
本节接着上节内容讲了关于增删查改的一些初级内容,
大家可以先看看,
下期升级,
我们不见不散~~~
目录
本节主要讲述MySQL的增删查改(这里是入门阶段讲解)
1.新增数据
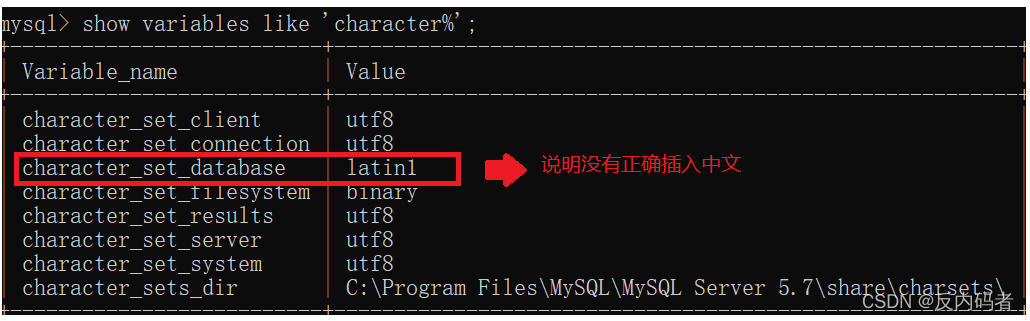
在新增数据之前,我们要先查看当输入字符串时,能不能输入中文,因为MySQL默认是拉丁文,如若不能,我们则要进行修改。
①不支持中文模式会存在的问题
②查看是否已经是支持中文模式
输入:show variables like 'character%';
由上图表名没有成功更改为中文,因此我们需要自己来进行更改操作
③通过MySQL配置服务来进行修改
a.打开Windows输入服务
b.打开服务,同时找到正在运行的MySQL,并且右键打开属性,同时记录下文件的路径
c.在我的电脑中打开文件的路径,会出现以下文件,注意!!!修改前一定要先备份,否则,将有极大可能性导致改错后无法挽回
d.打开文件后,以#开头的均为注释,我们需要找到两行注释,将其改成以下模样
e.修改完成后的三步走战略:
1)记得保存
2)重启MySQL服务器或者重启电脑
3) 还得把之前的数据库删了,并重建新的数据库
④修改成功的显示:
如果以上步骤均无误,恭喜你修改成功



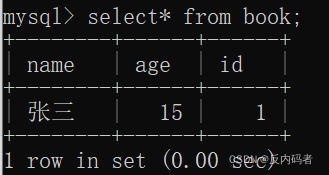
1.1单行数据 + 全列插入
①格式:
insert into 表名 values(值,值,......)
