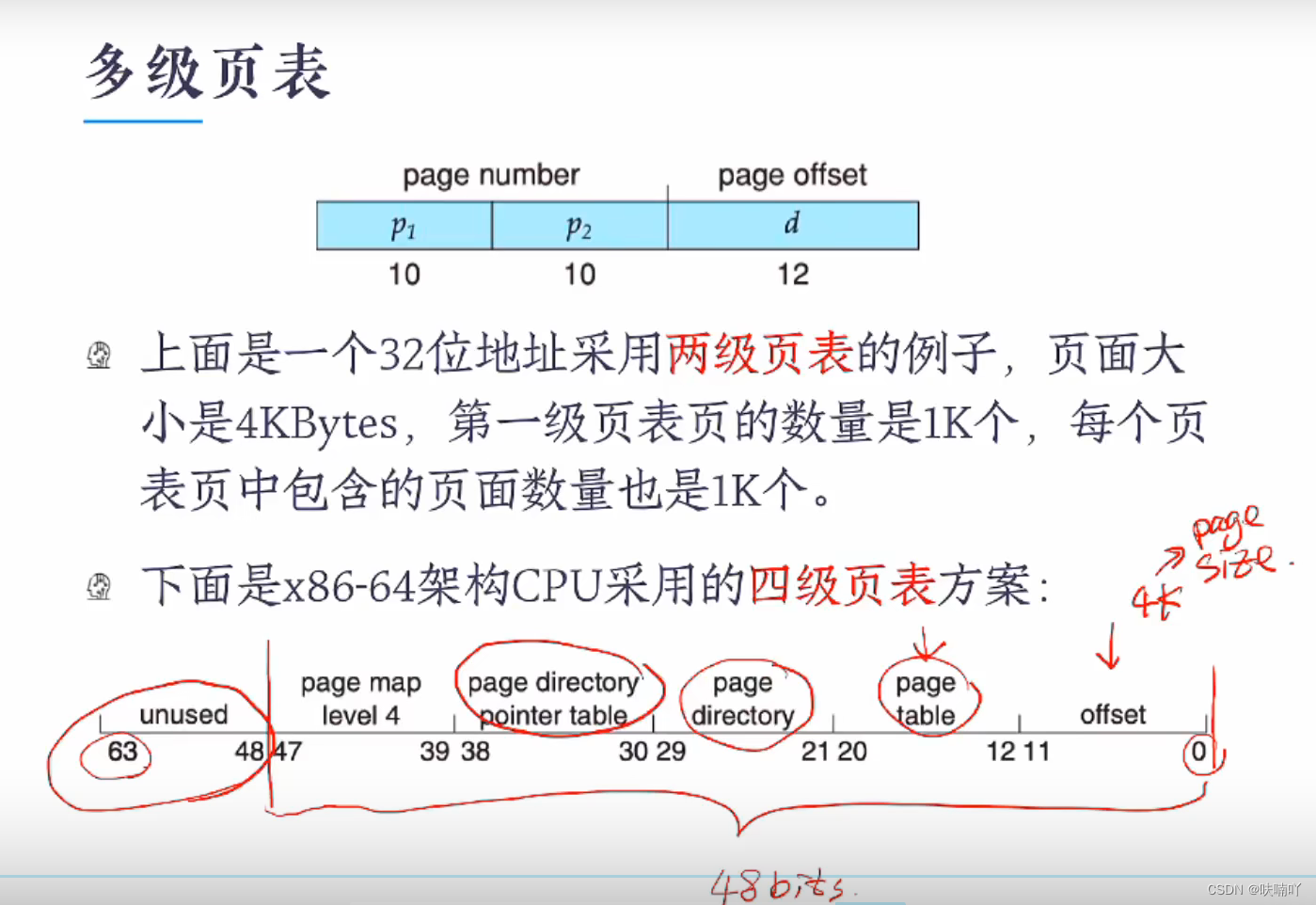
页表
为什么说分页的逻辑地址是一维的地址;
从下图我们可以看出,把一个程序分为等大的页面(这里每个页面大小假设4bytes),每一个页面的里的指令(假设每条指令大小为1bytes)都会有相对应的逻辑地址,都是从0开始算起的;
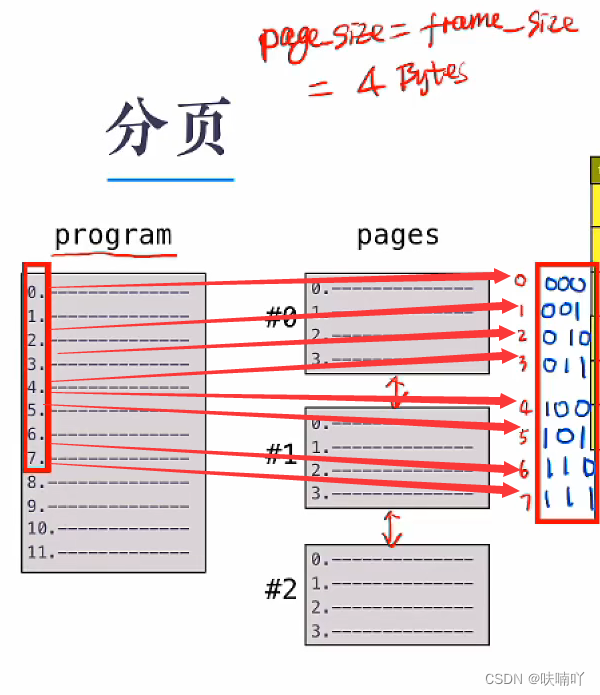
