文章目录
- 前文知识点回顾
- 正文 :对数据表进行“增删查改”操作
- 下一篇 [对数据表进行“增删查改”的进阶操作](https://blog.csdn.net/DarkAndGrey/article/details/123359881)
前文知识点回顾
MySQL第二讲 - 数据表简单操作 与 “增删查改的开头部分- 增”这个上篇博文中主要讲的是关于 数据库中 数据表的操作。
正文 :对数据表进行“增删查改”操作
新增操作 - insert 关键字
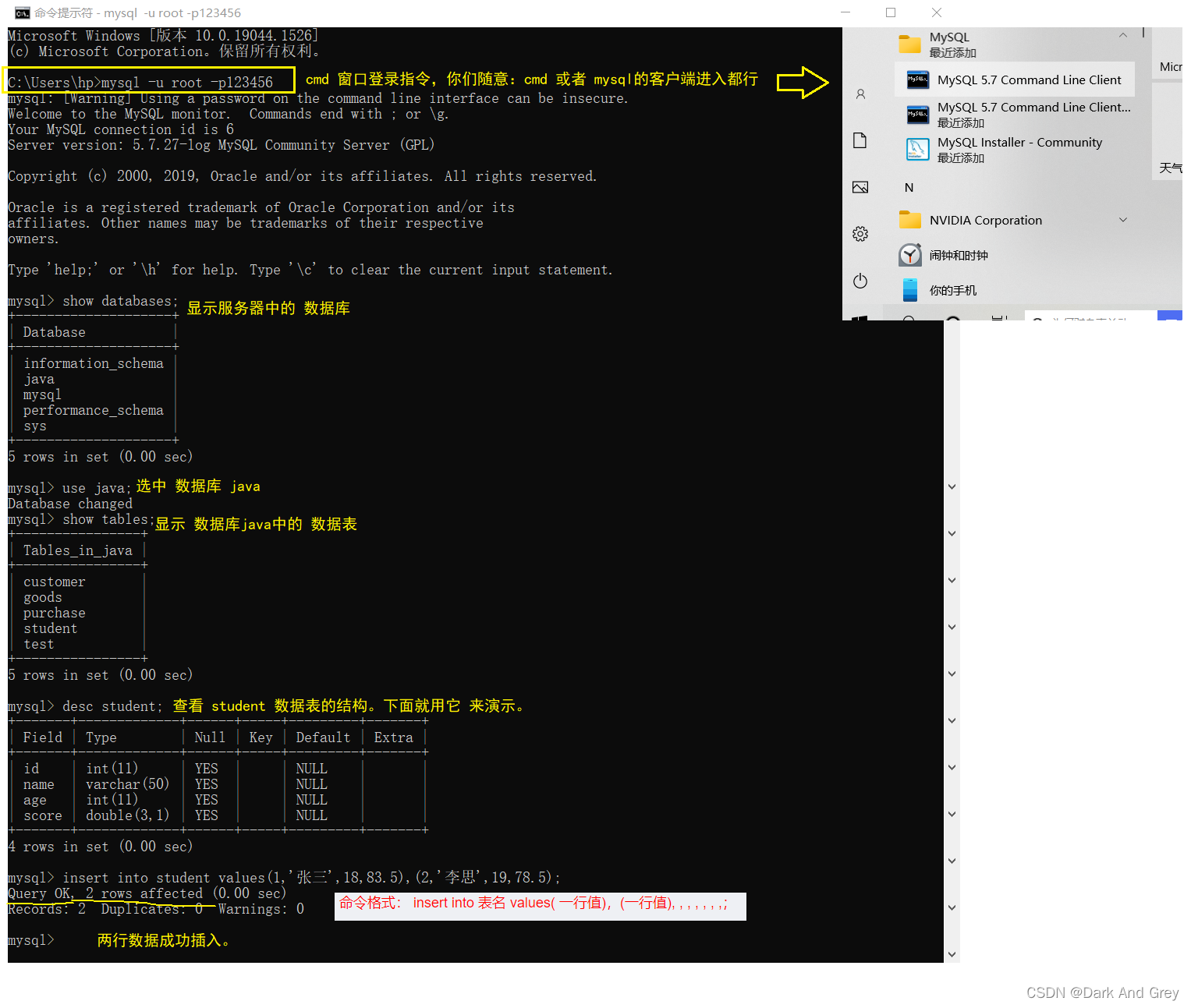
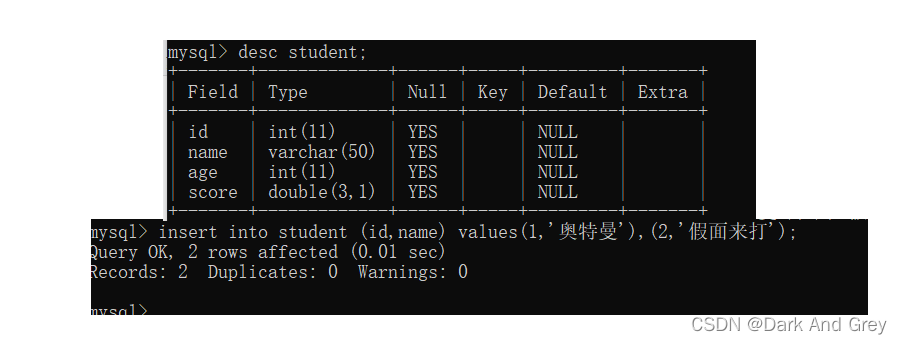
上篇博客中只是介绍了一个简单插入操作: insert into 表名 values(列值,列值…);
这个括号中的 列值的个数要与插入的数据表的列数相等,且对应的列值的类型也要相匹配【简单来说:要插入数据,就直接插入一行满的数据。使其 插入的值个数 与 列数相等】
但是呢!insert 在进行插入的时候,通过指定插入的表头,就可以直插入某一列或者几列的数据(不用列值的个数 与列数相匹配)。此时其他的列将采用默认值。
命令:insert into 表名 (指定的表头们/ 字段) values(列值,列值…);
不过呢,插入操作 : insert into 表名 values(列的值…);
它一次其实可以插入多行数据,而上篇博文演示的只是一次插入一行数据 / 一行中几列。
下面我们就来演示 insert 关键字的多行插入数据。
命令格式: insert into 表名 values( 一行值),(一行值), , , , , , ,;
values 后面的每个括号都对应着一行的数据,可以一次性的带有多个(),多个() 之间使用 逗号来分割。
当然,我们也可以 指定 多行插入的列值和列数。【通过指定插入的表头,就可以直插入多行的某一列或者几列的数据(不用列值的个数 与列数相匹配)。此时其他的列将采用默认值。】
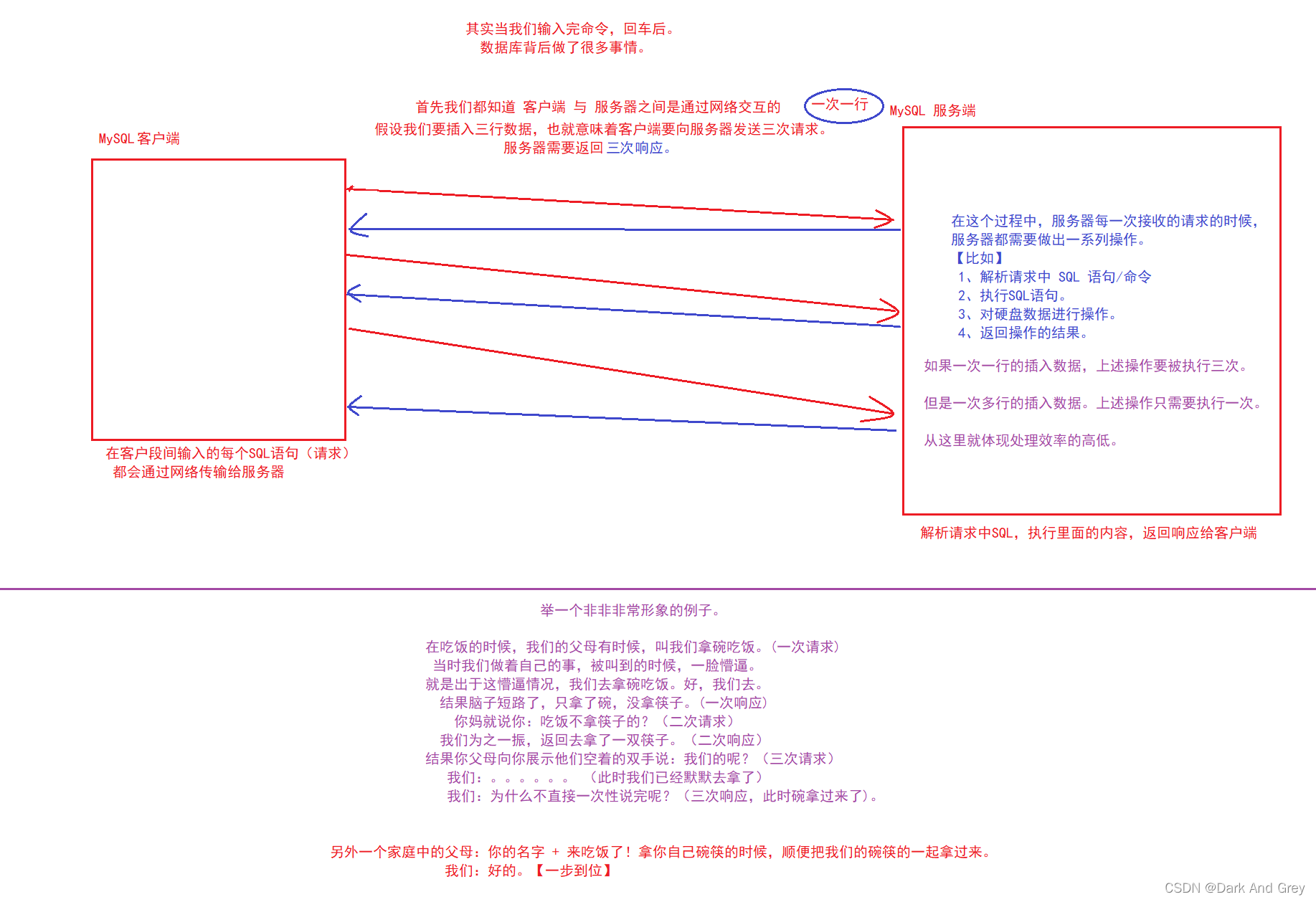
疑问时刻:当插入 N 行数据,insert 插入命令 : 一次插入一行(需要插入N次) 与 一次插入多行数据,有什么区别吗?
