来源我的GitHub博客 点击更好的阅读体验 Addicted to Learning
网络上深度学习相关博客教程质量参差不齐,很多细节很少有文章提到,所以本着夯实深度学习基础的想法写下此系列博文。
本文会从神经网络的概述、不同框架的公式推导和对应的基于numpy的Python代码实现等方面进行干货的讲解。如有不懂之处欢迎在评论留言,本人也初学机器学习与深度学习不久,有不足之处也请欢迎我联系。:)
推荐书籍与视频教程:
《机器学习》--周志华
《Deep learning》--Ian Goodfellow、Yoshua Bengio 和 Aaron Courville
李宏毅深度学习视频课程-youtube Bilibili
神经网络
神经网络是由具有适应性的简单单元组成的广泛并行互连的网络,它的组织能够模拟生物神经系统对真实世界物体所作出的交互反应。
神经网络最基本的组成是神经元模型,每个神经元与其他神经元相连,神经元接受到来自 \(n\) 个其他神经元传递过来的输入信号,这些信号通过带有权重的连接进行传递,神经元接收到的总输入值将于阈值进行比较,然后通过“激活函数”处理产生输出。把许多神经元按一定层次结构连接起来就得到了神经网络。
感知机模型
感知机模型(Perceptron)由两层神经元组成,分别是输入层与输出层。
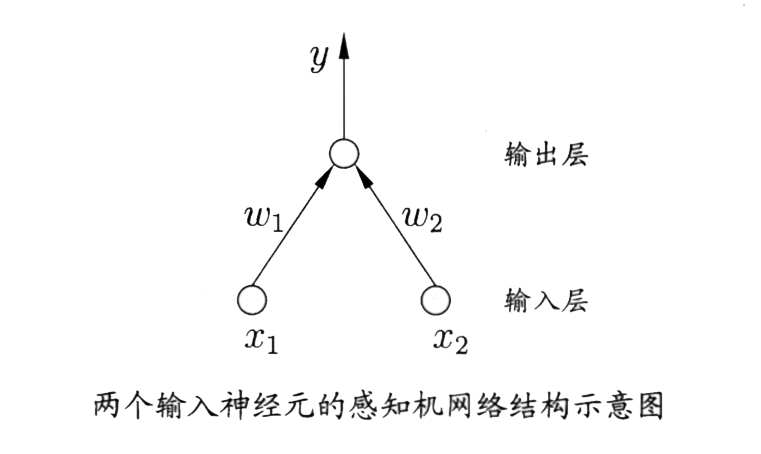
感知机模型是最为基础的网络结构,其计算形式如下
\[ y=f\left(\sum_i\omega_ix_i+b\right)\]
其中 \(f\) 为激活函数。我们先假设 \(f\) 是阶跃函数(Step function)。
def sign(out):
"""
y = sign(w·x + b)
:param out - the result of w·x + b
:return: y
"""
if out >= 0:
return 1
else:
return -1感知机的学习规则非常简单,对于训练样本 \((x,y)\),若当前感知机的输出为 \(\hat{y}\),则感知机参数更新方式如下
\[ \begin{align} \omega &\leftarrow \omega_i + \Delta\omega_i & \Delta\omega_i &= \eta\ (y-\hat{y})\ x_i \nonumber\\ \qquad& \nonumber\\ b_i &\leftarrow b_i + \Delta b_i & \Delta b_i &= \eta\ (y-\hat{y}) \nonumber \end{align} \]
其中 \(\eta\) 称为学习率(learning rate)
下面我们使用Python来实现感知机进行分类:
# 初始化变量w,b
w = np.zeros(shape=data[0].shape)
b = np.zeros(shape=label[0].shape)
def update(x, y, learning_rate):
"""
当发现误分类点时,更新参数w,b.
