的架构不难发现,基本上DPU包括三个模块:1)网络模块,2)计算模块,3)总线模块。其中计算模块可以理解为以前网络DMA芯片的升级版本,从一个简单的ASIC升级成了一个强大的CPU或者网络处理器;网络模块是NIC的核心部件,接口为100/200G,同时提供网络交换功能,本质是一个小型的网络交换芯片;而总线模块是因为需要互联host CPU进行协议转换,也需要互联DPU内置CPU,一般采取PCIe 4.0/5.0为主。
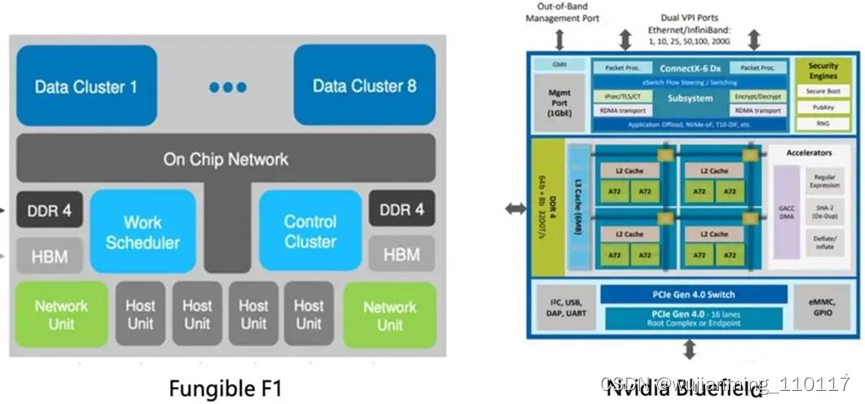
如果不是Fungible把F1叫做DPU用于智能网络,我觉得把这颗芯片当作一个路由器或者防火墙芯片也是绰绰有余的。考虑到Fungible具备强大的路由器、防火墙背景,这就不难理解了。我感觉Fungible的技术路线就是将防火墙芯片变成小放在网卡设备上,给每一台服务器提供一个防火墙芯片。但120瓦的功耗的确有点高。个人觉得这条技术路线不是DPU应该做的事情。
Nvidia很快就发现了这个问题,他们觉得如果用DPU处理CPU的任务是不可能的。DPU的CPU只应该做路径初始化和异常处理,有点类似L2/L3层交换机的意思。所以Nvidia的DPU就只放了几颗arm cpu,增加可编程能力而已。功耗也明显降低了下来。
02.4 当前DPU的问题:成本太高
和功耗一样现在的DPU成本太高了,基于DPU的解决方案变没有降低网络互联的成本。
02.5 当前DPU的问题:应用场景
目前DPU都是面向数据中心的应用场景。但服务器增长空间更多在边缘计算中心,而且未来边缘计算互联将成为网络技术趋势,所以DPU必须考虑边缘计算场景。
下一代数据中心(集群)将以Data Fabric作为支撑,而DPU是这个新Fabric的核心。
为什么芯片会催生新的计算架构
01 DPU和Smart NIC
DPU区别于Smart NIC最显著的特点,DPU本身构建了一个新的网络拓扑,而不是简单的数据处理卸载计算。最开始Fungible就是因为发展了自己的TCP协议,极大的降低了以太网互联的延迟和抖动问题,从而定义了DPU芯片。
DPU和Smart NIC的区别如下:
• DPU可以构建新的协议,Smart NIC一般只是加速协议处理
• DPU可以构建总线拓扑,Smart NIC是一个设备,无法构建新的总线拓扑
• DPU可以作为中心芯片(可以直接控制SSD等设备),而Smart NIC无法直接控制SSD、GPU等
Nvidia对DPU和Smart NIC做了一个非常详细的介绍,但没有到核心架构上。DPU可以脱离host CPU存在,而Smart NIC不行。这个本质的区别就是DPU可以构建自己的总线系统,从而控制和管理其他设备,也就是一个真正意义上的中心芯片,第三颗芯片。这个也是为什么Smart NIC出来这么多年,只有Fungible可以说他们的芯片是DPU!
