信息化与互联网的浪潮正冲击着社会的各个角落,而航空“数据化”越来越被重视,它已经被誉为是新时代的“石油和原材料”,成为企业未来发展的新能源与动力。航空领域的发展也在此阶段进一步得到重视,无论是国有航空还是民营航空,日益增加的数据信息、错综复杂的航线信息,这些数据都在爆炸式增长,如何利用好数据并发挥最大化作用,才是航空业面临的巨大挑战和机遇。
在航空业中,通过大数据来进行客户价值分析,进行精准营销,根据客户偏好、活跃度来发现潜在可转化为会员的客户。通过对会员的乘坐反馈,来多样化分析存在的不足,为旅客提供更加舒适的出行体验。而大数据的另一个领域数据挖掘,也同样可以在海量数据中提取出有用信息,来为航空公司提供 5-10 年的战略决策。
一、数据清洗与处理部分
数据清洗与处理说明:
1、数据清洗与处理采用的技术是pandas+numpy
2、数据清洗与处理代码中有详细注释
3、数据清洗与处理策略
- 数据集中存在大量的缺失值,但是因为缺失值所属的行数据也具有一定的价值,因此我们不能够将所有的缺失值行数据删除,我们需要将几个重要的字段为空的数据删除,针对于航空数据集,我们需要删除“航段距离”、“出发城市”,“到达城市”为空的行数据。
- 数据字段“每旅客分摊收入”存在大量空值,这将影响我们后续对数据的统计,因此我们需要将“每旅客分摊收入”为空的数据通过平均值来进行填充,解决思路是将所有不为空的“每旅客分摊收入”进行累加并求出不为空数据的数量,通过做商求出并均值进行填充。
- 数据中的日期形式为yyyy-mm-dd,此格式数据无法帮助我们进行数据的统计和分析,因此我们需要对数进行年、月、日的抽取,这里需要先将数据转换成Pandas的日期类型,再使用DatetimeIndex函数对数据进行年、月、日的划分,划分后,我们就可以通过使用.year或者.month的方式来获取想要的时间值,并将其作为新列添加到数据集中。
- 这里为了让数据分析有更好的效果,我们将数据中时间所对应的节假日时间区间通过字典的方式进行映射,然后通过apply函数对数据进行批量映射更换,并作为新列进行添加,将非节假日期间则用“正常日”进行填充。
代码展示
# 对数据进行处理和清洗
def process_data(df):
# 数据的缺失值不均衡 每旅客分摊收入 缺失值较多 可以通过填充来处理
# 航段距离 出发城市 到达城市 存在少量缺失值可直接去除所在行数据
df = df.copy()
df.dropna(subset=['航段距离','出发城市','到达城市'],inplace=True)
df = df[df['每旅客分摊收入'].apply(lambda x:not x == 'net_amt')]
# 将缺失值按照平均值进行填充
net_amt = df[df['每旅客分摊收入'].apply(lambda x:x is not np.NaN)]['每旅客分摊收入'][1:]
net_amt = [float(i) for i in net_amt]
avg = round(sum(net_amt)/len(net_amt),2)
df.fillna(avg,inplace=True)
df['每旅客分摊收入'] = df.loc[:,'每旅客分摊收入'].apply(lambda x:float(x))
# 构造坐客率字段
df['航节主舱位运力量'] = df['航节主舱位运力量'].astype(np.int)
df['旅客量'] = df['旅客量'].astype(np.int)
df['航段距离'] = df['航段距离'].astype(np.float)
df.eval('座公里=航节主舱位运力量*航段距离',inplace=True)
df.eval('客公里=旅客量*航段距离',inplace=True)
# 因为座公里为被除数 所以不能为0 将座公里为零的部分转换成1
df['座公里'] = df['座公里'].apply(lambda x:1 if x==0.0 else x)
df.eval('客座率=客公里/座公里', inplace=True)
old_date = df['承运日期']
# 将承运日期分别提取出来为年、月、日
df['承运日期'] = pd.to_datetime(df['承运日期'])
date = pd.DatetimeIndex(df['承运日期'])
df['年'] = date.year
df['月'] = date.month
df['日'] = date.day
df['周'] = df['承运日期'].dt.dayofweek
