目录
mnist数据集
本博客api参考:(深度学习入门(斋藤康毅著))
机器学习领域经典数据集
由0-9的数字图像(28x28=784)构成,训练图像6万张,测试图像1万张
数据集下载地址:
一种调用数据集的api(压缩包格式)
对于第一个压缩包格式的数据集,下载之后它是这个样子的
它的扩展名比较奇怪,一般的软件不能以可视化的形式将其呈现出来,这让我们觉得这个压缩包就像一个黑盒子,不知道里面装的什么东西
对于该数据集的理解
我们先来看看数据集的提供者Yunn LeCun先生为我们提供的一些信息,具体请参考原文
信息解读1

这段信息的大致意思为:
现有一种专门用于存储向量和多维矩阵的文件格式(特殊的文件格式,怪不得一般软件打不开),我提供的数据集就是以该种文件格式保存的,我已经将该文件格式的一般信息放在了这个页面的末尾,但是如果你仅仅是想要使用该文件格式你并不需要去看。
对于大多数非因特尔处理器,文件中的所有整数都以高位优先的格式存储,因特尔处理器用户和其他低端机用户都必须反转头字节
信息解读2

这段信息的大致意思为:
训练数据集包含6万张图片,测试数据集1万张
测试集的前5000张图片来自于原始的NIST训练数据集,后5000张图片来源于原始的NIST测试数据集,前5000张图片更加洁净(噪声小)和简单
信息解读3
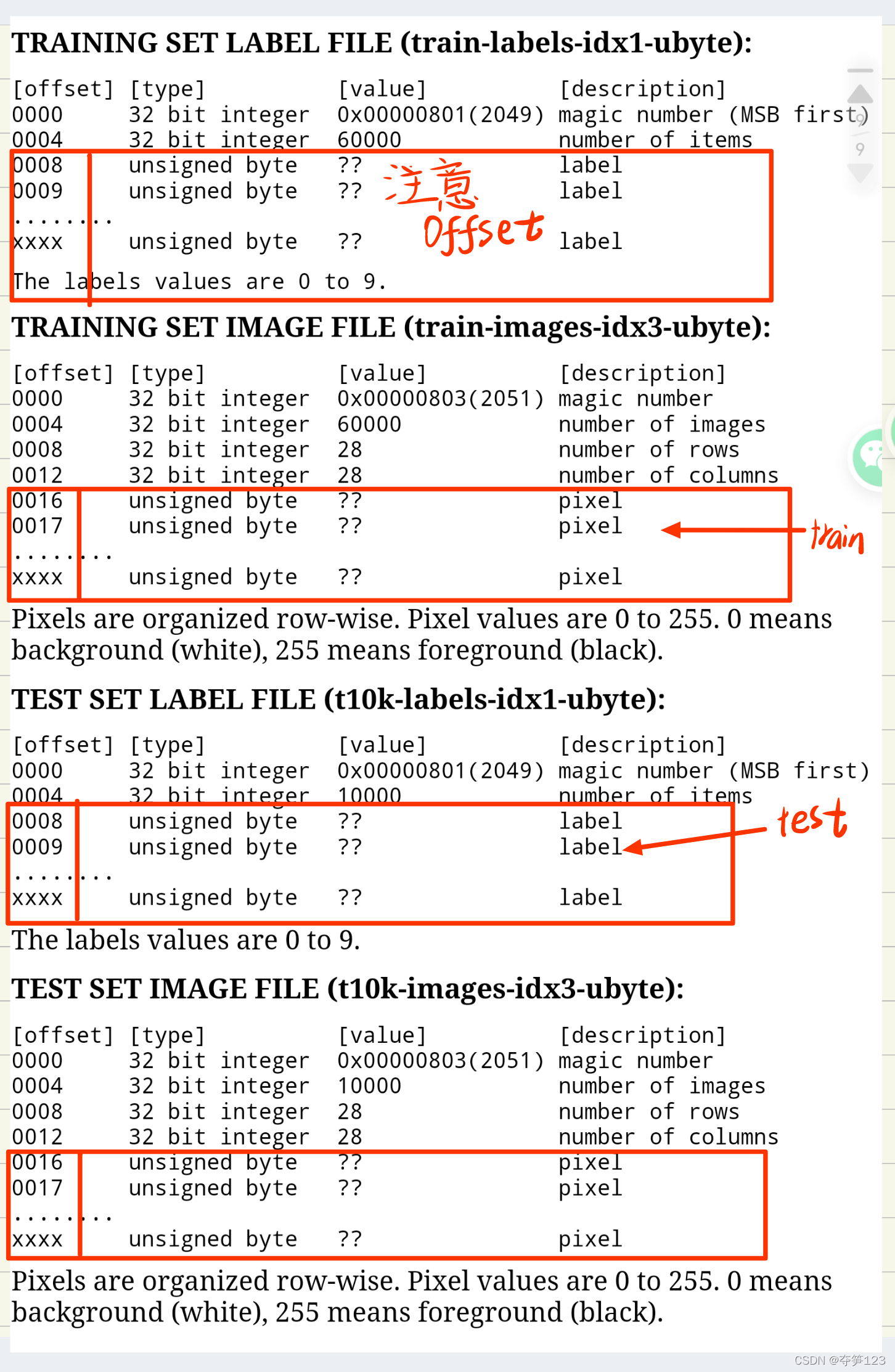
offset代表偏移量,这个参数非常重要,它表示数据集中包含了一些包括数据集本身信息的数据。比如测试数据集的标签集offset=8时才出现description=label的数据,表示真正的标签数据应从offset处开始读取
我们尝试用表格表示上述压缩包中数据的特征
| 压缩包名称 | 压缩包中包含的数据 意义 | offset(表示此处之后的数据对我们有真实意义) |
|---|---|---|
| train-images-idx3-ubyte.gz | 训练集数据 | 16 |
| train-labels-idx1-ubyte.gz | 训练集标签 | 8 |
| t10k-images-idx3-ubyte.gz’ | 测试集数据 | 16 |
| t10k-labels-idx1-ubyte.gz | 测试集标签 | 8 |
解压数据集并将其中的数据转化为Numpy数组
操作步骤
- 准备一个字典容器dataset用于存储(训练数据,训练标签),(测试数据,测试标签)
- 将图像数据和标签分别从对应的压缩包中解压出来(使用到了gzip库),转化为numpy数组(使用到了np.frombuffer()函数),存储在上面的字典容器中
使用gzip解压缩
gzip.open(filename, mode='rb', compresslevel=9, encoding=None, errors=None, newline=None)
使用二进制模式或文本模式打开gzip压缩文件,返回file object(此处为二进制流)
主要参数
| 参数 | 描述 |
|---|---|
| filename | 待打开的gzip压缩文件 |
