
JDK1.8源码
构造函数
public ConcurrentHashMap(int initialCapacity,
float loadFactor, int concurrencyLevel) {
if (!(loadFactor > 0.0f) || initialCapacity < 0 || concurrencyLevel <= 0)
throw new IllegalArgumentException();
if (initialCapacity < concurrencyLevel) // Use at least as many bins
initialCapacity = concurrencyLevel; // as estimated threads
long size = (long)(1.0 + (long)initialCapacity / loadFactor);
int cap = (size >= (long)MAXIMUM_CAPACITY) ?
MAXIMUM_CAPACITY : tableSizeFor((int)size);
this.sizeCtl = cap;
}
- initialCapacity:table数组的初始化大小
- loadFactor:负载因子
- concurrencyLevel:并发等级,用来确定Segment的个数,Segment的个数要大于等于并发等级
put执行过程
- 根据key的hashCode()计算hash值
- 如果table数组为空,则初始化table数组
- 定位到的Node为null时,利用CAS尝试放入,成功则退出,失败则再此进入循环
- 如果当前位置的Node.hash等于-1,则ConcurrentHashMap正在扩容,当前线程去帮助转移
- 利用synchronized加锁,将元素放入红黑树或者链表(key已经存在则替换)
- 如果链表的长度大于8,则转为红黑树
public V put(K key, V value) {
return putVal(key, value, false);
}
// 当元素存在时,onlyIfAbsent = true 直接返回旧值,不进行替换,否则进行替换
final V putVal(K key, V value, boolean onlyIfAbsent) {
if (key == null || value == null) throw new NullPointerException();
int hash = spread(key.hashCode());
int binCount = 0;
for (Node<K,V>[] tab = table;;) {
Node<K,V> f; int n, i, fh;
// 数组为空,初始化
if (tab == null || (n = tab.length) == 0)
tab = initTable();
// 数组i这个位置的元素为null,并且cas设置成功,返回
else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {
if (casTabAt(tab, i, null,
new Node<K,V>(hash, key, value, null)))
break; // no lock when adding to empty bin
}
// 正在扩容
else if ((fh = f.hash) == MOVED)
tab = helpTransfer(tab, f);
else {
V oldVal = null;
synchronized (f) {
// 链表的头节点有可能发生变化,再检测一遍
if (tabAt(tab, i) == f) {
// 是链表
if (fh >= 0) {
binCount = 1;
for (Node<K,V> e = f;; ++binCount) {
K ek;
if (e.hash == hash &&
((ek = e.key) == key ||
(ek != null && key.equals(ek)))) {
oldVal = e.val;
if (!onlyIfAbsent)
e.val = value;
break;
}
Node<K,V> pred = e;
if ((e = e.next) == null) {
pred.next = new Node<K,V>(hash, key,
value, null);
break;
}
}
} // 是红黑树
else if (f instanceof TreeBin) {
Node<K,V> p;
binCount = 2;
if ((p = ((TreeBin<K,V>)f).putTreeVal(hash, key,
value)) != null) {
oldVal = p.val;
if (!onlyIfAbsent)
p.val = value;
}
}
}
}
if (binCount != 0) {
// 链表长度 >= 8,并且数组长度 >= 64,链表转为红黑树
// 否则扩容
if (binCount >= TREEIFY_THRESHOLD)
treeifyBin(tab, i);
if (oldVal != null)
return oldVal;
break;
}
}
}
// hashmap中元素个数加1
addCount(1L, binCount);
return null;
}
为什么Node.hash >= 0 就说明是链表呢?
因为红黑树的结点为TreeBin,hash值为-2
这里有个需要注意的点为
链表长度 >= 8,并且数组长度 >= 64,链表转为红黑树,否则扩容
get执行过程
- 根据key的hashCode()计算hash值
- 定位到所在槽的第一个元素就是要获取的元素,则直接返回
- 如果是红黑树则按照树的方式获取值
- 如果是链表则按照链表的方式获取值
public V get(Object key) {
Node<K,V>[] tab; Node<K,V> e, p; int n, eh; K ek;
int h = spread(key.hashCode());
if ((tab = table) != null && (n = tab.length) > 0 &&
(e = tabAt(tab, (n - 1) & h)) != null) {
// 所在槽的第一个元素就是要获取的元素
if ((eh = e.hash) == h) {
if ((ek = e.key) == key || (ek != null && key.equals(ek)))
return e.val;
}
// 从红黑树上获取
else if (eh < 0)
return (p = e.find(h, key)) != null ? p.val : null;
// 从链表上获取
while ((e = e.next) != null) {
if (e.hash == h &&
((ek = e.key) == key || (ek != null && key.equals(ek))))
return e.val;
}
}
return null;
}
为什么get不用加锁呢?
首先从数组上取值时,用了Unsafe的api,保证了线程安全
static final <K,V> Node<K,V> tabAt(Node<K,V>[] tab, int i) {
return (Node<K,V>)U.getObjectVolatile(tab, ((long)i << ASHIFT) + ABASE);
}
其次Node对象用了volatile关键字来保证可见性。而final一旦赋值,对其他线程也是可见的
static class Node<K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
volatile V val;
volatile Node<K,V> next;
}
当发生rehash的时候,get和put操作会有怎样的行为?
- 未迁移到的hash槽,可以正常进行get和put操作
- 正在迁移的hash槽,get请求正常访问桶上的链表或者红黑树,因为rehash是复制新节点到table,不是移动
- 完成迁移的hash槽,get请求到新table上获取元素(迁移完成的槽上的节点为ForwardingNode,通过ForwardingNode到新table上查询),put请求则帮助迁移
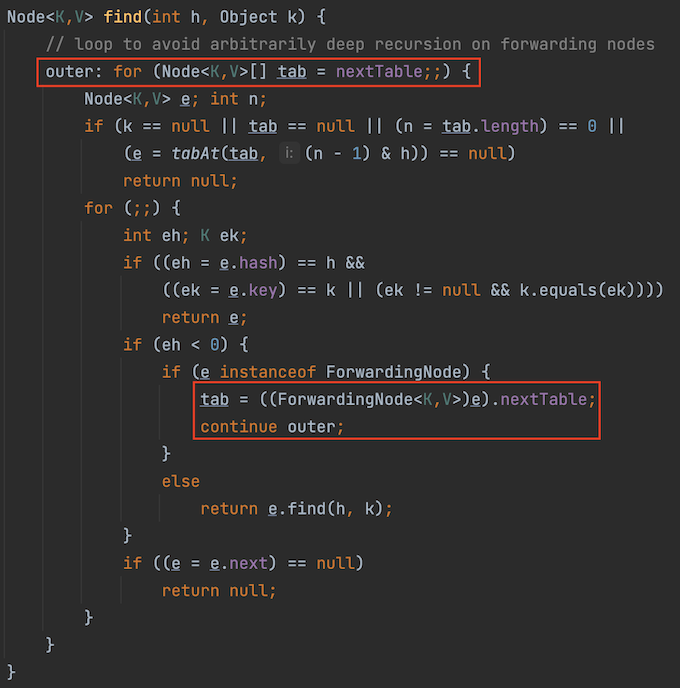
size方法
计数和获取总数的思路和LongAdder的差不多,看我的LongAdder文章吧
ConcurrentHashMap1.7和1.8的区别
底层实现
jdk1.7的实现为数组+链表,当发生hash冲突的时候采用拉链法,即链表,在链表上查找的复杂度为O(n)
jdk1.8的实现为数组+链表+红黑树,当发生hash冲突的时候也是采用拉链法,
但是当链表的长度大于8时,将链表转为红黑树,在红黑树上查找的效率为O(log(n))
保证线程安全的实现
jdk1.7基于Segment 分段锁 + Unsafe来保证线程安全
jdk1.8基于synchronized + CAS + Unsafe 来保证线程安全
并发度
jdk1.7中每个Segment独立加锁,能支持的最大并发度为Segment数组的长度
jdk1.8中锁的粒度变的更细,能支持的最大并发度为table数组的长度,并发度比1.7有所提高
获取元素总数
jdk1.7通过加锁来保证获取的元素总数是准确的
jdk1.8的元素总数是通过累加baseCount和cell数组的值得出来的,会有并发的问题,最终的值可能不精确(和LongAdder的计数思路类似)
参考博客
[1]https://blog.csdn.net/zzu_seu/article/details/106698150