GOplot | 更美观的富集分析可视化
数据准备
# 下载
install.packages('GOplot')
library(GOplot)
# 载入示例数据
data(EC)
# 富集分析结果
head(EC$david)
# 差异分析结果
head(EC$genelist)
# 生成画图数据
circ <- circle_dat(EC$david, EC$genelist)> head(circ)
category ID term count genes logFC adj_pval zscore
1 BP GO:0007507 heart development 54 DLC1 -0.9707875 2.17e-06 -0.8164966
2 BP GO:0007507 heart development 54 NRP2 -1.5153173 2.17e-06 -0.8164966
3 BP GO:0007507 heart development 54 NRP1 -1.1412315 2.17e-06 -0.8164966
4 BP GO:0007507 heart development 54 EDN1 1.3813006 2.17e-06 -0.8164966
5 BP GO:0007507 heart development 54 PDLIM3 -0.8876939 2.17e-06 -0.8164966
6 BP GO:0007507 heart development 54 GJA1 -0.8179480 2.17e-06 -0.8164966GOplot使用了zscore概念,但其并不是指Z-score标准化,而是指每个GO term下上调(logFC>0)基因数和下调基因数的差与注释到GO term基因数平方根的商。用于表示每个GO Term的上下调情况,公式:
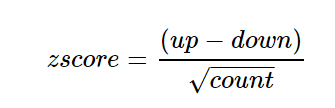
可视化
条图
GOBar(subset(circ, category == 'BP'))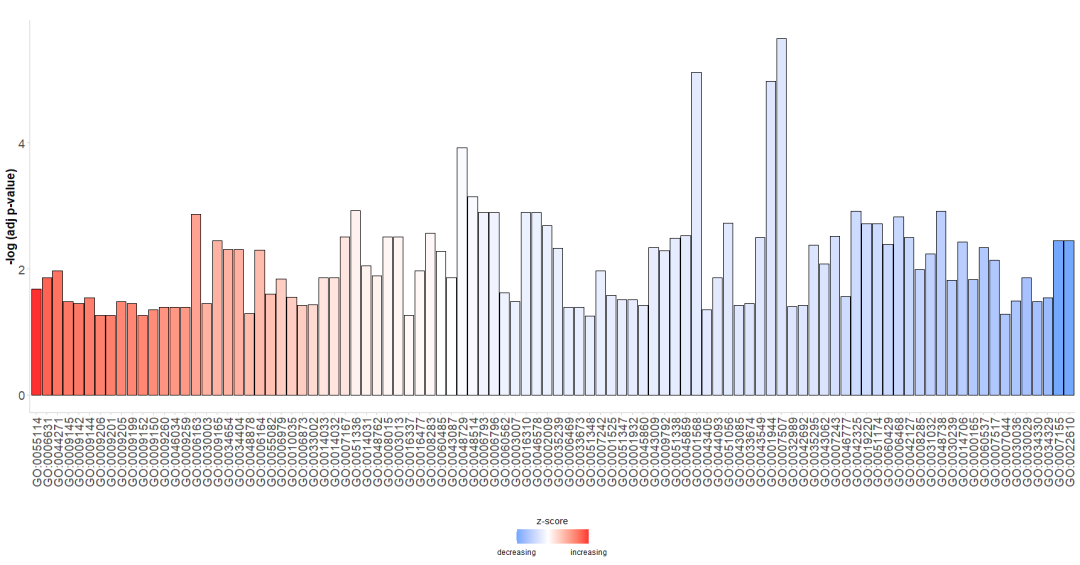
# 以terms的分类进行分面
GOBar(circ, display = 'multiple')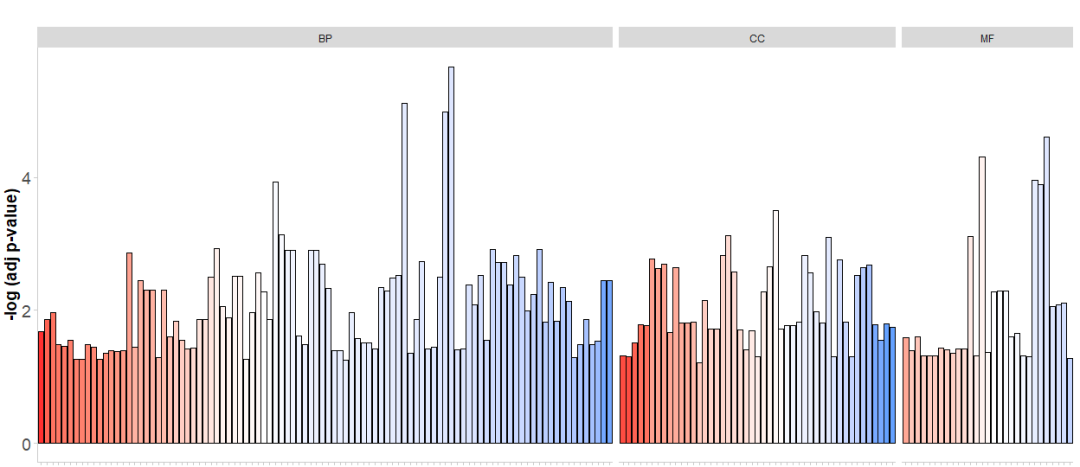