| mode | 可以是用于二进制模式的 ‘r’,‘rb’,‘a’,‘ab’,‘w’,‘wb’,‘x’ 或 ‘xb’ 中的任何一个,或者对于文本模式是 ‘rt’,‘at’,‘wt’ 或 ‘xt’ 中的任何一个。默认值为 ‘rb’。 |
file object(文件对象),又称file-like object(文件状对像)或steams(流),关于流的知识属于数据i/o的python的底层知识,这个讲解起来非常麻烦,笔者在撰写到这个地方时查阅了很多资料,很多次都绕了进去,而且始终没有想到一个好的角度来解释这个东西,我们先往下看
关于numpy.frombuffer()函数
numpy.frombuffer(buffer, dtype=float, count=- 1, offset=0, *, like=None)
将一个缓冲区转换为一维数组(将一个数据以流的形式读入转化为ndarray对象),返回类型:ndarray
主要参数
| 参数 | 描述 |
|---|---|
| buffer | 一个缓冲区对象 |
| *dtype | 返回数组中元素的类型 |
| *count | 要读取的项数,默认读取所有数据项 |
| *offset | 开始读取缓冲区数据的位置(以字节为单位) |
到现在为止我们大概认识了gzip.open()函数和np.frombuffer()函数
下面我们尝试使用gzip.open()函数打开压缩包获取有关mnist的数据,并且使用np.frombuffer()函数将这些字节型的数据转换为numpy数组
with open('train-images-idx3-ubyte.gz','rb') as f:
data=np.frombuffer(f.read(),np.uint8,offset=16)
关于buffer缓冲区,这也是一个底层知识,我们在这里就先认为f.read()就是一个缓冲区(实际上这是不对的),但是我们的目的是得到:(训练数据,训练标签),(测试数据,测试标签),因此我们暂时先不要纠结这个问题1
代码实现
def load_label(filename):
filepath=dataset_dir+os.sep+filename
print('converting'+filename+'to numpy array')
with gzip.open(filepath,'rb')as f:
labels = np.frombuffer(f.read(), np.uint8, offset=8)
return labels
def load_img(filename):
filepath=dataset_dir+os.sep+filename
print('converting'+filename+'to numpy array')
with gzip.open(filepath,'rb') as f:
data = np.frombuffer(f.read(), np.uint8, offset=16)
data = data.reshape(-1, img_size)
print("Done")
return data
最终api