02 “神奇”的DPU复用
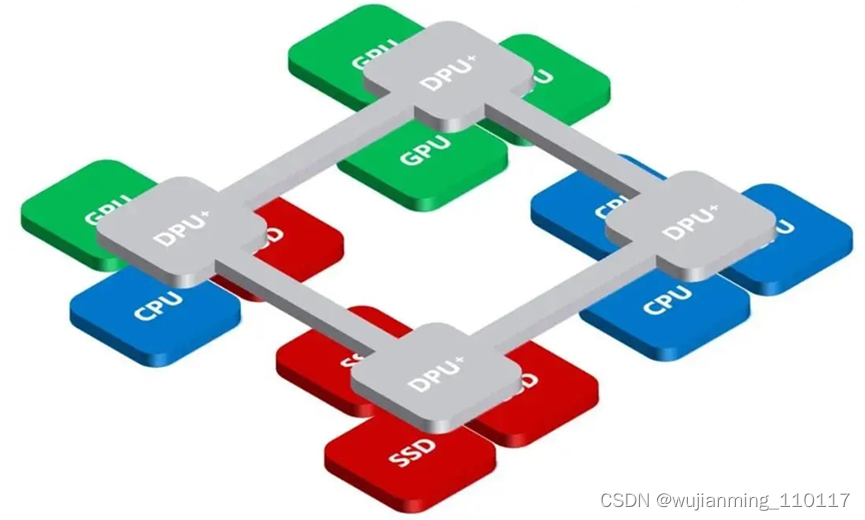
总线是一个非常珍贵的资源,可以做很多事情!Fungible的架构师明显意思到了这一点,做了非常有意思的解决方案。DPU复用!我们见过利用SR-IOV技术在一个服务器中虚拟化多个网卡VF的技术来实现多张网卡的,但很少见到一张网卡被多个服务器使用的?当然回到Fungbile DPU功耗达到120瓦的实际情况下,我们必须多“复用”这个DPU达到降低使用成本的目的。Fungible的架构师还真的就这么干了一个系统。
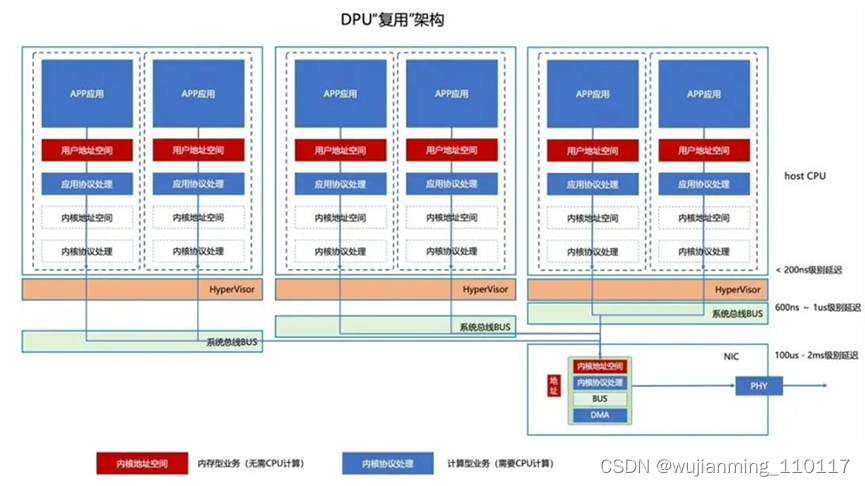
在DPU复用架构中,DPU实际上起到了交换ASIC作用,也就是说DPU可以互联一个小集群。目前Fungible是支持8个,Nvidia的BlueFiled应该也不会超过8个。
03 DPU复用开创的“芯”计算架构
DPU的复用看似是Fungible一个无奈的选择(功耗和成本太高、需要降低TCO),但却创造了一个全新的计算架构。传统的以CPU为中心的计算体系,要让位给DPU为了。未来我们将单独从架构上分析为什么这个趋势是不可避免的。
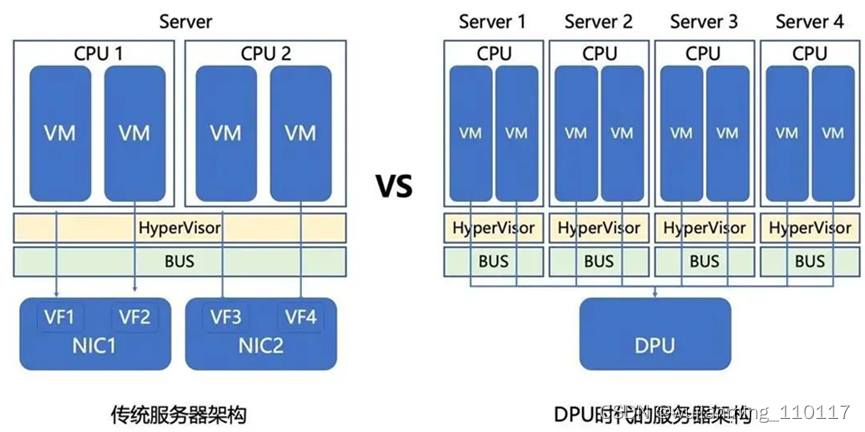
传统服务器架构中,服务器设计以CPU为中心,CPU通过初始化总线树,给每一个设备分配ID,然后所有设备按照总线协议进行协作。网卡通过SR-IOV技术可以通过软硬件协同的方式加速虚拟化环境中的网络性能,这种网络处理方式中,Mellonax的ConnectX性能比较突出。如果需要多路CPU,就通过CPU总线的方式扩展一路、双路、四路、甚至八路CPU加强计算能力。这种架构通用计算能力强悍,但重复计算较多(每个VM都需要处理相似的网络计算),对CPU的开销比较大,成本非常高。这个就是30% Datacenter tax的来源。
在DPU复用架构中,DPU相当于一个网络交换机,互联多个CPU服务器,形成一个计算集群。由于网络协议栈和一些公共计算由DPU提前处理完成,在这个集群中,CPU和CPU通讯减少了很多开销,达到了降低延迟的效果。或者反过来说,就是不需要强大的CPU了。这样可以极大降低8路互联集群的CPU成本,同时增强网络数据处理能力。在云计算领域具备非常明显的竞争优势。所以成为当前技术发展最热门的方向。
