What-什么是LSTM和BiLSTM?
LSTM:全称Long Short-Term Memory,是RNN(Recurrent Neural Network)的一种。LSTM由于其设计的特点,非常适合用于对时序数据的建模,如文本数据。
BiLSTM:Bi-directional Long Short-Term Memory的缩写,是由前向LSTM与后向LSTM组合而成。
可以看出其很适合做上下有关系的序列标注任务,因此在NLP中常被用来建模上下文信息。
我们可以简单理解为双向LSTM是LSTM的改进版,LSTM是RNN的改进版。
(这里简单说一下RNN,熟悉的可以直接跳过。RNN的意思是,为了预测最后的结果,我先用第一个词预测,当然,只用第一个预测的预测结果肯定不精确,我把这个结果作为特征,跟第二词一起,来预测结果;接着,我用这个新的预测结果结合第三词,来作新的预测;然后重复这个过程;直到最后一个词。这样,如果输入有n个词,那么我们事实上对结果作了n次预测,给出了n个预测序列。整个过程中,模型共享一组参数。因此,RNN降低了模型的参数数目,防止了过拟合,同时,它生来就是为处理序列问题而设计的,因此,特别适合处理序列问题。LSTM对RNN做了改进,使得其能够捕捉更长距离的信息。但是不管是LSTM还是RNN,都有一个问题,它是从左往右推进的,因此后面的词会比前面的词更重要。因此出现了双向LSTM,它从左到右做一次LSTM,然后从右到左做一次LSTM,然后把两次结果组合起来。)
Why-为什么使用LSTM与BiLSTM?
如果我们想要句子的表示,可以在词的表示基础上组合成句子的表示,那么我们可以采用相加的方法,即将所有词的表示进行加和,或者取平均等方法。但是这些方法很大的问题是没有考虑到词语在句子中前后顺序。而使用LSTM模型可以更好的捕捉到较长距离的依赖关系。因为LSTM通过训练过程可以学到记忆哪些信息和遗忘哪些信息。但是利用LSTM对句子进行建模也存在一个问题:无法编码从后到前的信息。而通过BiLSTM可以更好的捕捉双向的语义依赖。
How-BiLSTM原理

详细原理可看:https://www.jiqizhixin.com/articles/2018-10-24-13
Do-BiLSTM与NER任务
BiLSTM-CRF模型简单介绍
所有 RNN 都具有一种重复神经网络单元的链式形式。在标准的RNN中,这个重复的单元只有一个非常简单的结构,例如一个tanh层。

LSTM 同样是这样的结构,但是重复的单元拥有一个不同的结构。不同于普通RNN单元,这里是有四个,以一种非常特殊的方式进行交互。
