目录
1 概述
用电行为包含了电力用户在外界影响下进行的用电活动和背后的用电规律 。用电活动可以通过智能电表采样以负荷曲线的形式表现出来,用电规律包含了用户用电习惯爱好,需要通过数据挖掘才能表示出来。
分析用户用电行为,可以为客户提供节能建议,以及及时发现窃电用户,减少电网损失
。进行用户家庭用电行为分析的前提是先进行家用负荷分解,负荷分解得到各电器功率数据之后,再通过这些电器功率数据进行数据处理与分析,分析用户用电行为。
2 异常检测算法
2.1 孤立随机森林算法思想
孤立随机森林是无监督学习模型中用于检测异常值的一种方法,不同于其他通过计算距离和密度来识别样本点是否是孤立点,而是通过样本的疏密程度来判断样本的是否孤立。仅适用于连续型数据。这是一种通过隔离数据中的离群值识别异常的无监督学习算法。孤立森林的原理是:异常值是少量且不同的观测值,因此更易于识别。孤立森林集成了多棵孤立树,在给定的数据样本中隔离异常值。孤立森林采用二分法将样本点进行分区,该算法将样本中所有样本进行切分,直到每个样本点或极少样本点被划分在同一区域呢,这样样本越密集的区域,区域中的点被孤立时所需要的切分次数就越多,如果样本是孤立点,则该点被孤立时切分的次数就越低。因此异常值是树中路径更短的样本点,路径长度是从根节点到叶子节点经过的边数.
2.2 孤立随机森林算法步骤
孤立随机森林是和随机森林的概念类似,孤立随机森林是由多颗孤立树构成,先使用训练集集训练每颗孤立树,然后再计算验证集每个样本的异常分数值(0,1]判断该样本是否异常,分值越接近1样本越孤立,即样本异常可能性越大。
其算法流程如下:
(1)训练:
先从全部数据中抽取一批样本,构建t棵孤立树,对于每棵孤立树,然后随机选择一个特征作为起始节点,并随机选择一个值,这个值应在该特征的最小值和最大值之间,将样本中小于该取值的数据划到左分支,大于等于该取值的划到右分支。然后,在左右两个分支数据中,重复上述步骤,直到满足如下条件:数据不可再分,即:只包含一条数据,或者全部数据相同或者二叉树达到限定的最大深度。
先从全部数据中抽取一批样本,构建t棵孤立树,对于每棵孤立树,然后随机选择一个特征作为起始节点,并随机选择一个值,这个值应在该特征的最小值和最大值之间,将样本中小于该取值的数据划到左分支,大于等于该取值的划到右分支。然后,在左右两个分支数据中,重复上述步骤,直到满足如下条件:数据不可再分,即:只包含一条数据,或者全部数据相同或者二叉树达到限定的最大深度。
(2)预测:
获得t个孤立树之后,孤立随机森林训练就结束,然后我们可以用生成的孤立随机森林来评估测试数据。对于一个训练样本数据x,我们令其遍历每一棵孤立树,然后计算x最终落在每个树第几层(x在树的高度),然后我们可以得出x在每棵树的高度平均值。值得注意的是,如果x落在一个节点中含多个训练数据,可以使用一个公式来修正x的高度计算计算样本数据x的异常分值时,先要估算它在每棵孤立树中的路径长度(也可以叫深度)。具体的,先沿着一棵孤立树,从根节点开始按不同特征的取值从上往下,直到到达某叶子节点。假设孤立树的训练样本中同样落在x所在叶子节点的样本数为T.size ,则数据x在这棵孤立树上的路径长度h(x),可以用下面这个公式计算:
获得t个孤立树之后,孤立随机森林训练就结束,然后我们可以用生成的孤立随机森林来评估测试数据。对于一个训练样本数据x,我们令其遍历每一棵孤立树,然后计算x最终落在每个树第几层(x在树的高度),然后我们可以得出x在每棵树的高度平均值。值得注意的是,如果x落在一个节点中含多个训练数据,可以使用一个公式来修正x的高度计算计算样本数据x的异常分值时,先要估算它在每棵孤立树中的路径长度(也可以叫深度)。具体的,先沿着一棵孤立树,从根节点开始按不同特征的取值从上往下,直到到达某叶子节点。假设孤立树的训练样本中同样落在x所在叶子节点的样本数为T.size ,则数据x在这棵孤立树上的路径长度h(x),可以用下面这个公式计算:

式中:e 表示数据x从孤立树的根节点到叶节点过程中经过的边的数目,C(T.size)可以认为是一个修正值,它表示在一棵用T.size 条样本数据构建的二叉树的平均路径长度。
平均路径长度计算公式如下:

式中:H(n-1) 可用 ln(n-1)+0.5772156649 估算,这里的常数是欧拉常数。
数据 x 最终的异常分值 Score(x) 综合了多棵 iTree 的结果。
异常分值公式如下:

式中:
E
(
h
(
x
))
表示数据 x 在多棵 iTree 的路径长度的均值,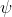 表示单棵iTree 的训练样本的样本数, c(
) 表示用 Ψ条数据(样本点)构建的二叉树的平均路径长度。得分越接近 1,表明数据 x 越异常,得分越接近 0,表示数据 x 越正常.
表示单棵iTree 的训练样本的样本数, c(
) 表示用 Ψ条数据(样本点)构建的二叉树的平均路径长度。得分越接近 1,表明数据 x 越异常,得分越接近 0,表示数据 x 越正常.
2.3 其他异常检测算法
(1)k 均值聚类做异常检测
在一般任务中,我们可以使用k均值聚类进行异常检测,流程如下:
1)利用“轮廓系数法”、“拐点法”、“间隔统计量法”或者“经验法”确定聚类的个数。
2)基于具体的聚类个数,对数据实施k均值聚类的应用,得到簇中心点的坐标。
3)计算簇内每个点到簇中心点的距离。
4)将距离跟阈值相比较,如果其大于阈值则认为是异帘,省则止吊。一般一个簇有一个阈值,阈值设定规则为:簇内每个点到簇中心的距离的平均值+3倍簇内每个点到簇中心的距离的标准差。
(2)密度聚类做异常检测
密度聚类(Density-Based Spatial Clustering of Applications with Noise,DBSCAN)该算法将具有足够密度的区域划分为子区域簇,并在具有噪声 的空间数据库中可以发现任意形状的簇,在一个空间中,将距离近的点分为一类,将低密度的点抛弃。
形象来说,我们可以认为这是系统在众多样本点中随机选中一个,围绕这个被选中的样本点画一个圆,规定这个圆的半径以及圆内最少包含的样本点,如果在指定半径内有足够多的样本点在内,那么这个圆圈的圆心就转移到这个内部样本点,继续去圈附近其它的样本点,就像传销一样,继续去发展下线。等到这个滚来滚去的圈发现所圈住的样本点数量少于预先指定的值,就停止了。那么我们称最开始那个点为核心点,如A,停下来的那个点为边界点,如B、C,在这个区域外的点为离群点。