04 DPU到底是什么?
目前DPU是没有一个明确的定义的。虽然大家都强调以数据处理为主,但实际上做的都是Smart NIC的事情。同时明显Fungbile的出发是以网络架构为中心,以网络安全为手段的技术路线,本质上是一个L4(协议层)的公司在试图解决L2/L3(Fabric和路由)的问题,而Nvidia是以设备为中心,以GPU数据加速为手段,本质上是一个L1(设备层)的公司在解决L2/L3(Fabric和路由)的问题,两个公司的技术背景和技术路线也存在明显的差别。其他公司就只能算是一个Smart NIC公司了,打着DPU的旗号干加速的事情。
05 DPU的未来
虽然Fungible和Nvidia都意识到了DPU的重要性,时间上具备领先优势,也做出了新架构的解决方案。但Intel发布的IPU进一步强调了在基础架构上数据芯片的重要性,干脆把IaaS模块全部下沉到了DPU上,将这个DPU重新命名为IPU。虽然Intel目前还没有明确表明自己IPU的架构,但可以预见Intel将整合网络、软件平台、总线技术的技术力量。
RDMA技术调研
直接内存访问 (DMA) 是设备无需 CPU 干预即可直接访问主机内存的能力。远程直接内存访问(RDMA)是访问(即读取或写入)远程机器上的内存而不中断该系统 上 CPU处理的能力。
如何配置InfiniBand和RDMA网络?
一、RDMA介绍1.2 RDMA介绍
传统网络中的转发过程:
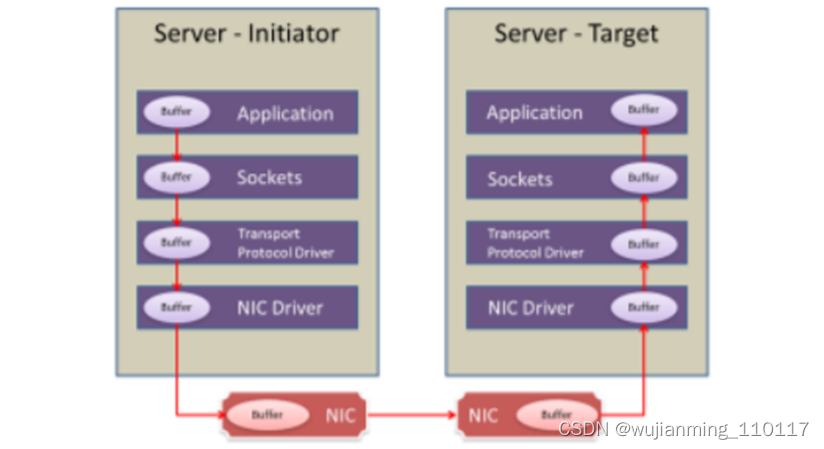
传统网络协议栈的过程下,无论是发送端还是接收端,都需要CPU的指挥和控制,包括 网卡的控制,中断的处理,报文的封装和解析等等。
使用了RDMA技术之后网络的转发过程:
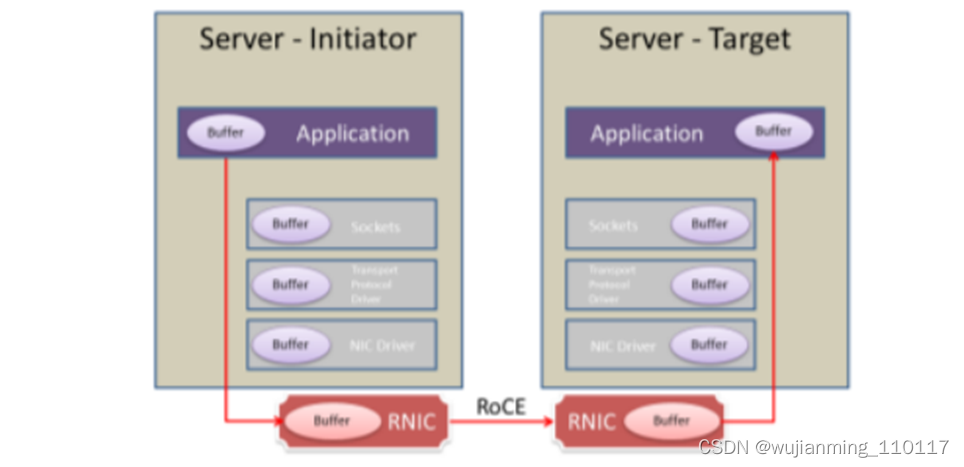
在使用了RDMA技术时,两端的CPU几乎不用参与数据传输过程(只参与控制面)。本端的网卡直接从内存的用户空间DMA拷贝数据到内部存储空间,然后硬件进行各层报文的组装后,通过物理链路发送到对端网卡。对端的RDMA网卡收到数据后,剥离各层报文头和校验码,通过DMA将数据直接拷贝到用户空间内存中。
1.2 RDMA相较于传统网络的核心优势
RDMA是现代高速网络的具体实现方案,现主要用于数据中心内部的存储服务器之间的数据交互,相较于传统网络,主要有三大核心优势∶
• 0拷贝∶应用程序可以在没有网络软件堆栈参与的情况下执行数据传输,并且数据被直接发送到缓冲区,而无需在网络层之间进行复制。
• 内核旁路∶应用程序可以真接从用户空间执行数据传输,而无需执行上下文切换。
• CPU卸载∶应用程序可以访问远程内存而不会消耗远程机器中的任何CPU。远程内存机器将在没有任何远程进程(或处理器)干预的情况下被读取。远程 CPU 中的缓存不会被访问的内存内容填满。
1.3 什么样的业务场景需要用到RDMA
可以在至少需要以下一项的场景中找到RDMA∶
• 低延迟-例如∶ HPC、金融服务、web 3.0
• 高带宽-例如∶HPC、医疗设备、存储和备份系统、云计算
• CPU占用空间小-例如∶ HPC、云计算
1.4 三种RDMA协议介绍
RDMA本身指的是一种技术,具体协议层面,包含Infiniband (IB),RDMA over Converged Ethernet (RoCE)和internet Wide Area RDMA Protocol (WARP)。三种协议都符合RDMA标准,使用相同的上层接口,在不同层次上有一些差别。
