逻辑回归:(用来做分类的,运用了线性回归的方法):
基础知识:
首先是用一个sigmoid函数,它是一个可以无限次数求导而且不归零的一个函数,正好在0和1中间0.5的位置有一个分界点,很好的表示了概率,概率大于0.5的取1,概率小于0.5的取0。

然后是我们平时用的二分类,比如我们用身高和鞋码做比喻,x轴是鞋码大小,y轴是身高,根据全班的身高和鞋码进行画图,得到下图,我们现在需要去判断一学生(已知身高鞋码)的男女,用下图中的直线进行分类,在线左边的分为女生,线右边的分为男生,这样的线可以有很多,怎么去找到哪根线是最合适的呢,这时候就引出了损失函数,离这根线的点的距离之和最小即可求出这根线的表达式。推广到高维。

具体操作:
uci data_banknote_authentication 数据集的下载
链接: http://archive.ics.uci.edu/ml/datasets/banknote+authentication


然后选择下载地址即可
如果通过网站下载不了的话(我们班有少数同学官网下载不了)
百度云盘链接:
https://pan.baidu.com/s/1uU9pgax2x6VfmEDr4ZlniQ
提取码:7d8c
用sigmoid函数来作为逻辑回归估计函数:
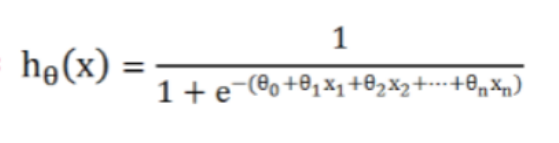
代价函数: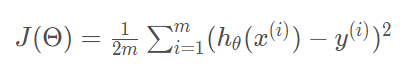
用梯度下降法去逼近最低值,以及求出所需的参数。
偏导函数:
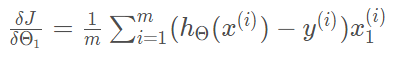
theta迭代函数:

代码:
# -*- coding: utf-8 -*-
import math
import numpy
import random
import pandas as pd
data= pd.read_csv('C:/Users/95870/Desktop/banknote/data_banknote_authentication.txt',header=None)
X = data[[0,1,2,3]] # 前四个为特征值
Y = data[[4]] #最后一个作为判别值
size=1372
#求theta
def sigmoid(x,theta):
z=0
for i in range (4):
z=z+x[i]*theta[i]
sum=1/(1.0+math.exp(-z))
return sum
def piandao(X,Y,theta,size,j): #j是维度(每次只能求某个维度的偏导)
sum=0.0
for i in range(size):
sum=sum+(sigmoid(X[i],theta)-Y[i])*X[i][j]
return (sum/size)
def sunshi(X,Y,theta,size):
sum=0.0
for i in range(size):
h=sigmoid(X[i],theta)
sum=sum+(h-Y[i])*(h-Y[i])
return (sum/2*size)
def tidu(X,Y,theta,size,a,count):
for i in range(count):
print(i)
t=[]
for j in range(4):
h= theta[j] - a * piandao(X,Y,theta,size,j)
t.append(h)
for j in range(4):
theta[j]=t[j]
print(theta)
if __name__ == '__main__':
theta = numpy.zeros((4)) #这里的4代表的是个数,而不是从0开始的下标数
#print(sigmoid(X[0],theta,con))
count=30000
a=0.002
tidu(X.values.tolist(),Y[4].tolist(),theta,size,a,count)
X=X.values.tolist()
Y=Y.values.tolist()
b=0
for i in range(1000):
z=0
j=random.randint(0,1371)
for k in range (4):
z=z+X[j][k]*theta[k]
sum=1/(1.0+math.exp(-z))
if sum>0.5 :
if Y[j][0]==1:
b=b+1
else :
if Y[j][0]==0:
b=b+1
print(b/1000)
输出的直接是贴合程度,或则说是预测准确率,大概在0.95的样子,每次执行结果不一样的原因是用random随机选取的数据进行测试的。
输出结果如下:
