大家好,我是小小明。
最近有不少博主有需求,需要快速提取Markdown文档中的目录并转换为xmind思维导图,据说官方提供了用python直接生成xmind思维导图的方法,但有人反映生成的文件打不开。那么基于这个现状,我将开发一个效率辅助工具,帮助大家快速将Markdown转换为xmind。
软件使用介绍
首先打开程序,界面如下:
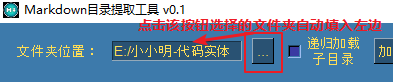
我们可以先选择被加载的Markdown文档所在的文件夹:
此时再点击加载按钮:
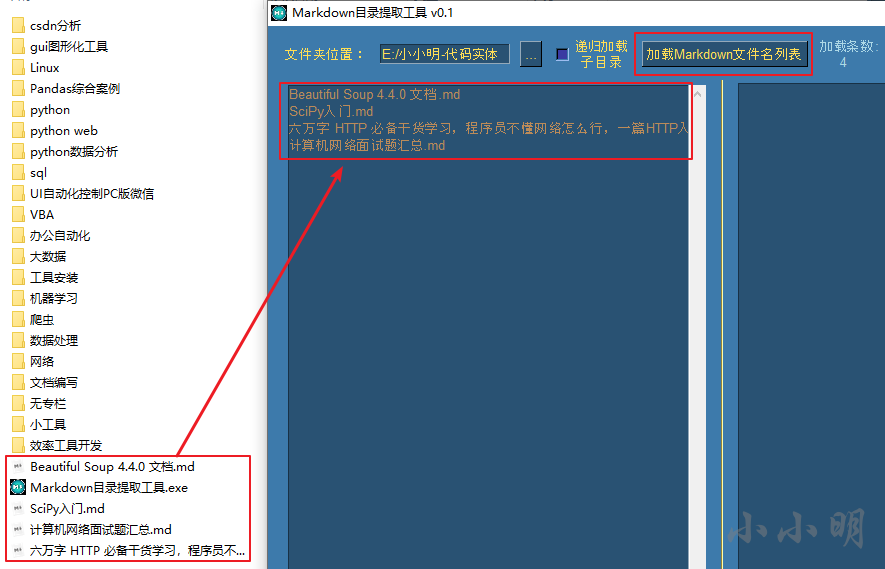
该目录下的所有md文件就都被加载到列表中。我们还可以再勾选 递归 复选框后进行加载:
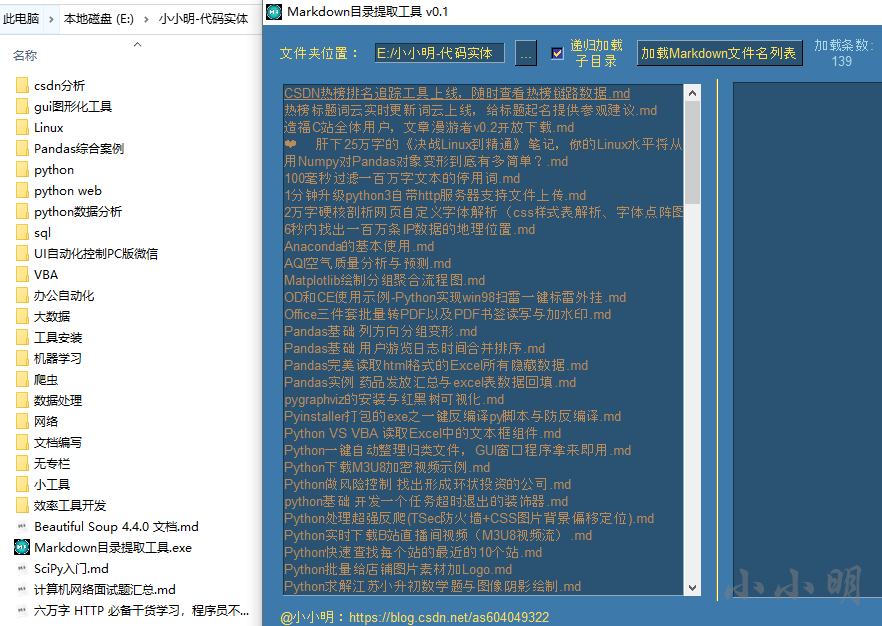
此时包含子文件就都被加载到列表中。
如何将获取指定Markdown文件对应的目录呢?