• Infiniband:从一开始就原生支持 RDMA 的新一代网络协议。由于这是一项新的网络技术,因此需要支持该技术的网卡和交换机。
• ROCE:一种允许在以太网网络上执行 RDMA 的网络协议。它的下部网络标头是以太网标头,其上部网络标头(包括数据)是 InfiniBand 标头。这允许在标准以太网基础设施(交换机)上使用 RDMA。只有 NIC 应该是特殊的并且支持RoCE。
• iWARP:一种允许通过 TCP执行 RDMA 的网络协议。有些功能存在于IB 和 RoCE 中,但在WARP中不受支持。这允许在标准以太网基础设施(交换机)上使用RDMA。只有NIC 应该是特殊的并支持WARP(如果使用CPU 卸载),否则所有 iWARP 堆栈都可以在SW中实现并失去大部分RDMA性能优势。发展脉络如下图所示:

1.5 如何使用RDMA
为了使用RDMA,需要一个具有 RDMA 功能的网络适配器(例如 Mellanox 的Connect-X 系列网卡)。网络的链路层协议可以是以太网或 InfiniBand——两者都可以传输基于 RDMA 的应用程序。
二、RDMA术语及基本流程介绍2.1 RDMA通信的基本流程
下面我们把CQ和WO(QP)放在一起,看一下一次SEND-RECV操作中,软硬件的互动(图中序号顺序不表示实际时序)∶

简而言之。在通信前,接收端APP需要提前在RQ中准备好接收任务工作区。
发送起始,发送端APP需要向SQ下达SEND任务。接收端收到数据后会第一时间向对方回复ACK,之后生成CO,并通过CO告知APP收到了消息。
发送端也会通过接收对方刚刚生成的ACK,生成CQ,进而通知APP任务完成。
三、RDMA编程方法介绍3.1RDMA编程基本概念介绍通信操作
通信操作
RDMA支持以下4种通信操作
• SEND/RECV SEND操作允许捋数据发送到远程OP的接收队列。接收器之前必须发布了一个接收缓冲区才能接收数据。发送方无法控制数据在远程主机中的所在位置。
• WRITE/READ系统将从远程主机中读取一段内存。调用者指定要复制到的远程虚拟地址以及本地内存地址。在执行RDMA操作之前,元程主机必须提供活当的权限来访问其内存。一目设置了这些权限,就会执行RDMA读取操作,无需发出任何通知到远程主机。对于RDMA的读写操作,远程端都是不知道正在执行此操作的(除了准备权限和资源之外)。
• ATOMIC对RDMA操作的原子扩展。
• SRQ_RECV通过共享RQ的方式,将原先的一个QP中一个SQ对应一个RQ的模式,变成了多个SQ共用一个RO的模式,减少了内存占用。
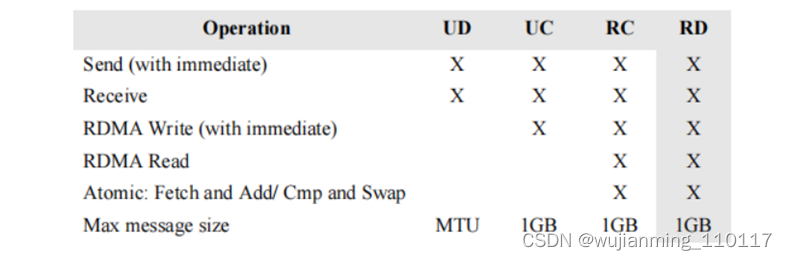
传输模式
• RC可靠连接,类似于TCP
• UC不可靠连接,做了连接,但是没有做重传
• UD不可靠数据报,类似于UDP
几种传输模式和支持的操作如下表所示∶
• DC使用UD的主要优点是单个OP 可以用来与任何其他 OP 对话;而使用 RC 时,需要创建与通信对等点数量一样多的 QP。Mellanox 的最新优化引入了 DCT(动态连接传输),可以很好地解决 OP 可扩展性问题。
关键概念
• Send Request:SR定义了将发送多少数据,从哪里、如何、发送到哪里。
• Receive Request:RR定义了要为非RDMA操作接收数据的缓冲区。如果没有定义缓冲区,并且发送器尝试发送操作或RDMA立即写入,则捋发送接收未准备好(RNR)错误。
• Completion Queue:完成队列是一种通知应用程序关于已结束的工作请求(状态、操作码、大小、来源)信息的机制。
• Memory Registration:内存注册是一种机制,允许应用程序使用虚拟地址来描述一组虚拟连续的内存位置或一组物理上连续的内存位置到网络适配器,作为一个虚拟连续的缓冲器。
• Protection Domain:保护域用于将队列对与内存区域和内存窗口关联起来,作为启用和控制网络适配器对主机系统内存的访问的一种手段。
• Scatter Gather 包含Address∶数据捋从其中收集或分散到的本地数据缓冲区的地址。Size∶将从该地址读取/写入的数据的大小。L_key∶已注册到此缓冲区的先生的本地密钥。
• Polling轮询CO是获取已发布的WR(发送或接收)的详细信息。
主要从RDMA是什么、RDMA通信逻辑以及如何进⾏RDMA编程三个方面初步介绍RDMA技术。
CUDA代码
从一份简单的C++代码开始,然后逐步介绍如何将C++代码转换为CUDA代码,以及对转换前后程序的运行时间进行对比,附详解代码。
- 前言
这是一份简单的CUDA编程入门,主要参考英伟达的官方文档进行学习,本人也是刚开始学习,如有表述错误,还请指出。官方文档链接如下:
https://developer.nvidia.com/blog/even-easier-introduction-cuda/
本文先从一份简单的C++代码开始,然后逐步介绍如何将C++代码转换为CUDA代码,以及对转换前后程序的运行时间进行对比,本文代码放在我的github中,有需要可以自取。
https://github.com/xcyuyuyu/My-First-CUDA-Code
本文所使用的CPU为i7-4790,GPU为GTX 1080,那就开始吧。 - 一份简单的C++代码
首先是一份简单的C++代码,主要的运行函数为add函数,该函数实现功能为30M次的for循环,每次循环进行一次加法。
// add.cpp
#include
#include <math.h>
#include <sys/time.h>
// function to add the elements of two arrays
void add(int n, float *x, float *y)
{
for (int i = 0; i < n; i++)
y[i] = x[i] + y[i];
}
int main(void)
{
int N = 1<<25; // 30M elements
float *x = new float[N];
float *y = new float[N];
// initialize x and y arrays on the host
for (int i = 0; i < N; i++) {
x[i] = 1.0f;
y[i] = 2.0f;
}
struct timeval t1,t2;
double timeuse;
gettimeofday(&t1,NULL);
// Run kernel on 30M elements on the CPU
add(N, x, y);
gettimeofday(&t2,NULL);
timeuse = (t2.tv_sec - t1.tv_sec) + (double)(t2.tv_usec - t1.tv_usec)/1000.0;