首先,从数据的角度来看,同时插入两行相等数据,分别对其进行一次插入一行 与 一次插入多行数据操作,两者存储数据不会存在差异,是一样的。
但是从插入数据的效率上看,一次插入多行数据 比 一次插入一行数据 要高出不少。【一次多行插入数据 速度是 一次一行的 好几倍】
通过上面的分析:我们很容明白,当行数一多,或者列数一多的时候,服务器做出相应的时间就越长(因为数据很多)。你又是一次一行的插入,那么这个时间效率非常的低。
如果我们一次多行插入数据,一步到位,那么服务器就省去了多余响应,一次性返回总的结果。
时间效率效率大大提升!!!
查找语句(基础操作) - select关键字 - 重点!!!!!!!!
我们说是“增删查改”,但是“增删改”都非常简单!
只有 “查” 有难度。
查找语句是 SQL语句 / 命令 中 最核心,也是最复杂的操作。
这么说吧:如果我们掌握了 查找语句,就基本上可以认为MySQL通关,后面也就没什么难点了。
1、最基础的查找:全列查找
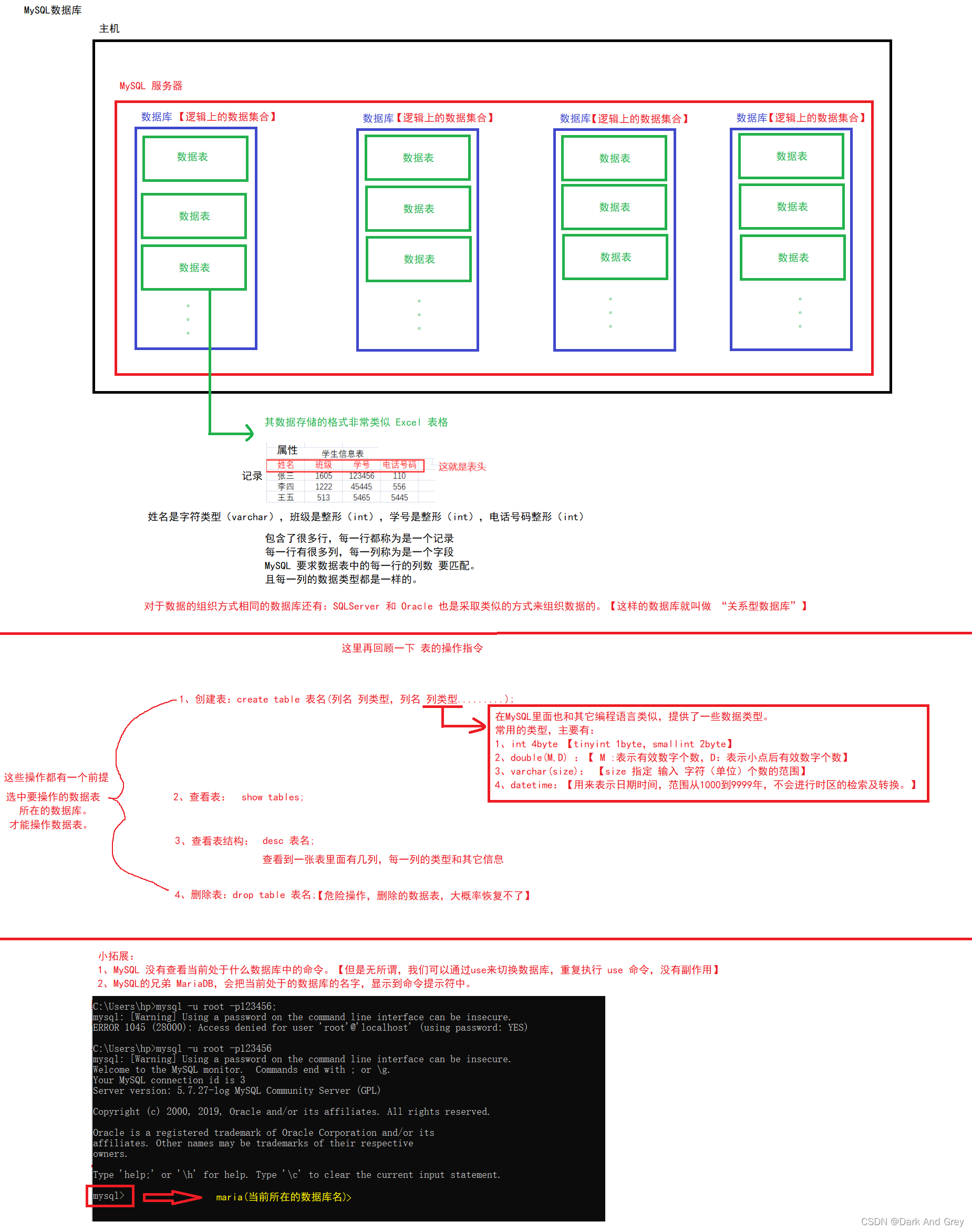
全列查找:就是直接把一个数据表中的 所有列 和 所有行 的数据,全部查找出来!
命令格式: select * from 表名;
在MySQL中,* 就叫做 “通配符”,表示一个数据表中的所有列。
【博主只记得:在Java的泛型的语法中涉及通配符的概念。符号 为 ?】