我们的目的是分别得到(训练数据,训练标签),(测试数据,测试标签)。下面笔者提供一种获取数据的api(参考书籍:深度学习入门(斋藤康毅著))
import os
import pickle
import gzip
import numpy as np
img_size=784
# filepath =r'?:/??/.../' # 使用前请将该地址修改为压缩包保存的地址
# save_file =r'?:/??/.../ ' +'my_mnist.pkl' # 使用前将该地址修改为pkl文件的保存地址
filepath=r'E:\others\ITbooks\deep_learning_entry\contents\dataset'
save_file='my_mnist.pkl'
key_file = {
'train_img' :'train-images-idx3-ubyte.gz',
'train_label' :'train-labels-idx1-ubyte.gz',
'test_img' :'t10k-images-idx3-ubyte.gz',
'test_label' :'t10k-labels-idx1-ubyte.gz'
}
def load_label(filename):
path =filepath+os.sep+filename
with gzip.open(path ,'rb' )as f:
labels = np.frombuffer(f.read(), np.uint8, offset=8)
return labels
def load_img(filename):
path =filepath +os.sep +filename
with gzip.open(path ,'rb') as f:
data = np.frombuffer(f.read(), np.uint8, offset=16)
data = data.reshape(-1, img_size)
return data
def convert_numpy():
dataset = {
}
dataset['train_img'] = load_img(key_file['train_img'])
dataset['train_label'] = load_label(key_file['train_label'])
dataset['test_img'] = load_img(key_file['test_img'])
dataset['test_label'] = load_label(key_file['test_label'])
return dataset
def init_mnist(): # 将dataset序列化存储为一个pkl文件,下次需要使用mnist数据集时直接从该文件反序列化为dataset即可,而不再需要重复的解压压缩包
dataset =convert_numpy()
with open(save_file ,'wb') as f:
pickle.dump(dataset ,f ,-1)
print('done!!!')
