前言
网上已经有很多的关于sharding-jdbc的使用,但是很多都是抄来抄去,说的也不是特别的完整,作者本来是闲来无事想跑起来试一下效果,但是找了一些文档都不是说的很明白。而且很多都是使用的是sharding-jdbc-core ,但是我们现在开发应该很少用spring mvc开发吧,大部分都是springboot开发,所以还是想用starter的方式。经历不断试错后搭建起最简单的、配置代码最少的测试案例。如果帮助到了你帮忙点赞啊。
一、引入依赖
- mybatis-spring-boot-starter
- sharding-jdbc-spring-boot-starter
- druid
<!-- 核心依赖-mybatis -->
<dependency>
<groupId>org.mybatis.spring.boot</groupId>
<artifactId>mybatis-spring-boot-starter</artifactId>
<version>2.1.4</version>
</dependency>
<!-- 核心依赖-mysql -->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<scope>runtime</scope>
</dependency>
<!-- 核心依赖-sharding-jdbc -->
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>sharding-jdbc-spring-boot-starter</artifactId>
<version>4.0.1</version>
</dependency>
<!-- 核心依赖-数据库连接池 -->
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid</artifactId>
<version>1.1.22</version>
</dependency>
需要注意的是,在这里使用的druid数据库连接池必须要用这个,如果用了druid的starter引用,需要将自动装配的类排除掉,否则也会自动去构建数据源,导致失败。
二、数据库表结构
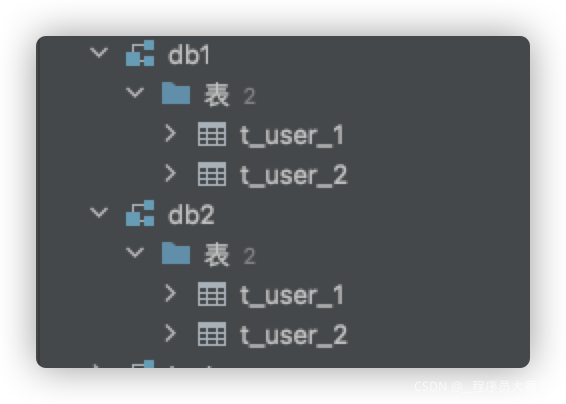
这里演示的是分库且分表,所以会有两个数据库,且每个数据库中有两个表,表结构都一致
db1: t_user_1 、 t_user_2
db2: t_user_1 、 t_user_2
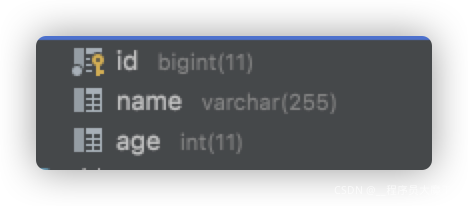
表结构为:
三、配置文件
# 应用服务 WEB 访问端口
server:
port: 8080
# 应用名称
spring:
application:
name: sharding-jdbc-test
shardingsphere:
# 是否打印sql
props:
sql:
show: true
datasource:
# 有几个库
names: db1,db2
# 库1 的配置
db1:
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://localhost:3306/db1?serverTimezone=CTT&useUnicode=true&characterEncoding=utf-8&allowMultiQueries=true
username: root
password: 123456
# 库2 的配置
db2:
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://localhost:3306/db2?serverTimezone=CTT&useUnicode=true&characterEncoding=utf-8&allowMultiQueries=true
username: root
password: 123456
sharding:
# 默认的库
default-data-source-name: db1
# 绑定的表 不配置也没找出啥问题
binding-tables: t_user
# 配置表的分片规则
tables:
# 指定某个表的分片配置
t_user:
# 这个配置是告诉sharding有多少个库和多少个表
actual-data-nodes: db$->{
1..2}.t_user_$->{
1..2}
#分库策略
database-strategy:
# 行表达式模式
inline:
# 选择需要分库的字段,根据那个字段进行区分
sharding-column: age
# 表达式,分库的算法,这个是通过年龄取模然后决定落到哪个库
algorithm-expression: db$->{
age % 2 + 1}
# 主键生成策略(如果是自动生成的,在插入数据的sql中就不要传id,null也不行,直接插入字段中就不要有主键的字段)
key-generator:
# 对应的数据库表的主键
column: id
# 生成方式, 雪花模式
type: SNOWFLAKE
# 配置表分片策略
table-strategy:
# 行表达式
inline:
# 配置表分片的字段
sharding-column: id
# 配置表分片算法
algorithm-expression: t_user_$->{
id % 2 +1}
mybatis.configuration.map-underscore-to-camel-case: true
四、代码配置
实际上到此为止,关于sharding-jdbc的配置已经完事了,剩下的就是mybatis的配置,可以和正常的CURD都一样了
mapper接口
public interface UserMapper {
/** 如果是主键自动生成的,切记不要传入id,否则会报错 */
@Insert("insert into t_user(name,age) values(#{name},#{age})")
void insert(UserModel user);
@Select("select * from t_user")
List<UserModel> selectAll();
@Select("select * from t_user where name like #{name}")
List<UserModel> selectLike(String name);
@Select("select * from t_user where name like #{name} limit 1")
List<UserModel> selectLikePage(String name);
}
model
@Data
public class UserModel {
private Long id;
private String name;
private Integer age;
}
启动类以及测试方法
@SpringBootApplication
@MapperScan(basePackages = "com.xxx.shard.shardingjdbctest.mapper")
public class ShardingJdbcTestApplication {
public static void main(String[] args) {
SpringApplication.run(ShardingJdbcTestApplication.class, args);
}
@RestController
class TestController{
@Resource
UserMapper userMapper;
@GetMapping("/add")
public Object add(){
UserModel model = new UserModel();
// model.setId(2);
model.setName("test2");
model.setAge(1);
userMapper.insert(model);
return "ok";
}
@GetMapping("/list")
public Object list(){
return userMapper.selectAll();
}
@GetMapping("/like")
public Object like(){
return userMapper.selectLike("%2%");
}
@GetMapping("/page")
public Object page(){
return userMapper.selectLikePage("%2%");
}
}
}
五、总结
这里的测试案例是分库分表最简单的配置,主要是为了初学者使用时体会一下效果,入门的搭建起来后面的公司项目才能一点一点进行复杂配置。