可以这么理解, * 就相当于万能wlan钥匙,什么 wlan 都能连。
只不过 * 匹配的是 列/字段。
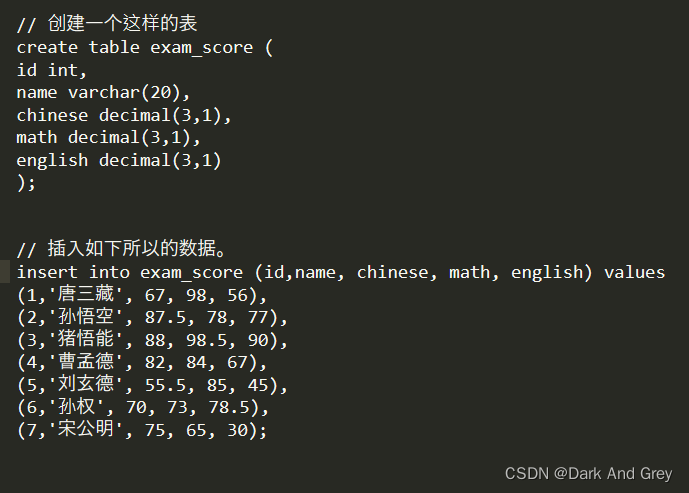
为了方便后面的功能演示,请大家创建如下面所示的数据表,并将输入插入到该数据表。
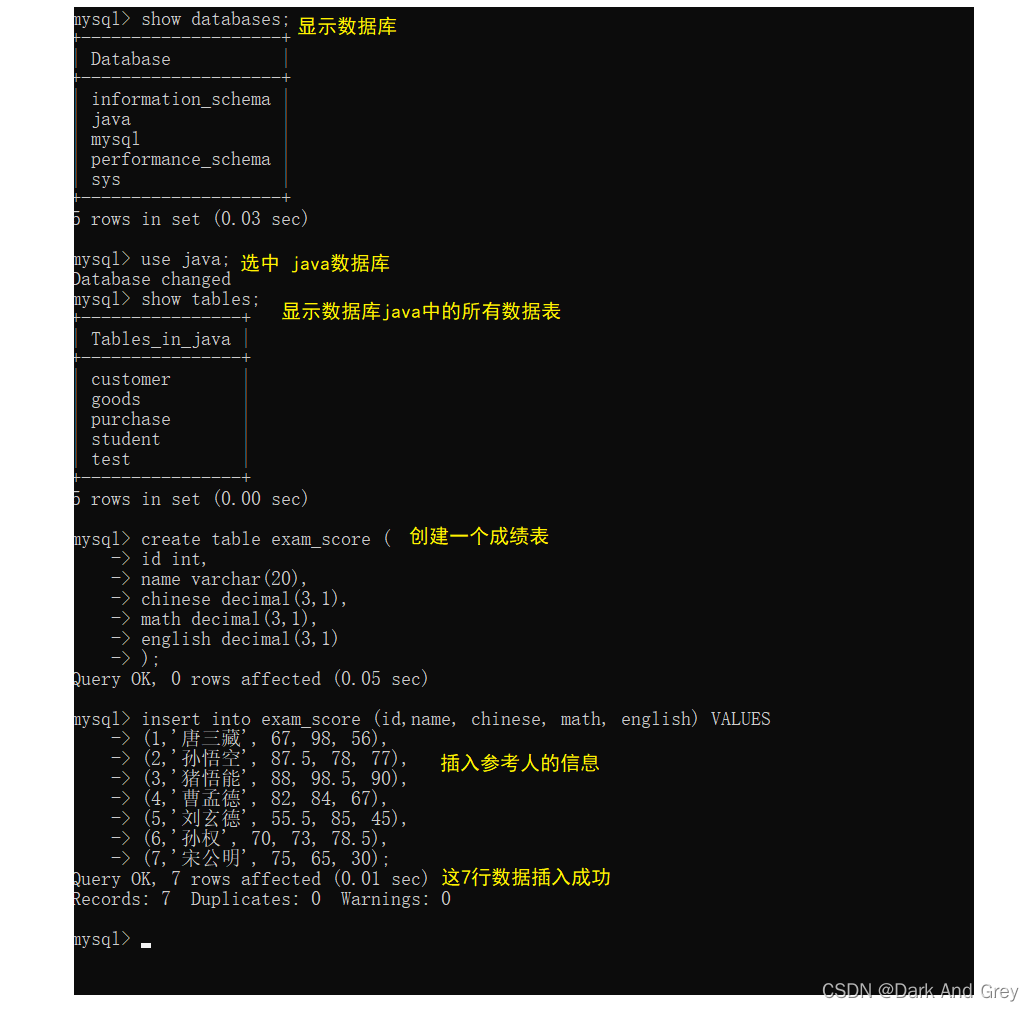
效果图
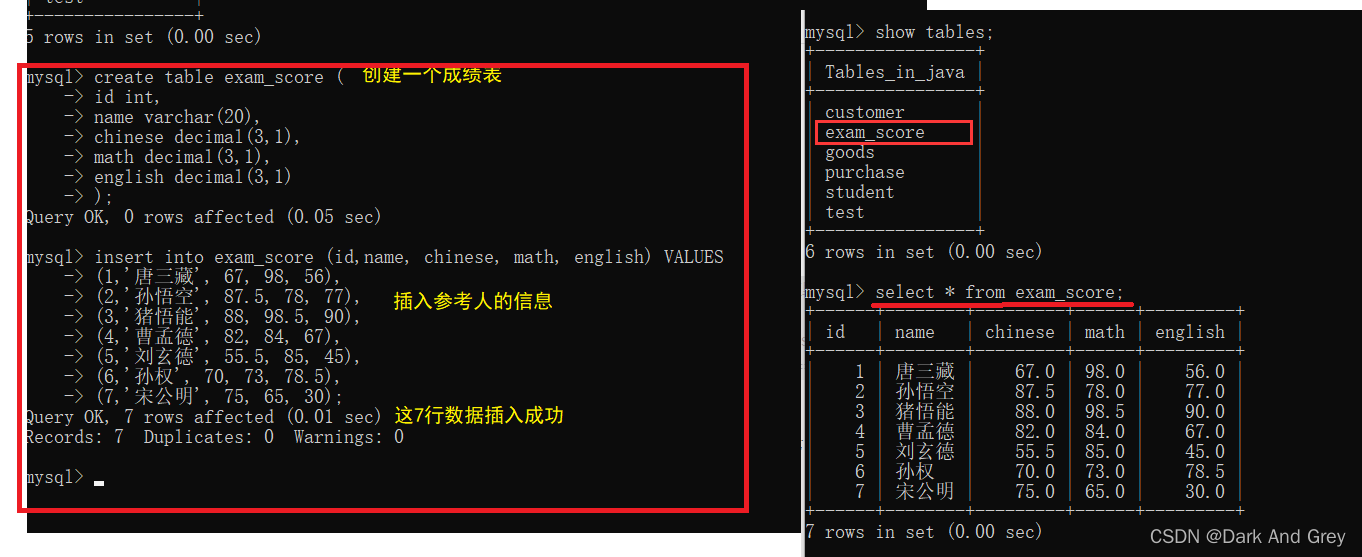
通过 select 关键字 的 全列查找灵敏,把一个表中所有的行与列的数据全部找到。
查找的结果以一个表的形式呈现出来,注意!这个表是一个 “临时表”。
为什么说这个打印出来表 是 临时表呢?
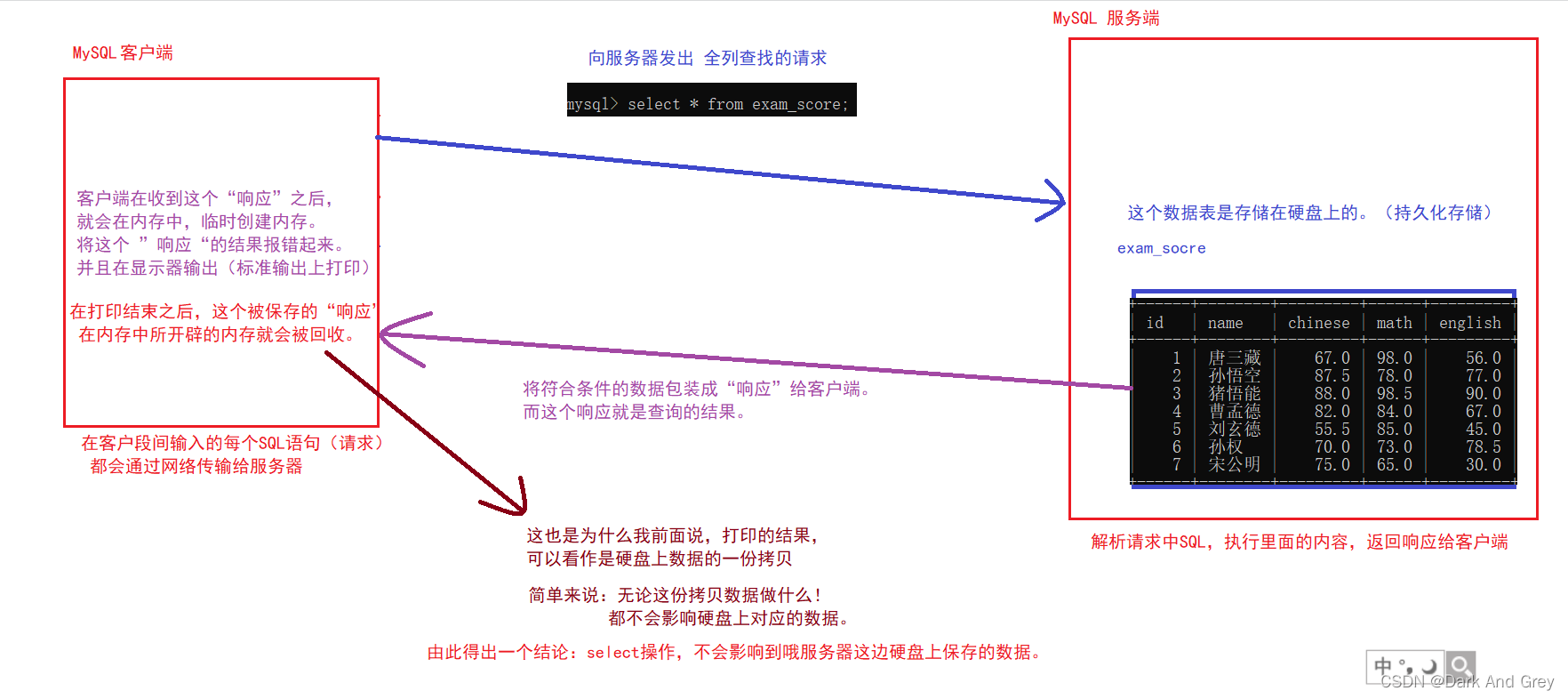
这是因为我们都知道数据库的 表 都是存储在硬盘上的。
原理是当服务器接收到客户端的“请求”之后,进行查找数据,将找到的数据整合发送给 客户端(数据还在硬盘没有改变,你可以理解为客户端拷贝了这一份“响应”),客户端再将“响应接收“”,解析,显示(这时候数据是在内存上操作的)。当显示以后,内存中存储这些数据的空间也就被释放了。
注意!在操作的过程中,硬盘上的并没有发生变化。因为客户端此时操作数据只是一份拷贝数据,属于一次消耗品。
拓展 : select * from 表名; 这个操作其实是一个危险操作!
为什么说 select * from 表名; 是一个危险操作?
理由很简单,我们 上篇博客讲了 “环境”的配置。你可以想象一下:如果是生产环境中的数据,少说也有几个T吧,你这条SQL通过网络发送 服务器,服务器接收到请求就会开始操作起来。
由于数据量庞大,服务器疯狂读取硬盘的数据,而一个机械硬盘的读取速度也就是几百兆左右,也就是说会把硬盘的IO 瞬间吃满,同时MySQL服务器又会立即返回找到数据作为响应给客户端。
【注意MySQL服务器 是找到符合条件的数据,就将其返回。不是说全部找到后,打包给客户端。】
因为 客户端 与 服务器是通过网络来交互的,再结合上面所述:服务器返回数据量也是非常大的。
这就会造成另外一个结果:把你的网速吃干净。专业术语来说:把网卡的带宽吃满。
【网卡的访问速度跟机械硬盘差不多。好的网卡 上 万兆的都有,比如王思聪家的电脑。但是呢,数据量还是很大的】
简单来说:对生存环境的数据,进行select * from 表名; 这个操作,我们的硬盘和 网卡都会被瞬间吃满,导致服务器卡死(繁忙),此时如果有客户想提出的任何“请求”,或者只是想链接服务器,服务器都没有那个时间去处理。
这就跟 LOL 战斗之夜的一区艾欧里亚 登录排队是一个效果。每一个人的账号数据都存储在服务器中。登进去肯定是要访问自己的账号信息的,但是呢,登录的人是在太多,服务器需要处理很多的数据,此时别说玩,你连登录都是一个问题。
得出结论:一旦 服务器的硬盘和网络被吃满,此时我们的数据库服务器就难以对其它客户端的请求作出响应。
而生产环境的服务器,无时不刻要向 普通用户提供响应。这就导致客户进不去,或者说网络不响应,再者就是响应时间太长等问题。
简称: 数据库累成“狗”。
为了预防这种情况的发生。
在实际开发中,一般公司都会对 SQL 的执行时间做出监控
一旦发现出现了这种长时间执行的 ‘慢SQL’,就会强制终止这个SQL 语句的运行,并删除它。
总之:在以后工作的时候,用之前先掂量掂量,以免对公司实施毁灭性打击。同时也是对你自己的毁灭性打击。
2、指定列查询 : 只查询自己想要的那一列数据
命令格式:select 列名,列名… from 表名;
查询的时候,显式的告诉数据库要查的是那些列。
数据库就会针对性的进行返回数据。(返回的结果,还是一个 “临时表”)
简单再说明一下临时表: 在客户端内存上临时保存一个数据表,随着打印的进行,内存就会被释放。
临时表的结果对于数据库服务器中的原始数据没有任何影响。
不要看了下面的结果,就认为改动了原始的数据。
相比于前面的全列查找,这种指定列查询就要高效很多,
后面在工作中接触数据库中,一个表至少有十几列都是很正常的,这种 指定列查询 不仅效率高,涉及到数据传输量不是很大。
因此,,这种 指定列查询 操作,在以后的开发中是会经常用到的。

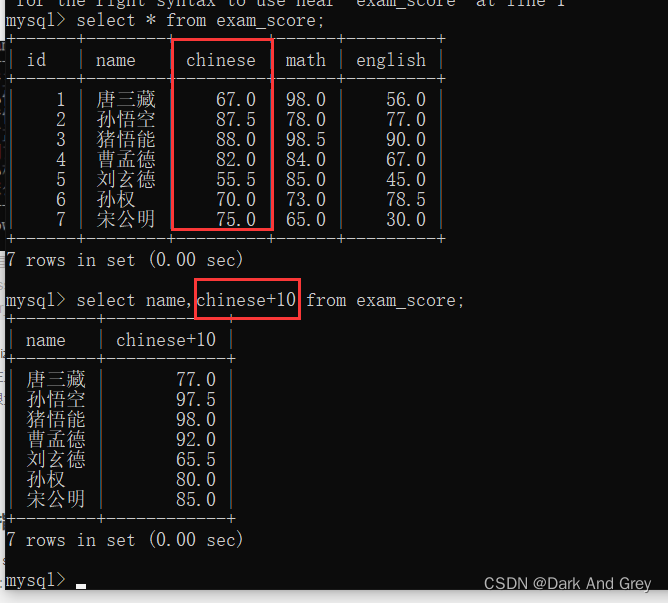
3、指定查询字段为表达式
在查询的时候,同时进行一些运算操作(列与列之间)
例如:考试结束之后,我们预估语文成绩 比实际成绩高10分。
命令格式:select 列名表达式,列名表达式… from 表名
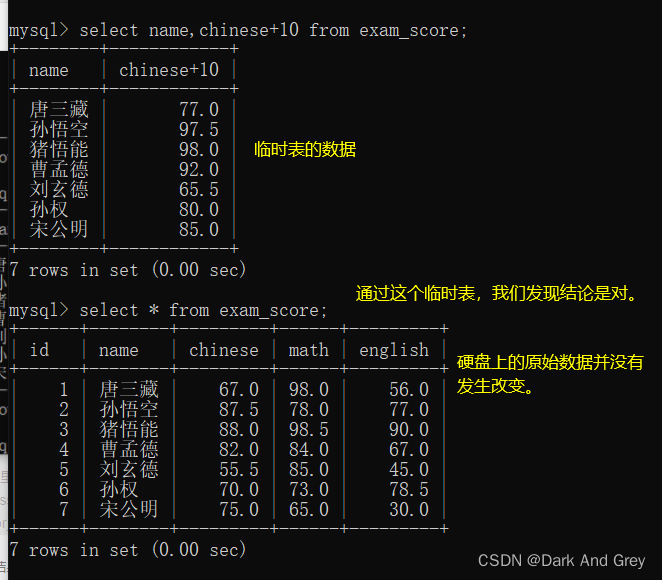
这个结果还是一个临时表,意思就是 硬盘上原始数据并没有改变。改变只是临时表中的数据。
再次强调: select关键字的操作,不会影响到硬盘上的原始数据。
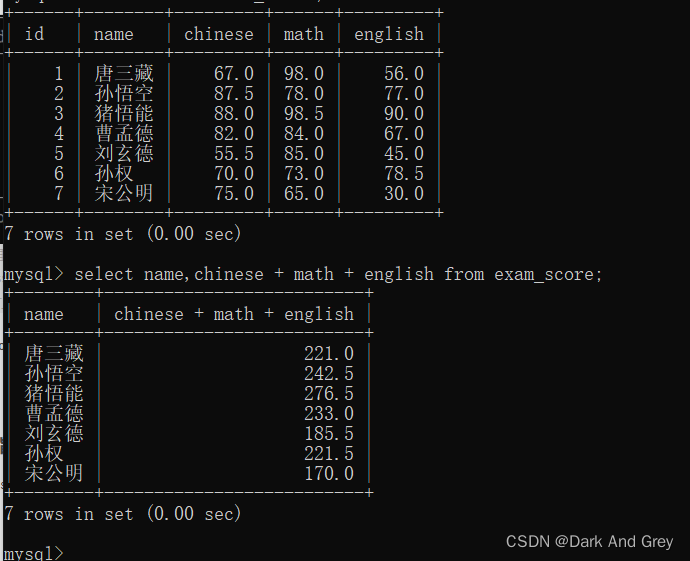
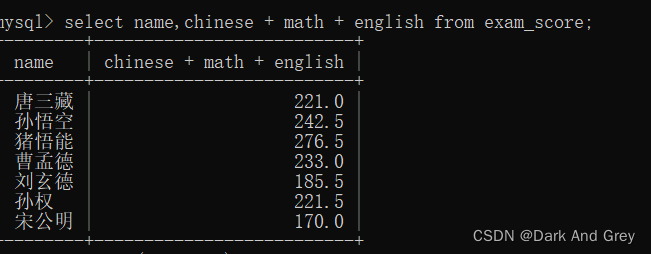
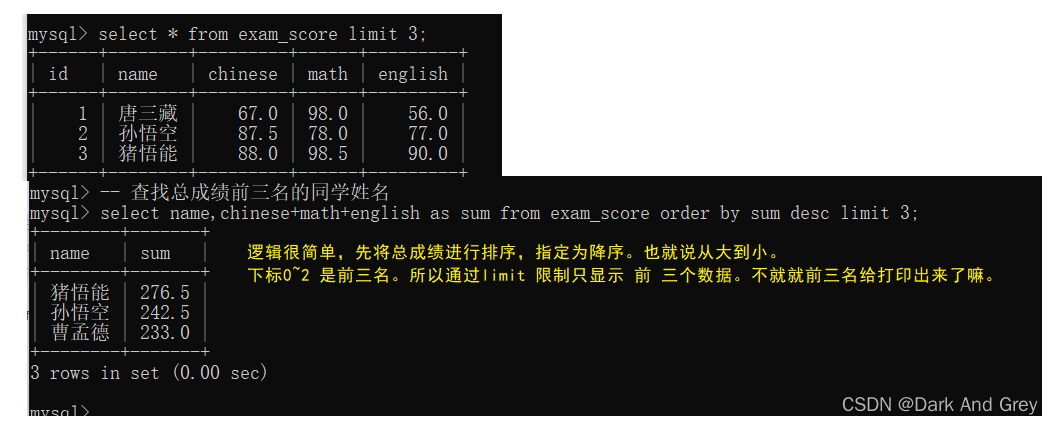
现在我们再练习一个例子,要求这些 “同学“的总成绩
但是,这里面还存在一些细节问题。来看下面
上述操作,都是针对 一列或者多列来进行的运算操作。
也就是针对指定的列中每一行的数据都进行相同的运算。
代入例子中:指定 语数外 三列的成绩相加,也就是将 每一行“同学”的 三列成绩相加。
行与行之间,数据互不影响。【你算你的,我算我的】
另外, 指定查询字段为表达式 的 运算方式,各种算术运算方式都是可以。
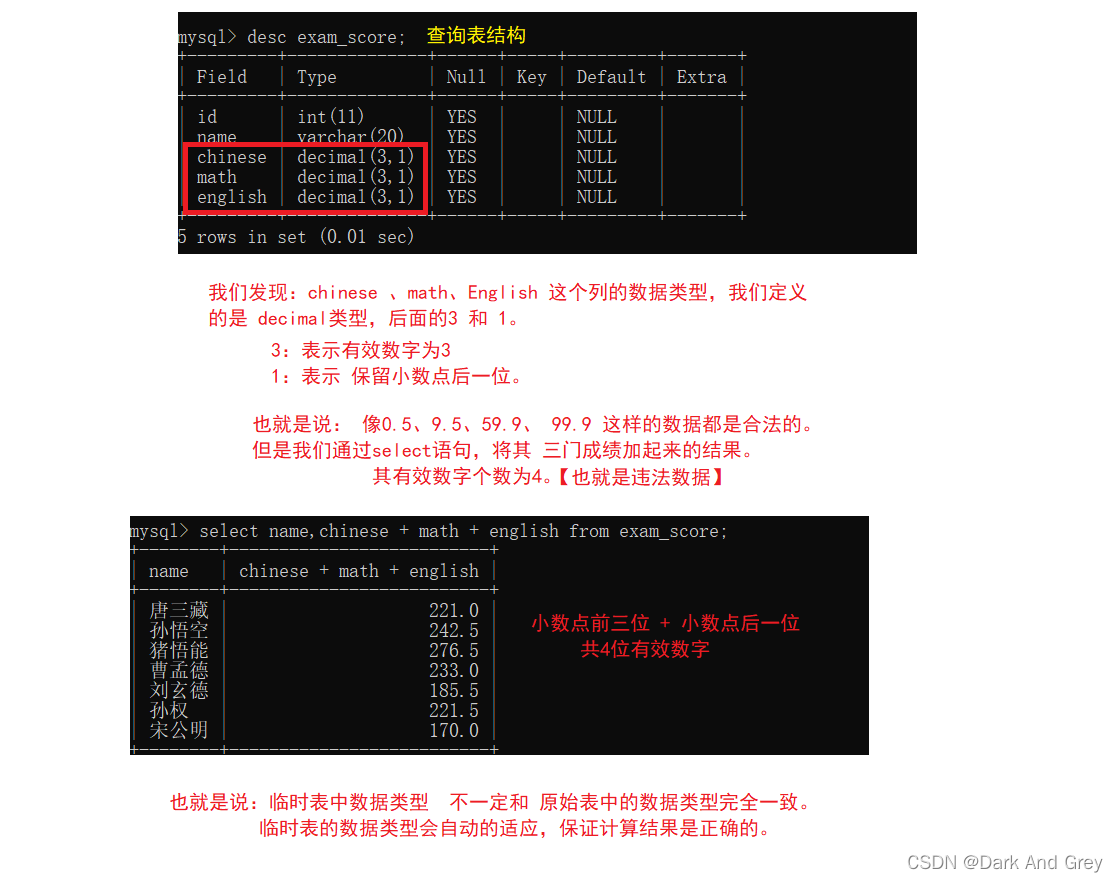
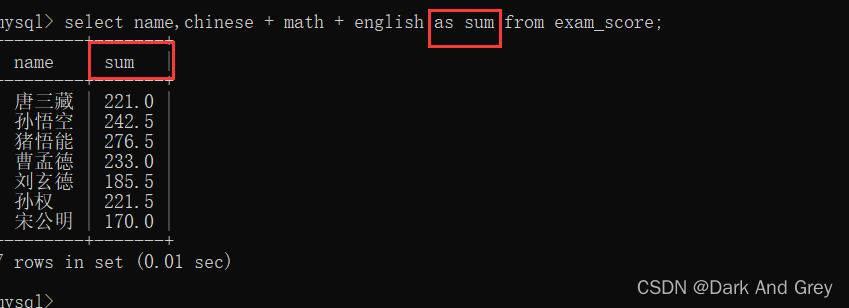
4、别名(关键字 as):指定查询字段为表达式,给表达式取个名字
前面计算总分的时候, 打印出的临时表,总分的表头名很长。
于是乎,我们就想:能不能给这个表达式换个名字,让打印出临时表看起来更舒服一些~
故,便有了别名(关键字为 as)。
它的语法格式:select 字段表达式 as 新名字 from表名;
另外,注意一点: as 是可省略的(表达式 与 别名 之间用空格隔开)。打印效果是一样的,但是代码的阅读性不高。
