在上一篇讲解了eth源码中的rlp的理解和分析,接下来将进入go-etherenum中 p2p下,去领略一番。在此之前,需要补充几个前提知识(DHT、Kademlia)。
- DHT(分布式哈希表)
- Kademlia协议
- 以太坊中的p2p
1、什么是DHT
(来自百度百科)

DHT全称叫分布式哈希表(Distributed Hash Table),是一种分布式存储方法。在不需要服务器的情况下,每个客户端负责一个小范围的路由,并负责存储一小部分数据,从而实现整个DHT网络的寻址和存储。新版BitComet允许同行连接DHT网络和Tracker,也就是说在完全不连上Tracker服务器的情况下,也可以很好的下载,因为它可以在DHT网络中寻找下载同一文件的其他用户。BitComet的DHT网络协议和BitTorrent2005年5月测试版的协议完全兼容,也就是说可以连入一个同DHT网络分享数据。
特别是在BitTorrent中,对DHT Protocol 进行具体实现。有兴趣的朋友可以阅读《DHT英文版简介》。
2、Kademlia协议
其中,Kad中实现的DHT算法,与其它的DHT技术实现进行比较(如Pastry、BitComet、eMule等等),Kad 通过独特的以异或算法(XOR)为距离度量基础,建立了一种 全新的 DHT 拓扑结构,相比于其他算法,大大提高了路由查询速度。

有趣的是,eMule中基于Kademlia技术的实现,也称为Kad(与本文的Kad有所不同,注意区分),其区别就在于Key、Value、NodeID的计算方法不同,感兴趣的朋友可以再去了解一下eMule中的协议实现。
本文从以下几个方面对Kademlia(Kad)进行展开:
- 节点状态
- 节点间距离
- K桶机制
- 协议操作
- 路由查询机制
- 数据存储
- 节点加入和退出
(1)节点状态
在Kademlia网络中,所有的节点都被当做一颗二叉树的叶子,并且每一个节点的位置都由其 ID 值的最短前缀唯一的确定。Kad 协议确保每个节点知道其各子树的至少一个节点,只要这些子树非空。在这个前提 下,每个节点都可以通过 ID 值来找到任何一个节点。这个路由的过程是通过所谓的 XOR(异或规则)距离得到的。
节点Node X,通过迭代的方式查询到“最佳”或者称为“最接近”的节点,最终达到目标节点上。
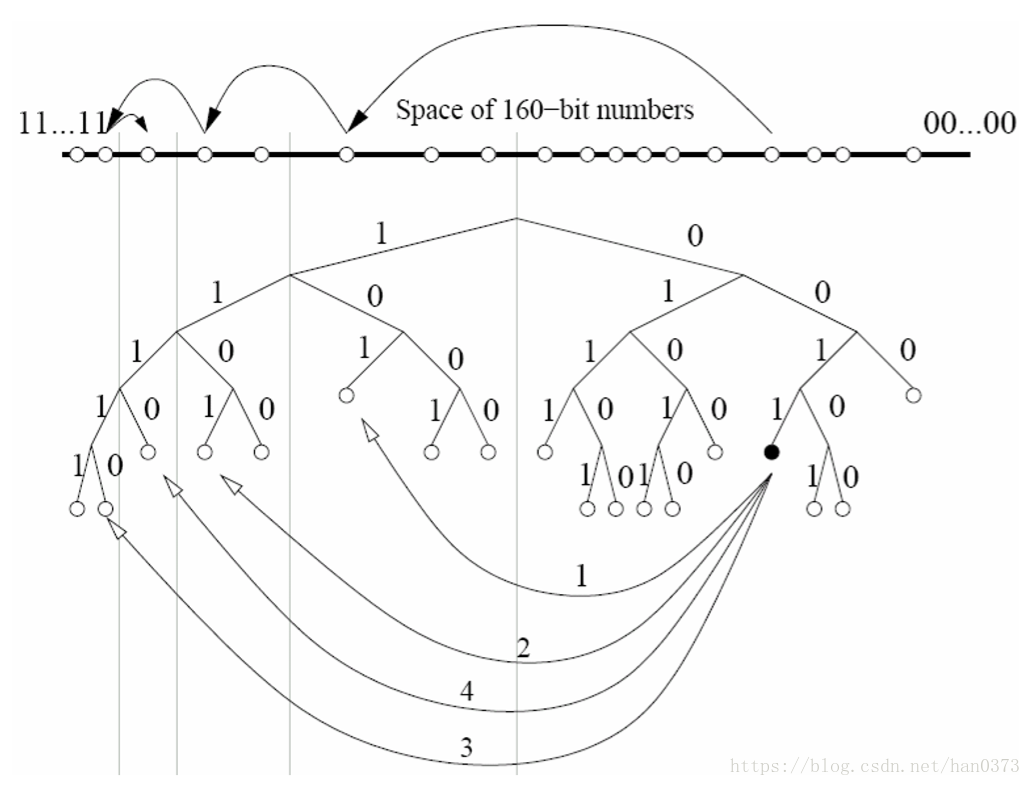
递归过程: 寻找 1 ,1 ->返回查询结果 -> 2 -> 返回查询结果 -> ... ->目标节点
(2)节点间距离
Kad 网络中每个节点都有一个 160bit 的 ID 值作为标志符,Key 也是一个 160bit 的标志 符,每一个加入 Kad 网络的计算机都会在 160bit 的 key 空间被分配一个节点 ID(node ID) 值(可以认为 ID 是随机产生的), <key,value>对的数据就存放在 ID 值“最”接近 key 值的 节点上。
而判断两个节点之间的距离远近,采用XOR的异或规则进行了计算。

输出结果:相同则为0,不同则为1。
同时,这样的XOR操作还具备一个特性,就是单向性。
确保了对于同一个 key 值的所有查询都会逐步收敛到同一个路径上,而不管查询的起始节点位置如何。 这样,只要沿着查询路径上的节点都缓存这个<key,value>对,就可以减轻存放热门 key 值 节点的压力,同时也能够加快查询响应速度。
(3)K桶机制
在Kad网络中,每一个节点均维护了160个list,其中的每个list均被称之为一个k-桶(k-bucket),如下图所示。在第i个list中,记录了当前节点已知的与自身距离为2^i~2^(i+1)的一些其他对端节点的网络信息(NodeID,IP地址,UDP端口),每一个list(k-桶)中最多存放k个对端节点信息。
这些信息由一些(IP address, UDP port, Node ID)数据列表构成(Kad 网络是靠 UDP 协议交换信息的)。 每 一 个这样的列表都称之为一个 K 桶,并且每个 K 桶内部信息存放 位置是根据上次看到的时间顺序排列,最近(least-recently)看到的放在头部,最后 (most-recently)看到的放在尾部。每个桶都有不超过 k 个的数据项。
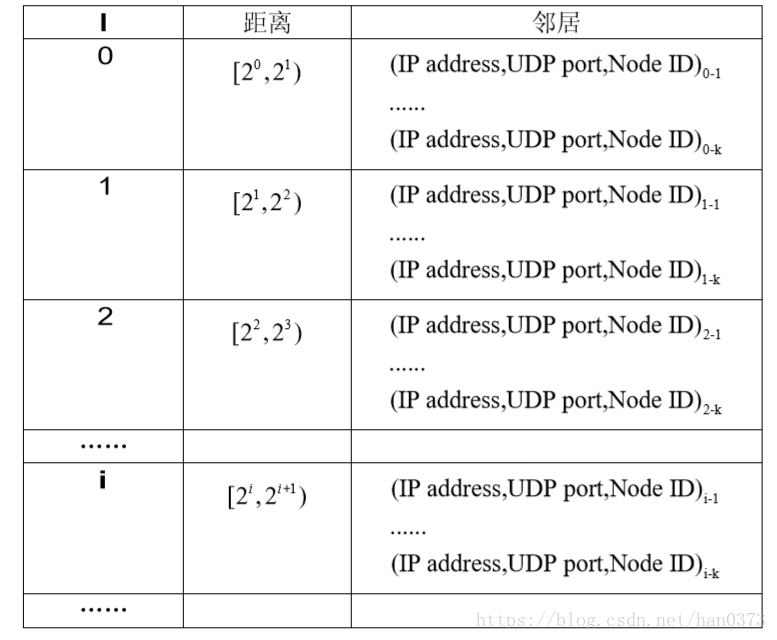
对每一个节点的i范围为 0 ≦ i ≦ 160,所以最后一项数只可能为 [2^160~2^161) 。每个 K 桶覆盖距离的范围呈指数关系增长,这就形成了离自己近的节点的信息多, 离自己远的节点的信息少,从而可以保证路由查询过程是收敛的。
其优点在于:
1、能在一定程度上防御 DOS 攻击,只有当老节点失效后,Kad 才会更新 K 桶的信息,这就避免了通过新节点的加入导致泛洪路由信息;
2、防止 K 桶老化,所有在一定时间之内无更新操作时,会分别从自己的 K 桶中 随机选择一些节点执行 RPC_PING 操作;
3、所有节点不会同时进行大量的更新操作;