def _change_one_hot_label(X) :# 将标签值转化为one-hot向量,如标签为2,其对应的one-hot标签就是[0,0,1,0,0,0,0,0,0,0]
T = np.zeros((X.size, 10))
for idx, row in enumerate(T):
row[X[idx]] = 1
return T
def load_mnist(normalize=True, flatten=True, one_hot_label=False):
"""读入MNIST数据集
Parameters
----------
normalize : 将图像的像素值正规化为0.0~1.0
one_hot_label :
one_hot_label为True的情况下,标签作为one-hot数组返回
one-hot数组是指[0,0,1,0,0,0,0,0,0,0]这样的数组
flatten : 是否将图像展开为一维数组
Returns
-------
(训练图像, 训练标签), (测试图像, 测试标签)
"""
if not os.path.exists(save_file):
init_mnist()
with open(save_file, 'rb') as f:
dataset = pickle.load(f)
if normalize: # 归一化,将0-255的像素值转化到0-1之间
for key in ('train_img', 'test_img'):
dataset[key] = dataset[key].astype(np.float32)
dataset[key] /= 255.0
if one_hot_label:
dataset['train_label'] = _change_one_hot_label(dataset['train_label'])
dataset['test_label'] = _change_one_hot_label(dataset['test_label'])
if not flatten:
for key in ('train_img', 'test_img'):
dataset[key] = dataset[key].reshape(-1, 1, 28, 28)
return (dataset['train_img'], dataset['train_label']), (dataset['test_img'], dataset['test_label'])
if __name__=='__main__':
aa=load_mnist()
print(aa[0][0].shape)
print(aa[0][1].shape)
print(aa[1][0].shape)
print(aa[1][1].shape)
'''
(60000, 784)
(60000,)
(10000, 784)
(10000,)
'''
api中一些小问题的理解
关于os.sep
请查看博客:os模块
对于reshape(-1)的理解
reshape(-1,784)
注意到load_img()函数中将压缩包解压后,有一段这样的代码data=data.reshape(-1,784),如何理解?
我们往下看
filepath='t10k-images-idx3-ubyte.gz'
with gzip.open(filepath,'rb') as f:
data = np.frombuffer(f.read(), np.uint8, offset=16)
print(data.shape)
data = data.reshape(-1, 784)
print(type(data))
print(data.shape)
'''
(7840000,)
<class 'numpy.ndarray'>
(10000, 784)
'''
看到上面代码的运行结果我想你们大概都明白了,data=data.reshape(-1,784)的意思就是,我不知道要将这个数据要分为几行(每行代表一个图像数据,尽管我们已经知道mnist的训练集有10000个图片,但这样处理会更好),但我知道每行多少数据,那我就使用这种模糊的方法,只给出我知道的信息,你给我把数据多少行分出来就完事了
reshape(-1,1,28,28)
原来的每一张图片信息都保存在一个含有784个元素的一维数组中,它的形状是(784,),此处的reshape(-1,1,28,28)将这个一维数组的形状转换为(1,1,28,28),我们看下面一个例子
import numpy as np
aa=np.arange(36)
print(aa.shape)
print(aa)
a=aa.reshape(-1,1,6,6)
print(a.shape)
print(a)
'''
(36,)
[ 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23
24 25 26 27 28 29 30 31 32 33 34 35]
(1, 1, 6, 6)
[[[[ 0 1 2 3 4 5]
[ 6 7 8 9 10 11]
[12 13 14 15 16 17]
[18 19 20 21 22 23]
[24 25 26 27 28 29]
[30 31 32 33 34 35]]]]
'''
实际上此处数组形状转化的意义多用于为卷积神经网络提供输入层数据
假设现在有一张图片要作为卷积神经网络的输入(如果我们已经知道它的长宽(a,b),那么这个输入值形状(a,b)),卷积神经网络首先要分析它的RGB色彩值,然后再分析图片的长和宽。如果该图片有色彩,那么将这个图片分为三张分别为R、G、B,于是输入值形状变成了(3,a,b);如果该图片没有色彩,那么输入值形状就变成了(1,a,b)
我们下面再来看看api中的代码
for key in ('train_img', 'test_img'):
dataset[key] = dataset[key].reshape(-1, 1, 28, 28)
| 形状 | |
|---|---|
| dataset[‘train_img’] | (60000,784) |
| dataset[‘test_img’] | (10000,784) |
我们看看这段代码的作用
filepath='mnist.pkl' # mnist.pkl文件是我们生成的序列化数据,里面包含了mnist数据集中的所有数据,请往下看
with open(filepath, 'rb') as f:
dataset = pickle.load(f)
for key in ('train_img', 'test_img'):
print(dataset[key].shape)
dataset[key] = dataset[key].reshape(-1, 1, 28, 28)
print(dataset[key].shape)
'''
(60000, 784)
(60000, 1, 28, 28)
(10000, 784)
(10000, 1, 28, 28)
'''
ok! 到这里我们应该理解了api中所有关于reshape()的内容!