【ps:不要搞事情,说不写就不写。一个优秀程序员,不是说他的代码不是写得多好,多精简!而是看他代码的可读性高不高!!!!】
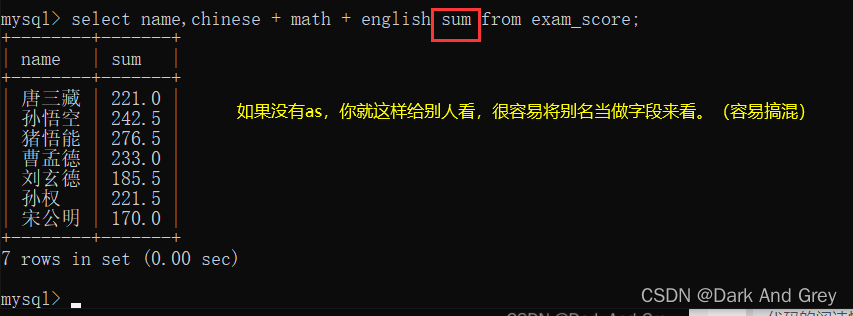
5、针对查重结果 去重 - 关键字 distinct
j针对查询的结果,把重复的记录去掉。【相同的数据,只能存在一个】
语法格式:select distinct 指定的列名 from 表名;
注意!如果是针对多个列来进行去重(上面是对单列进行去重),去重的条件:多个列的值都相同的时候,才视为重复。
你可以这么理解:多列去重的时候,执行去重操作的话。每个列直接就剩一个元素。
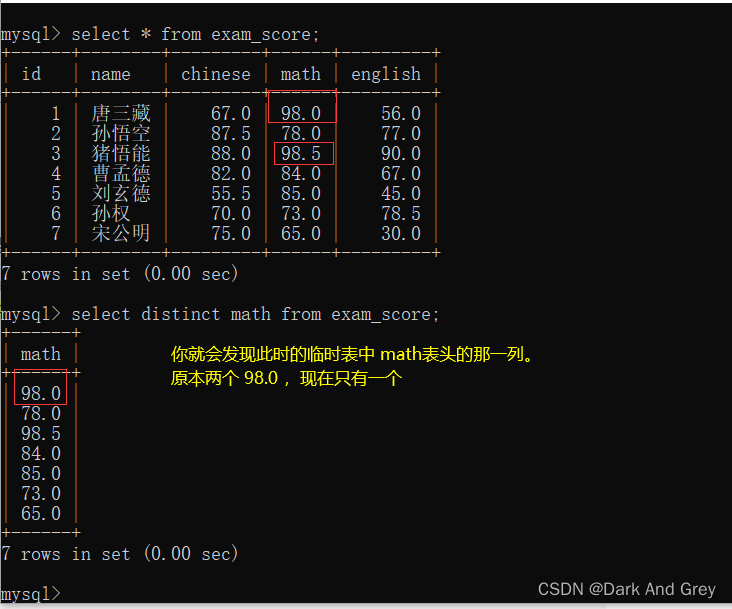

6、排序 :关键字(order by)
这里的排序针对于 查询的结果(临时表)进行排序。【不会影响到数据库服务器上的原始数据。说白了就是不会影响硬盘上的原始数据】
命令格式:select 列名… from 表名 order by 列名 asc(升序) / desc(降序);
意思就是:select选择的列,根据 order by 后面指定列,它的排序方式(sac/desc),进行排序移动。
其结果:就是 order by 后面指定列有序,其他列的数据不一定。
也就是说: order by 这种排序,只能保证至少一列有序。
但是!像数据库查询的结果,如果不去指定排序,此时查询结果的顺序是不可预期的。
【对应的情况是:指定的列中的 列值全部为相同的时候,无法确定谁在上,谁在下】
简单来说就是不要太过于依赖默认的顺序。

细节拓展
当指定排序的列中,含有NULL
有的数据库记录中是带有NULL值得,像这样的 NULL 认为是最小的(升序在最上面,降序在最下面)
【小拓展: NULL 和其他值进行运算,其结果还是 NULL,NULL 可以看作最小值,但和零没关系】
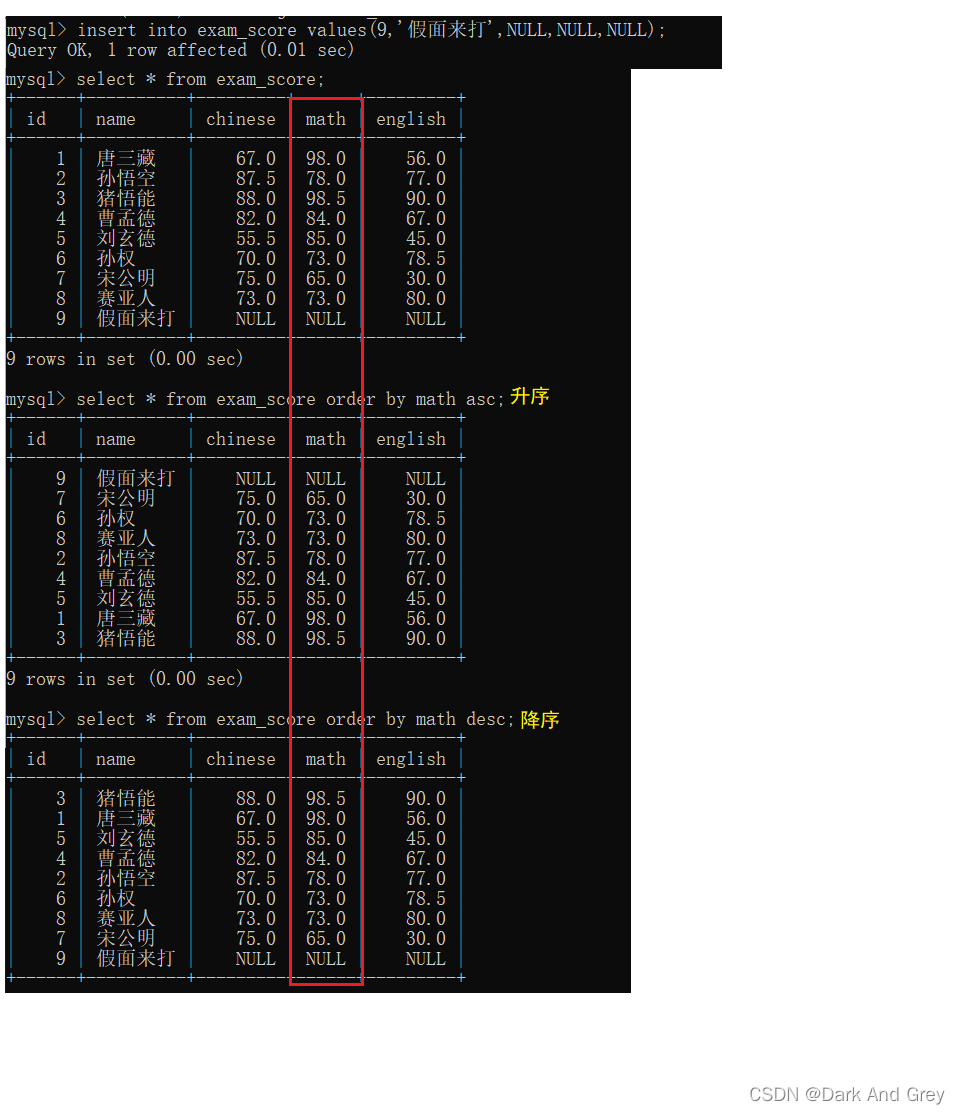
排序也可以依靠表达式或者别名来进行排序
下面我们就以总成绩来进行排序(下面演示升序,降序就没必要了,就把 asc 改成 desc就行了)
排序也可以字符串类型数据库
在创建数据库:可以指定数据字符集的校验规则【命令:collate 校验规则;】