4、对节点失效的情况能够进行快速响应;
(4)协议操作
Kademlia 协议包括四种远程 RPC 操作:
1、PING:探测一个节点,用以判断其是否仍然在线;
2、STORE:通知一个节点存储一个<key,value>对,以便以后查询需要;
3、FIND_NODE:使用一个 160bit 的 ID 作为参数。本操作的接受者返回它所知道的更 接近目标 ID 的 K 个节点的(IP address,UDP port,Node ID)信息。
4、FIND_VALUE:它只需要返回一个节点的(IP address,UDP port,Node ID)信息。如果本操作的接受者收到同一个 key 的 STORE 操作,则会直接返回存储的 value 值。
(5)路由查询机制
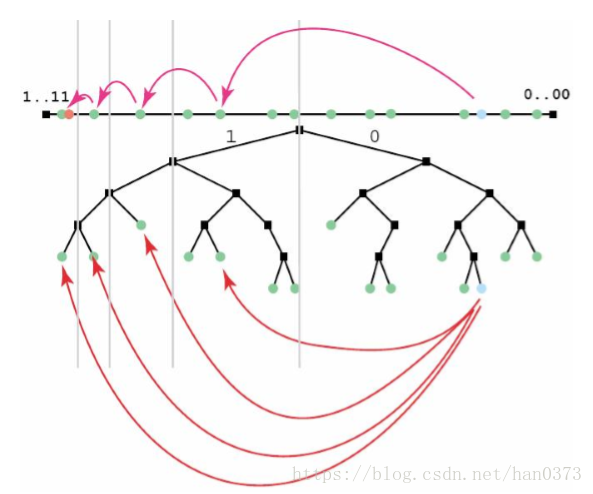
Kad 技术的最大特点之一就是能够提供快速的节点查找机制,并且还可以通过参数进行查找速度的调节。
整个路由查询过程是递归操作的,其过程可用数学公式表示为:

值得注意的地方,Kad 是按照递归操作步骤进行路由查找。去查询“最接近”(假设节点不存在,这会存在没有数据分配给任何一个节点的情况)的节点,想要深入了解的朋友可以参考原文进行解读,可调的参数还有a、t等等。
还有就是,在执行FIND_VALUE操作成功时,则<key,value>对数据会缓存在没有返回 value 值的最接近的节点上。从而提升下一次的查询效率。
(6)数据存储
存放<key,value>对数据的过程为:
1、 发起者首先定位 k 个 ID 值最接近 key 的节点;
2、 发起者对这 k 个节点发起 STORE 操作
3、 执行 STORE 操作的 k 个节点每小时重发布自己所有的<key,value>对数据。
4、 为了限制失效信息,所有<key,value>对数据在初始发布 24 小时后过期。
另外,为了保证数据发布、搜寻的一致性,规定在任何时候,当节点 w 发现新节点 u 比 w 上的某些<key,value>对数据更接近,则 w 把这些<key,value>对数据复制到 u 上,但是并不会从 w 上删除。
(7)节点加入和退出
加入节点:
以一个节点x插入到节点y为例。先决条件就是,x节点必须要与一个已经处于Kad网络的y节点“取得联系”。之后,将y插入到自己适当的 K Bucket 中。然后进行迭代查询,由近到远。之后再将自己的信息发布到其它节点的K Bucket中。