# 以terms的分类进行分面 切改变色阶颜色
GOBar(circ, display = 'multiple', title = 'Z-score coloured barplot', zsc.col = c('yellow', 'black', 'cyan'))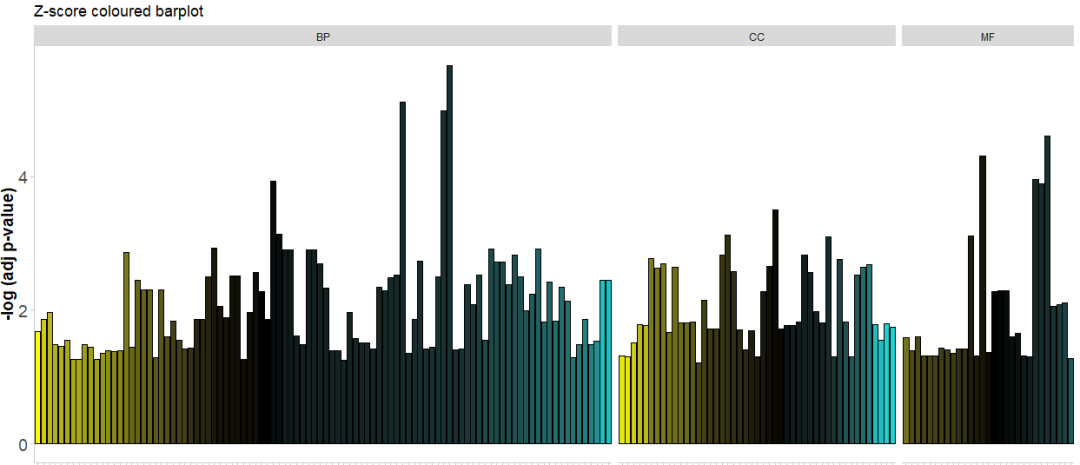
气泡图
z-score作为横坐标,校正p值的负对数作为纵坐标(y轴越高越显著)。所显示圆圈的面积与富集到term的基因数量成比例,颜色对应于类别。
# 生成y大于3的term的标签
GOBubble(circ, labels = 3)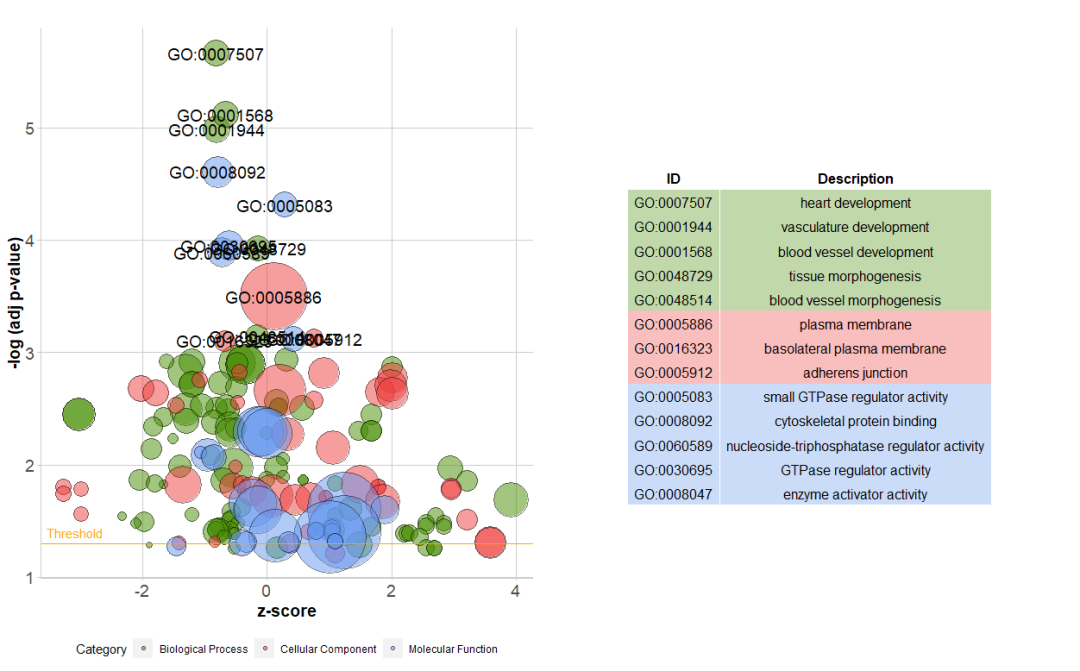
# 添加标题、分面、修改颜色
GOBubble(circ, title = 'Bubble plot', colour = c('orange', 'darkred', 'gold'), display = 'multiple', labels = 3)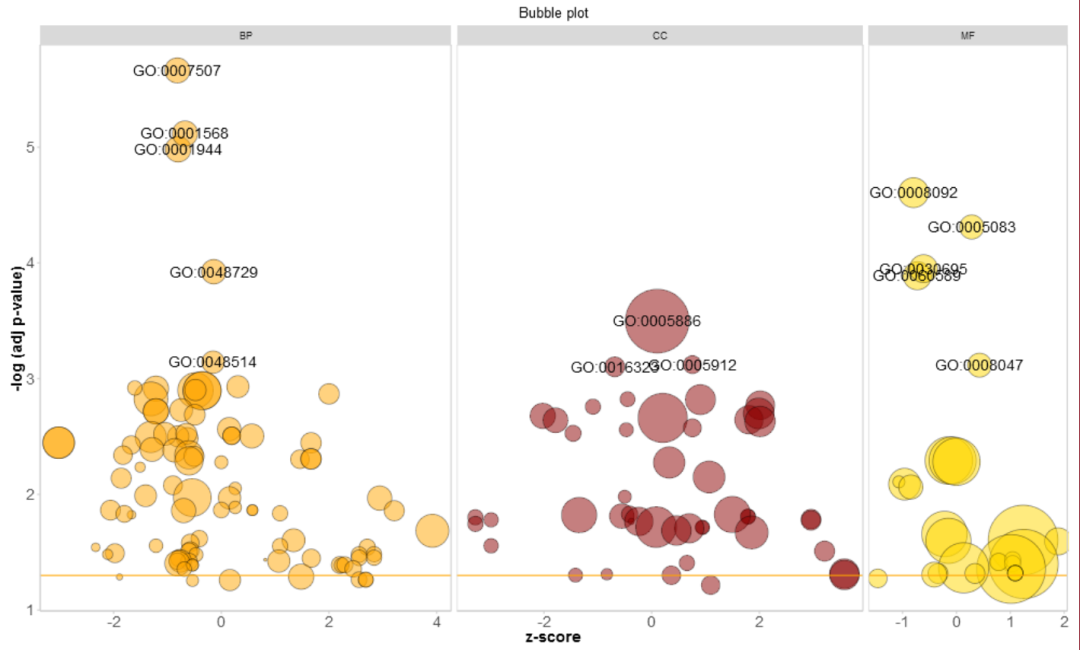