②演示:
a.插入
b.查看插入值,在后面将会讲到

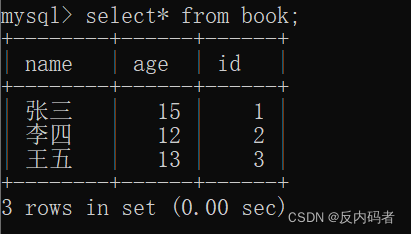
1.2多行数据 + 指定列插入
①格式:(每行间用,隔开即可)
insert into 表名 values(值,值,......),(值,值.....);
②演示:
a.直接插入两行
b.分别分两次进入插入
两者所得到的最终结果均如下所示,但是,第一种的速度却远快于第二种,即第一种的效率更高;
c.查看插入值(后面会讲到)


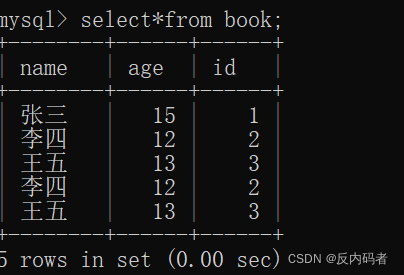
2.查询数据
是SQL最核心也最复杂的部分
2.1 全列查询
①格式:(最基础的查询,是将整个行整个列全部查找出来的操作)
select*from+表名;
而在此处*是一个通配符,表示的是这张表的所有列
②演示:
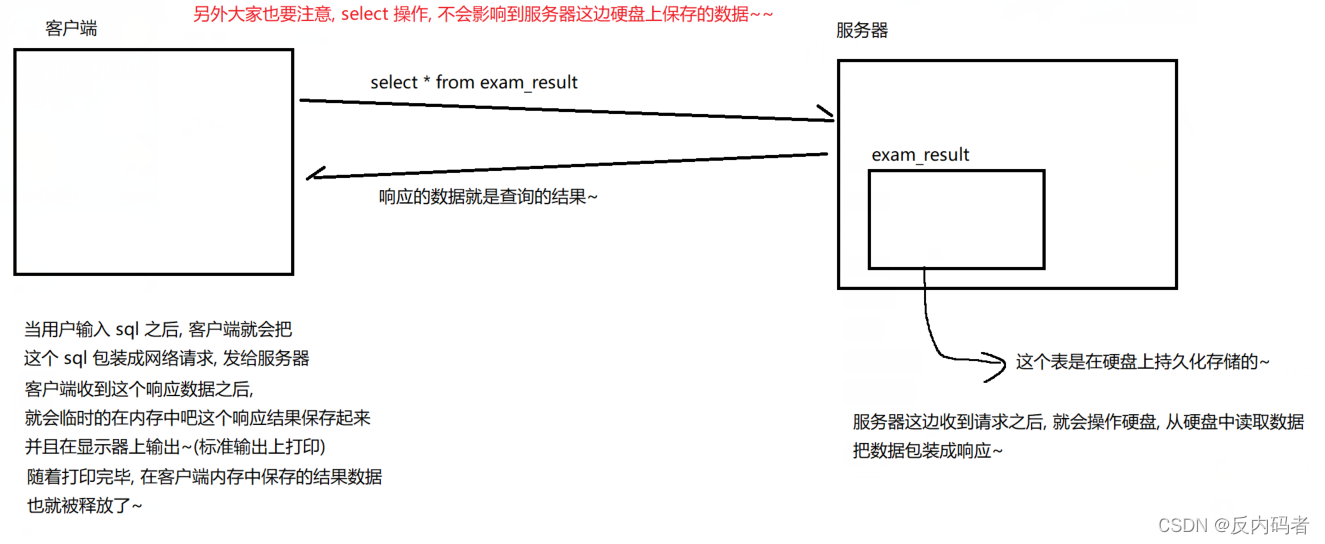
③临时表:
我们所查找到的表是一个临时表,我们之前说过数据库的表是存储在硬盘,但此处数据的查询却是临时表,随着表被显示的同时,数据也就被释放了;
④注意:
(select*from 实际上是一个很危险的操作)
因为生产环境保存的数据是非常大的,这就意味着MySQL服务器会疯狂的来读取硬盘数据,瞬间就会把硬盘的IO吃满,而硬盘的读取速度是存在上限的,尤其是机械硬盘,同时MySQL服务器又会立即的返回响应数据,由于返回的响应数据也很大很多,就会把网卡的宽带吃满,一旦服务器的硬盘和网络被吃满,此时数据库服务器就难以对其它的客户端的请求做出相应,而作为生产环境的服务器,需要无时无刻地给普通用户提供响应,数据库就好像废了一般。