df['承运日期'] = old_date
# 转换数据类型
df['航段起飞小时'] = df['航段起飞小时'].astype(np.int)
df['航段起飞分钟'] = df['航段起飞分钟'].astype(np.int)
df['航段到达小时'] = df['航段到达小时'].astype(np.int)
df['航段到达分钟'] = df['航段到达分钟'].astype(np.int)
df['Y舱基准价'] = df['Y舱基准价'].astype(np.float)
# 计算飞机飞行时长
df["飞行时长"] = (df['航段到达小时']-df['航段起飞小时'])*60+(df['航段到达分钟']-df['航段起飞分钟'])
df["飞行时长"] = df["飞行时长"].apply(lambda x:x+24*60 if x<0 else x)
# 处理承运日期 将承运日期按照具体节假日时间段进行划分 并构造新列 节假日
# df['承运日期'] = pd.to_datetime(df['承运日期'])
festival = []
for i in df['承运日期'].tolist():
if i in ['2012-05-01','2012-05-02','2012-05-03','2012-05-04','2012-05-05']:
festival.append('劳动节')
elif i in ['2012-06-12','2012-06-13','2012-06-14']:
festival.append('端午节')
elif i in ['2012-09-19','2012-09-20','2012-09-21']:
festival.append('中秋节')
elif i in ['2012-10-01','2012-10-02','2012-10-03','2012-10-04','2012-10-05','2012-10-06','2012-10-07']:
festival.append('国庆节')
else:
festival.append('正常日')
df['节假日'] = festival
return df
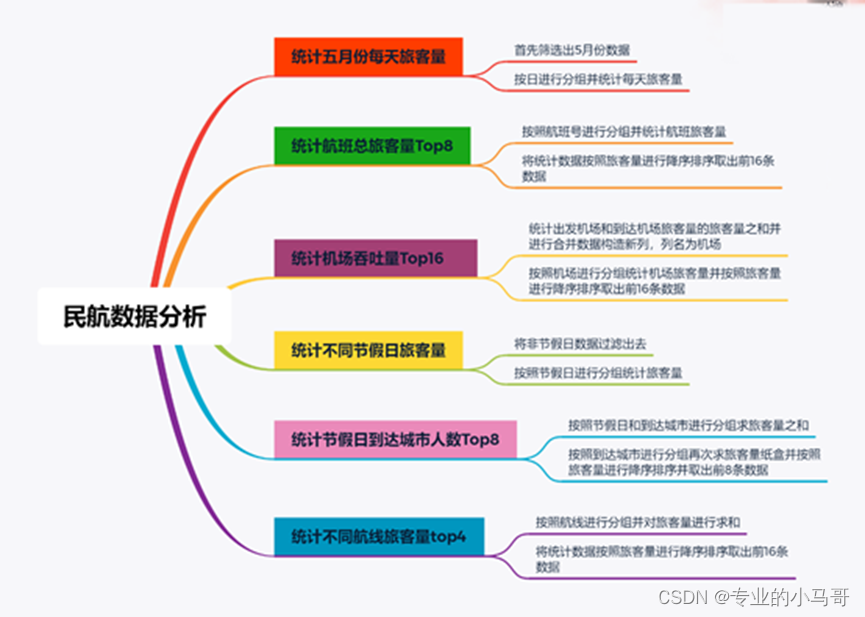
二、数据分析部分
数据分析说明:
1、数据分析采用的技术是pandas+numpy
2、数据分析策略
代码展示
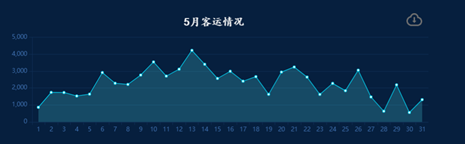
# 统计五月份每天的总旅客量
def date_traveler_count(df):
# 过滤出月份为5的数据
df = df[df['月']==5]
# 按照日进行分组统计旅客量总和
grouped = df.groupby('日')['旅客量'].sum().reset_index()
data = [[i['日'],i['旅客量']] for i in grouped.to_dict(orient="records")]
# print(data)
return data
# 统计航班总旅客量Top8
def flight_traveler_count(df):
# 按照航班号进行分组统计旅客量总和 并按照旅客量进行排序 取出旅客量前八的数据
grouped = df.groupby('航班号')['旅客量'].sum().reset_index().sort_values(ascending=False,by='旅客量')[:8]
data = [[i['航班号'],i['旅客量']] for i in grouped.to_dict(orient="records")]
# print(data)
return data
# 统计节假日到达城市人数Top8
def festival_city_count(df):
# 按照节假日和到达城市进行分组 统计旅客量总和
grouped_b = df.groupby(['节假日','到达城市'])['旅客量'].sum().reset_index()
# 再按照到达城市进行分组并 统计旅客量总和 并按照旅客量进行排序 取出旅客量前八的数据
grouped_s = grouped_b.groupby('到达城市')['旅客量'].sum().reset_index().sort_values(by='旅客量',ascending=False)[:8]
data = [[i['到达城市'], i['旅客量']] for i in grouped_s.to_dict(orient="records")]