浅谈one-hot编码
在机器学习领域中,经常会遇到分类 问题,这些分类类别往往不是连续值而是离散且无序的,如mnist手写数字会被分为0-9等10种类别
定义
独热编码,使用N位状态寄存器来对N个状态进行编码,每个状态都有它独立的寄存器位,并且在任意时候,其中只有一位有效。
如何理解
我们已经知道,一张手写数字图片未被正确分类前的标签可能为(0-9)中的任意一个,所以我们可以称这张图片的标签有10个状态,然而我们都知道这张图片上面的数字只可能是0-9中的一个,假设这个图片的标签为2,那么它对应的独热编码就是
[0,0,1,0,0,0,0,0,0,0]

代码中的change_one_hot()函数
我们只需要将训练集标签和测试集标签转化为one-hot码即可
T=np.zeros((X.size,10))
训练集标签有60000个,测试集标签10000个,此处代码生成针对每一个标签都生成一个对应的一维数组[0,0,0,0,0,0,0,0,0,0]
此时T是一个(60000,10)或(10000,10)的数组
for idx,row in enumerate(T):
row(X[idx])=1 # 其中X[idx]代表[0,0,0,0,0,0,0,0,0]中的有效位的索引
如果还不理解我们下面举个例子
import numpy as np
daa=np.zeros((6,2))
print(daa)
for i,j in enumerate(daa):
print(i,j)
'''
[[0. 0.]
[0. 0.]
[0. 0.]
[0. 0.]
[0. 0.]
[0. 0.]]
0 [0. 0.]
1 [0. 0.]
2 [0. 0.]
3 [0. 0.]
4 [0. 0.]
5 [0. 0.]
'''
pickle库序列化数据
pickle库提供了一个简单的持久化功能。可以将对象以文件(.pkl或.pickle)的形式存放在磁盘上。python中几乎所有的数据类型(列表,字典,集合,类等)都可以用pickle来序列化
序列化及反序列化的概念我们这里不再叙述,在这里我们只需要知道:我们上面创建的dataset是一个字典,里面保存了mnist数据集的所有数据,它是通过解压压缩包得到的,如果不不将它以文件的形式保存在磁盘中,我们每次使用mnist数据集都需要解压缩来获得,pickle的出现就是为了解决上面的问题
另外,pkl或pickle等文件经常在机器学习过程中保存神经网络的权重参数
序列化(将对象转换为文件保存)
pickle.dump(obj, file, protocol=None, *, fix_imports=True)
主要参数
| obj | 待持久化存储的对象(列表,字典,集合,类等) |
| file | 文件名,如’mnist.pkl’或‘mnist.pickle’ |
| protocol | 序列化协议,(上面该值为-1,是python3的一种专用的序列化协议) |
反序列化(将pkl等文件转换为对象)
pickle.load(file, *, fix_imports=True, encoding="ASCII", errors="strict")
主要参数
| 参数 | 描述 |
|---|---|
| file | 文件名 |
举例
import pickle
save_file='key.pickle'
key_file = {
'train_img':'train-images-idx3-ubyte.gz',
'train_label':'train-labels-idx1-ubyte.gz',
'test_img':'t10k-images-idx3-ubyte.gz',
'test_label':'t10k-labels-idx1-ubyte.gz'
}
with open(save_file,'wb') as f:
pickle.dump(dataset,f,-1)
我们生成了一个pickle文件

下面我们使用pickle.load()方法将其打开
with open(save_file, 'rb') as f:
dataset = pickle.load(f)
print(type(dataset))
for i,j in dataset.items():
print(i,j)
'''
<class 'dict'>
train_img train-images-idx3-ubyte.gz
train_label train-labels-idx1-ubyte.gz
test_img t10k-images-idx3-ubyte.gz
test_label t10k-labels-idx1-ubyte.gz
'''
对于数据流和buffer的理解,也许下面的博客会有帮助:mayavii的博客 ↩︎