页表记录的主要信息就是:页框号和页面号的映射关系,页框号也就是物理地址,页面号也是逻辑地址的一部分;
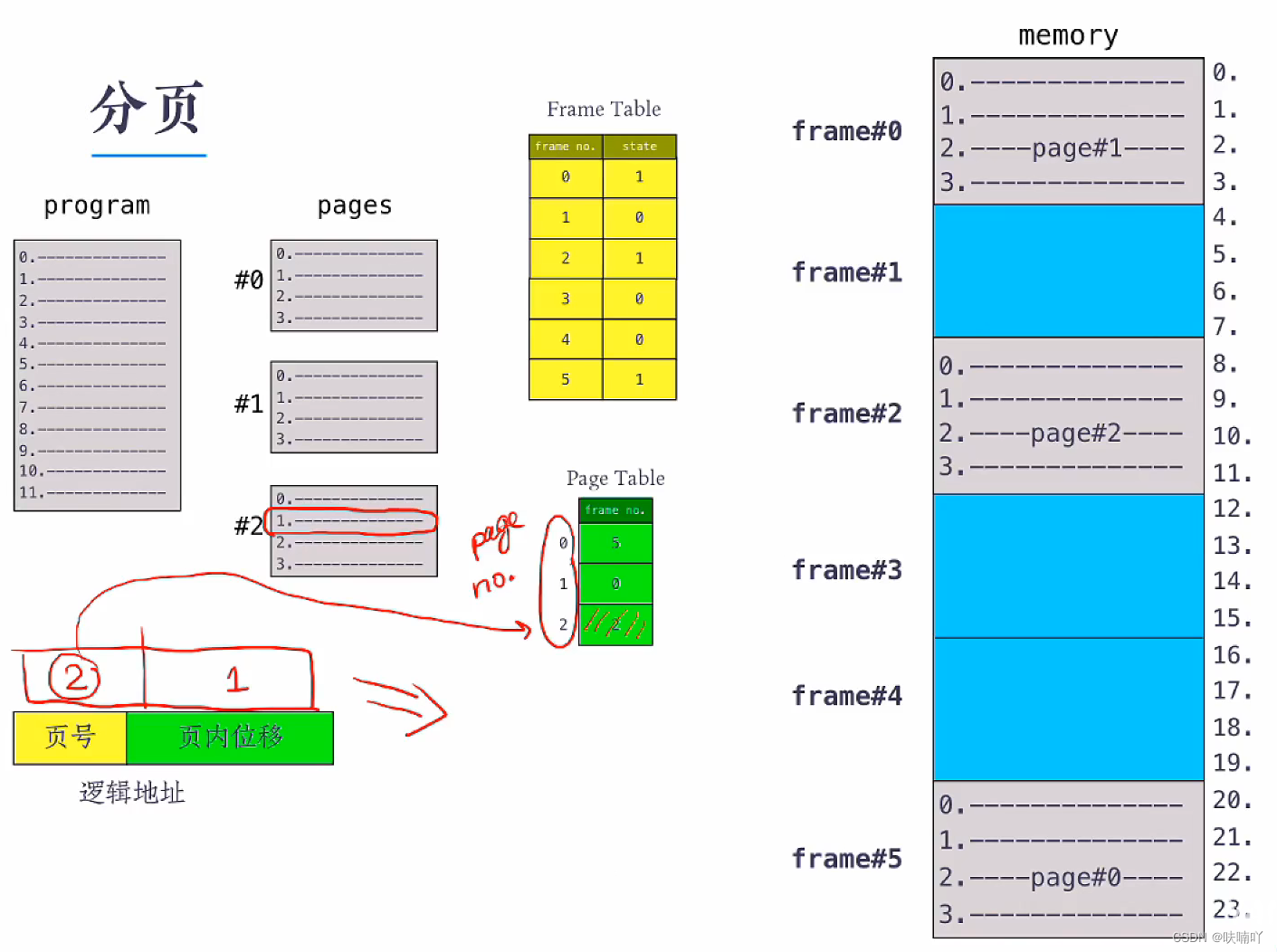
上面的例子中:把程序分为了3个页面的大小,放入到内存中,其中#0页面放入到了frame#5 也框中,#2页面放入到 frame#2页框中,#1放入到frame#0页框中;
至于是页面是如何放入到页框的,其实页框是也是有自己一份表,该表记录着页框是否呗占用的情况,只要放页面去页框前去查找页框表,发现没有被占用的页框,那么就会把页面放入进去;
由于程序的地址,被分成页面放入到页框中,并不是连续存放的,所以我们需要找到程序的真实物理地址,需要一个页表,来记录页框和页面的映射,方便我们找到真实的物理地址空间;
页面的大小
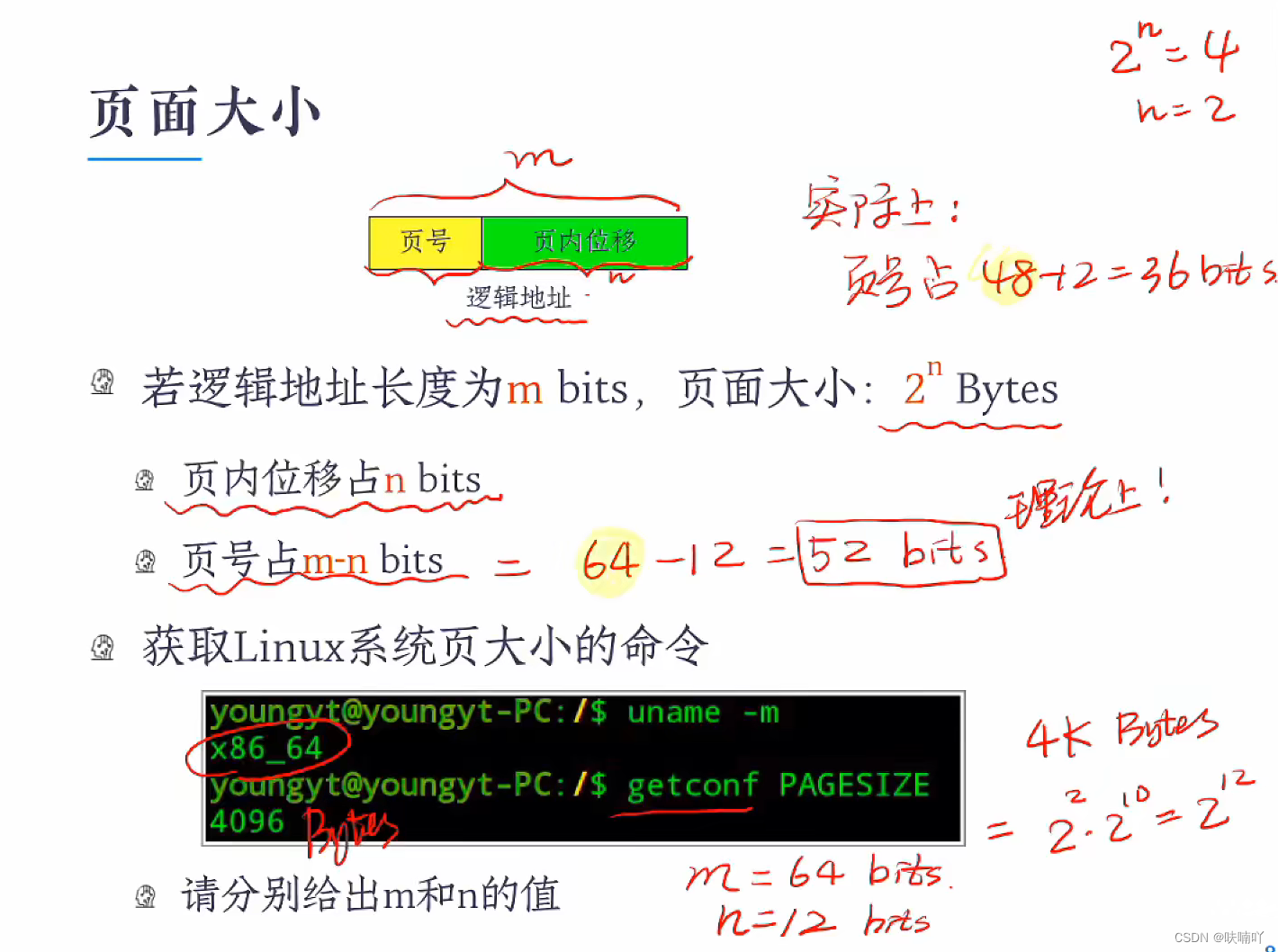
页面的大小如何计算?
我们前提的知道逻辑地址的bit位,和页面大小;
只要有这两个数据,我们就可以通过页面大小推算出,页内位移占用逻辑地址多少个bit;那么页面的大小就可以呼之欲出了;
不过,一般我们Linux的系统都是逻辑地址有64个bit,因为大多数都是64位OS系统了;
页面大小一般都是4kbytes,通过简单计算 我们得知 4kbytes = 212bit;那么说明页内位移是有12个bit,这样我们就得出页面大小占用的bit位数位 64 - 12 = 52; 但是着52个bit给页面用,只是理论上的,因为52bit位页面来用实在太多了,实际上OS只用32个bit,给页面使用,其他只是闲置放在没用而已;
页表特性

OS会给每一份进程都分配一个页表;
页表的主要作用就是翻译逻辑地址位物理地址的;
并且页表是只有在进程被CPU调度时候,才会被使用,如果该进程没有被调度,那么对应得页表只会留在内存中,不会被使用;
CPU是通过一个寄存器来保存页表得信息的;
并且页表带来一个新的问题,会增加上下文切换的开销,因为进程切换时候,不仅要保存进程的相关信息,它对应的页表信息也需要被保存起来;
PTBR–寄存器
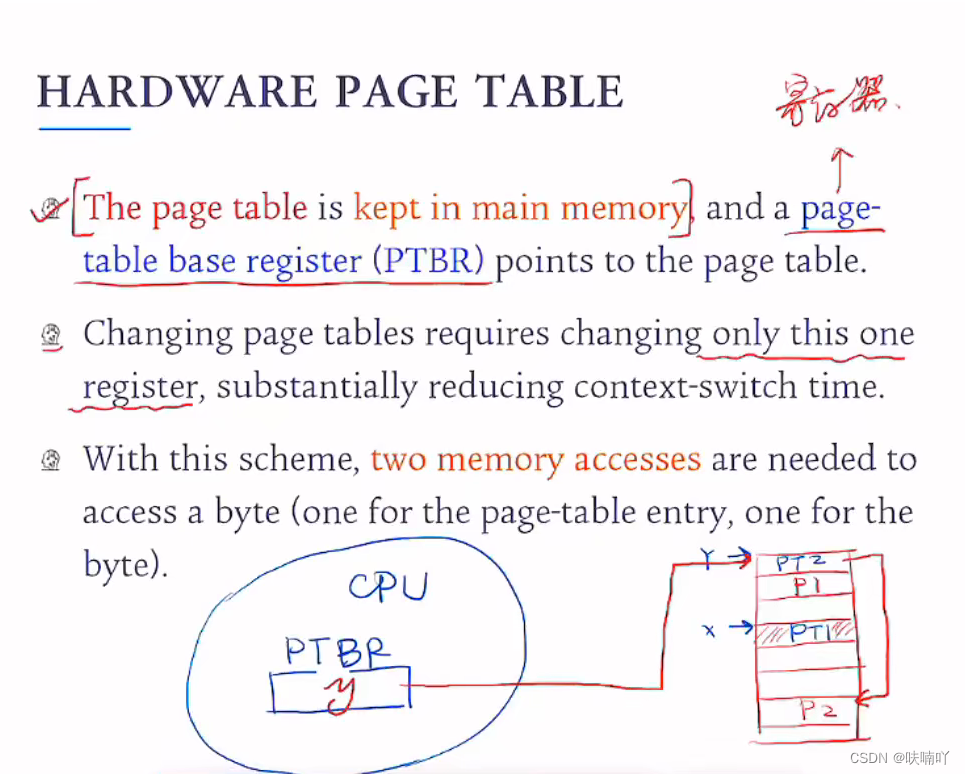
我们要清楚知道,页表也是需要存储在内存中的,但是页表会增加上下文切换的负担,一直让页表留在内存中,我们切换上下文就会缓慢,所以在CPU中专门有一个为页表服务的寄存器,那就是PTBR,它存放的是页表的地址;
有了它,就不用上下文切换时候,要把这页表搬来搬去,只需要修改PTBR的值即可,哪个进程被CPU调度,那么就往PTBR添加哪个进程的页表;极大缩短上下文切换的时间;
我们知道有了这个寄存器后,我们访问页表,就需要有两次的内存访问了咯,当我们调度进程时候,第一次,访问的是页表的位置在哪,把它放入到PTBR寄存器中,第二次访问就是内存中页表的逻辑地址到物理地址的具体位置数据在哪咯;
快表

认识快表前,我们要知道为什么需要快表?肯定是页表的访问速度太慢了,才导致快表的产生,是的,确实是,因为页表是存储在内存中的,还是那样CPU去内存读取页表,对于CPU来说太慢了,所以为了加快读取页表速度,那么OS设计者搞出一个快表;
他们如何搞快表的呢?我们知道软件设计有一个大原则:任何问题都可以通过增加中间层来解决问题;
是的,我们OS设计者,搞了一个硬件,是TLB,就是一缓存,它是专用缓存,专门用来存取页表的条目信息的,因为cahe比较小嘛。。不可以存储全部的页表,只能存储部分的页表条目;
所以当访地址空间时候,我们首先去TLBcahe查找是否有你要页表信息,如果有直接返回给CPU就可以处理,没有那么就再去内存访问剩余其他的页表条目即可;
这里会有两次内存访问,一次是访问 cache 一次是内存访问。是不是说这样变慢了/
不是的,只要我们保证一个原则,我们TLB cache中存放的页表信息,都是进程中需要寻找的地址那么就可以加快速度,只要再TLB cahce的信息,命中率高即可!