而在实际开发中,一般公司都会对SQL的执行时间做出监控,一旦发现出现了这种长时间执行的“慢SQL”,就强制把这个SQL给杀死
2.2指定列查询
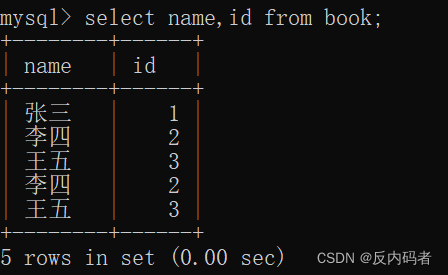
①格式:(只查询自己所关注的列)
select +列名,列名 +from+表名;
②演示:(在此就只显示name和id两列)
③注意:
这种有针对性的查询在日常中工作中才更容易用到,再次提醒这些关于查找的操作是一个临时数据表,且会随着打印的同时,释放内存,对原数据没有任何的影响;
2.3查询字段为表达式
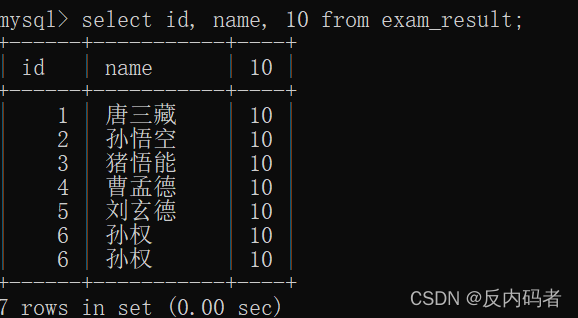
①格式及演示:(即在查询的过程中进行一些运算操作,列与列间)
a.表达式不包含字段:select id, name, 10 from exam_result;
b.表达式包含一个字段:select name, id, chinese+10 from exam_result;
c.表达式包含多个字段:select name, id, chinese+math+english from exam_result;

2.4别名
①格式:(一般用于名字太长从而为了避免错误的写法):