校验规则:描述字符之间的比较关系。
比如 英文之间的比较,忽略大小写,那么这个时候就不是按照字典序进行排序的。
而且字典序只是针对英文,如果你拿个中文,就没有什么作用。
而且 字符集有很多种,并不一定就是字典序。
所以说 字符串类型的数据,排是可以排序的,但不一定是字典序。
话说回来:用字符串去排序还是很少的。主要还是用数字去排序
所以,这里只要了解就行了,就不做过多的讲解。
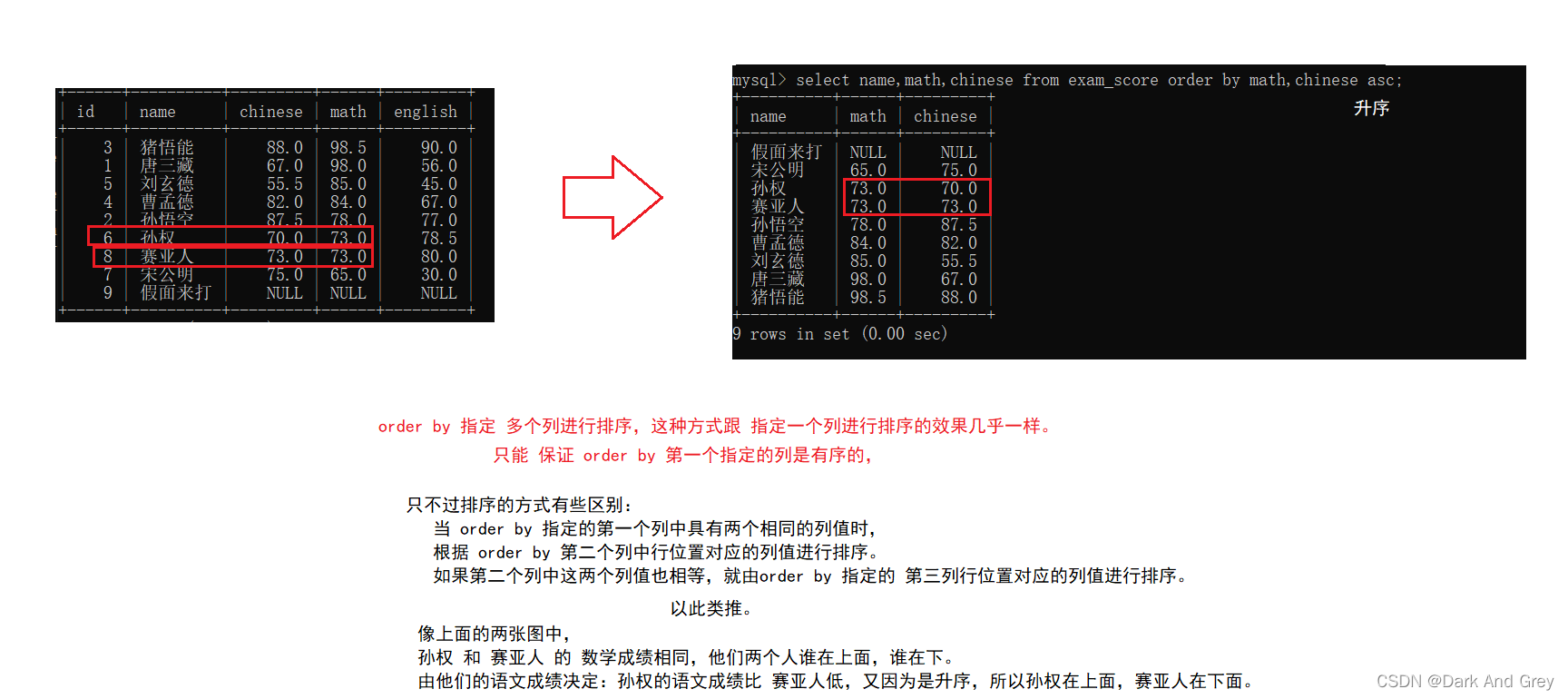
order by 可以 指定 多个列进行排序
先根据第一个列进行排序,如果第一个列结果相同,相同结果之间再通过第二个排序,以此类推
命令格式:select 列名,列名… from 表名 order by 列名,列名;
指定多个列的目的:就是为了避免指定一个列时,如果这个列中所有的列值都是相同的,那么彼此之间的顺序是无法确定的。
如果指定了多个列的时候,还可以根据其它列的数值进行排序。从而就能预期到彼此之间的顺序。
知识铺垫 - 为select 的 第七种操作铺垫
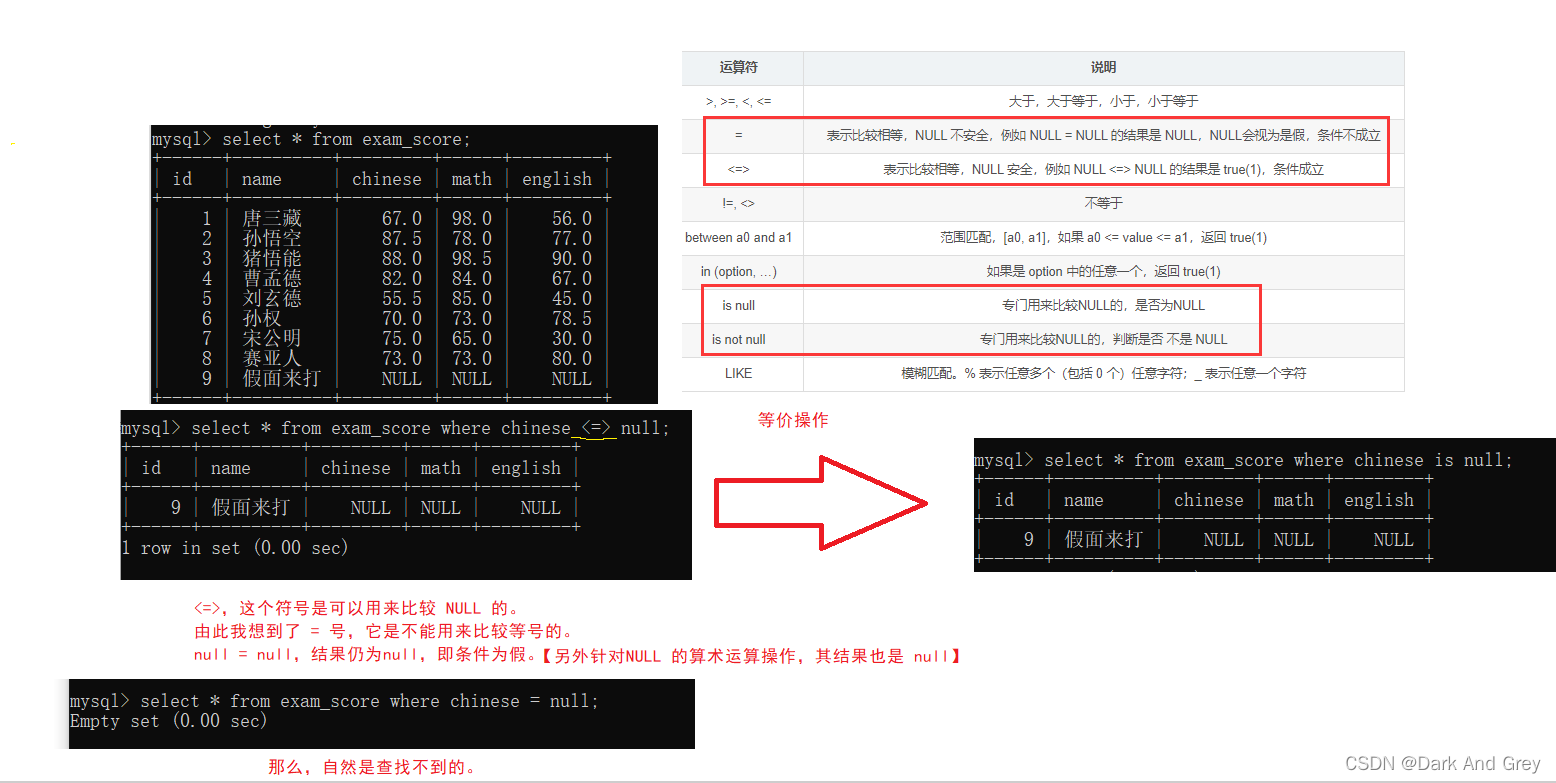
比较运算符
| 运算符 | 说明 |
|---|---|
| >, >=, <, <= | 大于,大于等于,小于,小于等于 |
| = | 表示比较相等,NULL 不安全,例如 NULL = NULL 的结果是 NULL,NULL会视为是假,条件不成立 |
| <=> | 表示比较相等,NULL 安全,例如 NULL <=> NULL 的结果是 true(1),条件成立 |
| !=, <> | 不等于 |
| between a0 and a1 | 范围匹配,[a0, a1],如果 a0 <= value <= a1,返回 true(1) |
| in (option, …) | 如果是 option 中的任意一个,返回 true(1) |
| is null | 专门用来比较NULL的,是否为NULL |
| is not null | 专门用来比较NULL的,判断是否 不是 NULL |
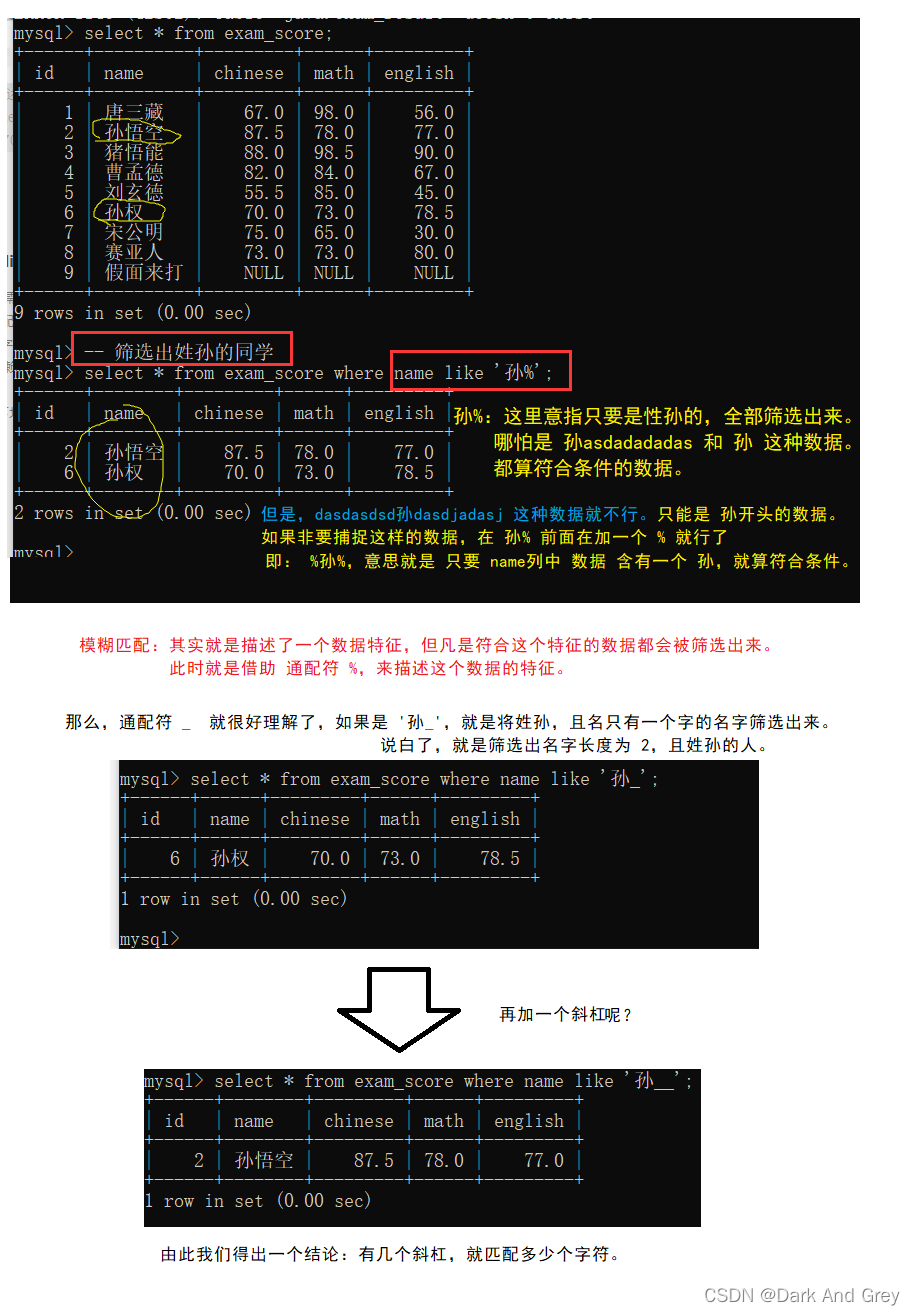
| LIKE | 模糊匹配。% 表示任意多个(包括 0 个)任意字符;_ 表示任意一个字符 |
逻辑运算符
| 运算符 | 说明 |