# 根据分类添加背景色
GOBubble(circ, title = 'Bubble plot with background colour', display = 'multiple', bg.col = T, labels = 3)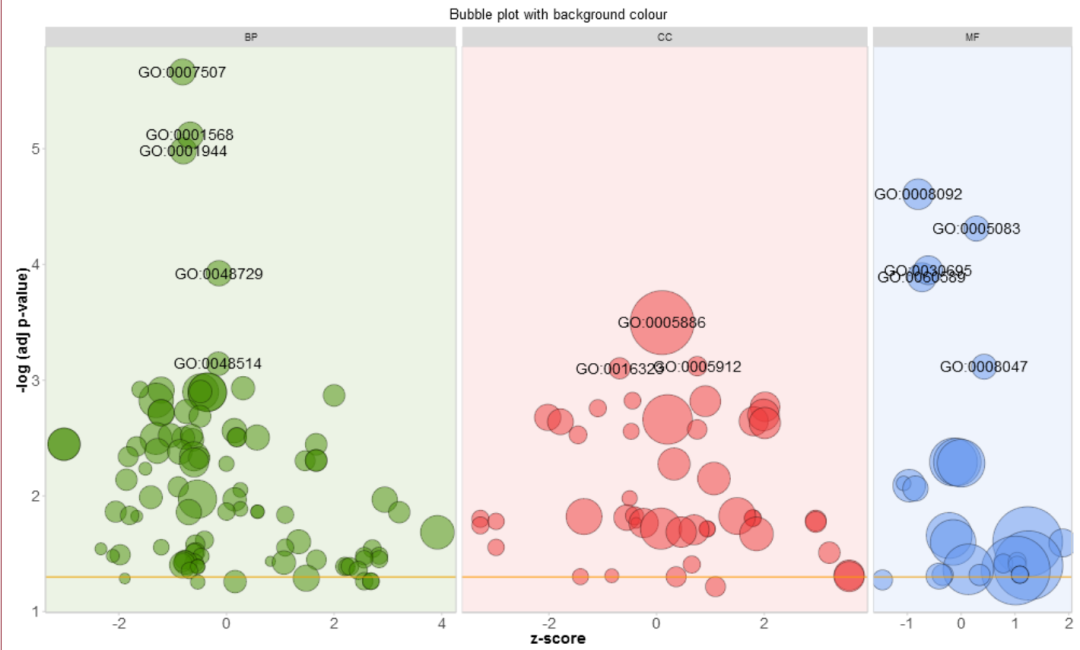
reduce_overlap减少冗余terms数目。该功能删除所有基因重叠大于或等于设定阈值的terms。保留每个组的一个terms作为代表,而不考虑GO层次结构。
# 删除所有基因重叠大于或等于 0.75的 terms
reduced_circ <- reduce_overlap(circ, overlap = 0.75)
GOBubble(reduced_circ, labels = 2.8)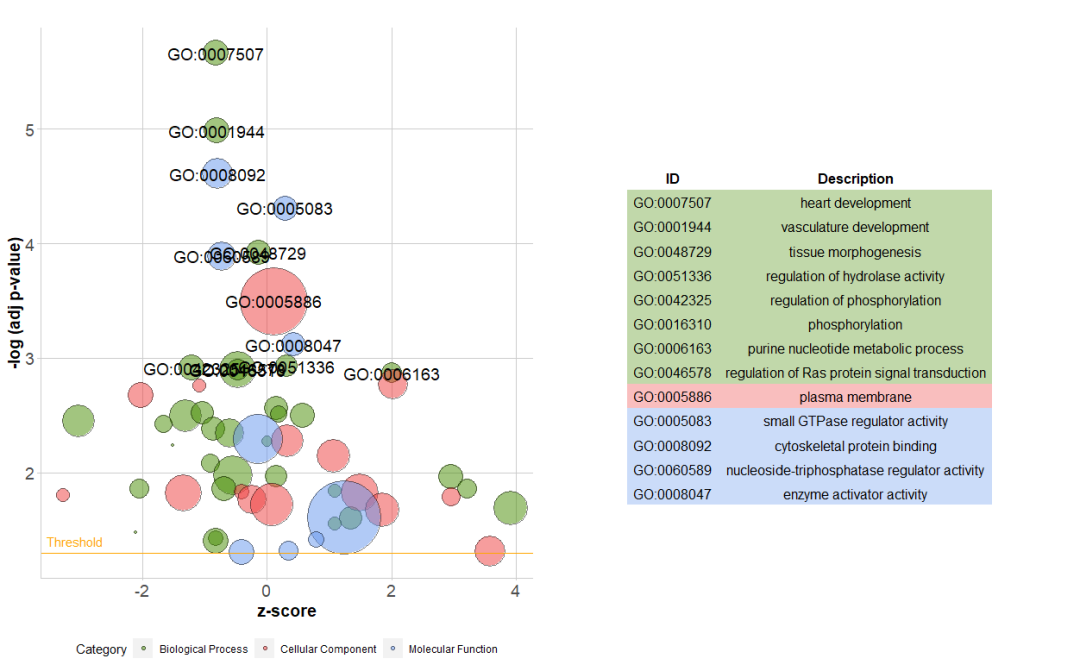
圈图
GOCircle(circ)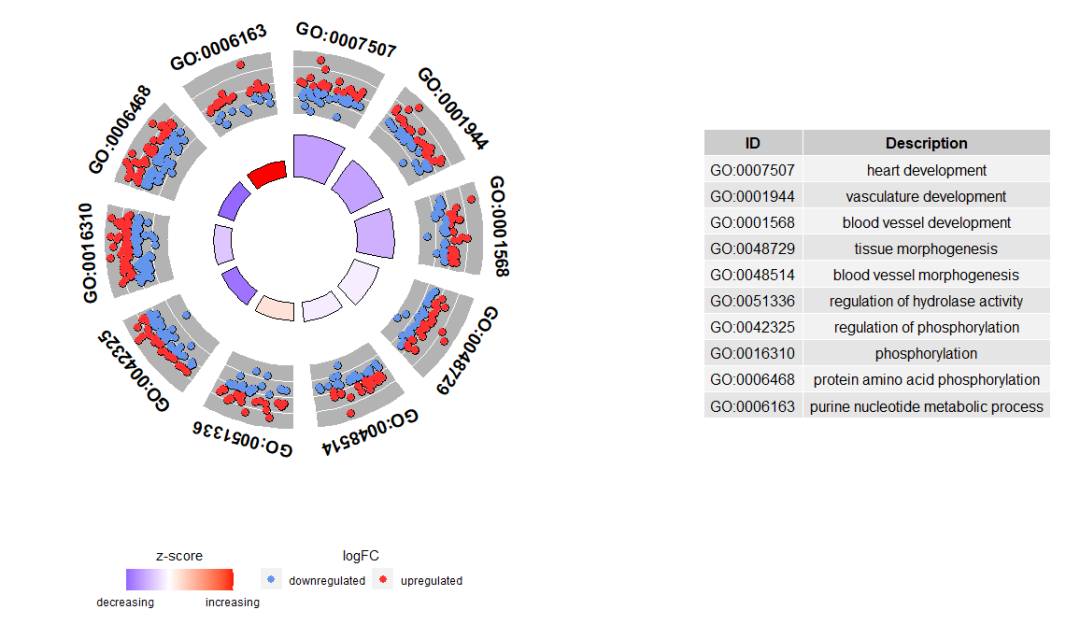
# 可视化感兴趣的 terms
IDs <- c('GO:0007507', 'GO:0001568', 'GO:0001944', 'GO:0048729', 'GO:0048514', 'GO:0005886', 'GO:0008092', 'GO:0008047')
