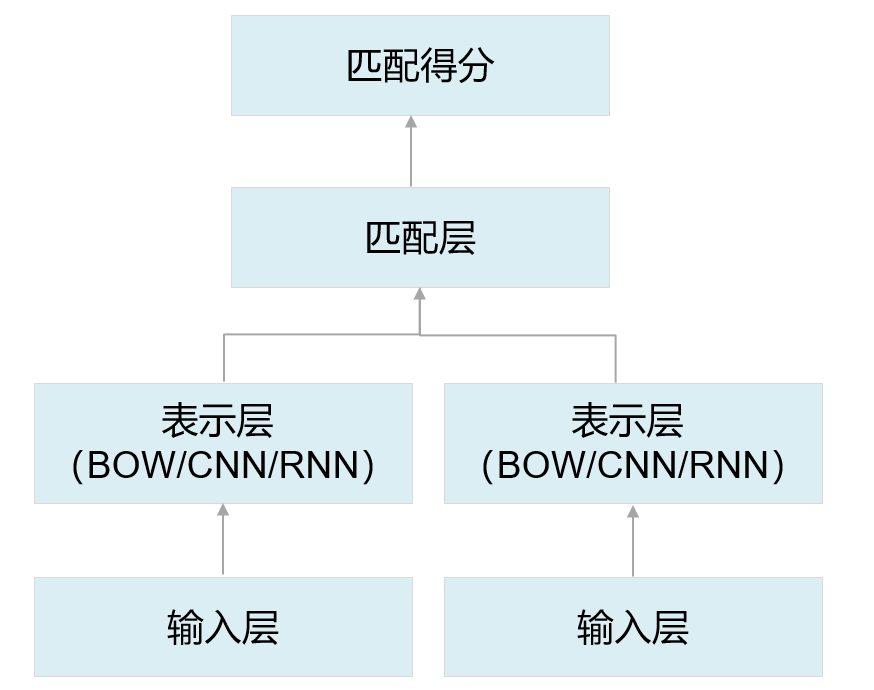
在NLP自然语言处理领域,有时我们需要计算不同文本之间的相似度,将不同文本进行编码,然后处理成Embedding定长表示向量,然后使用LSTM进行输出文本表示,定义多个多输入源数据进行计算。
句子1:我不爱吃剁椒鱼头,但是我爱吃鱼头
句子2:我爱吃土豆,但是不爱吃地瓜
同样使用LSTM网络,把每个句子抽象成一个向量表示,通过计算这两个向量之间的相似度,就可以快速完成文本相似度计算任务。在实际场景里,我们也通常使用LSTM网络的最后一步hidden结果,将一个句子抽象成一个向量,然后通过向量点积,或者cosine相似度的方式,去衡量两个句子的相似度。
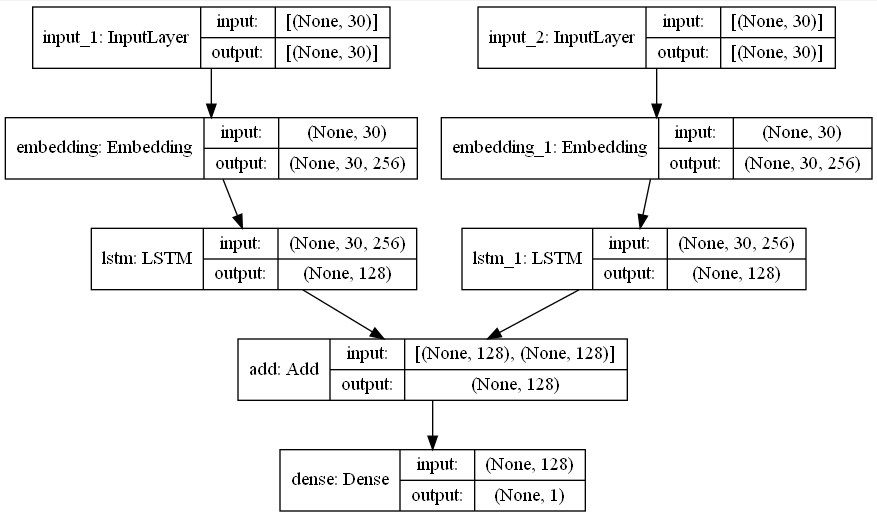
代码如下:
"""
* Created with PyCharm
* 作者: 阿光
* 日期: 2022/1/14
* 时间: 18:55
* 描述:
"""
import tensorflow as tf
from keras import Model
from tensorflow.keras.layers import *
def get_model():
x_input = Input(shape=30)
y_input = Input(shape=30)
x_embedding = Embedding(input_dim=252173,
output_dim=256)(x_input)
y_embedding = Embedding(input_dim=252173,
output_dim=256)(y_input)
x_lstm = LSTM(128)(x_embedding)
y_lstm = LSTM(128)(y_embedding)
def cosine_distance(x1, x2):
x1_norm = tf.sqrt(tf.reduce_sum(tf.square(x1), axis=1))
x2_norm = tf.sqrt(tf.reduce_sum(tf.square(x2), axis=1))
x1_x2 = tf.reduce_sum(tf.multiply(x1, x2), axis=1)
cosin = x1_x2 / (x1_norm * x2_norm)
return tf.reshape(cosin, shape=(-1, 1))
score = cosine_distance(x_lstm, y_lstm)
output = Dense(1, activation='sigmoid')(score)
model = Model([x_input, y_input], output)
return model
model = get_model()
model.summary()