至于愈合提高TLB cache的命中率,是缓存那边的话题,这先不讨论,我们只要知道;有一个TLB硬件,他是cache,并且他存放的是页表的部分条目信息,他可以加快页表的访问速度,快表的体现也就是体现在这里;
一张图解释:CPU调度程序,如何访问页表的过程:
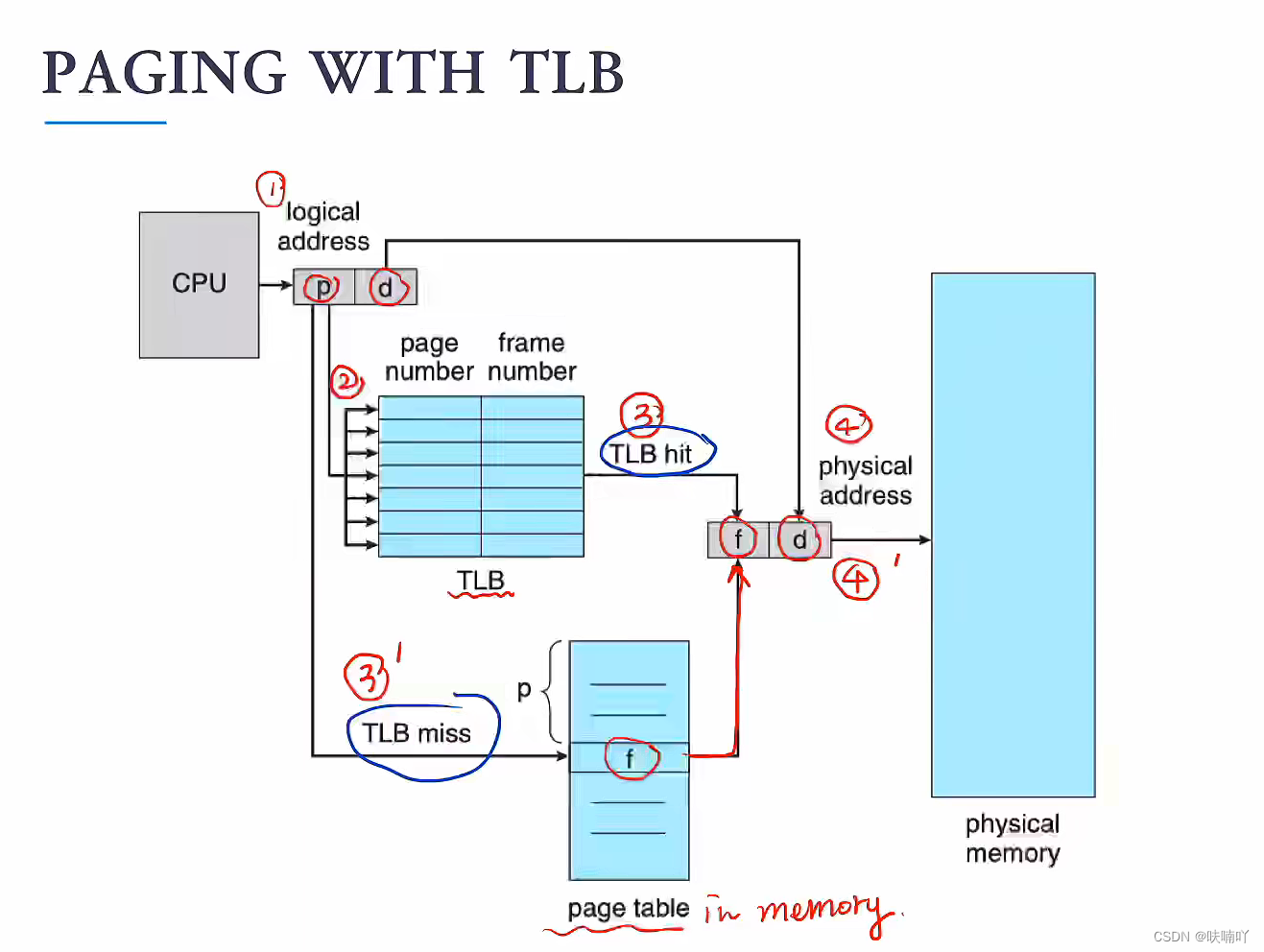
TLB 命中率

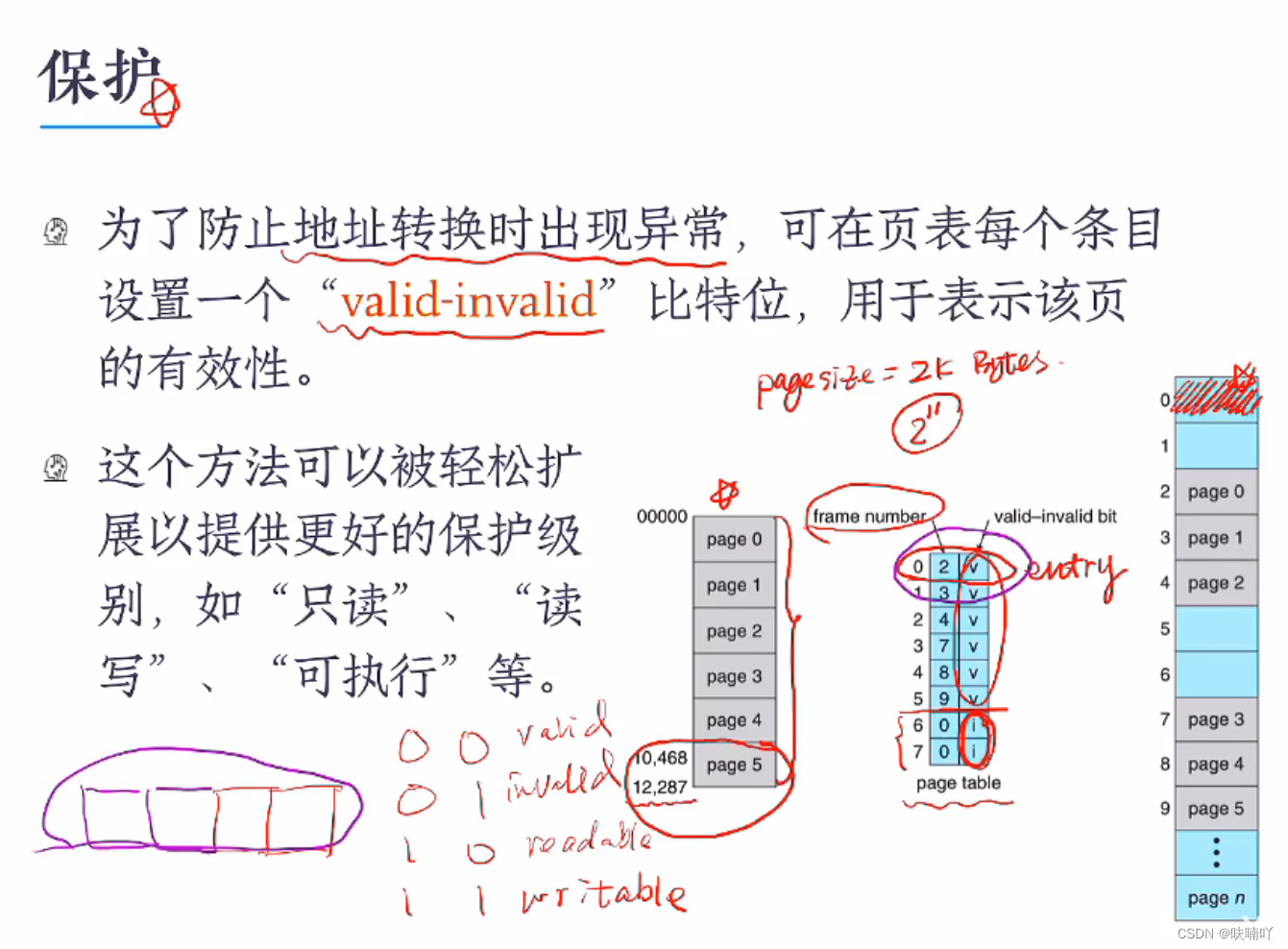
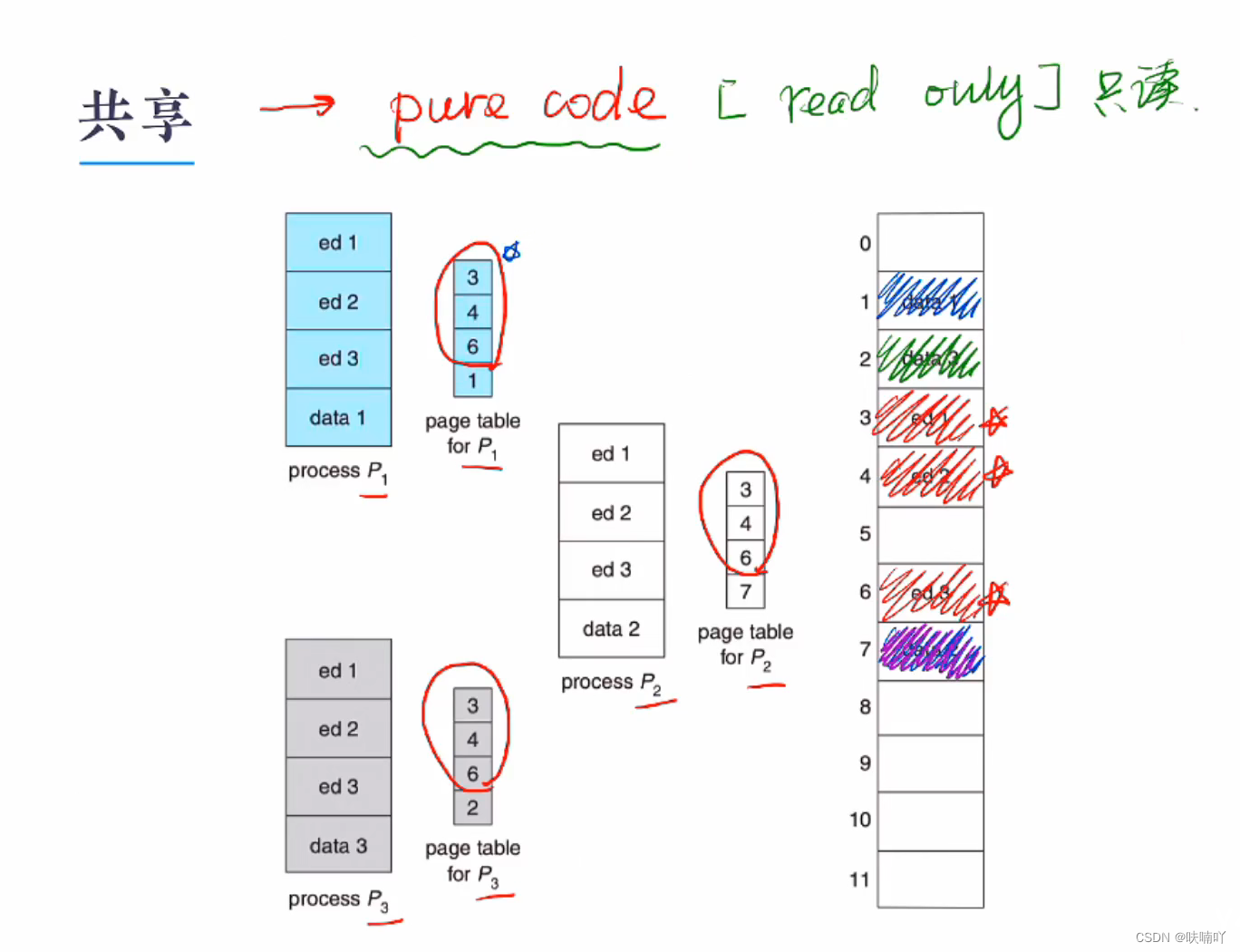