GOCircle(circ, nsub = IDs)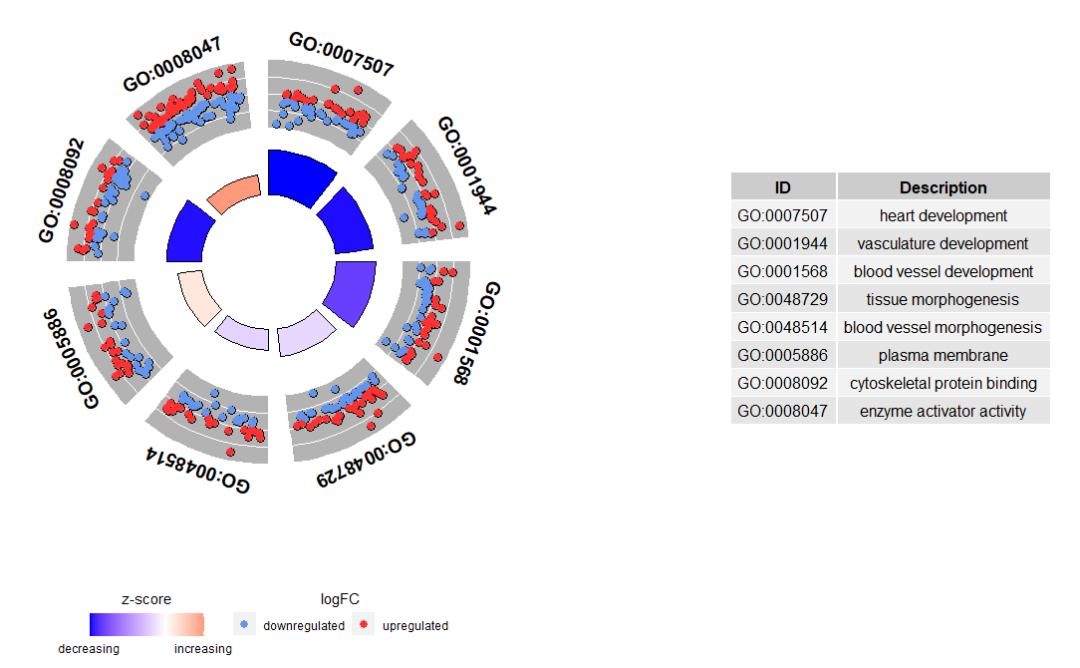
# 可视化前10个terms
GOCircle(circ, nsub = 10)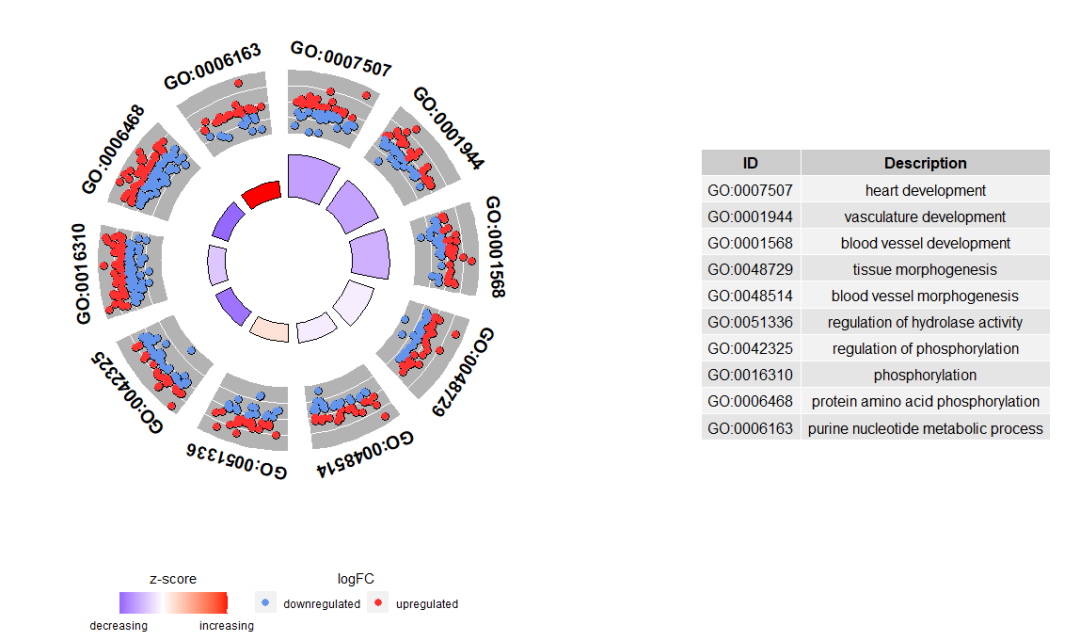
弦图
显示了所选基因和术语列表之间的关系,以及这些基因的logFC。
数据准备
head(EC$genes)
## ID logFC
## 1 PTK2 -0.6527904
## 2 GNA13 0.3711599
## 3 LEPR 2.6539788
## 4 APOE 0.8698346
## 5 CXCR4 -2.5647537
## 6 RECK 3.6926860
EC$process
## [1] "heart development" "phosphorylation"
## [3] "vasculature development" "blood vessel development"
## [5] "tissue morphogenesis" "cell adhesion"
## [7] "plasma membrane"chord <- chord_dat(circ, EC$genes, EC$process)
head(chord)
