机器之心报道 编辑:蛋酱
在这篇新论文中,TOELT LLC 联合创始人兼首席 AI 科学家 Umberto Michelucci 对自编码器进行了全面、深入的介绍。

论文链接:https://arxiv.org/pdf/2201.03898.pdf
神经网络通常用于监督环境。这意味着对于每个训练观测值 x_i,都将有一个标签或期望值 y_i。在训练过程中,神经网络模型将学习输入数据和期望标签之间的关系。
现在,假设只有未标记的观测数据,这意味着只有由 i = 1,... ,M 的 M 观测数据组成的训练数据集 S_T。
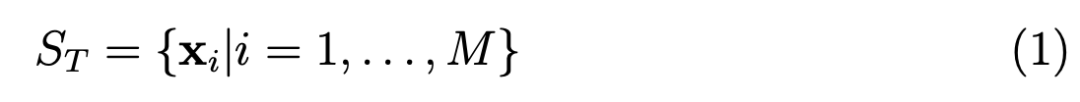
在这一数据集中,x_i ∈ R^n,n ∈ N。
1986 年,Rumelhart、Hinton 和 Williams 首次提出了自编码器(Autoencoder),旨在学习以尽可能低的误差重建输入观测值 x_i。
为什么要学习重建输入观测值?
如果你很难想象这意味着什么,想象一下由图片组成的数据集。自编码器是一个让输出图像尽可能类似输入之一的算法。也许你会感到困惑,似乎没有理由这样做。为了更好地理解为什么自编码器是有用的,我们需要一个更加翔实(虽然还没有明确)的定义。

图 1:自动编码器的一般架构。
为了更好地理解自编码器,我们需要了解它的经典架构。如下图 1 所示。自编码器的主要组成部分有三个:编码器、潜在特征表示和解码器。
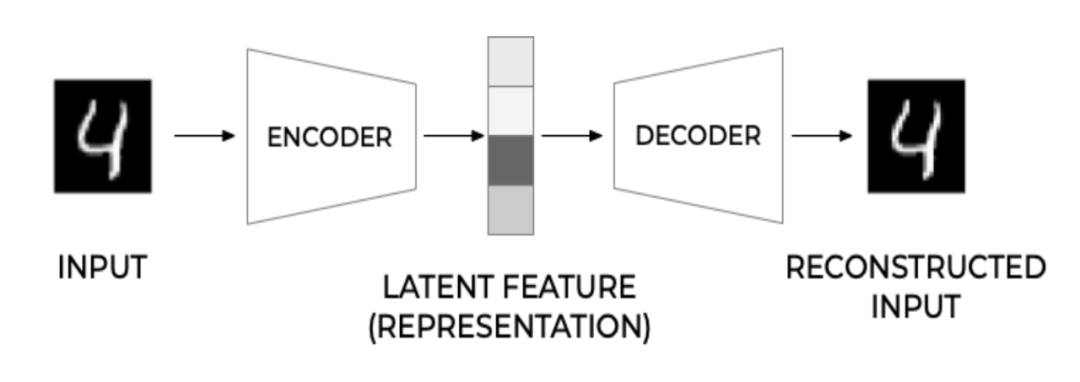
图 1:自动编码器的一般架构。
一般来说,我们希望自编码器能够很好地重建输入。同时,它还应该创建一个有用且有意义的潜在表示 (图 1 中编码器部分的输出)。例如,手写数字上的潜在特征可以是写每个数字所需的行数,或者每条线的角度以及它们之间的连接方式。
学习如何写数字不需要学习输入图像中每个像素的灰度值。人们也不会通过用灰色值填充像素来学习写作。在学习的过程中,我们提取基本的信息,这些信息可以帮助我们解决问题(例如写数字)。这种潜在表示法(如何写出每个数字)对于各种任务(例如可用于分类或聚类的实例特征提取)仅仅理解数据集的基本特征都非常有用。
在大多数经典架构中,编码器和解码器都是神经网络(这是本文将详细讨论的内容) ,因为它们可以很容易地用现有的软件库(TensorFlow 或 PyTorch)进行训练。一般来说,编码器可以写成一个函数 g,这个函数取决于一些参数

其中 h_i ∈ R^q (潜在特征表示)是图 1 中编码器块在输入 x_i 上求值时的输出。注意 g: R^n → R^q。
解码器(以及用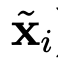 表示的网络输出)可以作为潜在特征的第二个通用函数 f 写入
表示的网络输出)可以作为潜在特征的第二个通用函数 f 写入
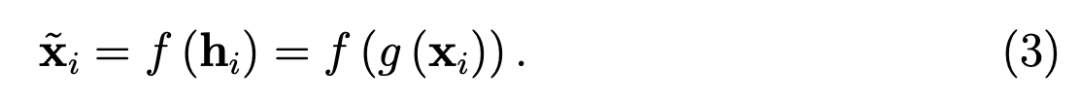
其中,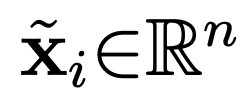 增加一个「瓶颈(bottleneck)」是通过使潜在特征的维度比输入的维度更低(通常要低得多)来实现的。这就是本文将详细讨论的情况。但在研究这种情况之前,需要提到正则化问题。
增加一个「瓶颈(bottleneck)」是通过使潜在特征的维度比输入的维度更低(通常要低得多)来实现的。这就是本文将详细讨论的情况。但在研究这种情况之前,需要提到正则化问题。
直观地说,正则化意味着在潜在特征输出中加强稀疏性。实现这一点的最简单方法是在损失函数中加入 l_1 或 l_2 正则项。
前馈自编码器
前馈自编码器(Feed-Forward Autoencoder,FFA)是由具有特定结构的密集层组成的神经网络,如下图 2 所示:

经典的 FFA 架构层的数量为奇数(尽管不是强制性要求),并且与中间层对称。通常,第一层有一定数量的神经元 n_1 = n(输入观察值 x_i 的大小)。向网络中心移动时,每一层的神经元数量都会有所下降。中间层通常有最少的神经元。事实上,这一层的神经元数量小于输入的大小,这是前面提到的「瓶颈」。
在几乎所有的实际应用中,中间层之后的图层是中间层之前图层的镜像版本。包括中间层在内及之前的所有层构成了所谓的编码器。如果 FFA 训练是成功的,结果将是输入的一个近似值,换句话说是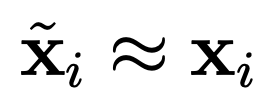 。需要注意的是,解码器只需要使用比最初的输入观测值 (n) 少得多的特征数 (q) 就可以重构输入。中间层的输出也称为输入观测值 x_i 的学习表示。
。需要注意的是,解码器只需要使用比最初的输入观测值 (n) 少得多的特征数 (q) 就可以重构输入。中间层的输出也称为输入观测值 x_i 的学习表示。
输出层的激活函数
在基于神经网络的自编码器中,输出层的激活函数起着特别重要的作用。最常用的函数是 ReLU 和 Sigmoid。
ReLU 激活函数可以假设范围 [0,∞] 内的所有值。作为余数,它的公式是 ReLU (x) = max (0,x)。当输入的观测值 x_i 假设范围很广的正值时,ReLU 是个很好的选择。如果输入 x_i 可以假设负值,那么 ReLU 当然是一个糟糕的选择,而且恒等函数是一个更好的选择。
Sigmoid 函数 σ 可以假定所有值的范围在] 0, 1 [ 。作为余数,它的公式是

只有当输入的观测值 x_i 都在] 0,1 [范围内,或者将它们归一化到这个范围内,才能使用这个激活函数。在这种情况下,对于输出层的激活函数来说,Sigmoid 函数是一个不错的选择。
损失函数
与任何神经网络模型一样,这里需要一个损失函数来最小化。这个损失函数应该测量输入 x_i 和输出 x˜i 之间的差异有多大:

其中,FFA、 g 和 f 是由全连接层获得的函数。自编码器广泛使用两种损失函数:均方差和二进制交叉熵。它们只有在满足特定需求时才能使用。
由于自编码器试图解决回归问题,最常用的损失函数是均方差(MSE):

如果 FFA 输出层的激活函数是一个 sigmoid 函数,即将神经元输出限制在 0 到 1 之间,并且输入特征被标准化为 0 到 1 之间,我们以使用 LCE 表示的二元交叉熵作为损失函数。