基于页表的保护与共享
多级页表
认识多级页表,我们先看看,页表的大小问题:
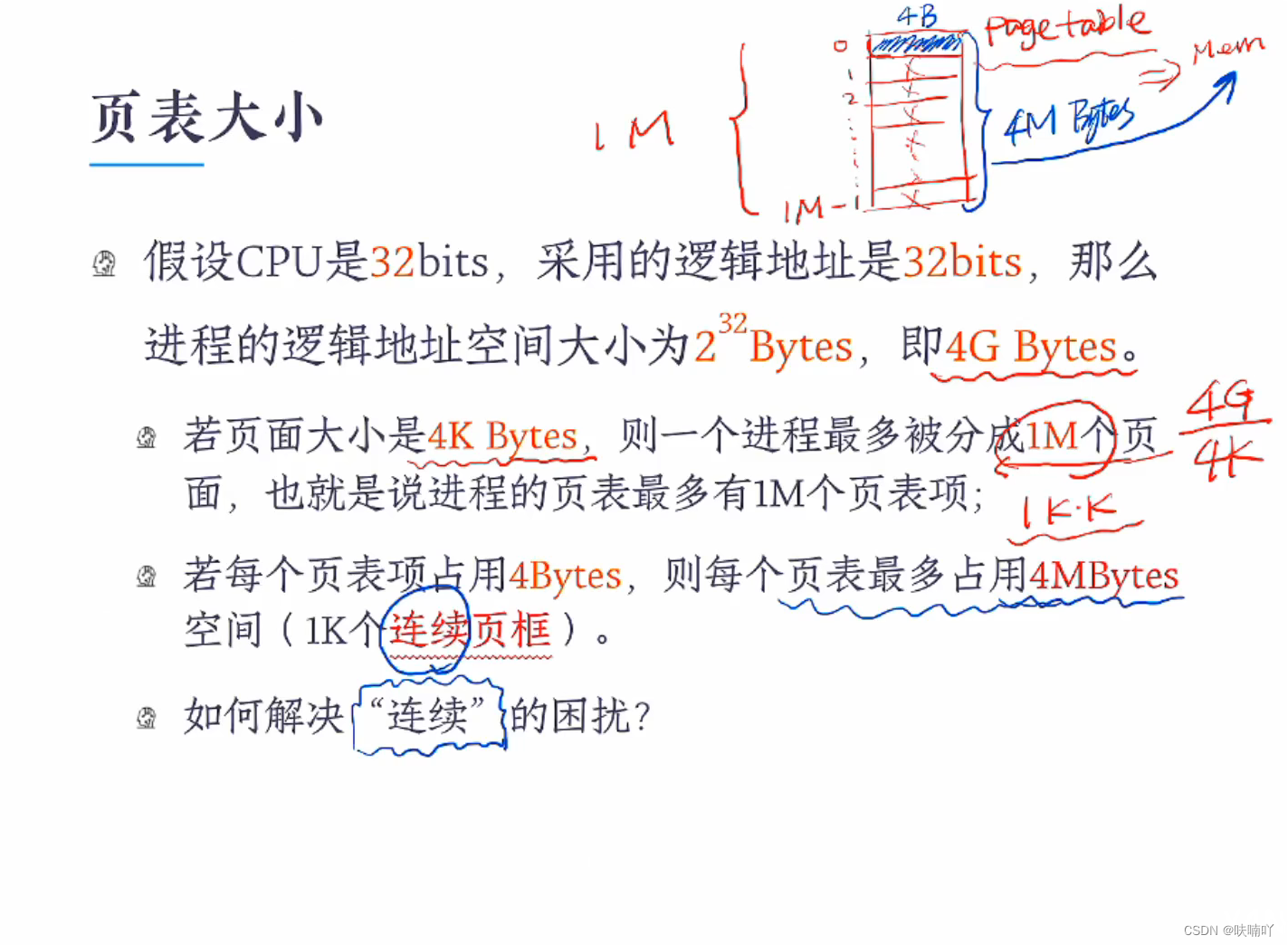
基于32位的系统下,我们一个进程最多可以分配到1m个页面(每个页面大小位4kb),用具体数字说,就是100w个左右的页面,那么一个进程的页表就是存放页面和页框的信息,也就是说,一个进程的页表就要存放1m左右的页表项(页面和页框的映射),也就是要一个进程的页表要存放100w个左右的页表项信息;
我们再假设一个页表项大小为4字节,那么,一个页表就要存放4M字节的信息,也就是400w个左右的页表项信息;
这是什么概念?这个概念是,每当你创建出一个进程,OS都需要为你这个进程维护一个页表,这个页表占用的实际空间是4M;
这样可能觉得不大,假如我的OS搞出100个进程呢?那么你OS就要帮你维护400M的页表信息;
这样说可能觉得还没什么,你知道一个进程维护一个4M字节的页表什么概念嘛?也就是你的物理内存,需要有
4M / 4KB = 1K个页框存放你的页表哦,意思是你的物理内存有1024个左右的页框,并且还是连续的1024个页框,为什么是连续的?因为你的页表不可以被打散存放在页框中,如果打算存放你怎么找到?
基于上面页表的信息过于大,且需要连续的物理空间,存放页表信息,所以我们认为这种方式不合理。
所以多级页表的方式就诞生的。
多级页表的意思是将页表也拆分一个一个的,然后放入到物理内存的页框中,此时我们就需要多了一个数据结构,保存,页表号,和页框号的信息,因为我们需要找到也标号,才能找到页面号,进而找到对应的物理地址;
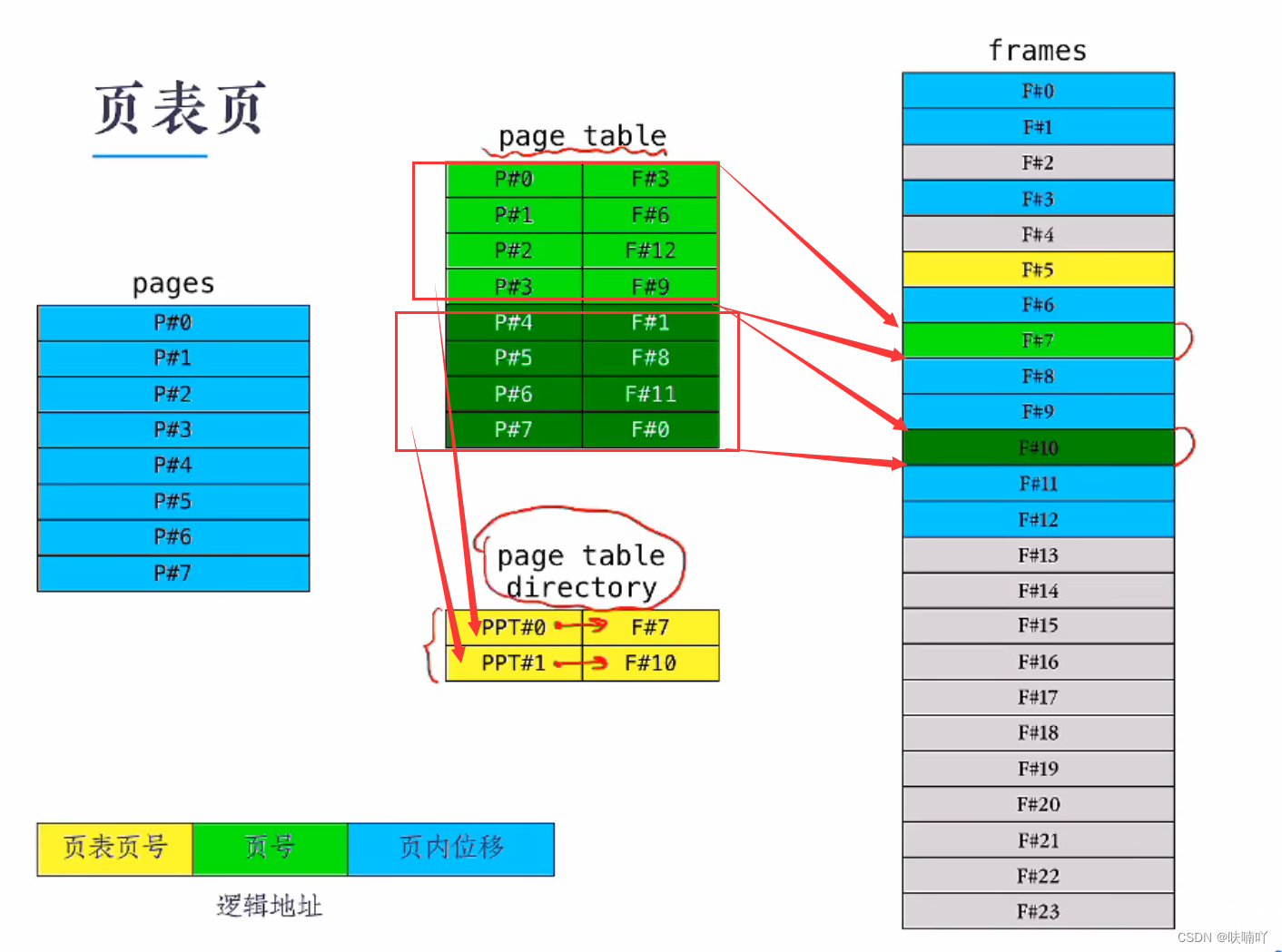
这个数据保存页表号的数据结构我们叫页表页;
所以一个逻辑地址:就被表示为了页表页号+页号+页内位移了;
上面的处理方式就是2级页表的处理方式;