MySQL 04
SQL语句综合运用---我的租房网


创建如上这5张表,分别添加一些数据:
INSERT INTO `hos_district`(`DID`,`dName`) VALUES (1,'海淀'),(2,'朝阳'),(3,'丰台'); INSERT INTO `hos_house`(`hMID`,`UID`,`SID`,`hTID`,`price`,`topic`,`contents`,`hTime`,`copy`) VALUES (1,1,1,1,'800.00','万泉庄','万泉庄一号','2016-12-14 17:03:55',NULL),(2,1,1,2,'800.00','万泉庄','万泉庄二号','2016-04-14 17:03:55',NULL),(3,1,2,1,'800.00','苏州街','苏州街一号','2016-01-14 17:03:55',NULL),(4,1,2,3,'800.00','苏州街','苏州街二号','2016-09-14 17:03:55',NULL),(5,1,3,1,'800.00','中关村','中关村一号','2016-10-14 17:03:55',NULL),(6,1,3,3,'800.00','中关村','中关村二号','2016-03-14 17:03:55',NULL),(7,1,4,2,'800.00','东四','东四二号','2016-09-14 17:03:55',NULL),(8,1,4,1,'800.00','东四','东四一号','2016-11-14 17:03:55',NULL),(9,1,4,3,'800.00','东四','东四三号','2016-09-14 17:03:55',NULL); INSERT INTO `hos_street`(`SID`,`sName`,`sDID`) VALUES (1,'万泉庄',1),(2,'苏州街',1),(3,'中关村',1),(4,'东四',2),(5,'三里屯',2),(6,'望京',2); INSERT INTO `hos_type`(`hTID`,`hTName`) VALUES (1,'一室一厅'),(2,'两室一厅'),(3,'三室一厅'); INSERT INTO `sys_user`(`UID`,`uName`,`uPassWord`) VALUES (1,'张三','11111');
1.查询输出第6条~第10条出租房屋信息
我们可以使用limit实现查询数据分页显示
CREATE TEMPORARY TABLE lin( SELECT * FROM hos_house LIMIT 5,10 ); SELECT * FROM lin;
我们创建了一个临时表格(TEMPORARY)lin,查询结果如下:

结果数据来源于出租房屋信息表、客户信息表、区县信息表、街道信息表
(1).使用连接查询
SELECT `dName`,`sName`,h.* FROM `hos_house` AS h INNER JOIN `sys_user` AS u ON u.`UID`=h.`UID` INNER JOIN `hos_street` AS s ON s.`SID`=h.`SID` INNER JOIN `hos_district` AS d ON d.DID=s.`sDID` WHERE u.`uName`='张三'
就是一个简单的多表连接查询,只需挑选条件sys_user表中的uName的值为张三就行。
(2).子连接
SELECT (SELECT `dName` FROM `hos_district` AS d WHERE d.`DID`=s.`sDID`) AS '街道名',`sName`,h.* FROM `hos_house` AS h INNER JOIN `hos_street` AS s ON s.`SID`=h.`SID` WHERE h.`UID`=(SELECT `UID` FROM `sys_user` WHERE `uName`='张三')这里我们用到了 相关子查询(父查询执行一条,子查询一遍) [无关子查询 :子查询优先执行,返回的结果作为父查询的条件/表结构]
子查询可以添加在任何位置,这里我们在select中用子查询查询了区县信息表中区县信息表中DID与街道信息表sDID相同的区县名。
3.根据户型和房屋所在区县和街道,为至少有两个街道有出租房屋的区县制作出租房屋清单