std::cout << "add(int, float*, float*) time: " << timeuse << “ms” << std::endl;
// Check for errors (all values should be 3.0f)
float maxError = 0.0f;
for (int i = 0; i < N; i++)
maxError = fmax(maxError, fabs(y[i]-3.0f));
std::cout << "Max error: " << maxError << std::endl;
// Free memory
delete [] x;
delete [] y;
return 0;
}
编译以及运行代码:
g++ add.cpp -o add
./add
不出意外的话,你应该得到下面的结果:

第一行表示add函数的运行时间,第二行表示每个for循环里的计算是否与预期结果一致。
这个简单的C++代码在CPU端运行,运行时间为85ms,接下来介绍如何将主要运算的add函数迁移至GPU端。
3. 把C++代码改成CUDA代码
将C++代码改为CUDA代码,目的是将add函数的计算过程迁移至GPU端,利用GPU的并行性加速运算,需要修改的地方主要有3处:
1.首先需要做的是将add函数变为GPU可运行函数,在CUDA中称为kernel,为此,仅需将变量声明符添加到函数中,告诉 CUDA C++ 编译器这是一个在 GPU 上运行并且可以从 CPU 代码中调用的函数。
global
void add(int n, float x, float y)
{
for (int i = 0; i < n; i++)
y[i] = x[i] + y[i];
}
那么修改后的add函数的调用也比较简单,仅需要在add函数名后面加上三角括号语法<<<i,j>>>指定CUDA内核启动即可,<<<i,j>>>称为执行配置(execution configuration),用于配置程序运行时的线程,后续会讲到,目前先将其设置为<<<i,j>>>:
add<<<1, 1>>>(N, x, y);
2. 那么为了在GPU进行计算,需要在GPU上分配可访问的内存。CUDA中通过Unified Memory(统一内存)机制来提供可同时供GPU和CPU访问的内存,使用cudaMallocManaged()函数进行分配:
cudaMallocManaged(&x, Nsizeof(float));
cudaMallocManaged(&y, Nsizeof(float));
同时,在程序最后使用cudaFree()进行内存释放:
cudaFree(x);
cudaFree(y);
其实就相当于C++中的new跟delete。
3. add函数在GPU端运行之后,CPU需要等待cuda上的代码运行完毕,才能对数据进行读取,因为CUDA内核启动时并未对CPU的线程进行固定,需要使用cudaDeviceSynchronize()函数进行同步。
4. 整体的程序如下所示:
// add.cu
#include
#include <math.h>
// Kernel function to add the elements of two arrays
// global 变量声明符,作用是将add函数变成可以在GPU上运行的函数
