1 分析页面
1.1 分析网址
https://bing.ioliu.cn/?p=11.2 元素寻找页面
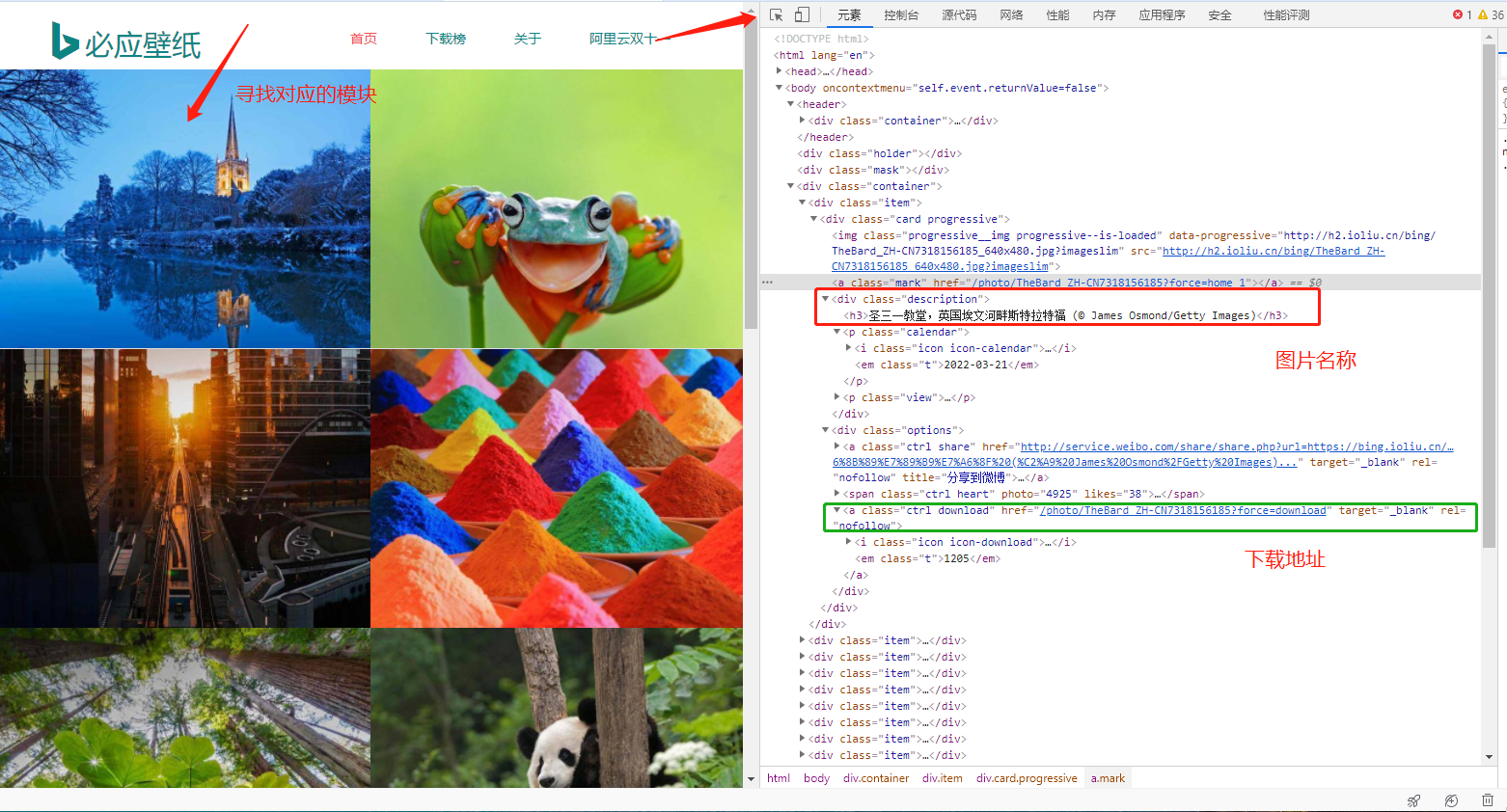
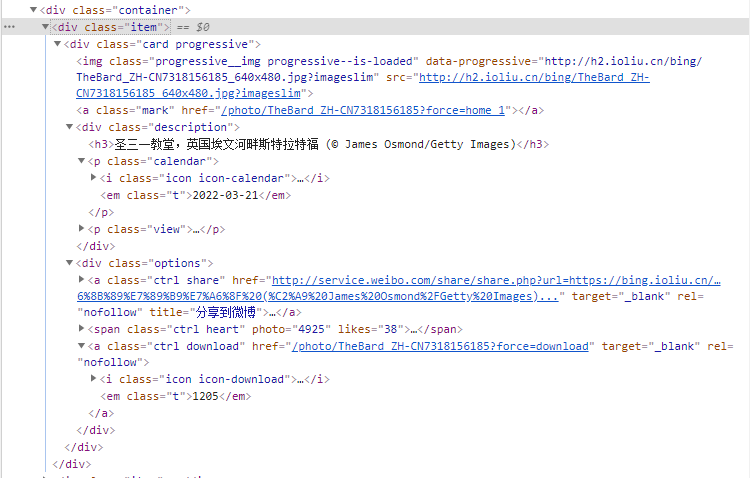
2 代码编写
import urllib3
import re
import os
http = urllib3.PoolManager() # 创建连接池管理对象
# 定义火狐浏览器请求头信息
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:77.0) Gecko/20100101 Firefox/77.0'}
# 通过网络请求,获得该页面的信息
def send_request(url,headers):
response = http.request('GET',url,headers=headers)
if response.status == 200:
html_str = response.data.decode('utf-8')
return html_str
# 解析地址并下载壁纸
def download_pictures(html_str):
# 提取壁纸名称
pic_names = re.findall('<div class="description"><h3>(.*?)</h3>',html_str)
print("未处理的壁纸名称:",pic_names)
# 提取壁纸的下载地址
pic_urls = re.findall('<a class="ctrl download" href="(.*?)" ',html_str)
print("未处理的下载地址:", pic_urls)
for name,url in zip(pic_names,pic_urls): # 遍历壁纸的名称与地址
pic_name = name.replace('/',' ') # 把图片名称中的/换成空格
pic_url = 'https://bing.ioliu.cn'+url # 组合一个完整的url
pic_response = http.request('GET',pic_url,headers=headers) # 发送网络请求,准备下载图片
if not os.path.exists('pic'): # 判断pic文件夹是否存在
os.mkdir('pic') # 创建pic文件夹
with open('pic/'+pic_name+'.jpg','wb') as f:
f.write(pic_response.data) # 写入二进制数据,下载图片
print('图片:',pic_name,'下载完成了!')
if __name__ == '__main__':
for i in range(1, 2):
url = 'https://bing.ioliu.cn/p={}'.format(i)
print(url)
html_str = send_request(url=url, headers=headers) # 调用发送网络请求的方法
download_pictures(html_str=html_str) # 调用解析数据并下载壁纸的方法3 效果展示
