注意:本篇为50天后的Java自学笔记扩充,内容不再是基础数据结构内容而是机器学习中的各种经典算法。这部分博客更侧重于笔记以方便自己的理解,自我知识的输出明显减少,若有错误欢迎指正!
目录
昨日又双叒叕是毕业各种琐事打乱了昨天的正常更新,整理整理心绪,今天对于过去十日完成的内容做一次小总结,同时也对一些错误进行分析。
1.尝试作为知识的输出者
首先,过去10日内容是自己作为机器学习小白,通过模仿老师的代码一步步学习机器学习的内容进行完善得到。相比于1~50天内容的几乎纯粹的知识输出,我本希望的是写得更像笔记一些,但是写着写着就感觉内容渐渐偏向一种理解阐述,就是把自己听到的东西试着作为输出方输出出来。
这样无疑非常花费时间,但是这个过程中我对于这个知识的理解似乎渐渐变得更加明了。例如过去几日的NB算法,说起来好笑,我在写博客的时候其实还不是很明白算法的过程,但是通过一边跟着老师的公式推导一边自己推导,渐渐理解NB的一些思想了,同时写出来的东西不完全类似于老师的东西,而是有更多自己的理解。我认为这也是一种自我的学习,通过在理解一个陌生的东西过程中不断试着扮演输出者,说出自己的一瞬间灵感和想法,从而学习新的内容。
当然这样可能也会有些弊端,比如自己一瞬间的理解可能不完全正确,这样的文章需要在自己理解更丰富后再读几遍,完善一些措辞。而且能自我输出量始终是有限的,只是一种尽可能采用的策略。
2.机器学习的不确定性
相比于基础的数据结构,部分机器学习的代码都包含一定的不确定性,比如KNN中采用测试一部分数据的策略能大幅度减少时间开销,但是换来了测试的不稳定性,但是这也是一种可取的节省时间的方案;KMeans算法分簇时,因为初始点是在全图中随机选择的,所以中心点的不同直接导致了最终结果不同的分簇,在我56~57天的博客的最后一张图中,我给出了我偶然测试出的一些奇怪的数据:
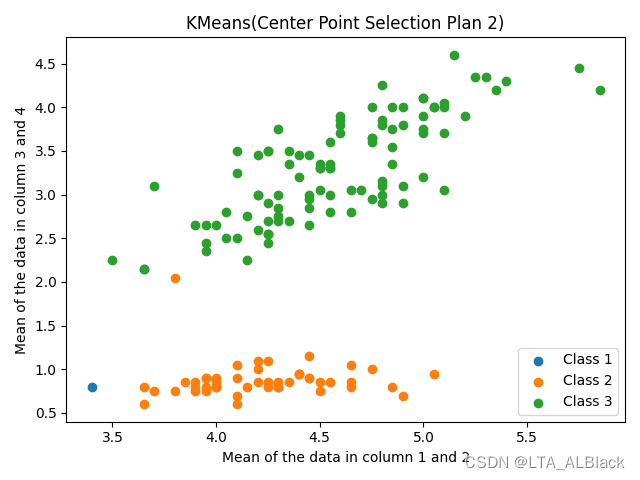
这里的Class1数据就是在过于偏左下角的中心点导致的错误分簇(正确的分簇可参考我的原图),这就是算法的一种不确定性,但是通过多次测试来看,其实这样的案例属于低概率,大部分情况下不会出现这个独立分簇的情况。
综上,一些基础的机器学习算法有不可避免的不确定性,这个我感觉是不同于许多基础数据结构算法。
3.关于KNN与KMeans的差异
- KMeans本质上是无监督学习,而KNN是监督学习;
- KMeans是聚类算法,KNN是分类(或回归,这个区分点在于最终决断的数据类型是非数值的标签还是数值型的连续数据)算法。
- KMeans算法把一个数据集分割成簇,使得形成的簇是同构的,每个簇里的点相互靠近。KNN算法尝试基于其k(可以是任何数目)个周围邻居来对未标记的观察进行分类。
-
KMeans的K选取要比KNN复杂度得多,并且直接影响最终分簇效果;而KNN的话相对简单,略微的调整并不会影响全局结果,但是普遍来说K是比较小的, 因为对于KNN算法,k值越大,表示模型的学习能力越弱,它越倾向于从“面”上考虑做出判断,而不是具体地考虑一个样本,近身的情况来做出判断,所以,它的偏差会越来越大。
-
KMeans的K表示的是类别情况,代表最终分簇的簇的数目;而KNN的K是邻居数目,是用于度量当前数据的决策的参考信息。因此他们本质上是有差异的。
4.关于Leave-one-out的一些思考