重构误差
重构误差 (RE) 是一个度量,它指示了自编码器能够重建输入观测值 x_i 的好坏。最典型的 RE 应用是 MSE
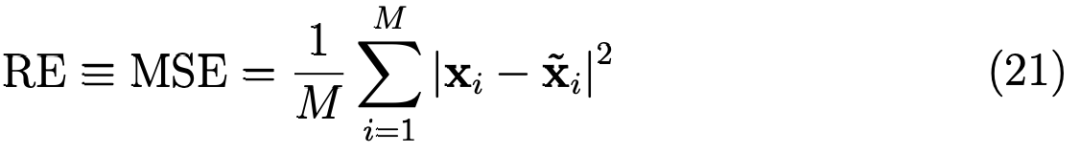
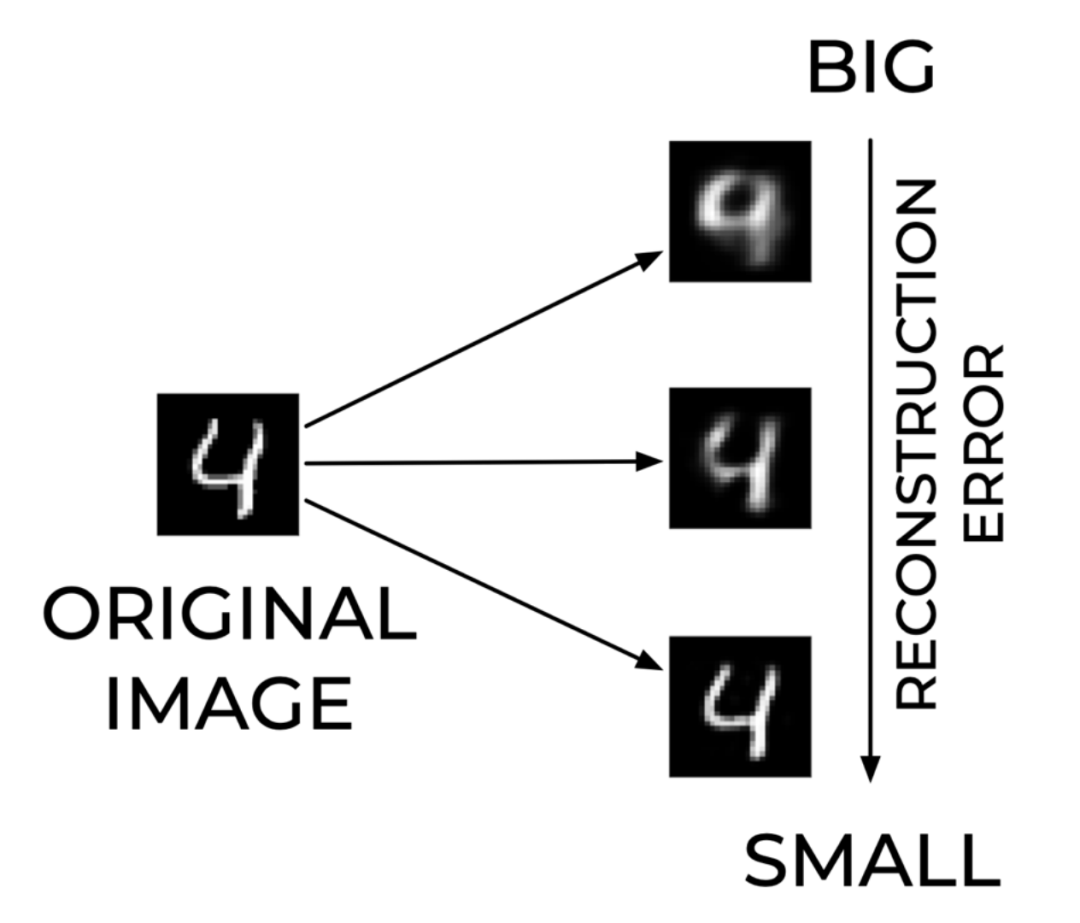
这很容易计算出来。在使用自编码器进行异常检测时,常常用到 RE。对于重建误差有一个简单的直观解释。当 RE 值较大时,自编码器不能很好地重构输入信号,当 RE 值较小时,重构是成功的。下图 3 展示了一个自编码器试图重建图像时出现的大大小小的重建错误的示例。
在最后一部分,作者还介绍了自编码器的几种应用,如降维、分类、去噪和异常检测,以及应用过程涉及的其他理论方法。更多细节详见原论文。
猜您喜欢:

附下载 |《TensorFlow 2.0 深度学习算法实战》