# print(data)
return data
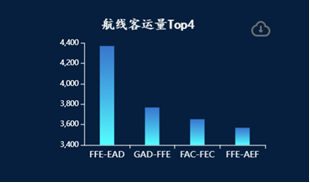
# 统计不同航线旅客量top4
def airline_traveler_count(df):
# 按照航班航线进行分组 统计旅客量总和 再按照旅客量进行排序 取出旅客量前四数据
grouped = df.groupby('航班航线')['旅客量'].sum().reset_index().sort_values(by='旅客量',ascending=False)[:4]
data = [[i['航班航线'], i['旅客量']] for i in grouped.to_dict(orient="records")]
# print(data)
return data
# 统计机场出、入港旅客量(吞吐量)Top16
def airport_traveler_count(df):
# 先按照出发城市进行分组
grouped_go = df.groupby('出发机场')['旅客量'].sum().reset_index()
# 先按照到达城市进行分组
grouped_arrive = df.groupby('到达机场')['旅客量'].sum().reset_index()
# 将列名进行统一并合并
grouped_go.rename(columns={
'出发机场':'机场'},inplace=True)
grouped_arrive.rename(columns={
'到达机场':'机场'},inplace=True)
grouped = pd.concat([grouped_go,grouped_arrive],axis=0,ignore_index=True)
# 按照城市进行分组统计机场吞吐量
grouped_throughput = grouped.groupby('机场')['旅客量'].sum().reset_index().sort_values(by='旅客量',ascending=False)[:16]
airport = [i['机场'] for i in grouped_throughput.to_dict(orient="records")]
nums = [i['旅客量'] for i in grouped_throughput.to_dict(orient="records")]
# print(data)
data = [airport,nums]
return data
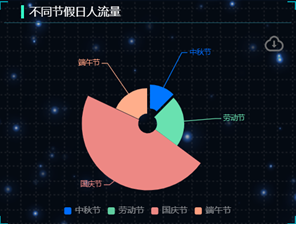
# 统计不同节假日旅客量
def festival_traveler_count(df):
# 将正常日过滤处理
df = df.query('节假日 != "正常日"')
# 按照节假日进行分组 统计旅客量总和
grouped = df.groupby('节假日')['旅客量'].count().reset_index()
data = [[i['节假日'],i['旅客量']] for i in grouped.to_dict(orient="records")]
return data
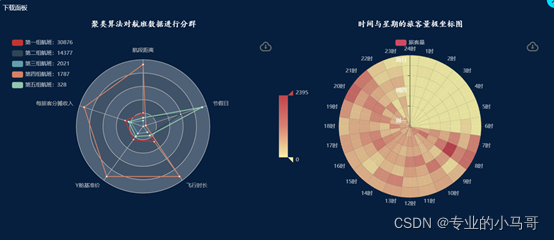
# 周与时间的平均旅客量极坐标图
def week_hour_traveler_count(df):
grouped = df.groupby(['周', "航段起飞小时"])['旅客量'].sum().reset_index()
grouped_data = grouped.to_dict(orient="records")
hour = [i for i in range(24)]
new_data = []
for i in range(1, 8):
for j in grouped_data:
if j['周'] == i and j['航段起飞小时'] in hour:
hour.remove(j['航段起飞小时'])
new_data.append(j)
for a in hour:
new_data.append({
'周': i, "航段起飞小时": a, "旅客量": 0})
hour = [i for i in range(24)]
data = [[i['周'],i['航段起飞小时'],i['旅客量']] for i in new_data]
return data
