1、应用场景
1.1、实际工作中可能会遇到百万条数据量的Excel表格上传到后台进行解析。
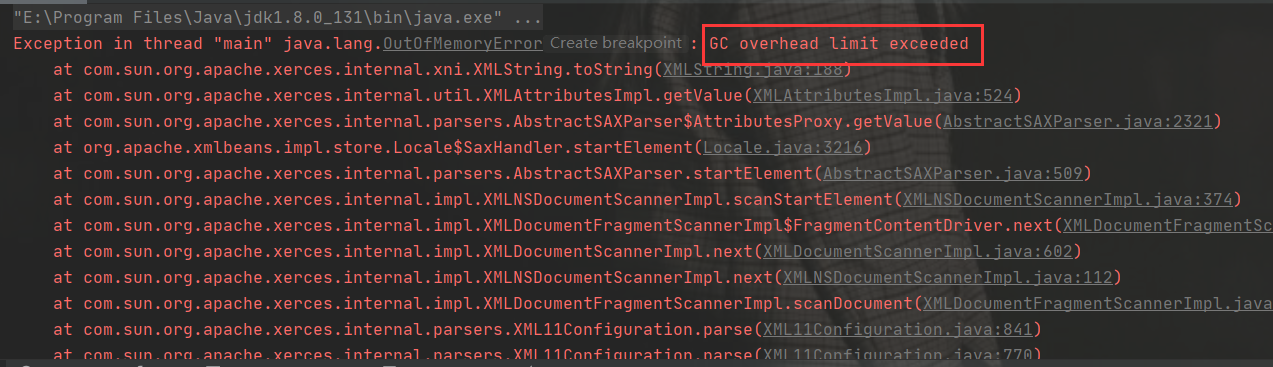
那么传统的POI,它只适用于数据量较小的Excel表格解析,当数据量到一定级别时,后台程序就会报出类似内存溢出的错误
1.2、POI提供了两种读取Excel的模式,分别是
用户模式:也就是poi下的usermodel有关包,它对用户友好,有统一的接口在ss包下,但是它是把整个文件读取到内存中的,对于大量数据很容易内存溢出,所以只能用来处理相对较小量的数据;
事件模式:在poi下的eventusermodel包下,相对来说实现比较复杂,但是它处理速度快,占用内存少,可以用来处理海量的Excel数据。
2、解决方案
2.1、首先业务上将单个大数据量的Excel表拆分成多个Exce文件,进行批量上传。
2.2、后台采用线程池异步处理解析数据以及存储数据
3、具体实现过程
3.1、pom.xml文件引入相关的依赖包
<!-- POI相关的包 -->
<dependency>
<groupId>org.apache.poi</groupId>
<artifactId>ooxml-schemas</artifactId>
<version>1.1</version>
</dependency>
<dependency>
<groupId>fr.opensagres.xdocreport</groupId>
<artifactId>org.apache.poi.xwpf.converter.core</artifactId>
<version>1.0.6</version>
</dependency>
<dependency>
<groupId>org.apache.poi</groupId>
<artifactId>poi-ooxml</artifactId>
<version>3.17</version>
</dependency>
<!-- easyexcel依赖包 -->
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>easyexcel</artifactId>
<version>2.2.7</version>
</dependency>注:此处我将POI相关的包以及EasyExcel的包都引进来了。
3.2、后台Java处理逻辑
logger.info("==============开始导入企业表数据====================userid={},oldOperateId={},type={}",zkjcUser.getId(),oldOperateId,type);
MultipartHttpServletRequest multipartRequest = (MultipartHttpServletRequest) request;
MultipartFile file = multipartRequest.getFile("file");
if(file!=null&&file.getSize()<=0){
log.error("导入失败,"+file.getOriginalFilename()+",文件无内容!");
}
//保存上传文件到本地(异常时查看)
File tempFile=null;
try {
//文件夹不存在则创建
String os = System.getProperty("os.name");
String sbLj="0".equals(type)?operateId:oldOperateId;
String tempath="/temp/resources/upload/";
if(os.toLowerCase().startsWith("win")){
tempath="D:\\temp\\resources\\upload\\";
}
File fdir = new File(tempath);
if (!fdir.exists()) { fdir.mkdirs(); }
tempFile = new File(fdir.getPath()+File.separator+ originalFilename);
file.transferTo(tempFile);
} catch (IllegalStateException e1) {
// TODO Auto-generated catch block
e1.printStackTrace();
} catch (IOException e1) {
// TODO Auto-generated catch block
e1.printStackTrace();
}
String fileName = file.getOriginalFilename();
fileName = fileName.substring(0, fileName.indexOf("."));
try {
long t1 = new Date().getTime();
logger.info("=======================开始解析上传文件===========================");
ExcelParser parse = null;
try {
// InputStream inputStream = file.getInputStream();
InputStream inputStream = new FileInputStream(tempFile);
parse = new ExcelParser().parse(inputStream);
} catch (InvalidFormatException | IOException | ParseException e) {
logger.error("导入失败,解析excel异常:{}",e);
}
List<String[]> datas = parse.getDatas();
if(null==datas ||(null!=datas&&datas.size()<=0)){
logger.error("表格数据内容为空!请检查数据模板是否正确");
}
datas.remove(0);//移除表的字段标题行
long t2 = new Date().getTime();
logger.info("=======================POI解析出("+datas.size()+")条数据,POI解析上传文件耗时("+(t2-t1)+")===========================");
List<List<String[]>> partitionList = ListUtils.partition(datas, 2000);//一个线程处理2千条数据
// 创建一个线程池
ExecutorService exec = Executors.newFixedThreadPool(10);
// 定义一个任务集合
List<Callable<List<ZkjcCompanyError>>> tasks = new ArrayList<>();
Callable<List<ZkjcCompanyError>> task = null;
for (List<String[]> list : partitionList) {
task = new Callable<List<ZkjcCompanyError>>() {
@Override
public List<ZkjcCompanyError> call() throws Exception {
return zkjcCompanyService.saveBatch2(operateId,oldOperateId,list,type);
}
};
// 这里提交的任务容器列表和返回的Future列表存在顺序对应的关系
tasks.add(task);
}
//执行任务
List<ZkjcCompanyError> failList = new ArrayList<>();
try{
List<Future<List<ZkjcCompanyError>>> results = exec.invokeAll(tasks);
for (Future<List<ZkjcCompanyError>> future : results) {
failList.addAll(future.get());
}
//任务执行结束,如果有异常数据,此处会返回封装到failList中,这里可以根据自己的业务做一些处理
}catch (Exception e){
logger.error("线程池执行任务异常:{}",e);
}finally {
// 关闭线程池
exec.shutdown();
}
long t3 = new Date().getTime();
logger.info("====================数据入库总计耗时("+(t3-t2)+")==============================");
} catch (Exception e) {
logger.error("导入表数据操作失败,发现异常:", e);
}3.3、上面核心逻辑处理部分用到的工具类
ExcelParser.java:核心解析工具类
package com.xxx.support.excel;
import java.io.File;
import java.io.FileInputStream;
import java.io.IOException;
import java.io.InputStream;
import java.util.ArrayList;
import java.util.List;
import org.apache.poi.openxml4j.exceptions.InvalidFormatException;
import org.apache.poi.openxml4j.exceptions.OpenXML4JException;
import org.apache.poi.openxml4j.opc.OPCPackage;
import org.apache.poi.xssf.eventusermodel.ReadOnlySharedStringsTable;
import org.apache.poi.xssf.eventusermodel.XSSFReader;
import org.apache.poi.xssf.eventusermodel.XSSFSheetXMLHandler;
import org.apache.poi.xssf.eventusermodel.XSSFSheetXMLHandler.SheetContentsHandler;
import org.apache.poi.xssf.model.StylesTable;
import org.apache.poi.xssf.usermodel.XSSFComment;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.xml.sax.InputSource;
import org.xml.sax.SAXException;
import org.xml.sax.XMLReader;
import org.xml.sax.helpers.XMLReaderFactory;
public class ExcelParser {
private static final Logger logger = LoggerFactory.getLogger(ExcelParser.class);
/**
* 表格默认处理器
*/
private ISheetContentHandler contentHandler = new DefaultSheetHandler();
/**
* 读取数据
*/
private List<String[]> datas = new ArrayList<String[]>();
/**
* 转换表格,默认为转换第一个表格
* @param stream
* @return
* @throws InvalidFormatException
* @throws IOException
* @throws ParseException
*/
public ExcelParser parse(InputStream stream)
throws InvalidFormatException, IOException, ParseException {
return parse(stream, 1);
}
/**
*
* @param stream
* @param sheetId:为要遍历的sheet索引,从1开始
* @return
* @throws InvalidFormatException
* @throws IOException
* @throws ParseException
*/
public synchronized ExcelParser parse(InputStream stream, int sheetId)
throws InvalidFormatException, IOException, ParseException {
// 每次转换前都清空数据
datas.clear();
// 打开表格文件输入流
OPCPackage pkg = OPCPackage.open(stream);
try {
// 创建表阅读器
XSSFReader reader;
try {
reader = new XSSFReader(pkg);
} catch (OpenXML4JException e) {
logger.error("读取表格出错");
throw new ParseException(e.fillInStackTrace());
}
// 转换指定单元表
InputStream shellStream = reader.getSheet("rId" + sheetId);
try {
InputSource sheetSource = new InputSource(shellStream);
StylesTable styles = reader.getStylesTable();
ReadOnlySharedStringsTable strings = new ReadOnlySharedStringsTable(pkg);
getContentHandler().init(datas);// 设置读取出的数据
// 获取转换器
XMLReader parser = getSheetParser(styles, strings);
parser.parse(sheetSource);
} catch (SAXException e) {
logger.error("读取表格出错");
throw new ParseException(e.fillInStackTrace());
} finally {
shellStream.close();
}
} finally {
pkg.close();
}
return this;
}
/**
* 获取表格读取数据,获取数据前,需要先转换数据<br>
* 此方法不会获取第一行数据
*
* @return 表格读取数据
*/
public List<String[]> getDatas() {
return getDatas(true);
}
/**
* 获取表格读取数据,获取数据前,需要先转换数据
*
* @param dropFirstRow
* 删除第一行表头记录
* @return 表格读取数据
*/
public List<String[]> getDatas(boolean dropFirstRow) {
