目录
提示:本文结合B站视频:
一、BERT基础架构
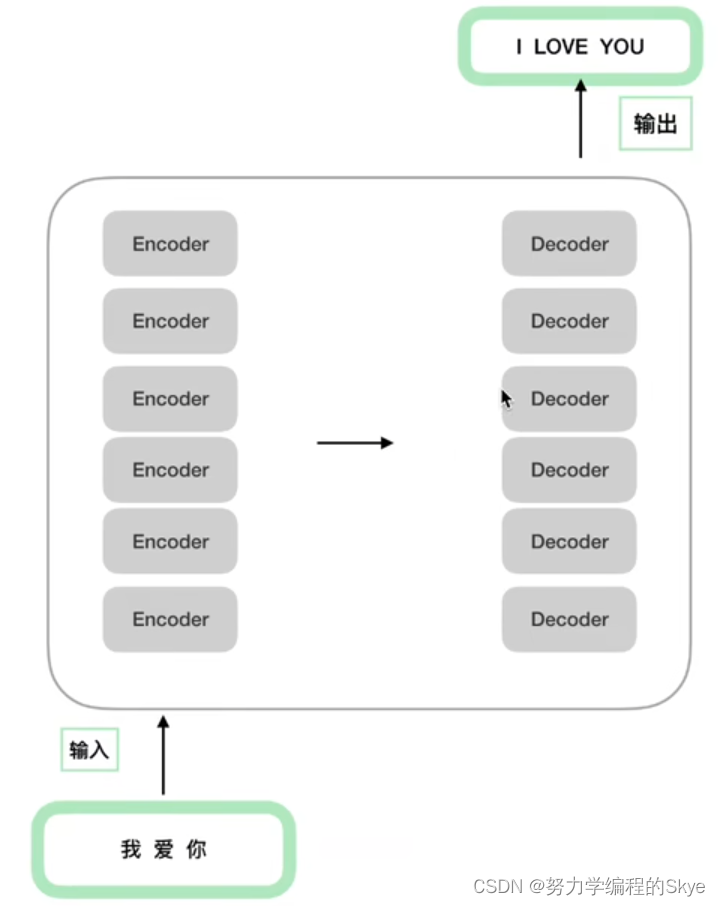
1.Transformer基础架构
首先回顾下Transformer基础架构,由6个Encoder组成的编码端和6个Decoder组成的解码端组成。
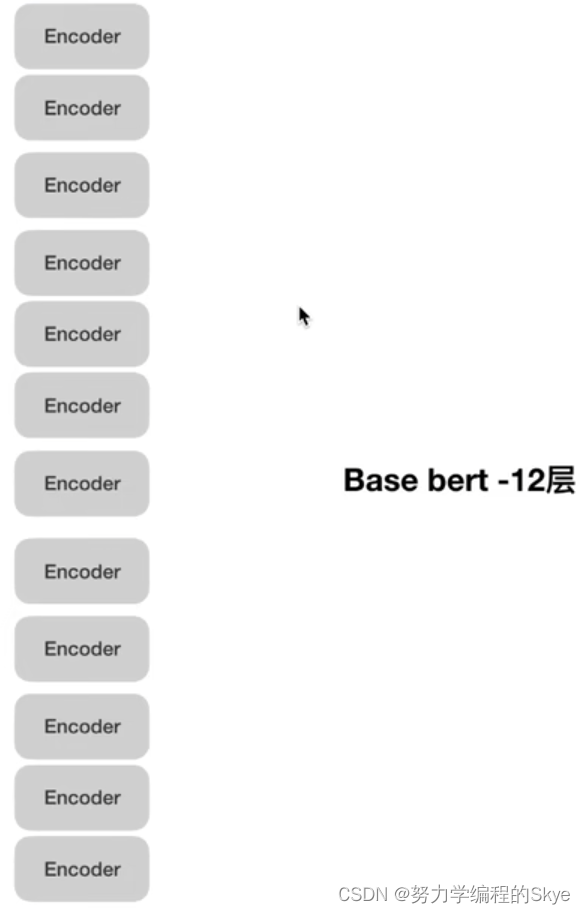
2.BERT基础架构
而基础的Base bert由12个Encoder组成。
下面我们具体看一下BERT中Encoder的架构。

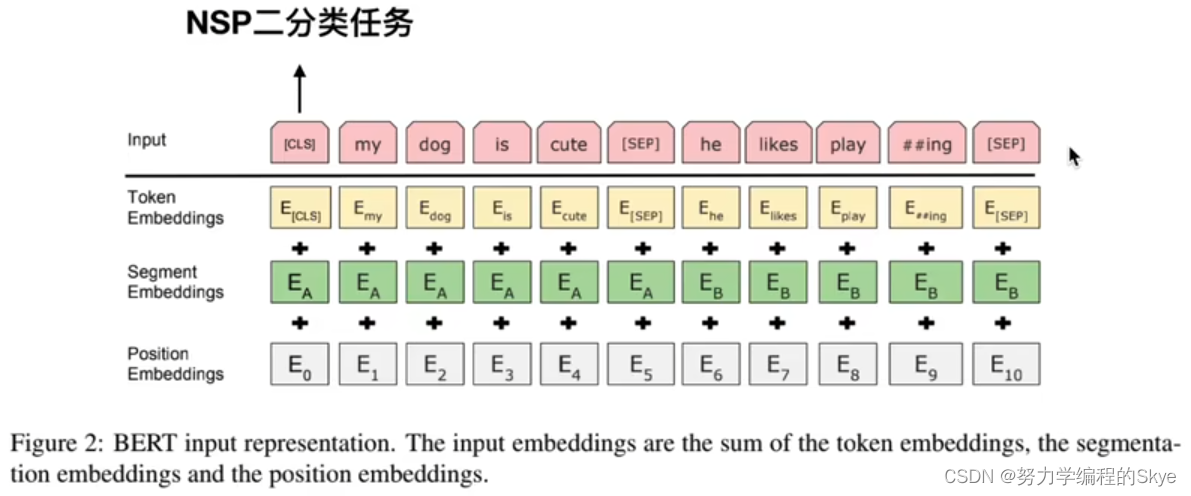
输入
CLS→NSP:Next Setence Prediciton,处理两个句子的关系。
(1)Token Embedding:对输入部分进行正常embedding,如随机初始化;
(2)Segment Embedding:对输入部分两个句子进行区分的embedding;
(3)Position Embedding:随机初始化,没有做正余弦位置编码,而是让模型自己学习每个位置对应的embedding。
二、预训练BERT
(1)MLM : Masked Language Model,打破原有文本,让他文本重建。也存在mask和mask之间存在以来的局限性。

具体代码实现如下:

(2)NSP二分类任务样本选择 : 无效可能是因为主题预测和连贯性预测合并为一个单项任务。
正样本:从训练语料库取出的两个连续的段落;
负样本:从不同文档中随机创建一对段落;
三、微调BERT
微博文本情感分析:
1.在大量通用语料上训练一个LM (Pretrain) 一中文谷歌BERT
⒉在相同领域上继续训练LM(Domain transfer) 一在大量微博文本上继续训练这个BERT
3.在任务相关的小数据上继续训练LM(Task transfer) 一在微博情感文本上(有的文本不属于情感分析的范畴)
4.在任务相关数据上做具体任务(Fine-tune) 。
结果证明:先Domain transfer再进行Task transfer最后Fine-tune 性能是最好的。
如何在相同领域数据中进行进一步的预训练?
1.动态mask:就是每次epoch去训练的时候mask,而不是一直使用同一个
2.n-gram mask:ERNIE和SpanBert都是类似于做了实体词或n-gram的mask
参数设置