# 聚类算法对航班数据进行分群
def kmeans_flight_divide(df):
df['节假日_数字'] = df['节假日'].replace({
'正常日': 1, '中秋节': 2, '端午节': 3, "劳动节": 4, '国庆节': 5})
# 提取特征值数据
attr = ['航段距离', '每旅客分摊收入', 'Y舱基准价', '飞行时长', '节假日_数字']
data = df[attr]
# 对数据进行归一化
std = MinMaxScaler()
data = std.fit_transform(data)
# 调用k-means算法,进行聚类分析
kmodel = KMeans(n_clusters=4)
kmodel.fit(data)
# 查看各样本对应的类别
means_cores = kmodel.cluster_centers_.tolist()
# 对聚类中心进行绝对值处理
means_cores = [[abs(j) for j in i] for i in means_cores]
print(means_cores)
# 计算每个分组的个数
series = Series(kmodel.labels_)
count_list = series.value_counts().tolist()
print(count_list)
# 求出每个特征值的最大值并构造雷达图indicator
core1 = [abs(means_cores[i][0]) for i in range(len(means_cores))]
core2 = [abs(means_cores[i][1]) for i in range(len(means_cores))]
core3 = [abs(means_cores[i][2]) for i in range(len(means_cores))]
core4 = [abs(means_cores[i][3]) for i in range(len(means_cores))]
core5 = [abs(means_cores[i][4]) for i in range(len(means_cores))]
cores = [core1, core2, core3, core4, core5]
indicator = [{
'name': attr[i], "max": max(cores[i])} for i in range(len(attr))]
print(indicator)
return means_cores
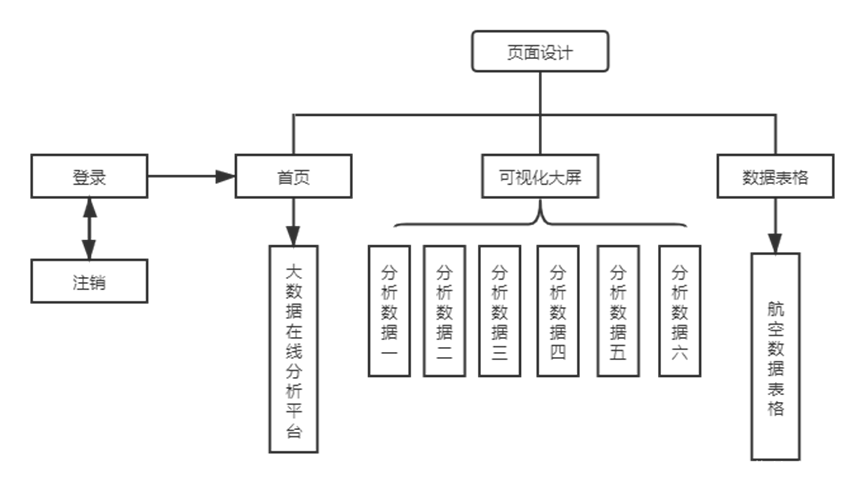
三、Web框架搭建
Web框架搭建说明:
1、Web框架搭建采用的是Flask及其扩展库
2、关于数据分析的相关视图函数在这里没有进行展示
3、视图函数模块设计图
代码展示
from flask import request,jsonify,session,redirect,render_template
from my_area.models import User,db
from . import api
from my_area.utils import analysis
from my_area.utils.common import login_required
# 初始化首页
@api.route('/init_index')
@login_required
def init_index():
sign = session.get("sign")
file = session.get("file")
username = session.get("username")
df = analysis.run("get")
from_city = df.groupby('出发城市')['到达城市'].count().reset_index().sort_values(by='到达城市', ascending=False)
from_city = [i['出发城市'] for i in from_city.to_dict(orient="records")]
to_city = df.groupby('到达城市')['出发城市'].count().reset_index().sort_values(by='出发城市', ascending=False)
to_city = [i['到达城市'] for i in to_city.to_dict(orient="records")]