if (dropFirstRow && datas.size() > 0) {
datas.remove(0);// 删除表头title
}
return datas;
}
/**
* 获取读取表格的转换器
*
* @return 读取表格的转换器
* @throws SAXException
* SAX错误
*/
protected XMLReader getSheetParser(StylesTable styles, ReadOnlySharedStringsTable strings) throws SAXException {
XMLReader parser = XMLReaderFactory.createXMLReader();
parser.setContentHandler(new XSSFSheetXMLHandler(styles, strings, getContentHandler(), false));
return parser;
}
public ISheetContentHandler getContentHandler() {
return contentHandler;
}
public void setContentHandler(ISheetContentHandler contentHandler) {
this.contentHandler = contentHandler;
}
/**
* 表格转换错误
*/
public class ParseException extends Exception {
private static final long serialVersionUID = -2451526411018517607L;
public ParseException(Throwable t) {
super("表格转换错误", t);
}
}
public interface ISheetContentHandler extends SheetContentsHandler {
/**
* 设置转换后的数据集,用于存放转换结果
*
* @param datas
* 转换结果
*/
void init(List<String[]> datas);
}
/**
* 默认表格解析handder
*/
class DefaultSheetHandler implements ISheetContentHandler {
/**
* 读取数据
*/
private List<String[]> datas;
private int columsLength;
// 读取行信息
private String[] readRow;
private ArrayList<String> fristRow = new ArrayList<String>();
@Override
public void init(List<String[]> datas) {
this.datas = datas;
// this.columsLength = columsLength;
}
@Override
public void startRow(int rowNum) {
if (rowNum != 0) {
readRow = new String[columsLength];
}
}
@Override
public void endRow(int rowNum) {
//将Excel第一行表头的列数当做数组的长度,要保证后续的行的列数不能超过这个长度,这是个约定。
if (rowNum == 0) {
columsLength = fristRow.size();
readRow = fristRow.toArray(new String[fristRow.size()]);
}else {
readRow = fristRow.toArray(new String[columsLength]);
}
datas.add(readRow.clone());
readRow = null;
fristRow.clear();
}
@Override
public void cell(String cellReference, String formattedValue, XSSFComment comment) {
int index = getCellIndex(cellReference);//转换A1,B1,C1等表格位置为真实索引位置
try {
fristRow.set(index, formattedValue);
} catch (IndexOutOfBoundsException e) {
int size = fristRow.size();
for (int i = index - size+1;i>0;i--){
fristRow.add(null);
}
fristRow.set(index,formattedValue);
}
}
@Override
public void headerFooter(String text, boolean isHeader, String tagName) {
}
/**
* 转换表格引用为列编号
*
* @param cellReference
* 列引用
* @return 表格列位置,从0开始算
*/
public int getCellIndex(String cellReference) {
String ref = cellReference.replaceAll("\\d+", "");
int num = 0;
int result = 0;
for (int i = 0; i < ref.length(); i++) {
char ch = cellReference.charAt(ref.length() - i - 1);
num = (int) (ch - 'A' + 1);
num *= Math.pow(26, i);
result += num;
}
return result - 1;
}
}
public static void main(String[] args) {
ExcelParser parse = null;
File file=new File("E:\\test\\logs\\aa.xlsx");
try {
InputStream inputStream = new FileInputStream(file);
parse = new ExcelParser().parse(inputStream);
} catch (InvalidFormatException | IOException | ParseException e) {
logger.error("上传数据POI解析异常:{}",e);
}
List<String[]> datas = parse.getDatas();
System.out.println(datas.size());
for (String[] strings : datas) {
System.out.println(strings);
}
}
}
ListUtils.java 分割集合List的工具类可以在我的另一篇博文中查看
Java 分割集合工具类![]() https://blog.csdn.net/weixin_36754290/article/details/123642486
https://blog.csdn.net/weixin_36754290/article/details/123642486
目录
1.1、实际工作中可能会遇到百万条数据量的Excel表格上传到后台进行解析。
2.1、首先业务上将单个大数据量的Excel表拆分成多个Exce文件,进行批量上传。
如有错误或者需要指正的地儿可以在评论区留言或者私信小编,小编定会第一时间给予答复。