多表查询核心
- 数据关联
- 左右连接
- 数据分组 (分组统计、统计函数、多字段分组)
- 分组数据的过滤(having)
- 子查询(以上的综合)
本篇文章将根据以上五点进行SQL多表查询的详细解释,包含有语法、案例、思路、分析、测试
数据关联
概念:
多表查询,即在多张表中查询需要的信息,但是直接查询的话会产生笛卡尔积,会造成数据量及其庞大
简单说明笛卡尔积:
两个表的数据量(行数)相乘 这里是14×4 为56行数据
如下图:


解决:
利用关联字段来进行数据的多表查询,关联字段是根据数据来关联的 并不是字段名称
注意:
多表查询之前,首先必须查询各个表中的数据量,这个操作可以通过COUNT()函数来完成。
#查询emp表中的数据量
select count(*) from emp;
#查询dept表中的数据量
select count(*) from dept;
具体举例说明:
按照上面的思路 你可能会这样写关联字段
select * from emp,dept where deptno=deptno;
这样当然是错误的,因为数据库系统并不能自动识别deptno是数据哪个表的
正确的语法是这样的
select * from emp,dept where emp.deptno=dept.deptno;

查询出来的信息中并没有40部门的原因是 这样写的关联字段是根据=前的表来进行关联的,即emp表中没有40部门
如下图:
注:
根据需求来调整显示的关联关系 用左右连接 下面会讲到

如果表的名称比较长,那么这样的方式很不方便使用,解决办法就是使用表别名,如下:
注意语法 在查询的表名后面空格写别名
select * from emp e,dept d where e.deptno=d.deptno;效果跟上面的一样
注意:
这个别名只是对当前sql有效
练习案例:
- 查询每一位雇员的编号,姓名,职位,部门名称,部门位置
思路:
1、首先确认需要的表;
emp表可以查询雇员的编号,姓名,职位;
dept表可以查询部门名称和位置;
2、确定表的关联字段;
emp.deptno=dept.deptno
做法:
1、查询出每一位雇员的编号,姓名和职位;
select e.empno,e.ename,e.job from emp e;
2、为查询中引入部门表,同时增加消除笛卡儿积的条件;
select e.empno,e.ename,e.job,d.dname,d.loc
from emp e,dept d
where e.deptno=d.deptno;
- 查询出每一位雇员的姓名,职位和领导姓名
思路:
1、确认需要的表;
emp表可以查询雇员的姓名,职位和领导编号
emp表可以查询领导的姓名
2、确定关联字段;
emp.mgr=emp.empno,雇员的领导编号=领导的雇员编号 要
做法:
1、查询每一位雇员的姓名和职位
select e.ename,e.job from emp e;
2、查询领导信息,加入自身关联
select e.ename,e.job,m.ename
from emp e,emp m
where e.mgr=m.empno; 根据领导的编号来决定雇员的编号,所以要把mgr写在前面
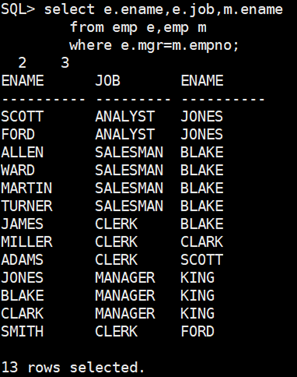
注意:查询结果少了一行,缺少KING的领导姓名,因为他没有领导,后面左右链接解释。KING是没有领导的
- 查询出每个雇员的编号,姓名,基本工资,职位,领导的姓名,部门名称及位置
思路:
1、确认需要的表;
emp表查询每个雇员的编号,姓名,基本工资,职位
emp表查询领导的姓名
dept表查询部门的名称及位置
2、确定已知的关联字段
雇员和部门: e.deptno=d.deptno
雇员和领导: e.mgr=m.empno
做法:
1、查询出每个雇员的编号,姓名,基本工资,职位
select empno,ename,sal,job from emp;
2、加入领导的信息,引入自身关联,同时增加消除笛卡儿积的条件
select e.empno,e.ename,e.sal,e.job,m.ename
from emp e,emp m
where e.mgr=m.empno;
3、加入部门的信息,引入dept表,有新表,则要继续加入消除笛卡儿积的条件
select e.empno,e.ename,e.sal,e.job,m.ename,d.dname,d.loc
from emp e,emp m,dept d
where e.mgr=m.empno 这里更上一个案例的描述相同
and e.deptno=d.deptno; 要根据员工的部门编号去关联部门的表是因为题中要查询的是员工的部门名称与位置
注意:
要分清楚关联条件 即=左边的才是基数据(要查询的数据)根据左边来关联右边,这及其关键,要不然会造成查询的数据有很大的出入

- 查询出每一个雇员的编号,姓名,工资,领导的姓名,部门名称及位置,工资所在公司的工资等级
此案例请自己试着做一下 跟上一个案例其实差不多
思路:

关联:
表1与表2 e.mgr=m.empno 以前面的为主导 即 以领导的数量为筛选因素(表1为主导)
表1与表3 e.deptno=m.deptno 以前面的为主导 即 以表1的前提为筛选因素
表1与表4 ((e.sal>s.losal) and (e.sal<s.hisal)) 以前面的为主导 即 以表1的前提为筛选因素
select e.empno,e.ename,e.sal,m.ename,d.dname,d.loc,s.grade
from emp e,emp m,dept d,salgrade s
where e.mgr=m.empno and e.deptno=m.deptno and ((e.sal>s.losal) and (e.sal<s.hisal));
工资等级也可以用以下语句
(e.sal between s.losal and s.hisal)

左右连接
说明:左右连接可以改变查询判断条件的参考方向
举例:
select * from emp e,dept d where e.deptno=d.deptno;
注意:一共有四个部门,但是这里只有三个,缺少40部门的部门信息,原因就是现在的查询以emp表为参考进行查询,要想显示40部门,就必须改变参考的方向,这时就需要左右连接
用法:
select * from emp e,dept d where e.deptno(+)=d.deptno;

分析:
此时虽然有部门40 的数据 但是并没有意义,因为没有那个员工是属于部门40 的
(+)用于左右连接的更改,这种符号有以下两种使用情况:
(+)=:表示右连接
=(+):表示左连接
不用刻意区分左还是右,根据查询结果来定,如果发现有些需要的数据没有显示出来,就使用此符号来改变连接方向,该符号为oracle独有。
之前的查询领导姓名的范例:
select e.ename,e.job,m.ename from emp e,emp m
where e.mgr=m.empno(+);

分析:
因为用的是左连接,则可以查出来king这个人的职位 但是他没有上司 因为他就是总裁
总结:
要根据具体情况来具体分析该不该使用左右来连接
统计函数
分类:
-
COUNT():查询表中的数据记录
-
AVG(): 求出平均值
-
SUM(): 求和
-
MAX(): 求出最大值
-
MIN(): 求出最小值
分组统计
什么情况下需要分组统计?
1、男的分一组,女的分一组
2、年龄分组,成年和未成年
3、地区分组,上海和北京,
这些信息如果都保存在数据库中,肯定在数据库的某一列上存在重复数据,例如按照性别分组的时候,有男和女,按照年龄分组,有一个范围的重复,按照地区的话有一个地区的信息重复
注意:当数据重复的时候分组才有意义,一个人也可以单独分一组,但是没有意义。
如果需要分组,可以使用GROUP BY子句,语法如下:
SELECT [DISTINCT]*| 字段 [别名][字段 [别名]] | 统计函数
FROM 表名称 [别名],[表名称 [别名],...]
[WHERE 条件(s)]
[GROUP BY 分组字段1 [,分组字段2,...]]
[ORDER BY 排序字段 [ASC|DESC][排序字段 [ASC|DESC],...]]
下面根据案例来进行语法的熟悉:
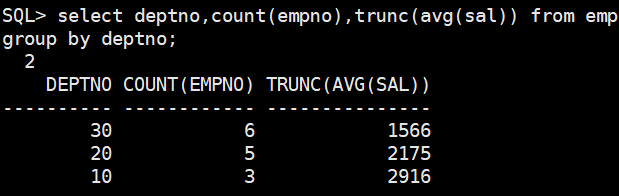
- 按照部门编号分组,求出每个部门的人数和平均工资
分析:
要查的数据在emp表中 from emp
要查的内容是 count(empno)avg(sal)
按照编号分组 group by deptno
select deptno,count(empno),avg(sal) from emp