month = ["{}月".format(i + 1) for i in range(12)]
day = ["{}日".format(i + 1) for i in range(31)]
return render_template('index.html',**locals())
# 查询函数
@api.route("/search")
def search():
sign = session.get("sign")
if not sign:
return jsonify(errno="404",errmsg="请先登录用户!")
file = session.get("file")
if not file:
return jsonify(errno="400", errmsg="请先上传文件!")
# 获取参数
city_from = request.args.get('from')
city_to = request.args.get('to')
month = request.args.get('month')
# 处理月数据
if not month == "不限":
month = int(month.split("月")[0])
day = request.args.get('day')
# 处理日数据
if not day == "不限":
day = int(day.split("日")[0])
df = analysis.run("get")
# 方便后续字符串拼接
map1 = [{
'key': "出发城市", 'value': "city_from"}, {
'key': "到达城市", 'value': "city_to"},
{
'key': "月", 'value': "month"}, {
'key': "日", 'value': "day"}]
map2 = [{
'key': "出发城市", 'value': city_from}, {
'key': "到达城市", 'value': city_to},
{
'key': "月", 'value': month}, {
'key': "日", 'value': day}]
use_map = [i for i in map2 if not i['value'] == "不限"]
str = ''
for i in range(len(use_map)):
key = use_map[i]['key']
value = [i['value'] for i in map1 if i['key'] == key][0]
if i == len(use_map) - 1:
str += (key + "==" + "@" + value)
else:
str += (key + "==" + "@" + value + " and ")
search_data = df.query(str)
search_data['出发到达'] = search_data['出发城市'] + '-' + search_data['到达城市']
search_data = search_data.groupby(['承运日期', '航班号', '出发到达', '航空公司'])['旅客量'].sum().reset_index()
# print(search_data)
data = search_data[['承运日期', '航班号', '出发到达', '航空公司', '旅客量']].to_dict(orient="records")
return jsonify(errno="200",data=data)
# 注册函数
@api.route('/user_register')
def user_register():
username = request.args.get('username')
password = request.args.get('password')
user = User.query.filter_by(username=username).first()
if user:
return jsonify(errno="404",errmsg="用户已存在!")
user = User(username=username,password=password)
db.session.add(user)
db.session.commit()
return jsonify(errno="200",errmsg="注册成功!")