a.一般情况下,最好把as写上,避免看错:select name, id, chinese+math+english as sum from exam_result:
b.也可以不写,但还是推荐写上:select name, id, chinese+math+english sum from exam_result:


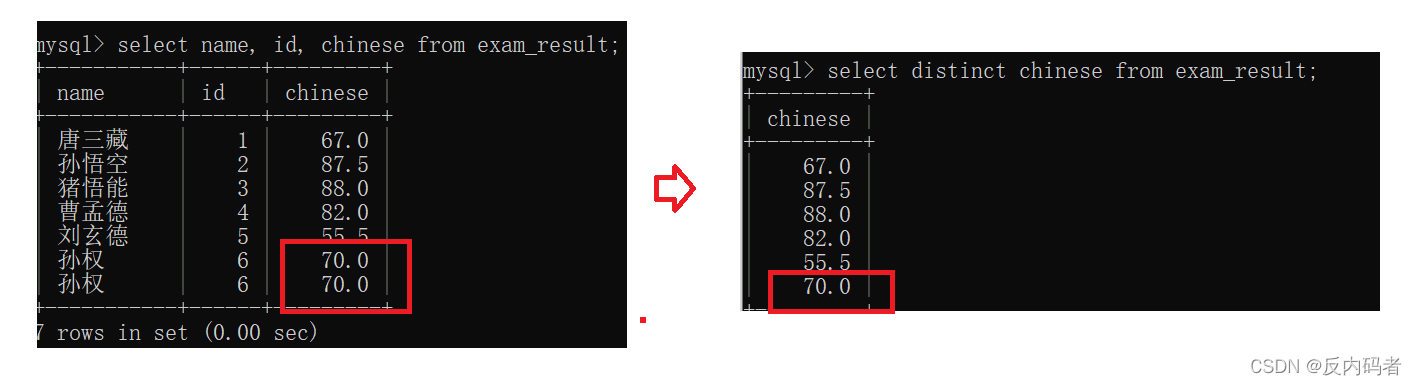
2.5去重:DISTINCT
①格式及演示:(将重复数据去掉)
distinct关键字来进行操作
2.6排序:ORDER BY
①格式及演示:(主要是针对某些特定的条件,如升序,降序等)
select 列名......from 表名 order by 列名 asc/desc......
a.直接排序
b.针对表达式来进行排序
c.利用别名进行排序
②注意:
a. asc为升序,desc为降序,而如果什么都不加,则表示默认为升序。
b.如果在待排序列中存在null,那么null将会是被认为成最小的值,要么排在升序最前面,要么排在降序最后面

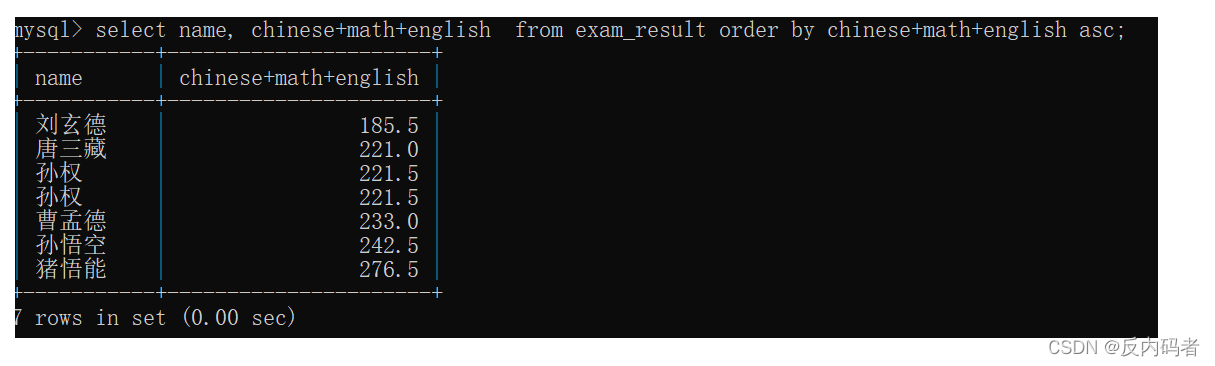
2.7条件查询:where
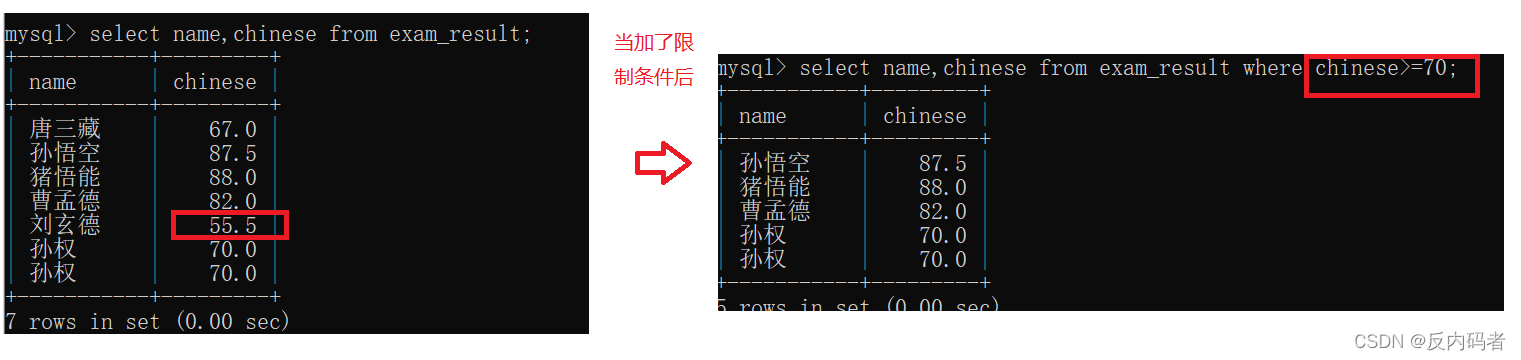
①格式:(where后面跟具体条件)
select 列名 from 表名 +where
②比较运算符:
运算符 说明 >, >= , <= , < 大于,大于等于,小于等于, 小于 = <=> !=, <> 不等于 between a and b in(option,......) is null 是 null is not null 不是null like a.<=相关符号示例:
b.between and示例:
注意:
当然between and也可以实现如下的同义替换:
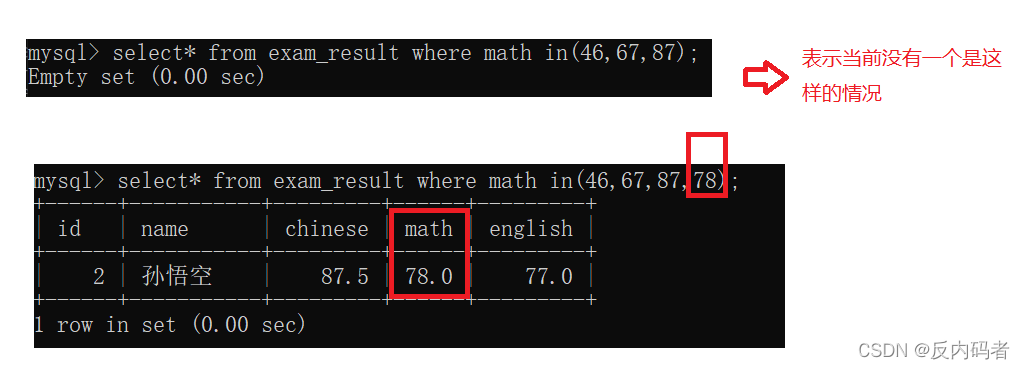
c.in的使用:
d.is null示例:
(此图表示没有出现这种情况)
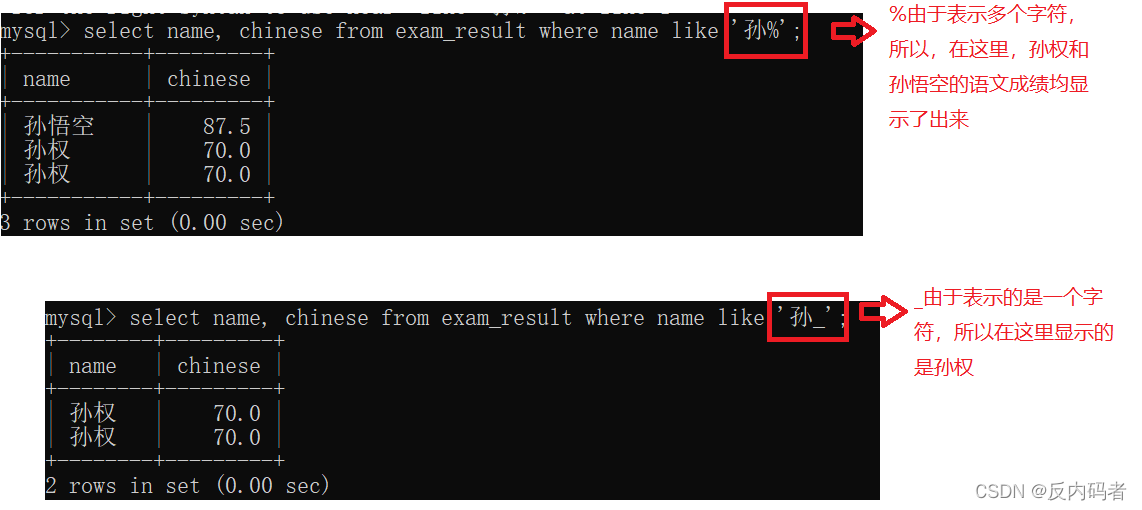
e.like 搭配通配符来进行使用的:
1、%:代表任意多个字符,当然也可以指0个字符
2、_:仅仅代表一个字符


2.8分页查询:LIMIT
①格式:(用limit来实现分页的操作)
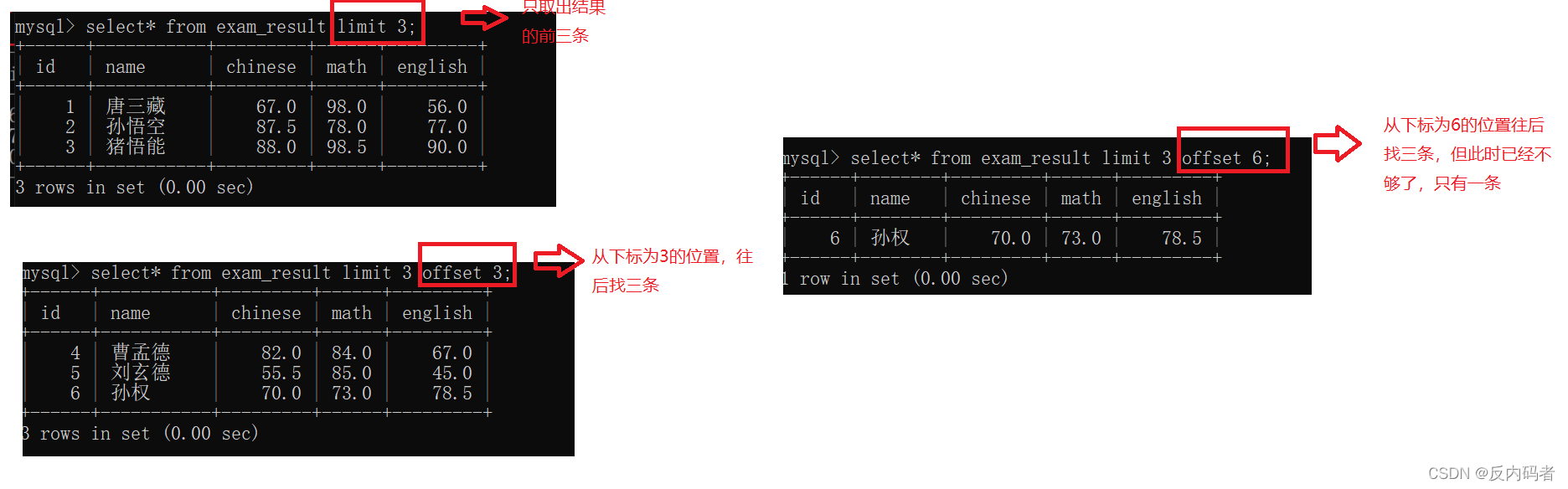
3.修改数据
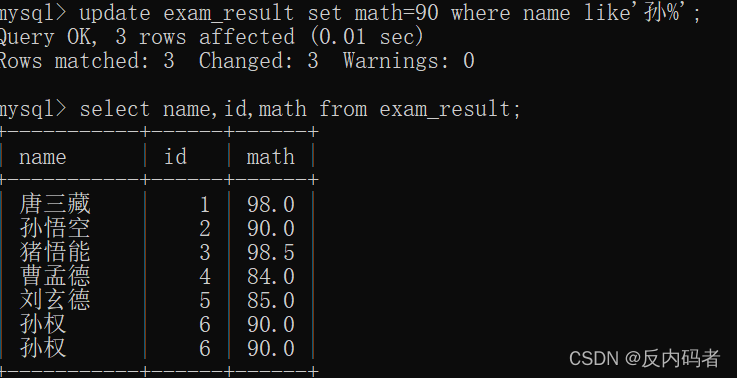
①格式:
update 表名 set 列名=值,列名=值 where +条件;
②注意:
updata的修改是会修改数据库服务器上的数据库;
4.删除数据
①格式:
delete from 表名 where + 条件
②示例:
③注意:
这里是删除表中的数据而得到一个空表,要是是drop table;就是连表一起进行删除了;

感谢观看~~~(#^.^#)