由于工资一般都是向下取整的,所以优化一下这个语句
select deptno,count(empno),trunc(avg(sal)) from emp
group by deptno;
- 按照职位分组,求出每个职位的最高和最低工资
分析:
要查的表在emp from emp
要查的数据是 max(sal) min(sal)
分组的数据是职位 group by job
Select job,max(sal),min(sal)
from emp
group by job;

注意:分组函数有以下要求:
1、分组函数可以在没有分组的时候单独使用,可是不能出现其他的查询字段,如:
正确使用:select count(empno) from emp;
错误使用,出现其他字段:select empno,count(empno) from emp;
错误的原因显而易见,empno是一个多行单列的数据,而count()函数统计出来的是一个单行单列的数据
2、如果要进行分组,则select子句之后,只能出现分组的字段和统计函数,其他字段不能出现,如:
正确使用:select job,count(empno),avg(sal) from emp group by job;
错误用法:select empno,job,count(empno),avg(sal) from emp group by job;
错误的原因显而易见,即select后的empno是多行单列的数据,而count()与avg()求的是一个单行单列的数据
3、分组函数允许嵌套,但是嵌套之后的分组函数的查询之中不能再出现任何的其他字段,如:
按照职位分组,统计平均工资最高的工资
先统计出各个职位的平均工资
select job,avg(sal) from emp group by job;
查询平均工资最高的工资
错误使用:select job,max(avg(sal)) from emp group by job;
错误的原因显而易见,即select后的job是多行单列的数据, 而最大的平均工资是一个数据段
正确使用:select max(avg(sal)) from emp group by job;
强化案例:
- 查询出每个部门的名称,部门的人数,平均工资
思路:
1.要查的数据有两个表 dept的dname emp表中的count(empno) avg(sal)
2.分组的依据是部门的名称 group by dname
3.因为有两张表 则要进行数据关联 dept的deptno=emp的deptno 当然这里是根据第二表的来进行查询的,即要有40部门(虽然并没有雇员在40部门工作) 所以 在等号的右边写上(+)表示左连接
select d.dname, count(e.empno),avg(e.sal)
from dept d,emp e
where d.deptno=e.deptno(+)
group by d.dname;

优化:
1.字段的显示 利用别名
2.operations的平均工资栏目为空 将其利用NVL函数改为0
select d.dname,count(e.empno) total_people,trunc(nvl(avg(e.sal),0)) avg_sal
from dept d,emp e
where d.deptno=e.deptno(+)
group by d.dname;

多字段分组
案例:
- 要求显示每个部门的编号,名称,位置,部门的人数和平均工资
思路:
1、确定所需要的数据表
dept表:每个部门的编号,名称,位置
emp表:统计出部门的人数,平均工资
2、分组的依据是部门的编号 部门的名称 部门的位置
如何找到分组的依据?
在需要查找的数据中找到重复的数据 以上数据中除了部门人数与平均工资外都是重复项 所以分组的依据都是他们
做法:
1.由于存在两张表,则有数据关联 根据部门的编号来确定总人数与平均工资,所以是左连接
dept的deptno=emp的deptno(+);
2.将多个分组依据用逗号隔开
语句:
select d.deptno,d.dname,d.loc,count(e.empno),avg(e.sal) avg
from dept d,emp e
where d.deptno=e.deptno(+)
group by d.deptno,d.dname,d.loc;

优化:
- 字段名
- 平均工资的余数
- 40部门没有平均工资栏
select d.deptno,d.dname,d.loc,count(e.empno) total_people,trunc(nvl(avg(e.sal),0)) avg_sal
from dept d,emp e
where d.deptno=e.deptno(+)
group by d.deptno,d.dname,d.loc;