# 登录检测函数
@api.route('/check_user')
def check_user():
# 获取参数
username = request.args.get('username')
password = request.args.get('password')
user = User.query.filter_by(username=username).first()
if not user:
return jsonify(errno="404")
if user:
rel_password = user.password
if rel_password==password:
session['username'] = username
sign = session.get("sign")
sign = True
session['sign'] = sign
return jsonify(errno="200")
else:
return jsonify(errno="404")
# 获取表单函数
@api.route('/get_form')
@login_required
def get_form():
df = analysis.run("get")
df['出发到达'] = df['出发城市']+'-'+df['到达城市']
grouped = df[['承运日期','航班号','出发到达','航空公司','旅客量']]
grouped = grouped.groupby(['承运日期', '航班号', '出发到达', '航空公司'])['旅客量'].sum().reset_index()
data = grouped.to_dict(orient="records")
file = session.get('file')
file = True
session['file'] = file
return render_template('table.html', **locals())
# 获取数据表格函数
@api.route('/get_table')
@login_required
def get_table():
return render_template('table.html', **locals())
# 注销登录
@api.route('/sign_out')
def sign_out():
session.clear()
return redirect("http://127.0.0.1:5000/api/v1.0/init_index")
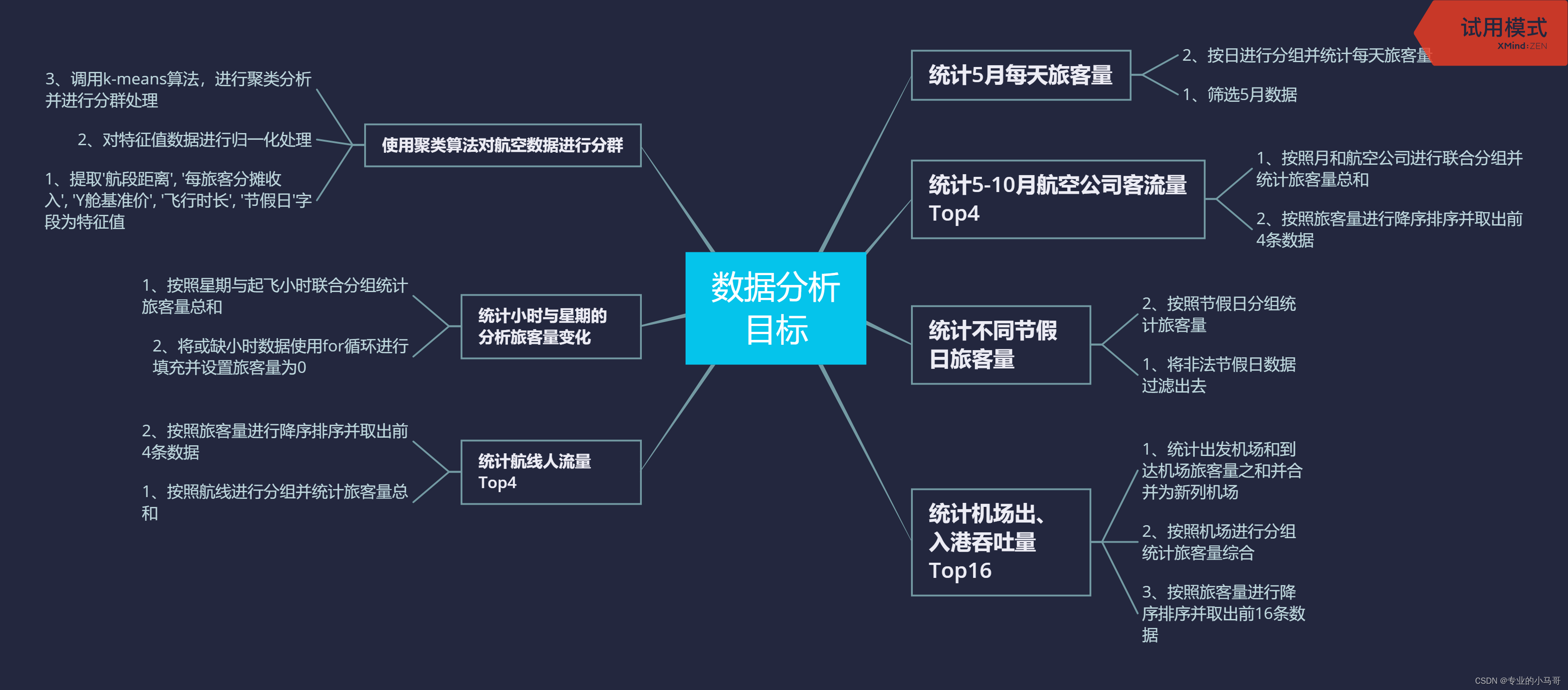
四、数据可视化部分
数据可视化说明:
1、数据可视化采用的是Echarts
2、可视化图表模块
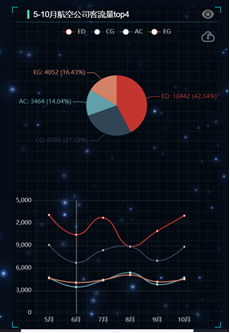
3、可视化图表展示说明
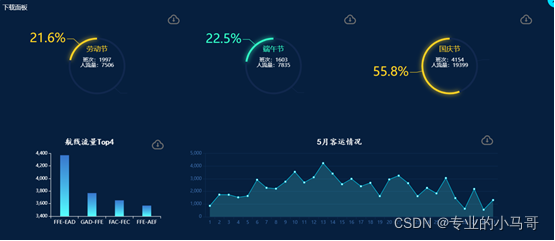
- 统计5-10月航空公司客运量Top4
- 统计机场旅客吞吐量Top16
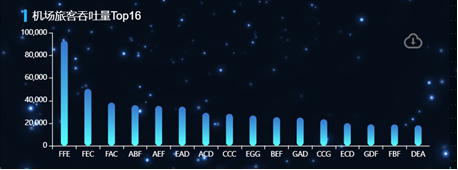
- 统计机场旅客吞吐量Top16
- 统计五月机场总客运量
- 统计航线客运量Top4
- 航班维度聚类分析
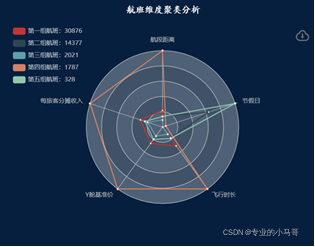
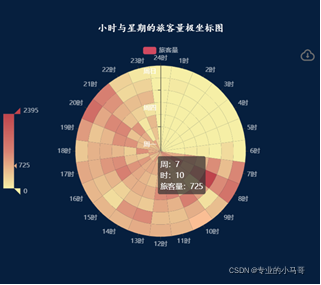
- 时间与星期的旅客量变化
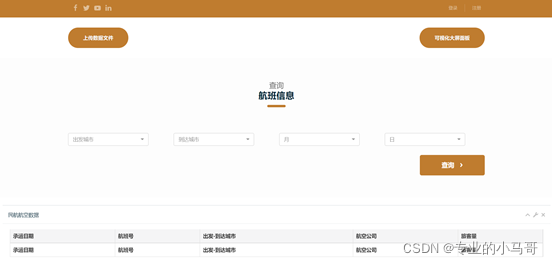
五、项目可视化页面展示
可视化页面说明:
1、首页支持数据查询
2、在未进行登录时,是无法点击可视化大屏页面按钮和上传数据文件按钮
3、表格页面上传数据后,数据表格才会显示数据,可以对数据表格进行翻页、搜索、打印等操作
4、可视化大屏页面中的数据图表均可进行拖拽、隐藏和显示、位置变换、以及图片下载。
(一)首页
(二)注册页面
(三)登录页面
(四)数据表格页面
- 未上传数据文件
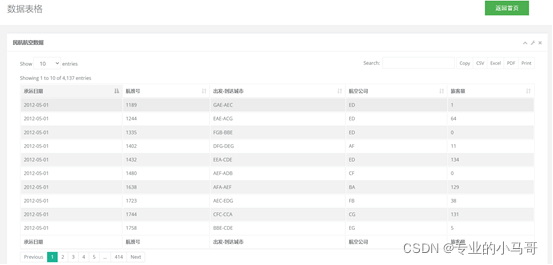
- 已上传数据文件
(五)可视化图表页面 - 大屏页面

- 大数据可视化分析一按钮
- 大数据在线分析二按钮
以上是本项目的核心内容,希望能够帮助你们,如需要数据集以及项目核心讲解视频,下方评论