我们可以使用having关键字来筛选出街道数量大于1的区县
SELECT `hTName`,u.`uName`,`dName`,`sName` FROM `hos_house` AS h INNER JOIN `hos_type` AS t ON t.hTID = h.`hTID` INNER JOIN `hos_street` AS s ON s.`SID`=h.`SID` INNER JOIN `hos_district` AS d ON d.DID=s.`sDID` INNER JOIN `sys_user` AS u ON u.`UID`=h.`UID` WHERE d.DID IN ( SELECT sDID FROM `hos_street` WHERE SID IN( SELECT SID FROM `hos_house` GROUP BY SID) GROUP BY sDID HAVING COUNT(*)>1 )
我们先看where条件中的SQL代码,它查询了区县表中的区县ID是否在括号其中,括号中查询的的为街道表的区域SDID,且满足街道SID在房屋出租表中的SID中,并且根据SDID分组,最后筛选出有1条街道以上有房屋出租的区域。之后则是一个简单的5表联合查询出`hTName`,u.`uName`,`dName`,`sName`。
**4.按季度统计出本年各区县各街道各种户型房屋出租数量
输出2016年从1月1日起至今的全部出租房屋数量、各区县出租房屋数量及各街道、户型出租房屋数量
SELECT QUARTER(hTime) AS 季度,' 合计' AS 区县,'' AS 街道,'' AS 户型,COUNT(*) AS 出租数量 FROM `hos_house` GROUP BY 季度 UNION SELECT QUARTER(hTime) AS 季度,dname AS 区县,' 小计' AS 街道,'' AS 户型,COUNT(*) AS 出租数量 FROM `hos_house` AS h INNER JOIN `hos_street` AS s ON s.SID=h.SID INNER JOIN `hos_district` AS d ON d.did=s.sdid GROUP BY 季度,d.did UNION SELECT QUARTER(hTime) AS 季度,dname AS 区县,sName AS 街道,htname AS 户型,COUNT(*) AS 出租数量 FROM `hos_house` AS h INNER JOIN `hos_street` AS s ON s.SID=h.SID INNER JOIN `hos_district` AS d ON d.did=s.sdid INNER JOIN `hos_type` AS t ON t.`hTID`=h.`hTID` GROUP BY 季度,d.did,s.sid,t.`hTID` ORDER BY 1,2,3,4
union的作用
UNION 用于合并两个或多个 SELECT 语句的结果集,并消去表中任何重复行。
UNION 内部的 SELECT 语句必须拥有相同数量的列,列也必须拥有相似的数据类型。同时,每条 SELECT 语句中的列的顺序必须相同.
因为union连接的select语句必须拥有相同数量的列,在第一个select查询中,我们在房屋出租表hos_house中首先查询了季度,定义了一个常量列区县为合计,街道、户型为空列,最后一个按照季度分组统计了数量,及各个季度有多少出租的;
第二个select查询为一3表联合查询,分别为房屋表,街道表,区县表,任查询了季度,dname另名为区县,设置街道为常量列'合计',户型为空列,按照季度与区名分组统计了数量,及统计了各个季度有多少出租的还有各个区县有多少出租的;
第三个select查询为4表联查,添加了一个户型表hos_type,查询了季度,dname区县,sname街道,htname户型,以及按照季度,区名,街道名,户型分组统计数量,统计了各个季度,各个区县,各个街道,各个户型分别有多少出租的。
最后我们使用order by 使其按照季度名1,2,3,4排序。有因为我们在合计常量列与小计常量列前加了空格,使其排序在前。具体查询结果如下:
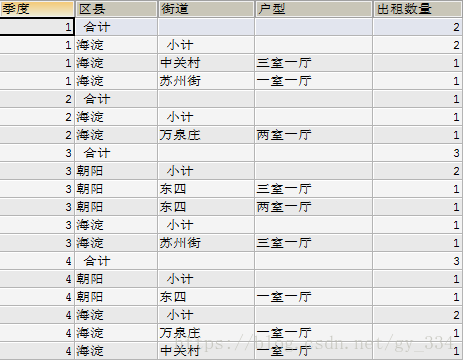
如果觉得结果不够明显我们可以再添加一些数据,使结果更明显。