完美~
总结:
是分组查询,不管是单字段还是多字段,一定要有一个前提就是存在了重复数据。
扩展:
- 在上个案例的基础上,要求统计出每个部门的详细信息,并且要求这些部门的平均工资高于2000
思路:
在where中添加条件
select d.deptno,d.dname,d.loc,count(e.empno) mycount,trunc(nvl(avg(e.sal),0)) myavg
from dept d,emp e
where d.deptno=e.deptno(+) and avg(e.sal)>2000
group by d.deptno,d.dname,d.loc;

可见,出现错误
ERROR at line 3:
ORA-00934: group function is not allowed here
意思是说在where子句中不能使用统计函数,这和where子句的功能有关。
引申出来
对分组数据过滤(having)
如果要对分组后的数据再次进行过滤,需要使用HAVING子句,语法格式如下:
SELECT [DISTINCT]*| 字段 [别名][字段 [别名]] | 统计函数
FROM 表名称 [别名],[表名称 [别名],...]
[WHERE 条件(s)]
[GROUP BY 分组字段1 [,分组字段2,...]]
[HAVING 分组后的过滤条件(可以使用分组函数)]
[ORDER BY 排序字段 [ASC|DESC][排序字段 [ASC|DESC],...]]
使用HAVING进行过滤
select d.deptno,d.dname,d.loc,count(e.empno) total_people,trunc(nvl(avg(e.sal),0)) avg_sal
from dept d,emp e
where d.deptno=e.deptno(+)
group by d.deptno,d.dname,d.loc
having avg(sal)>2000;

请务必理解下面的话
注意:
WHERE和HAVING的区别
WHERE:在执行GROUP BY操作之前进行的过滤,表示从全部数据中进行过滤,不能使用统计函数;
HAVING: 在GROUP BY分组之后的再次过滤,可以使用统计函数。
子查询(核心重点)
定义:
子查询=简单查询+限定查询+多表查询+统计查询的综合体
之前说多表查询不建议使用,因为性能差,但是多表查询最有利的替代者就是子查询,在实际的开发中使用最多的就是子查询。
语法:
SELECT [DISTINCT]*| 字段 [别名][字段 [别名]] | 统计函数,(
SELECT [DISTINCT]*| 字段 [别名][字段 [别名]] | 统计函数
FROM 表名称 [别名],[表名称 [别名],...]
[WHERE 条件(s)]
[GROUP BY 分组字段1 [,分组字段2,...]]
[ORDER BY 排序字段 [ASC|DESC][排序字段 [ASC|DESC],...]])
FROM 表名称 [别名],[表名称 [别名],...],(
SELECT [DISTINCT]*| 字段 [别名][字段 [别名]] | 统计函数
FROM 表名称 [别名],[表名称 [别名],...]
[WHERE 条件(s)]
[GROUP BY 分组字段1 [,分组字段2,...]]
[ORDER BY 排序字段 [ASC|DESC][排序字段 [ASC|DESC],...]])
[WHERE 条件(s)](
SELECT [DISTINCT]*| 字段 [别名][字段 [别名]] | 统计函数
FROM 表名称 [别名],[表名称 [别名],...]
[WHERE 条件(s)]
[GROUP BY 分组字段1 [,分组字段2,...]]
[ORDER BY 排序字段 [ASC|DESC][排序字段 [ASC|DESC],...]])
[GROUP BY 分组字段1 [,分组字段2,...]]
[HAVING 分组后的过滤条件(可以使用统计函数)]
[ORDER BY 排序字段 [ASC|DESC][排序字段 [ASC|DESC],...]]
WHERE:子查询一般只返回单行单列,多行单列,单行多列的数据
FROM:子查询返回的一般是多行多列的数据,当作一张临时表出现。
具体举例:
情况1 子查询出来的数据是单行单列
- 要求查出工资比SMITH还要高的全部信息
思路:
1、首先要知道SMITH的工资是多少
select sal from emp where ename='SMITH';
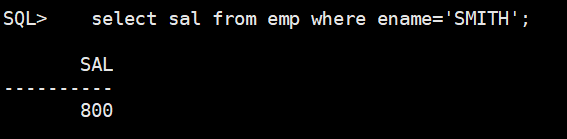
2、由于此时返回的是单行单列的数据,所以这个子查询可以在WHERE中出现
select * from emp where sal>(
select sal
from emp
where ename='SMITH');