## heart development phosphorylation vasculature development
## PTK2 0 1 1
## GNA13 0 0 1
## LEPR 0 0 1
## APOE 0 0 1
## CXCR4 0 0 1
## RECK 0 0 1
## blood vessel development tissue morphogenesis cell adhesion
## PTK2 1 0 0
## GNA13 1 0 0
## LEPR 1 0 0
## APOE 1 0 0
## CXCR4 1 0 0
## RECK 1 0 0
## plasma membrane logFC
## PTK2 1 -0.6527904
## GNA13 1 0.3711599
## LEPR 1 2.6539788
## APOE 1 0.8698346
## CXCR4 1 -2.5647537
## RECK 1 3.6926860绘制
chord <- chord_dat(data = circ, genes = EC$genes, process = EC$process)
GOChord(chord, space = 0.02, gene.order = 'logFC', gene.space = 0.25, gene.size = 5)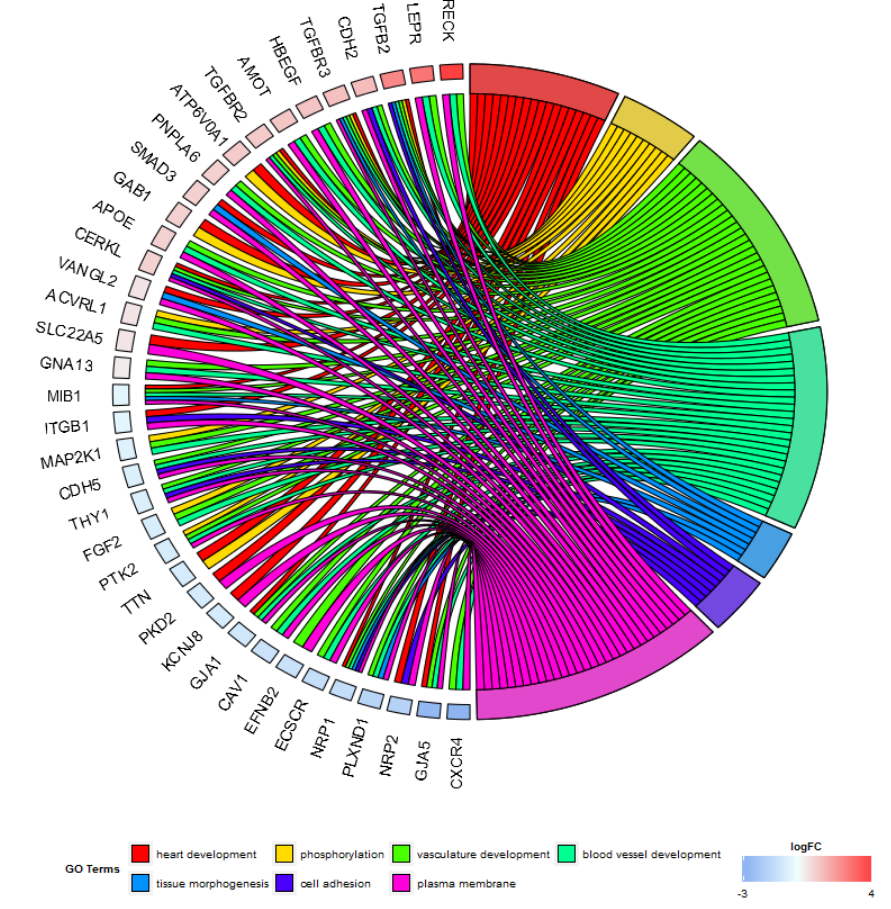
#只显示富集到至少3个terms的基因
GOChord(chord, limit = c(3, 0), gene.order = 'logFC')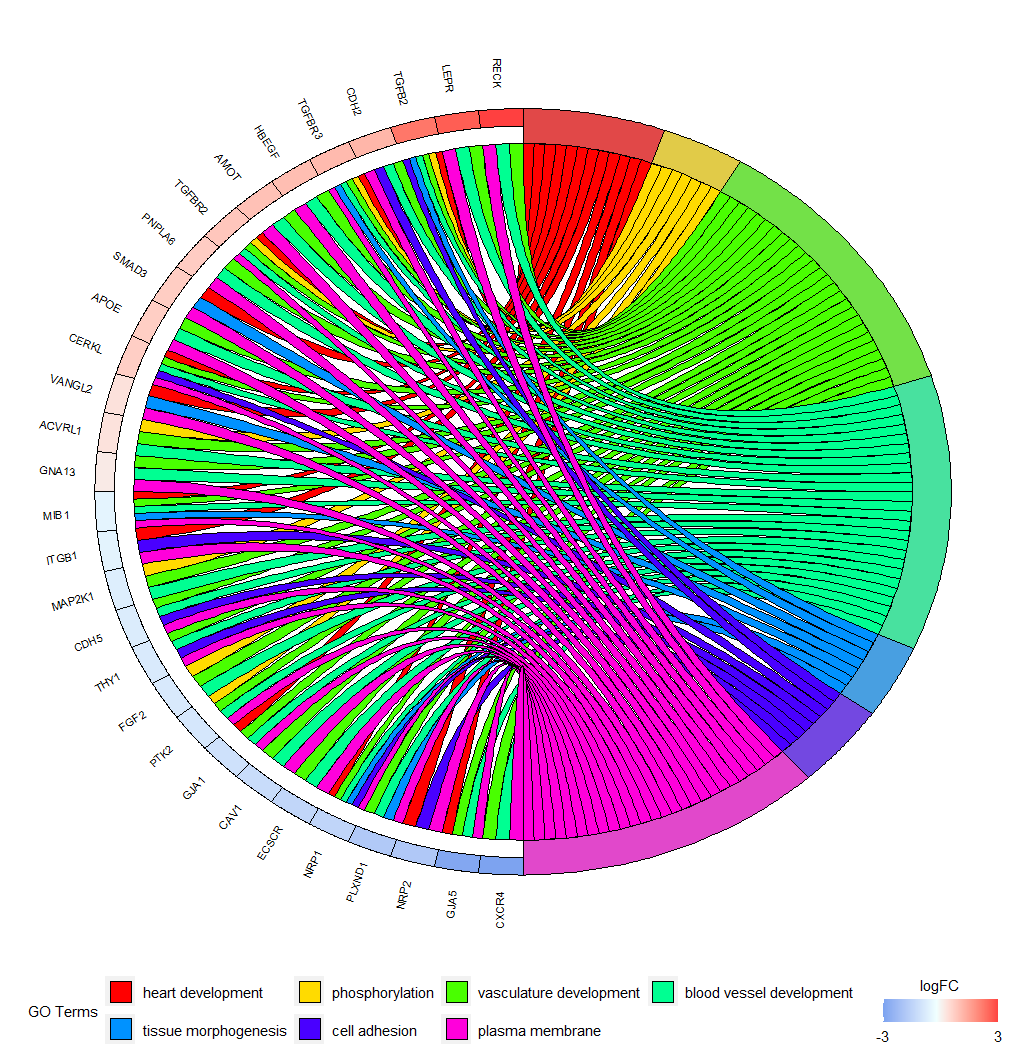
热图
GOHeat(chord[,-8], nlfc = 0) #nlfc = 0,则以count为色阶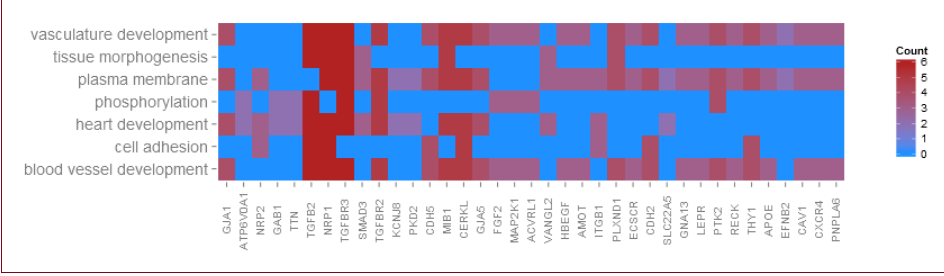
GOHeat(chord, nlfc = 1, fill.col = c('red', 'yellow', 'green')) #nlfc = 0,则以logFC 为色阶
GOCluster
GOCluster(circ, EC$process, clust.by = 'logFC', term.width = 2)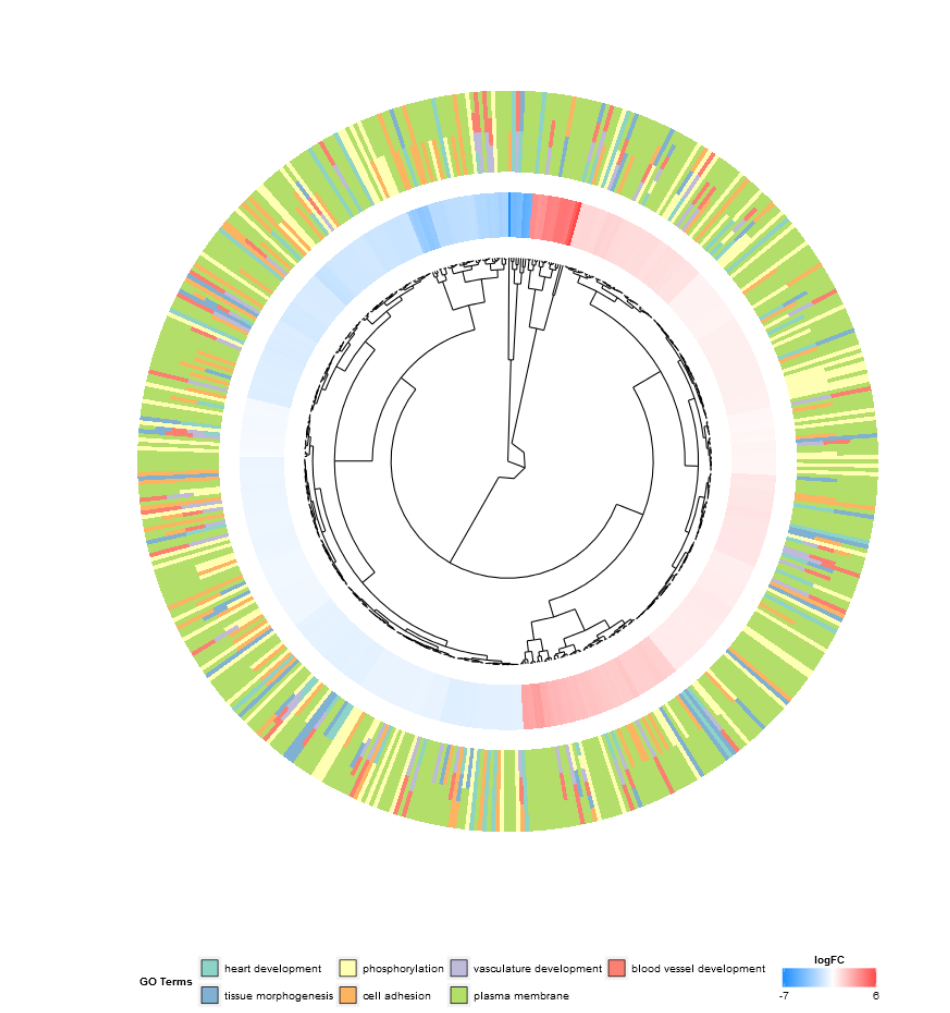