// global 函数被称为kernel,
// 在 GPU 上运行的代码通常称为设备代码(device code),而在 CPU 上运行的代码是主机代码(host code)。
global
void add(int n, float *x, float *y)
{
for (int i = 0; i < n; i++)
y[i] = x[i] + y[i];
}
int main(void)
{
int N = 1<<25;
float *x, *y;
// Allocate Unified Memory – accessible from CPU or GPU
// 内存分配,在GPU或者CPU上统一分配内存
cudaMallocManaged(&x, Nsizeof(float));
cudaMallocManaged(&y, Nsizeof(float));
// initialize x and y arrays on the host
for (int i = 0; i < N; i++) {
x[i] = 1.0f;
y[i] = 2.0f;
}
// Run kernel on 1M elements on the GPU
// execution configuration, 执行配置
add<<<1, 1>>>(N, x, y);
// Wait for GPU to finish before accessing on host
// CPU需要等待cuda上的代码运行完毕,才能对数据进行读取
cudaDeviceSynchronize();
// Check for errors (all values should be 3.0f)
float maxError = 0.0f;
for (int i = 0; i < N; i++)
maxError = fmax(maxError, fabs(y[i]-3.0f));
std::cout << "Max error: " << maxError << std::endl;
// Free memory
cudaFree(x);
cudaFree(y);
return 0;
}
使用nvcc对程序进行编译并运行:
nvcc add.cu -o add_cuda
./add_cuda
或者使用nvprof进行速度测试:
nvprof ./add_cuda
不出意外的话,你会得到以下输出:
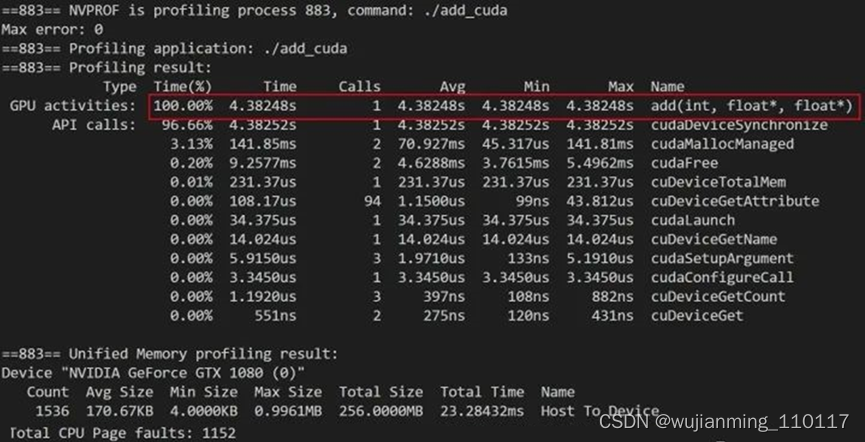
框出来的就是add函数在GPU端的运行时间,为4s。没错,就是比CPU端85ms还要慢,那还学个锤子。
4. 使用CUDA代码并行运算
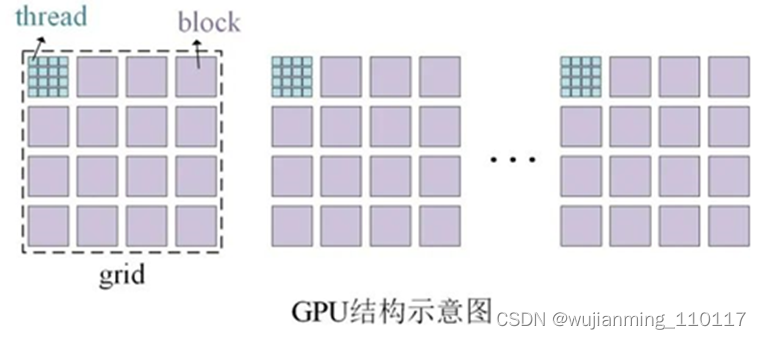
好的回过头看看,问题出现在这个执行配置 <<<i,j>>> 上。不急,先看一下一个简单的GPU结构示意图,按照层次从大到小可将GPU按照 grid -> block -> thread划分,其中最小单元是thread,并行的本质就是将程序的计算模块拆分成多个小模块扔给每个thread并行计算。
再看一下前面执行配置 <<<i,j>>> 的含义,<<<i,j>>> 应该写成 <<<numBlocks, blockSize>>> ,即表示函数运行时使用的block数量以及每个block的大小,前面我们将其设置为<<<1,1>>> ,说明程序是单线程运行的,那当然慢了~~。下面我们以单个block为例,将其改为<<<1,256>>>,add函数也需要适当修改:
global
void add(int n, float *x, float *y)
{
int index = threadIdx.x; // threadIdx.x表示当前在第几个thread上运行
int stride = blockDim.x; // blockDim.x表示每个block的大小
for (int i = index; i < n; i += stride)
y[i] = x[i] + y[i];
}
修改的部分也比较好理解,不赘述了,接下来运行看看结果:
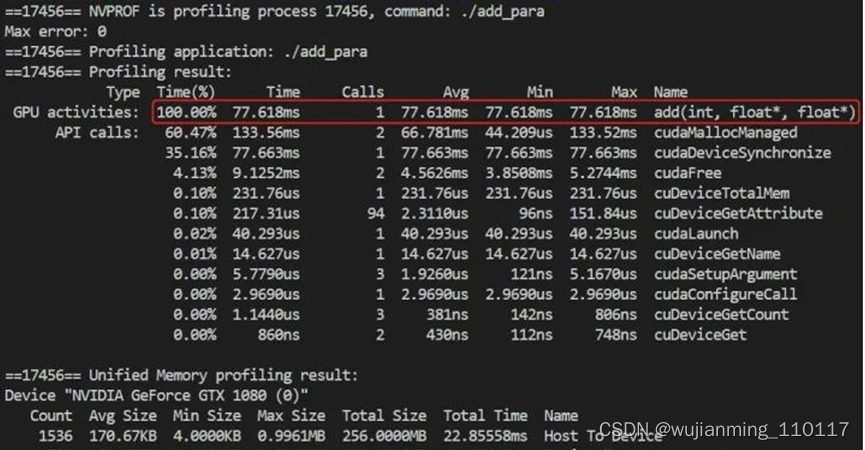
开始加速了,4s加速到了77ms。
那么,<<<numBlocks, blockSize>>> 的两个参数应该怎么设置好呢。首先,CUDA GPU 使用大小为 32 的倍数的线程块运行内核,因此 blockSize 的大小应该设置为32的倍数,例如128、256、512等。确定 blockSize 之后,可以根据for循环的总个数N确定 numBlock 的大小(注意四舍五入的误差):
int numBlock = (N + blockSize - 1) / blockSize;
当然因为变成了多个block,所以此时add函数需要再改一下:
global
void add(int n, float *x, float *y)
{
int index = blockIdx.x * blockDim.x + threadIdx.x;
int stride = blockDim.x * gridDim.x;
for (int i = index; i < n; i+=stride)
y[i] = x[i] + y[i];
}
这里index跟stride的计算可以参考上面GPU结构图以及下面的图(图取自An Even Easier Introduction to CUDA | NVIDIA Technical Blog),自行推算,较好理解。
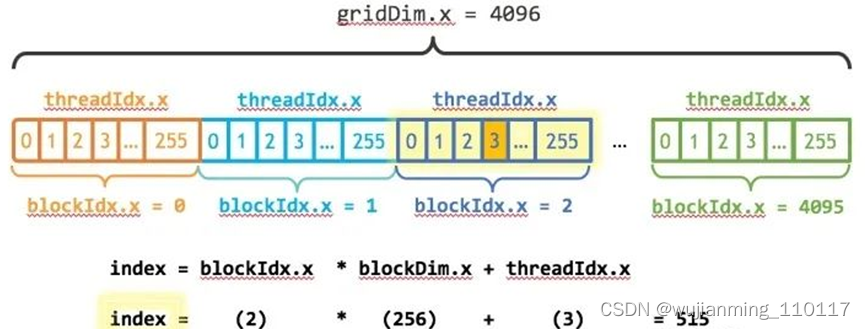
搞定之后再编译运行一下:
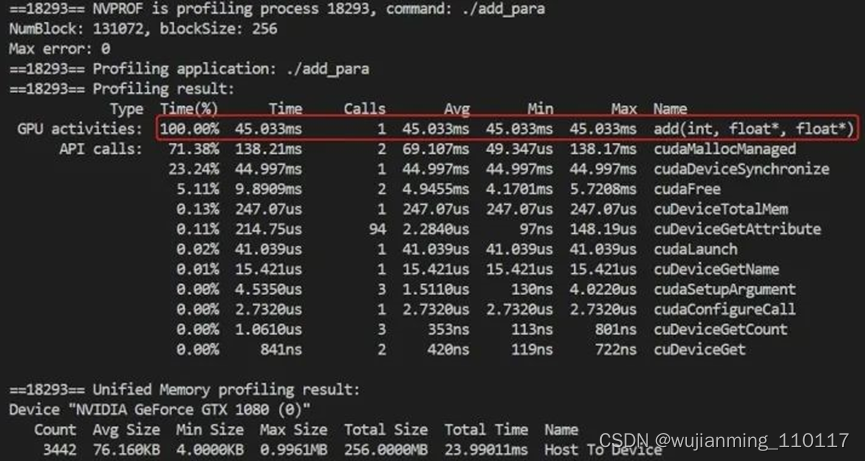
看看,又加速了不是,通过提升并行度而加速,相比于CPU端(85ms)加速了接近一倍左右。
参考文献链接
https://baike.baidu.com/item/DPU/11007035?fr=aladdin
https://baike.baidu.com/item/CUDA/1186262?fr=aladdin
https://baike.baidu.com/item/RDMA/1453093?fr=aladdin
https://mp.weixin.qq.com/s/l_7EYBRRHyAkuh7HmnE1xQ
https://mp.weixin.qq.com/s/ebOyILHjqsomFpfylgNdRw
https://github.com/xcyuyuyu/My-First-CUDA-Code
https://mp.weixin.qq.com/s/zwGdaqkvbc950LeT6ABxYA
https://developer.nvidia.com/blog/even-easier-introduction-cuda/