- 要求查询出高于公司平均工资的全部雇员信息
思路:
1.先查出公司的平均工资
Select avg(sal) from emp;

2.单行单列数据,则可以用where的子查询
Select * from emp where sal>(
Select avg(sal)
from emp);

情况2 子查询出来的数据是单行多列
以上返回的是单行单列,但是在子查询中,也可以返回单行多列的数据,只是这种子查询很少出现,如:
select * from emp where(job,sal)=(
select job,sal
from emp
where ename='ALLEN');
子查询是单行多列

利用这个来匹配 job,sal等于这个的 这样做的话 你仔细想想 其实没啥用

情况3子查询出来的数据是多行单列
需要使用三种判断符来进行判断:IN,ANY,ALL
下面将分三点详细解释
1、IN操作符:用于指定一个子查询的判断范围
- 查询manager的工资 用子查询方法做
a.查出来manager的表
select sal
from emp
where job='MANAGER';

b.查询sal属于这个个子查询的表中的全部数据
select * from emp
where sal in(
from emp
where job='MANAGER');

注意:
在使用IN的时候还要注意NOT IN的问题,如果使用NOT IN操作,在子查询中,如果有一个内容是NULL,则不会有任何查询结果,因为如果有NULL,则会查询所有数据,如果数据量太大就会导致有漏洞产生,所以加入限制。
举例:
- 查询工资不是manager的工资的全部数据 用子查询方法
select * from emp
where sal not in(
select sal
from emp
where job='MANAGER');

2、ANY操作符,与每一个内容相匹配,有三种匹配形式
1、=ANY:功能与IN操作符是完全一样;
select * from emp
where sal=any(
select sal
from emp
where job='MANAGER');
2、>ANY:比子查询中返回记录最小的还要大的数据
select * from emp
where sal>any(
select sal
from emp
where job='MANAGER');
3、<any:比子查询中返回记录的最大值还要小的
select * from emp
where sal<any(
select sal
from emp
where job='MANAGER');
3、ALL操作符:与每一个内容相匹配,有两种形式
1、>ALL:比子查询结果中最大值还大
select * from emp
where sal>all(
select sal
from emp
where job='MANAGER');
2、<ALL:比子查询结果中最小值还小
select * from emp
where sal<all(
select sal
from emp
where job='MANAGER');
对于子查询出来的数据是多行多列的情况 用From语句
- 查询出每个部门的编号,名称,位置和部门人数,平均工资
思路:
- 查询的数据有 emp表的count(empno) avg(sal) dmpt表的 deptno dname loc
- 关联字段是dmpt的deptno=emp的deptno 注意这里为左连接即以部门的编号为主导,则会出现40部门无人员信息 跟上面的案例一样
- 分组依据为 dmpt表的deptno dname loc
select d.deptno,d.dname,d.loc,count(e.empno),avg(e.sal)
from emp e,dept d
where d.deptno=e.deptno(+)
group by d.deptno,d.dname,d.loc;

下面使用子查询来完成,所有的统计查询只能在GROUP BY中出现,所以在子查询之中负责统计数据,而在外部的查询之中,负责将统计数据和dept表数据相统一。
子查询:
select deptno,count(empno) count,avg(sal) avg
from emp
group by deptno;

select d.deptno,d.dname,d.loc,nvl(temp.count,0),nvl(temp.avg,0)
from dept d,(
select deptno,count(empno) count,avg(sal) avg
from emp
group by deptno) temp
where d.deptno=temp.deptno(+);

总结:
在开发中,使用子查询可以提高效率和节省性能,大部分情况下:如果最终查询结果中出现了select语句,但是又不能直接使用统计函数时,就在子查询中统计信息。