GOCluster(circ, EC$process, clust.by = 'term', lfc.col = c('darkgoldenrod1', 'black', 'cyan1'))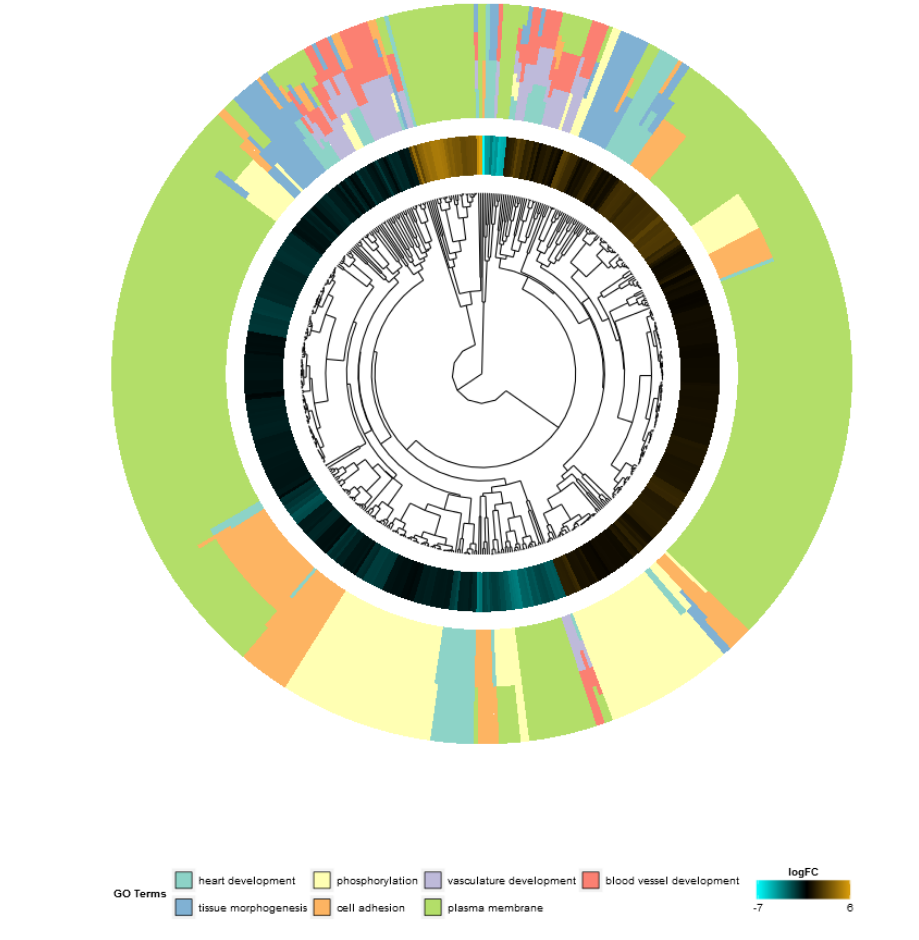
Venn diagram
l1 <- subset(circ, term == 'heart development', c(genes,logFC))
l2 <- subset(circ, term == 'plasma membrane', c(genes,logFC))
l3 <- subset(circ, term == 'tissue morphogenesis', c(genes,logFC))
GOVenn(l1,l2,l3, label = c('heart development', 'plasma membrane', 'tissue morphogenesis'))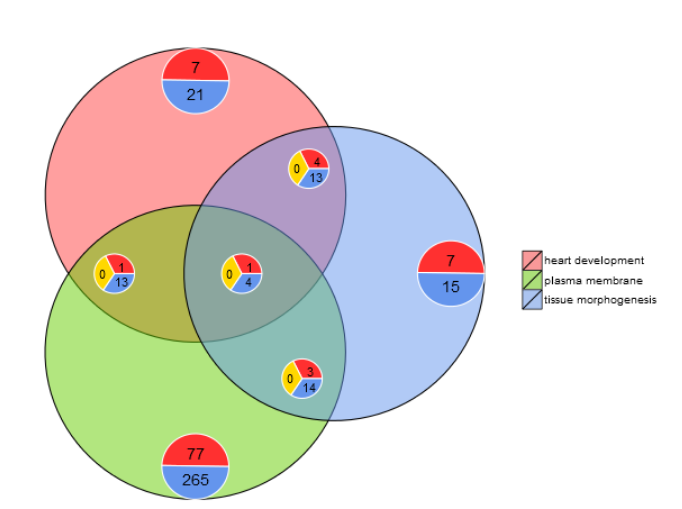
参考
GOplot (wencke.github.io)
往期
- END -
