内存使用
内存使用:将程序放在内存中,PC指向内存地址
首先,我们需要让程序进入内存
举个例子
int main(int argc, char *argv[])
{
...
}
.text
_entry: //入口地址
call _main
call _exit
_main:
...
ret
_entry: //入口地址
call 40
call xx
_main: //偏移是40
...
我们需要把上面这段程序放入内存中,因为里边有条指令call 40,这意味着在物理内存中,main函数就必须放在内存地址为40的地方,这样程序才能执行
//物理内存中
40: _main: mov[300], 0
...
call x
call 40
上面的方法理论上是可行的,代码确实能够在内存中运行,但是程序必须放在0地址处,main函数必须放在40处,如果有多个程序同时需要用到40处的内存,那么就会发生冲突,因此,我们需要修改程序中的地址,也就是将程序中的地址加上偏移,比如说把程序开始地址放在1000处
1040: _main: mov[300], 0
...
call x
call 40 --> ip=1000
重定位:修改程序中的地址(是相对地址)
找一段空闲的内存,将程序放入内存中,重定位程序中的逻辑地址
什么时候完成重定位?编译时, 载入时
-
编译时重定位的程序只能放在内存固定位置
-
载入时重定位的程序一旦载入内存就不能动了
载入时重定位比较灵活,但是程序载入之后还需要移动
交换(swap)
计算机内存资源紧张,而磁盘资源多,因此我们一般会将睡眠的进程换出到磁盘,然后再从磁盘中换入进程,这样一来,就不会造成内存的浪费,同时,一个进程被换入换出,其内存位置肯定发生了变化,那么载入时重定位的程序就不能执行了。
因此,从上面我们知道,一个程序被换入时,就开始执行,而我们就要在此时进行重定位,也就是在运行时重定位
运行时重定位(地址翻译):每个进程对应的PCB都会保存基地址(base),执行指令时第一步先从PCB中取出这个基地址,然后对每一条取指指令进行地址翻译。
分段
一个程序一般由以下部分组成
- 主程序 mian
- 变量集 data
- 函数库 sin
- 动态数组 array
- 栈 stack
根据分治的思想,我们希望对不同的段进行不同的处理,这就是分段的作用
从内存使用我们知道,我们需要在运行时重定位,而我们重定位的方法就是从进程的PCB中取出基地址,然后对取指指令进行地址翻译,但是当我们一个进程被分段了,那么此时一个基地址就不够用了,这时候就有了<段号,段内偏移>,如mov[es:bx], ax;
因此,我们在PCB中设计一个表结构(段表),根据段号可以查找段内偏移,然后进行地址翻译
GDT表:操作系统对应的段表
LDT表:进程对应的段表
内存分区
从上面我们知道,一个程序分段放入内存,在执行时需要在PCB中的LDT表找到段内偏移,而cpu是基于寄存器来工作的,因此有一个保存段表的寄存器ldtr还有一个保存段号的寄存器cs,举个例子
ldtr---> 1 1000
0 3000
jump 40 cs:40 ---> 0:40 ---> 40+3000
这就完成了地址翻译
切换进程时,ldtr就指向新的PCB中的LDT表
从上面我们引出一个问题,当我们对一个程序进行分段时,需要在内存中找到一段空闲分区,将程序载入内存时同时对LDT进行初始化,那么我们要如何对内存进行分区?
固定分区
将内存等分为k个分区
该方法不合适,因为程序大小不一
可变分区
根据程序大小分区
可变分区的管理
可变分区的管理实际上就是维护一个表
//表结构
起始地址 内存长度
程序段申请内存,有三种方式
- 首先适配:时间复杂度为O(1)
- 最佳适配:与所需内存大小相差最小的分区,易产生极小的内存段
- 最差适配:与所需内存大小相差最大的分区
分页
分页:解决内存分区导致的内存效率问题
内存分区制造了一大堆细小的内存碎片,没办法使用,如果采用内存紧缩的方法(即将各个内存碎片移动到一起),效率太低,因此引出了内存分页的概念
分页:将内存分页,根据段的请求,系统一页一页的分配给这个段,这样一个段最多就浪费一页的内存。
jmp 40如何执行?如何找到实际的物理内存?
跟段表类似,分页机制也有页表
//页表结构
Page# Offset
第几页 页面尺寸
例子
mov [0x2240], &eax
逻辑地址 0x02 0x240
在PCB表中找到页表首地址指针赋给cr3
页号 页框号 保护
0 5 R
1 1 R/W
2 3 R/W
3 6 R
页框是物理分页的页号
页号 = 逻辑地址/页面尺寸 = 0x2240<<12 = 2
找到页框号为3,将页框号>>12,也就是把3接在240前面,找到物理内存3240
这些计算都是由MMU完成的,只要给出逻辑地址和页表首地址,MMU就能自动算出物理地址
多级页表
分页机制中,页表在地址翻译中起到关键性的作用,而页表号又等于逻辑地址/页面大小,为了减少内存浪费,页面大小一般都不会大,如果页面大小为4k,那当我们写一个32为程序时,内存地址就是2^32,2^32/2^12 = 2^20也就是1M,而一个页表项需要4个字节,所以一个页表就需要4M内存,当系统并发执行多个进程时,就会消耗大量的内存空间
那么如何解决这个问题?
实际上大部分逻辑地址根本不会用到
32位:[0, 4G]
一个简单hello.c文件怎么可能需要4G的内存,实际上大部分物理地址都不会被用到,那么也不同特地的为它们设置页表项
第一种尝试,只存放用到的页
如果去掉不需要的页,那么整个页表就不连续,不连续的页表查询页表项那么效率肯定降低,所以这种方法不可行
如何既要页表连续又要让页表占用内存少?
用书的章目录和节目录来类比思考……
第二种尝试,多级页表,即页目录(章) + 页表(节)
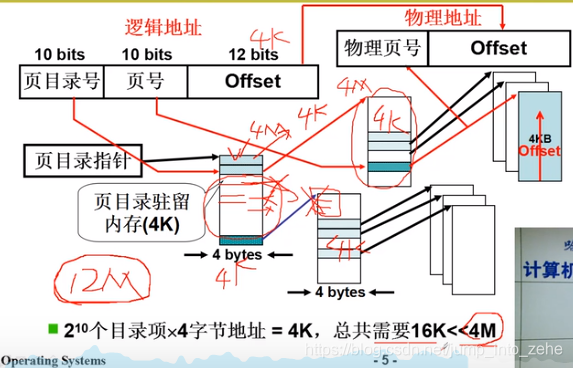
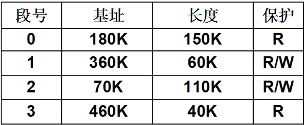
从图中可以看到,我们将一个逻辑地址划分位3段,前10位为页目录号,中间10位位页号,当我们需要查询页号时,首先查询一下页目录号,而页目录号也就10位,页表占用内存就是2^10*4=4k,
而页目录项对应的一个页表大小为2^10*4=4k,一个页表对应的内存为2^12*2^10*4=4M,因此一个页目录其实就指向了物理内存的4G,但是当我们使用12M时,也就是3个页表+一个页目录表=16k;
因此,采用了多级页表,一个使用了12M内存大小的32位进程的页表占用内存才16K
但是,多级页表的增加也导致访存次数的增多,每增加一级页表,访存次数就多一次,当操作系统为64位系统时,访存次数就会增加到5、6次,如何既能保证空间还能尽量降低时间呢?
快存
多级页表增加了访存的次数,尤其是64位系统
- TLB是一组相联快速存储,是寄存器
对于一些经常用到的页表,我们可以将其放在TLB中,而TLB是寄存器,执行速度非常快,当在TLB找不到时,就回到多级页表中去查找,也就是TLB和多级页表的合作。
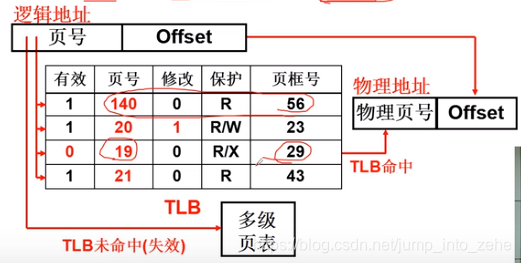
TLB得以发挥作用的原因
-
TLB命中时效率会很高,未命中时效率降低
有效访问时间 = HitR * (TLB+MA) + (1-HitR)*(TLB+2MA) HitR:命中率 MA: 内存访问时间 TLB: TLB时间 -
TLB价格很高,一般为[64,1024]
为什么TLB条目数可以在64-1024之间
- 程序的地址访问存在局部性
- 程序多体现为循环、顺序结构