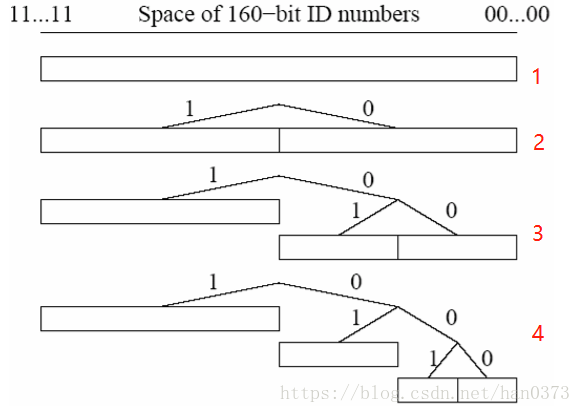
每个节点的路由表都表示为一个二叉树,叶子节点为 K 桶,K 桶存放的 是有相同 ID 前缀的节点信息,而这个前缀就是该 K 桶在二叉树中的位置。这样,每个 K 桶 都覆盖了 ID 空间的一部分,全部 K 桶的信息加起来就覆盖了整个 160bit 的 ID 空间,而且 没有重叠。
以节点 x 为例,其路由表的生成过程为:
1、开始时,路由表为一个单个的 K 桶,覆盖了整个 160bit ID 空间;
2、当学习到新的节点信息后,则 x 会尝试把新节点的信息,根据其前缀值插入到对应的 K 桶中:
如果该 K 桶没有满,则新节点直接插入到这个 K 桶中;
如果该 K 桶已经满了, 则
(1) 如果该 K 桶覆盖范围包含了节点 x 的 ID,则把该 K 桶分裂为两个大小相同 的新 K 桶,并对原 K 桶内的节点信息按照新的 K 桶前缀值进行重新分配
(2) 如果该 K 桶覆盖范围没有包节点 x 的 ID,则直接丢弃该新节点信息 3. 上述过程不断重复,最终会形成表 1 结构的路由表。达到距离近的节点的信息多, 距离远的节点的信息少的结果,保证了路由查询过程能快速收敛。
3、不断重复上述过程,则最终形成路由查询的快速收敛。(达到距离近的节点的信息多, 距离远的节点的信息少)
退出节点:
Kad节点机制运行任意的节点在任意时刻失效,且不需要发布任何信息。为此,Kad 要求每个节点必须周期性的发布全部自己存放的 <key,value>对数据,并把这些数据缓存在自己的 k 个最近邻居处,这样存放在失效节点的 数据会很快被更新到其他新节点上。
3、以太坊中的p2p
先来看一下p2p所涉及的目录和包结构。
discover:基于UDP,其中包含了上述所提到的Kad(Kademlia协议)
discv5:新的节点发现协议,目前还处于试验阶段
enr:支持"secp256k1-keccak"
nat:提供对公共网络端口映射协议的访问
natutil:提供nat的一些工具支持
simulations:p2p网络的模拟
testing:对p2p的测试
-----------------------------------------------
下一章将对p2p中的discover部分进行具体分析,文章部分内容和图片来自ZtesoftCS的github,在此鸣谢。
有任何建议或问题,欢迎加微信一起学习交流,欢迎从事IT,热爱IT,喜欢深挖源代码的行业大牛加入,一起探讨。
个人微信号:bboyHan