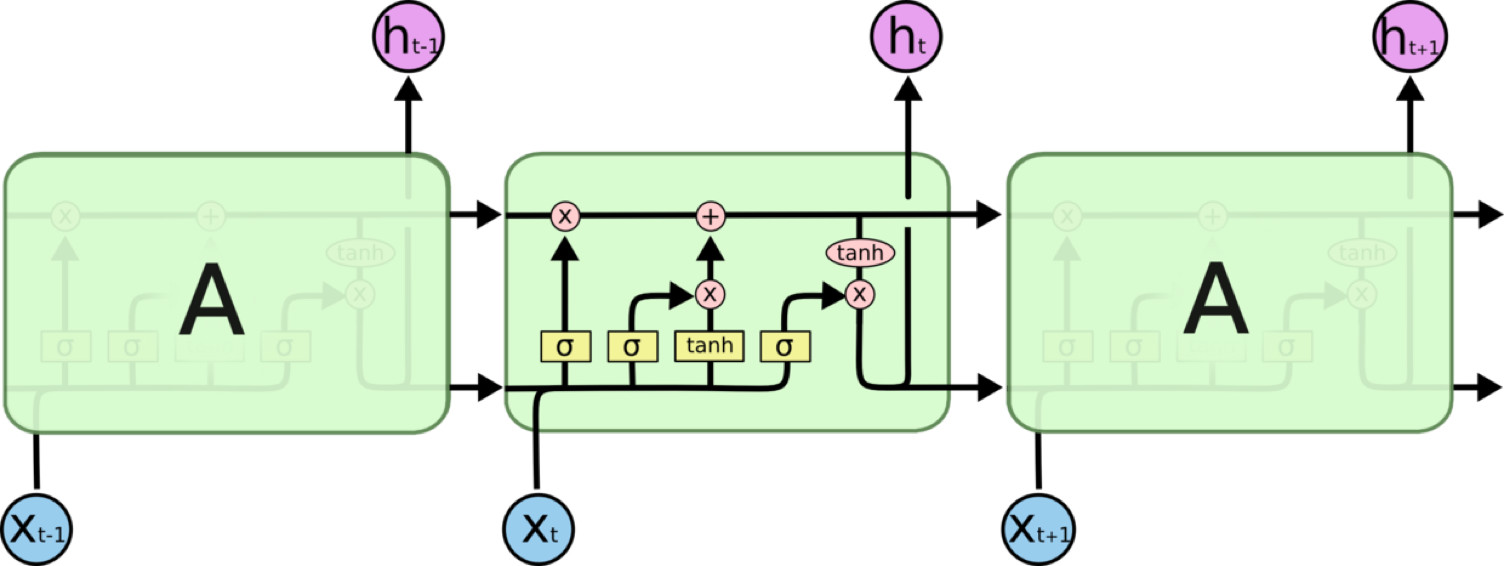
图4:LSTM结构
LSTM通过三个门结构(输入门,遗忘门,输出门),选择性地遗忘部分历史信息,加入部分当前输入信息,最终整合到当前状态并产生输出状态。
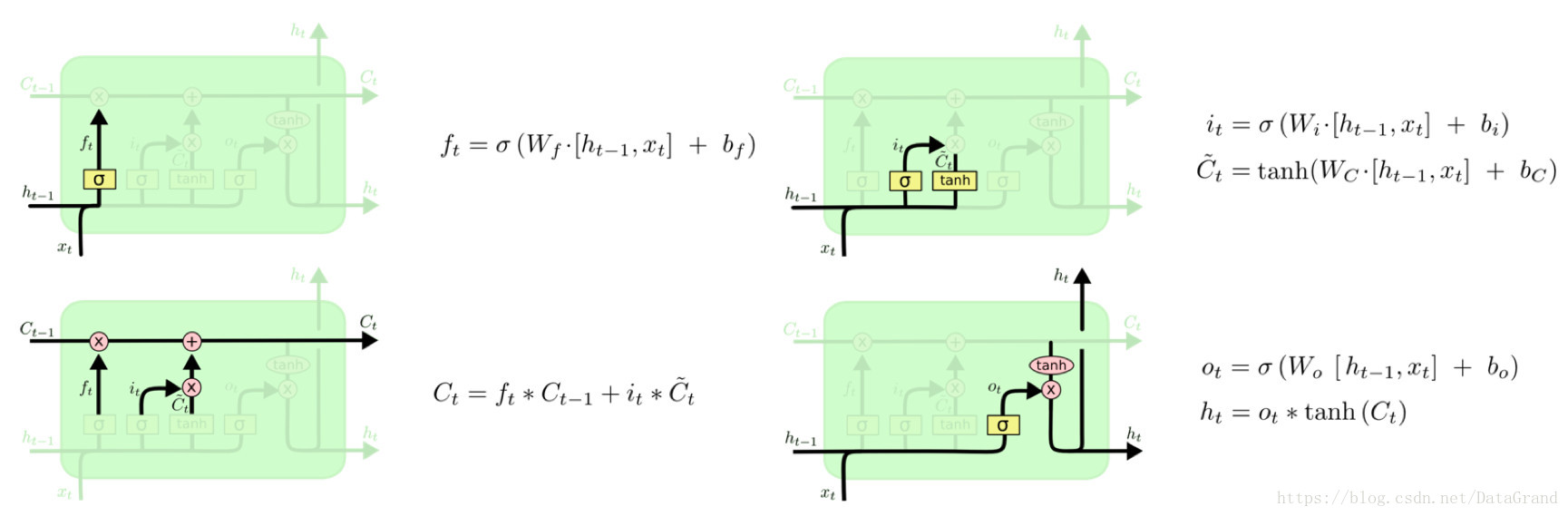
图5:LSTM各个门控结构
应用于NER中的biLSTM-CRF模型主要由Embedding层(主要有词向量,字向量以及一些额外特征),双向LSTM层,以及最后的CRF层构成。实验结果表明biLSTM-CRF已经达到或者超过了基于丰富特征的CRF模型,成为目前基于深度学习的NER方法中的最主流模型。在特征方面,该模型继承了深度学习方法的优势,无需特征工程,使用词向量以及字符向量就可以达到很好的效果,如果有高质量的词典特征,能够进一步获得提高。
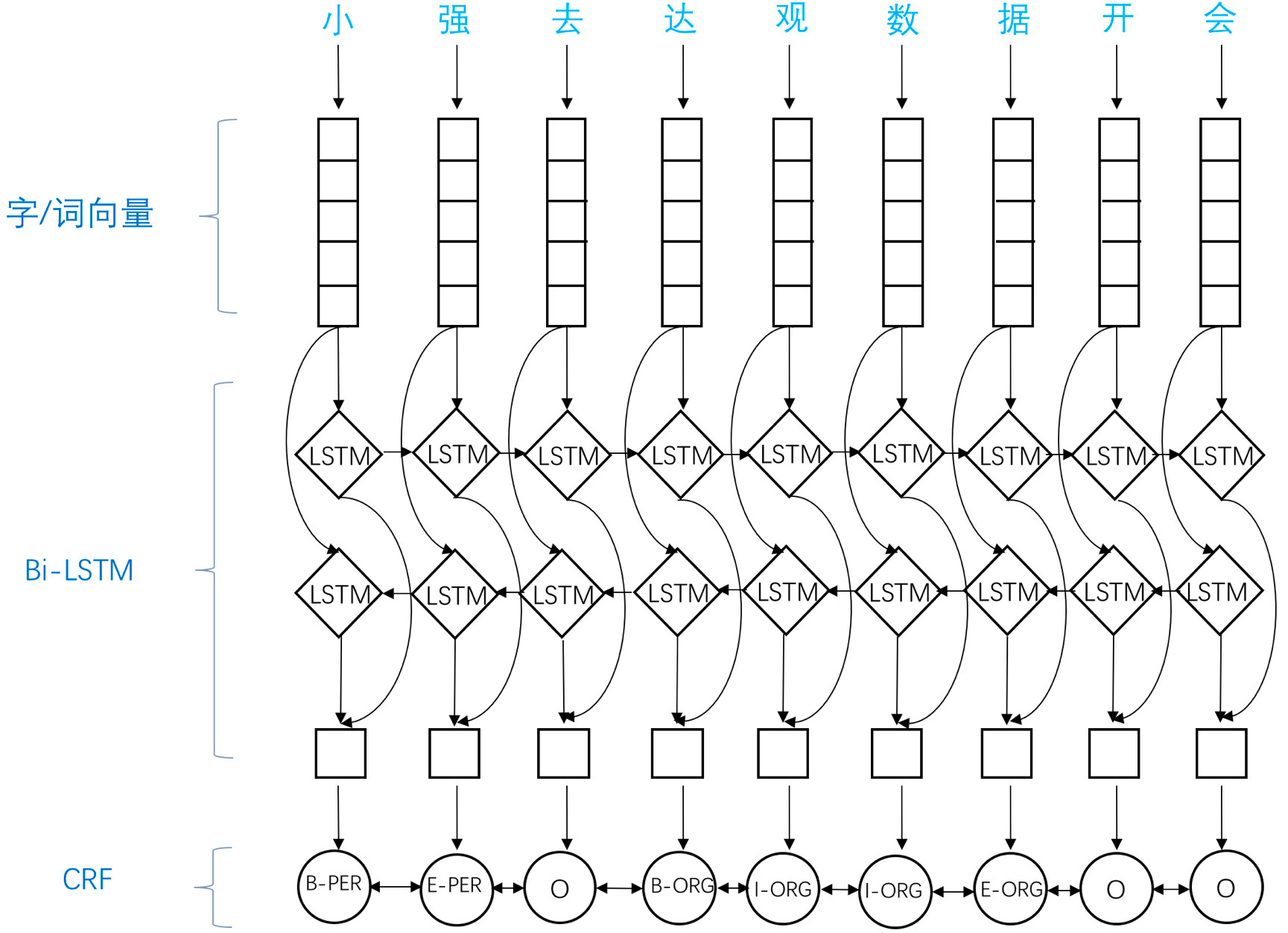
参考文章
https://my.oschina.net/datagrand/blog/2251431
https://www.jiqizhixin.com/articles/2018-10-24-13