只需单击对应的列表项即可:
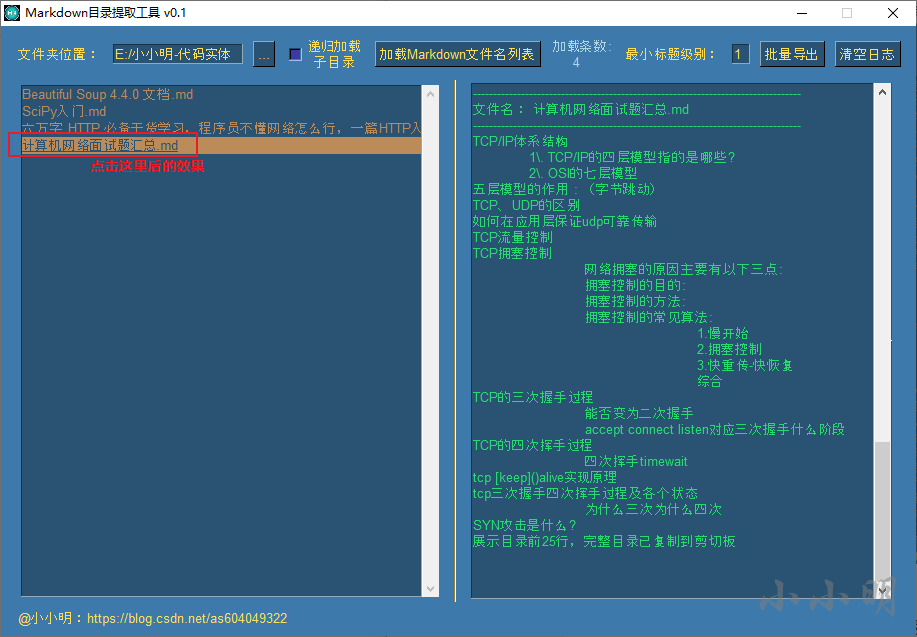
此时,Markdown目录已经被复制到剪切版,此时我们可以粘贴到xmind软件中。打开xmind软件后,删除多余节点后,选中中心节点,再粘贴:
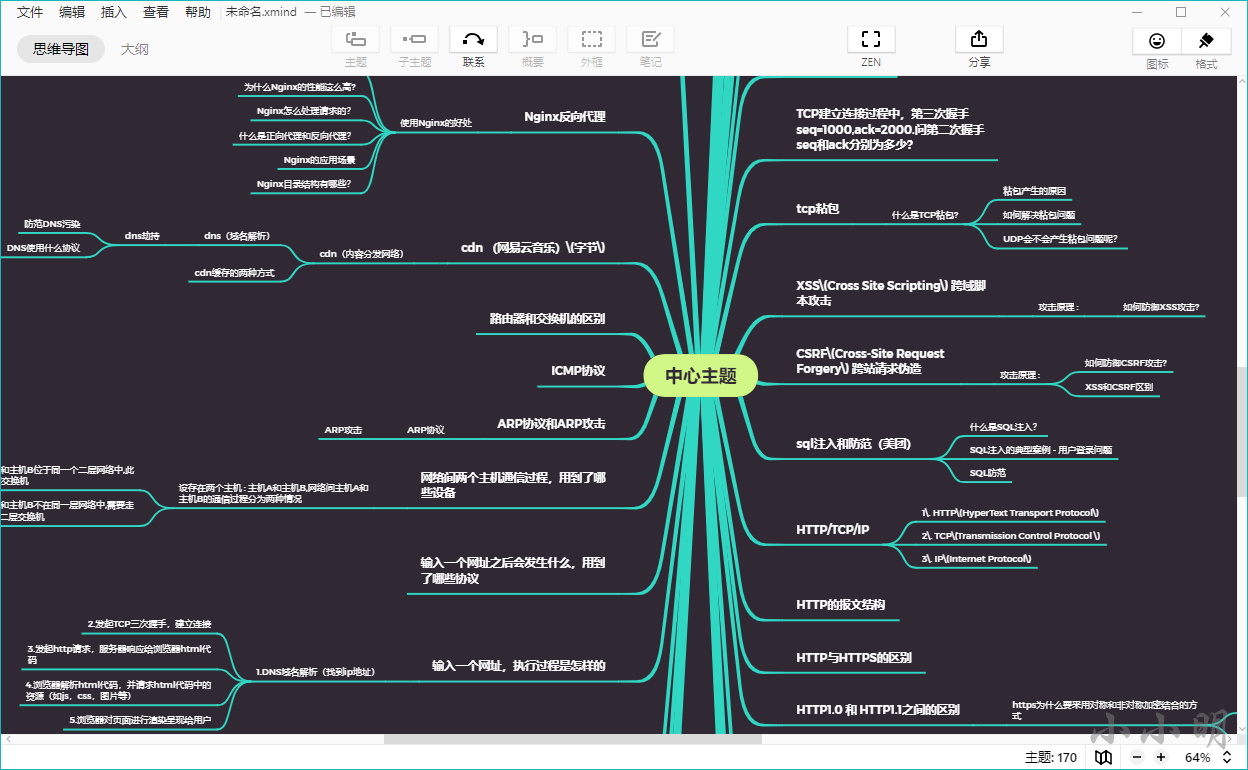
可以看到结果已经成为比较完美的思维导图,此时我们只需修改中心节点的名称后保存即可。
当然有部分Markdown文档比较特殊,比如:
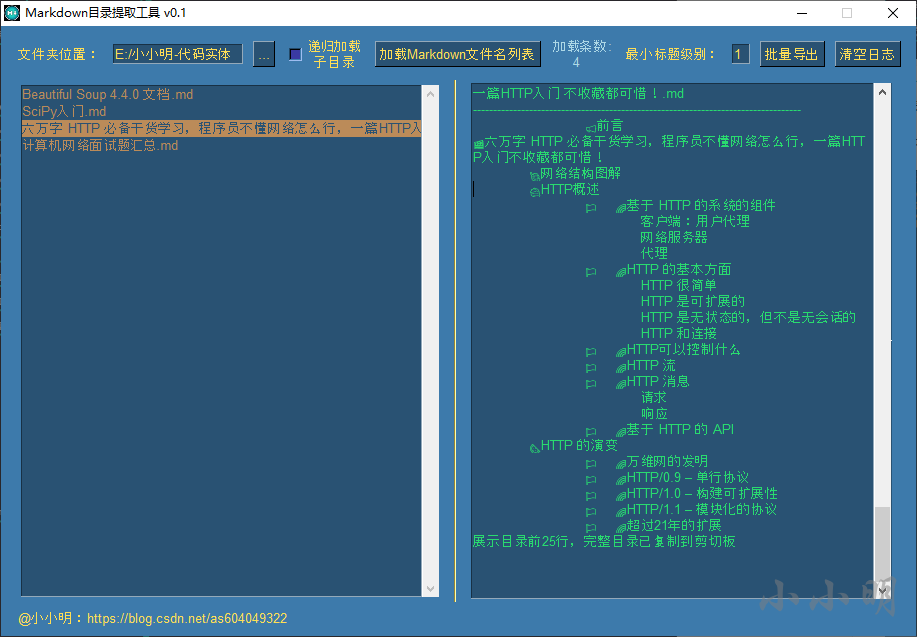
我们希望把一级标题去掉,其他级别的标题提高一级,可以将最小标题级别修改为2之后再单击该文章:
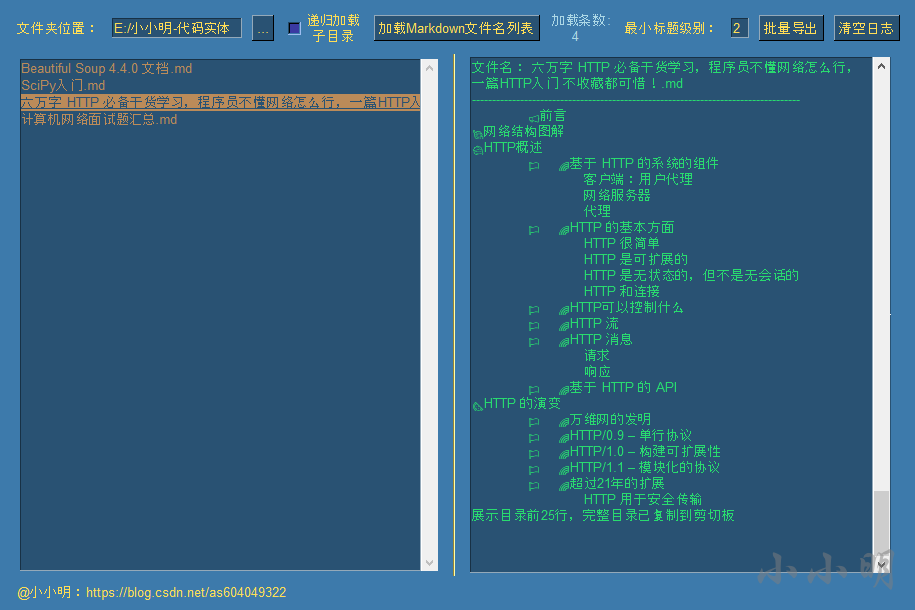
此时再去xmind粘贴就能获取想要的效果。
当然对于列表中的文件,我们还可以批量导出目录文件,点击批量导出即可。点击批量导出后,先选择一个保存的位置,选择后则开始导出:

若点击后取消保存文件夹的选择就会终止导出任务的执行。
开发代码
先开发一个提取Markdown目录的功能:
import cchardet
def load_md(filename, min_level=1):
with open(filename, "rb") as f:
md_bytes = f.read()
encoding = cchardet.detect(md_bytes)['encoding']
if encoding is None:
encoding = "u8"
md = md_bytes.decode(encoding)
code_area = False
result = []
for line in md.splitlines():
if line.startswith("```"):
code_area = not code_area
if code_area or not line.startswith("#") or line.find(" ") == -1:
continue
num_sign, title = line.split(maxsplit=1)
if not title:
continue
tab_num = len(num_sign) - min_level
if tab_num < 0:
continue
result.append("\t" * tab_num + title)
return result
这里我使用了cchardet进行编码识别,未使用过的读者需要安装:
pip install cchardet
上述代码的原理就是按行读取Markdown文本,碰到#开头而且含空格的文本就认为是含标题的行,同时排除掉#是处于代码区域的情况。
其他代码,感兴趣的童鞋自行研究噢,完整代码和已打包好的工具请到codeChina下载。
工具和开源代码下载地址: