python爬虫学习29
五、Xpath的使用其四
5-11 多属性匹配
在之前我们学习了如何匹配一个拥有多值属性的节点,那么如何匹配拥有多个属性的节点呢?
这就要用到运算符
例如,我们稍稍修改一下这里的html节点

现在我们想要匹配那个同时拥有class与name节点下的a节点的内容:
from lxml import etree
html = etree.parse('./python.html', etree.HTMLParser())
# 使用 and 运算符连接两个属性
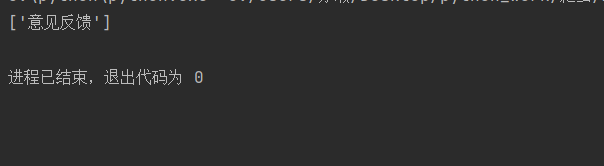
result = html.xpath('//li[contains(@class,"li") and @name="item"]/a/text()')
print(result)
运行结果:可以看到意见反馈被我们提取出来了
Xpath中的运算符

5-12 按序选择
像是之前我们获取节点时返回了许多符合的结果,若是我们想要点用其中的某一个或是第几个就要进行如下操作:
例如:还是这里的三个节点

# 按序获取
from lxml import etree
html = etree.parse('./python.html', etree.HTMLParser())
# 选取返回结果中的第一个结果 注意这里与我们在python进行索引时的区别
result0 = html.xpath('//li[1]/a/text()')
print(result0)
# 选取返回结果中的最后一个
result1 = html.xpath('//li[last()]/a/text()')
print(result1)
# 选取位置中小于等于2(前两个)的节点
result2 = html.xpath('//li[position()<=2]/a/text()')
print(result2)
# 获取最后一个结果前一个结果
result3 = html.xpath('//li[last()-1]/a/text()')
print(result3)
result = html.xpath('//li/a/text()')
print(result)
运行结果:

5-14 节点轴选择
一些常用的关于节点轴的调用方法:
# 节点轴选择
from lxml import etree as e
html = e.parse('./python.html', e.HTMLParser())
# 选取第一个li节点的所有祖先节点
result = html.xpath('//li[1]/ancestor::*')
print(result)
# 选取第一个li节点的特定的祖先节点(在::后面加想要获得的节点名)
result = html.xpath('//li[1]/ancestor::div')
print(result)
# 选取一个节点的所有属性 已知li节点中的class字段属性为“li”
result = html.xpath('//li[1]/attribute::*')
print(result)
# 选取li节点下的target属性为"_blank"的直接子节点a
result = html.xpath('//li[1]/child::a[@target="_blank"]')
print(result)
# 选取第一个ul节点下的所有a子孙节点
result = html.xpath('//ul[1]/descendant::a')
print(result)
# 选取当前节点下的所有节点
result = html.xpath('//ul[1]/following::*')
print(result)
# 选取当前节点后所有的同级节点
result = html.xpath('//li[1]/following-sibling::*')
print(result)
运行结果:

至此我们就已经基本掌握了Xpath的使用方法
今日结束,未完待续!