leave-one-out测试其实说通俗就是拿出一个样例作为中心进行测试,然后除了它以外的全部数据都是他的训练环境,这样的话数据具有最大的学习可能性,也是最公平的;但是相对应的,他要面对全部的数据,复杂度是非常大的,对于算力要求是比较大的。
我感觉一般对于单次学习过程可以通过某些快速的数学方法进行度量的,我们都喜欢于leave-one-out,我有种感觉...那些单次学习能力比较弱的算法,似乎可以通过庞大的leave-one-out来增加算法的代表性与公平性,从而得到不错的结果。比如我们基于M-distance的推荐系统以及NB似乎都是走的这种流派,与之相对的KNN的单次学习的开销就比较大(遍历全部训练集),所以我们更喜欢采用数据分割学习的思路。
这就是针对合适的数据环境,采用合适的算法体系。
5.关于常用的距离公式整理
之前在KNN与KMeans这部分关于向量的距离度量公式我一带而过了,这里在总结的时候专门拎出来整理一下,便于后续编码查阅
5.1 欧氏距离
全称是欧几里得距离(Educlidean Distance),指在\(n\)维空间中两点之间的真实距离。这个公式主要是从我们常见的二维距离公式中抽象而来,结合常识发现同样适用于一维与三维空间。于是,在多维空间中也近似地推广了这种计算。
\[d(x, y)=\sqrt{\sum_{i=1}^{n}\left(x_{i}-y_{i}\right)^{2}}\]
5.2 曼哈顿距离
欧氏距离虽然使用比较频繁,但是计算起来比较复杂,要平方,加和,再开方,而人们在空间几何中度量距离很多场合其实是可以做一些简化的。于是在19世纪著名的德国犹太人数学家赫尔曼·闵可夫斯基发明了曼哈顿距离(Manhattan Distance)。
\[d(x, y)=\sum_{i=1}^{n}\left|x_{i}-y_{i}\right|\]
如果把欧式距离理解成点到点的直线距离,那么曼哈顿距离就指的是两点之间的实际距离,这个距离不一定是直线。它的计算公式看起来简洁很多,只需要把两个点坐标的 x 坐标相减取绝对值,y 坐标相减取绝对值,再加和。就如同一个网格状的街区相互相连,到任意两点的距离其实就像这样水平+竖直走格子的过程,所以曼哈顿距离又叫做出租车距离。
6.其余高维距离距离
其余的距离我就没在代码里面用过了,这里稍微记录下就好了,用时还需要再查阅下。
切比雪夫距离(Chebyshev Distance):切比雪夫距离 - MBA智库百科
\[d(x, y)=\lim _{i \rightarrow \infty}\left(\sum_{i=1}^{n}\left|x_{i}-y_{i}\right|\right)^{\frac{1}{i}}\]
切比雪夫距离定义为两个向量在任意坐标维度上的最大差值。换句话说,它就是沿着一个轴的最大距离。切比雪夫距离通常被称为棋盘距离,因为国际象棋的国王从一个方格到另一个方格的最小步数等于切比雪夫距离。
明氏距离(Minkowski Distance)
\[D(x, y)=\left(\sum_{i=1}^{n}\left|x_{i}-y_{i}\right|^{p}\right)^{\frac{1}{p}}\]
明可夫斯基距离(Minkowski Distance)的简称,其比大多数距离度量更复杂。它是在范数向量空间(n 维实数空间)中使用的度量,这意味着它可以在一个空间中使用,在这个空间中,距离可以用一个有长度的向量来表示。常见的 p 值有:
- p=1:曼哈顿距离
- p=2:欧氏距离
- p=∞:切比雪夫距离
更多距离查阅:这个网址
7.测试与训练的分割应当采用随机数组分割
这是一个错误后的总结经验。事情是这样的,早些时候发现老师的NB算法的一些bug,然后在讨论后纠正了bug却发现识别率下降了(从0.99下降到了0.95)。于是老师让我测试一下NB算法的分割训练与测试集的效果。然后我就简单地将数据按照顺序的前后,将数据集分为70%和30%用于测试或训练,但是效果下降得太离谱了(见下)。
| Training Set Distribution | Testing Set Distribution | |
| Top-30% | Post-30% | 0.91 |
| Top-30% | Post-70% | 0.64 |
| Post-30% | Top-70% | 0.79 |
| Post-70% | Top-30% | 0.85 |
之后通过老师的随机分割代码得到与源情况类似的0.96~0.95的识别率。
是我代码错了吗?我很不甘心啊,于是我反复对照了老师的代码和我的代码,发现并没有问题,于是我将老师的随机数组改为顺序数组:[0,1,2,3,4,5...]。结果非常神奇啊,我上面的测试数据果然被还原了!那么我的代码应该是没错的。
但是,我反而又非常迷惑不解了,为什么数据分割一定要随机?首先就今天我和老师讨论的我48日写的NB算法将leave-one-out改为分割的数据来说,我跑了下全部可能的分割测试:
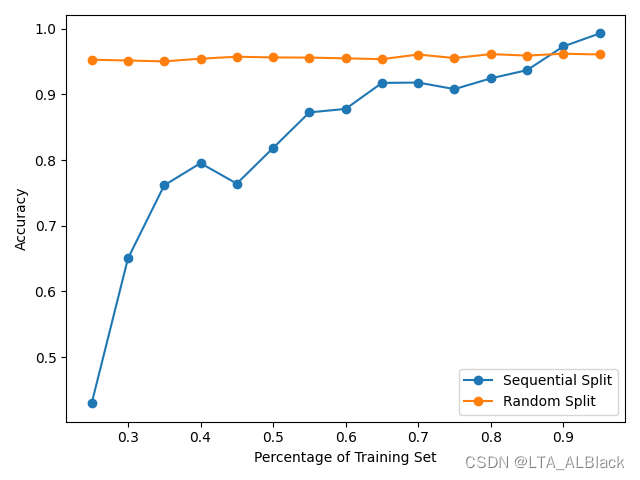
效果非常amazing啊!可以明显发现,采用随机分割数据集之后能保证无论数据集怎么分割,我们的识别率是稳定;相反,如果单独只是把数据前半部分分为训练集,后半部分分为测试集这样的方法非常不稳定的,很有可能因为受到数据分布的影响(训练得越多-测试得越少 识别率就高这种怪像)我又到网络上查了一些,有下面这样的结论:
打乱全量数据,这样做 train/dev/test 测试的时候每一部分的数据比较有代表性
往往来说,对于那种对随机性比较敏感的模型,典型的就是 NN,打乱数据很重要。对于那种对随机性不太敏感的模型,理论上说可以不打乱。但敏感不敏感也跟数据量级,复杂度,算法内部计算机制都有关,目前并没有一个经纬分明的算法随机度敏感度列表。既然打乱数据并不会得到一个更差的结果,一般推荐的做法就是打乱全量数据。
8.要去怀疑
通过上面的第7条总结得出的过程,其实验证了我们学习过程一个关键路径:怀疑
其实在学KNN时对于老师提到的随机数组分割我当时是没有疑虑的,看上去非常合理地使用,结果也符合预期。从来没有想过“ 为什么要随机分割 ”,当然很大部分也是因为当时KNN的iris数据很有序,随机分割是很正常的思路。但是对于本身数据长得就很随机的数据,是否也要随机?(比如字符型数据集mushroom、voting这些)
这些问题有时候可能只有在自己“ 试着去违背 ”之后才能发现猫腻。今天我误打误撞顺序分割数据果然就导致了识别率的下降,于是就去分析自己的方案和正常的方案的差异,于是发现了问题,同时也学到了关于模型随机分隔的意义。这不妨是一次误打误撞导致的“ 主动学习 ”。
9.“ 错误的代码 ”反而更高的识别率?