更新方法:
w = w + learning_rate * x * y
b = b + learning_rate * y
:param x: 误分类点坐标
:param y: 误分类点正确分类标签
:return: None
"""
global w, b
w = w + learning_rate * x * y
b = b + learning_rate * y
假设训练集是线性可分的。更新过程便是,遍历全部的训练实例,通过感知机的计算方式计算出结果 \(y\) 与对应标签进行比较(感知机标签一般为 1 和 -1),如果误分便使用updata()进行参数更新。下图是感知机线性分类的拟合过程。
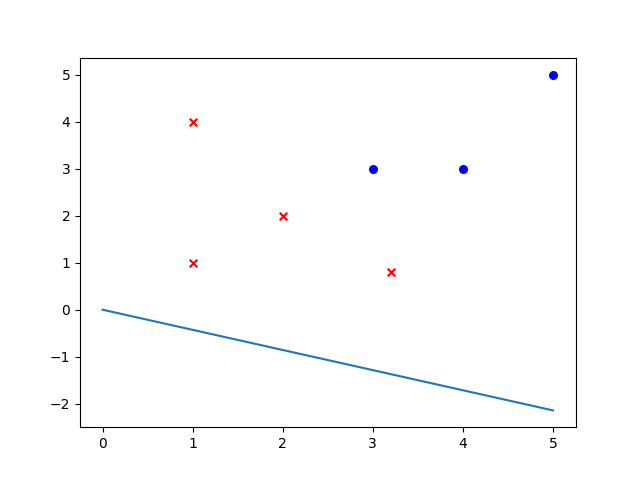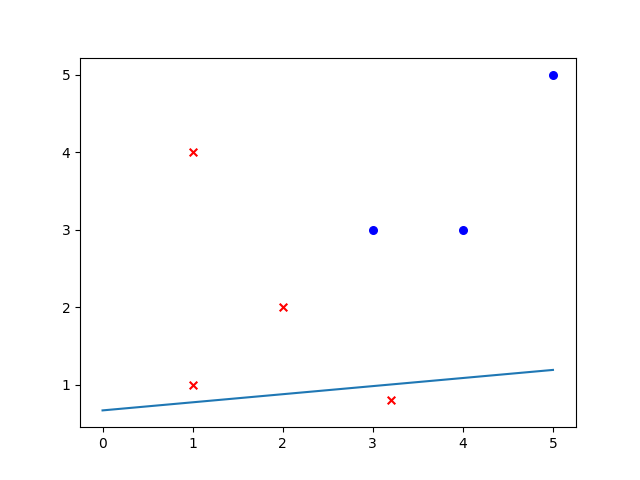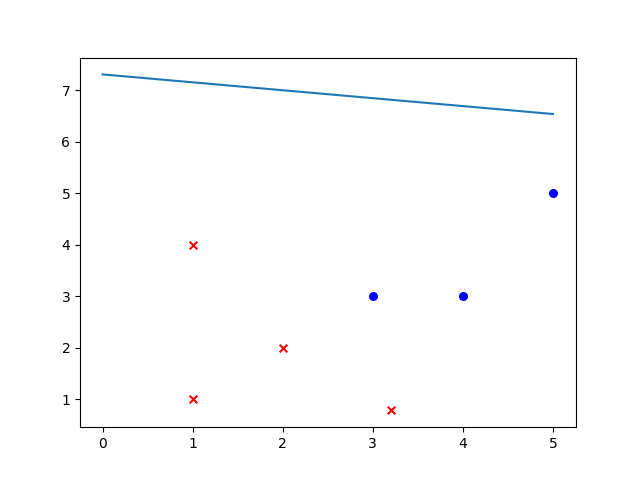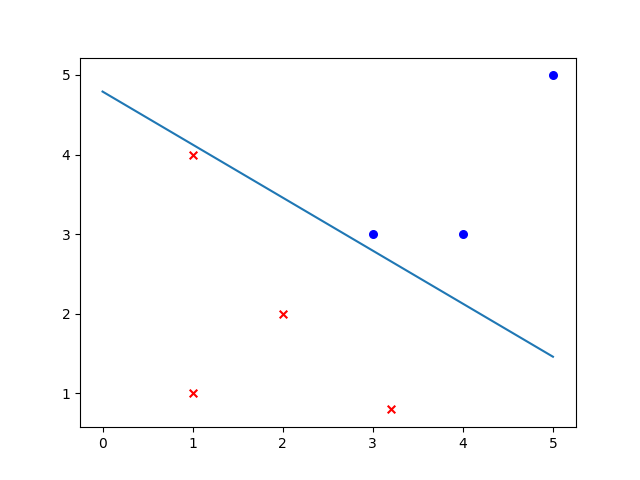
随意写的训练数据
# x
[[3.2, 0.8], [5, 5], [3, 3], [4, 3], [1, 1], [2, 2], [1, 4]]
# y
[-1, 1, 1, 1, -1, -1, -1]感知机只有输入层和输出层,且只有输出层神经元进行激活处理,即只有一层功能神经元,其学习能力非常有限。如果问题是非线性可分问题,那么感知机会发生振荡,无法收敛。
多层网络
为了解决非线性可分问题,那么便需要采用多层功能神经元,如简单的两层感知机。如图

其中输入层与输出层之间一层被称为隐藏层(隐含层),隐藏层和输出层都是拥有激活函数的功能神经元。一般情况下,隐藏层可以有多层,同层神经元之间不存在连接,也不存在跨层连接。这样的神经网络结构被称为多层前馈神经网络(multi-layer feedforward neural networks)
因多层功能神经元的存在,多层网络的学习能力要强得多,同时简单的感知机学习规则显然已经无法满足要求。更强大的学习算法,误差逆传播(error BackPropagation)算法,即BP算法便是最成功的神经网络学习算法。
TODO
在下一篇博文中,我们将使用BP算法来实现“全连接网络”。