刚刚讲第7点的时候我提到了我和老师修了bug反而识别率更高的问题,最后我细细总结下这个问题。
问题的开始是这样的,关于NB算法的某个求和过程有代码错误,这个最早由@张海涛同学发现,然后通过问我我也发现了这个问题,发现这个错误会导致识别率上升。之后向老师指明的后,老师后续也将其修改了,但是改bug的时候不小心改错了一个地方:\[P^{L}\left(x_{j} \mid D_{i}\right)=\frac{n P\left(x_{j} D_{i}\right)+1}{n P\left(D_{i}\right)+v_{j}}\] 就是这个平平无奇的Laplacian平滑式子,本来其代码体现是:
conditionalProbabilitiesLaplacian[i][j][k] = (conditionalCounts[i][j][k] + 1)
/ (tempClassCounts[i] + tempNumValues);其中\(nP (x_{j} D_{i} )\)用conditionalCounts[i][j][k]可以直接表示,但是因为有个\(n\),所以会非常容易误打误撞写成:
conditionalProbabilitiesLaplacian[i][j][k] = (numInstances * conditionalCounts[i][j][k] + 1)
/ (numInstances * tempClassCounts[i] + tempNumValues);这样平滑式子就变成了:\[P^{L}\left(x_{j} \mid D_{i}\right)=\frac{n^{2} P\left(x_{j} D_{i}\right)+1}{n^{2} P\left(D_{i}\right)+v_{j}}\] 这无疑是代码层面的失误,但是识别率却发生了非常amazing的提升:

采用leave-one-out和分割训练测试的效果差异是一致,不过就是稳定与否的差异。可以发现错误的测试始终会高出正确测试一部分。为了解释这种奇怪的现象,我们试着分析平滑的公式,这样改变\(n\)的设置对于平滑的目的来说,似乎并没有什么问题:首先,确实能避免0概率;其次,这样的平滑的条件概率,对于多个平行遍历的\(x_j\)求和,依然能保证概率和为1,即\(\sum_{j=1}^{v_{j}} P^{L}\left(x_{j} \mid D_{i}\right)=1\)。所以说这种平滑式子本身是合理的!其实对于条件概率的平滑,Laplacian其实也只是一种手段而已,手段可以有很多种。通过老师分析,通过乘\(n\)扩大分子与分母的中\(nP (x_{j} D_{i} )\)与\(nP (D_{i} )\)的效果,附加的 1 和 \(v_j\) 起到的作用更小,弱化了平滑效果。
老师这番话语倒激起了我继续测试的兴趣,我在平滑式子里面引入了一个控制系数\(k\),即修改成下面的样子:\[P^{L}\left(x_{j} \mid D_{i}\right)=\frac{kn P\left(x_{j} D_{i}\right)+1}{kn P\left(D_{i}\right)+v_{j}}\] 然后分别设置了不同的参数测试了一下:

\(k = 1\)是原版我们认为“ 正确 ”的平滑效果,\(k = n\) 是误打误撞得到的错误数据,其余是我假象的基于\(k = n\) 上下的测试,可以发现随着\(k\)的增加,似乎相似度有非常奇妙的增加过程。为了测试更多\(k\),我该用leave-one-out方法,让识别度稳定下来,看\(k\)的变化对于整个识别度的影响:
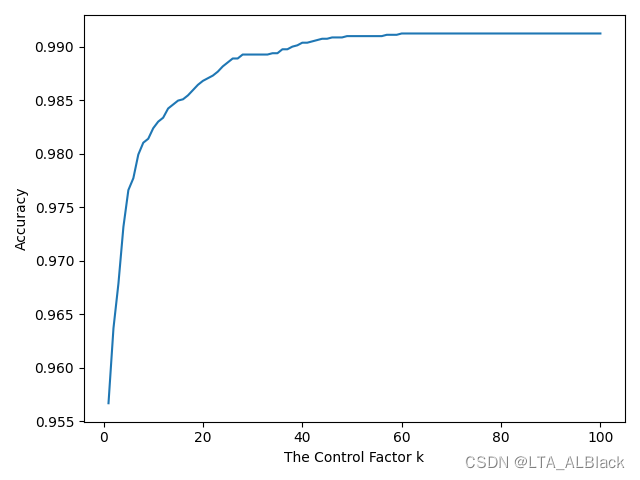
意外地高!至于为什么弱化平滑效果会出现这样的情况我暂时也找不到很好的理由。如果k到30左右就可以提高到如此可怕的地步,似乎也不难理解为什么我们误打误撞的\(k = n\)会导致识别率出奇地高。另外还有个非常诡异的一点,这种平滑的魔改非常吃数据,我试了voting数据后发现\(k\)的设置完全不会对识别度产生影响,但是对于mushroom数据集会产生非常巨大的影响....
10.机器学习总是让人摸不着头脑
通过NB的这个平滑问题和分割数据集时自己的失误探究,我更加明确地感觉到,在机器学习中很多地方都很灵活,要合理用算法去分析数据一方面需要多总结、多试错。甚至有时候,一些错误能带给你完全不一样的理解,你永远不知道你点击“ 运行 ”这个按钮后,系统会给你呈现什么样的结构。在你以为会数据值很高时突然变低了...认为写错了识别率应该很低结果突然很高...永远不要相信自己的自觉。这可能就是机器学习的奇妙吧。
但是有点我似乎有点感觉到了,无论正确与否,分析数据去发现新的可能性过程还是非常有成就感的。