|---|---|
| and (逻辑与 &&) | 多个条件必须都为 TRUE(1),结果才是 TRUE(1) |
| or (逻辑或 双竖线) | 任意一个条件为 TRUE(1), 结果为 TRUE(1) |
| not(逻辑非 !) | 条件为 TRUE(1),结果为 FALSE(0) |
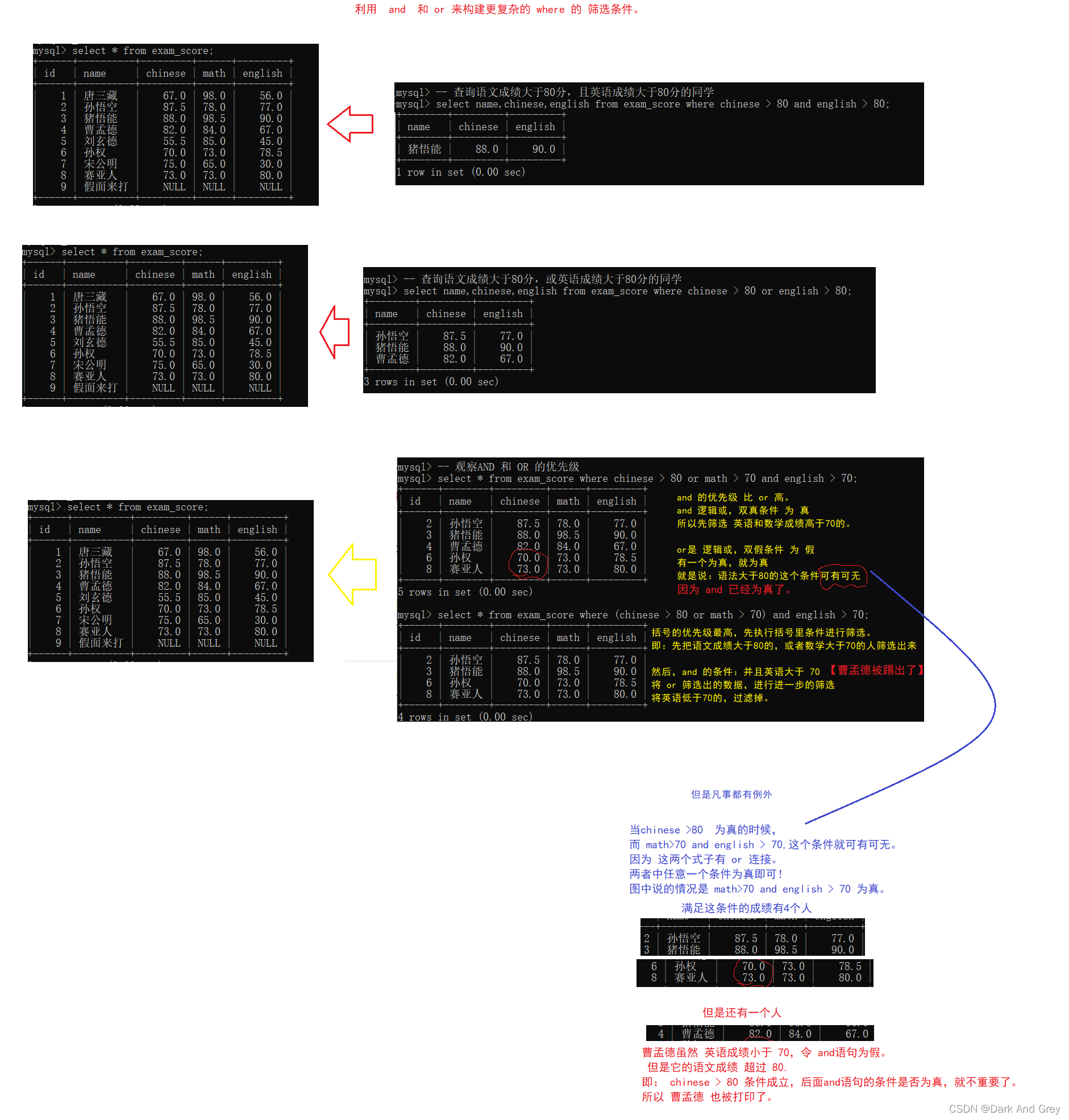
注意:
1、where条件可以使用表达式,但不能使用别名。
2、 and的优先级高于or,在同时使用时,需要使用小括号()包裹优先执行的部分
7、select 中的 条件查询:关键字 where
在 select 查询语句的后面加上一个 where 语句,后面跟上一个具体的筛选条件。
命令格式:select 列名,列名… from 表名 where 筛选条件;
作用:把查询结果中满足筛选条件的记录保留,把不满足筛选条件的记录给过滤掉。
基本查询

and与or
范围查询 : between and + in
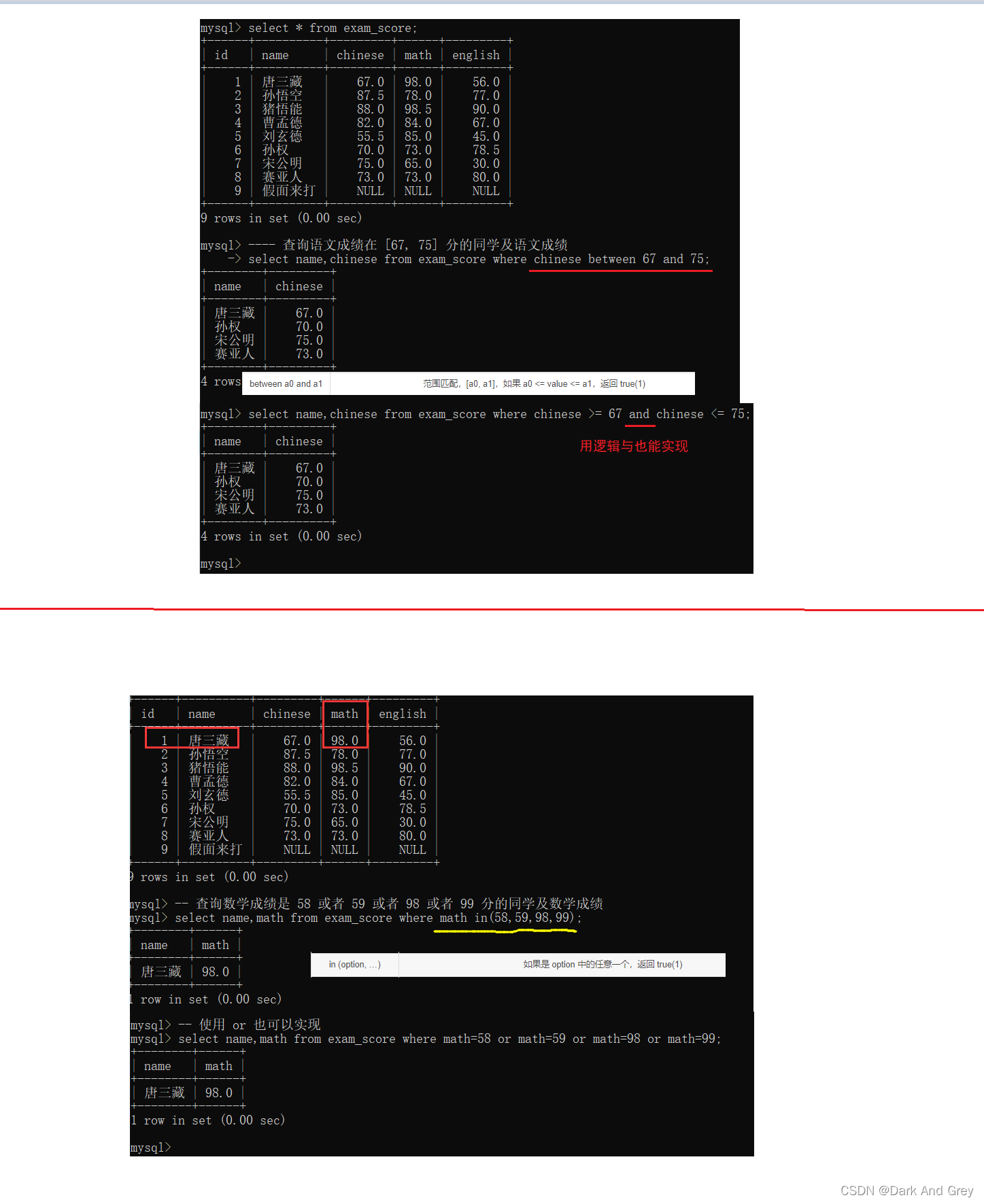
小拓展:MySQL的 between a0 and a1 算是不常见的 闭区间 语法。其他大部分语言都是 左闭右开的区间,比如java的 substring,还有在java的底层代码中,只要见到 form to 这样的字样,就是 左闭右开的区间。

模糊查询:like
like,需要搭配通配符来使用:只需要对方的字符串符合你此处描述的一个形式就ok
这里like使用的通配符有两种 : % 和 _
%: 代表 任意个字符【任意个:大小不做限制,可以是很大或者很小的数。包括0】,且每个字符又可以表示为任意字符(就是打牌中赖子一样,可以将它当做任意一张牌)。
_ :下划线它只能代表一个字符,但是这一个字符是“赖子”,即:可以表示任意字符。
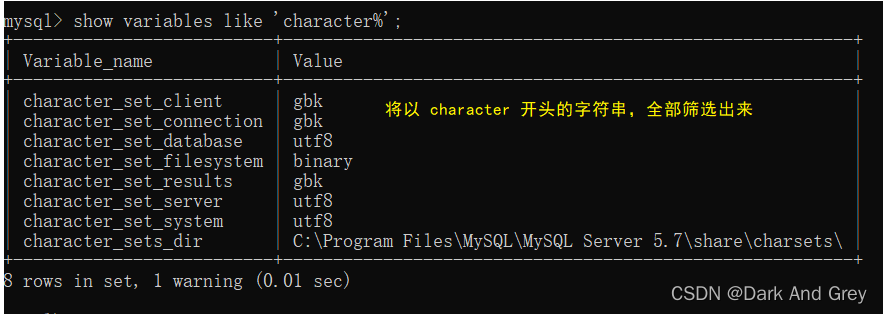
还记得查看字符集的指令吗?
命令格式 :show variables like ‘character%’;
这里其实就是使用了通配符。
如果抛开 SQL,站在更广的角度来看待 通配符体系。编程中还有一个东西叫做“正则表达式”,提供l更多的特殊符号来描述一个字符串的规则/特征。【别问我,我不会。】
查询语句中,和NULL 进行比较
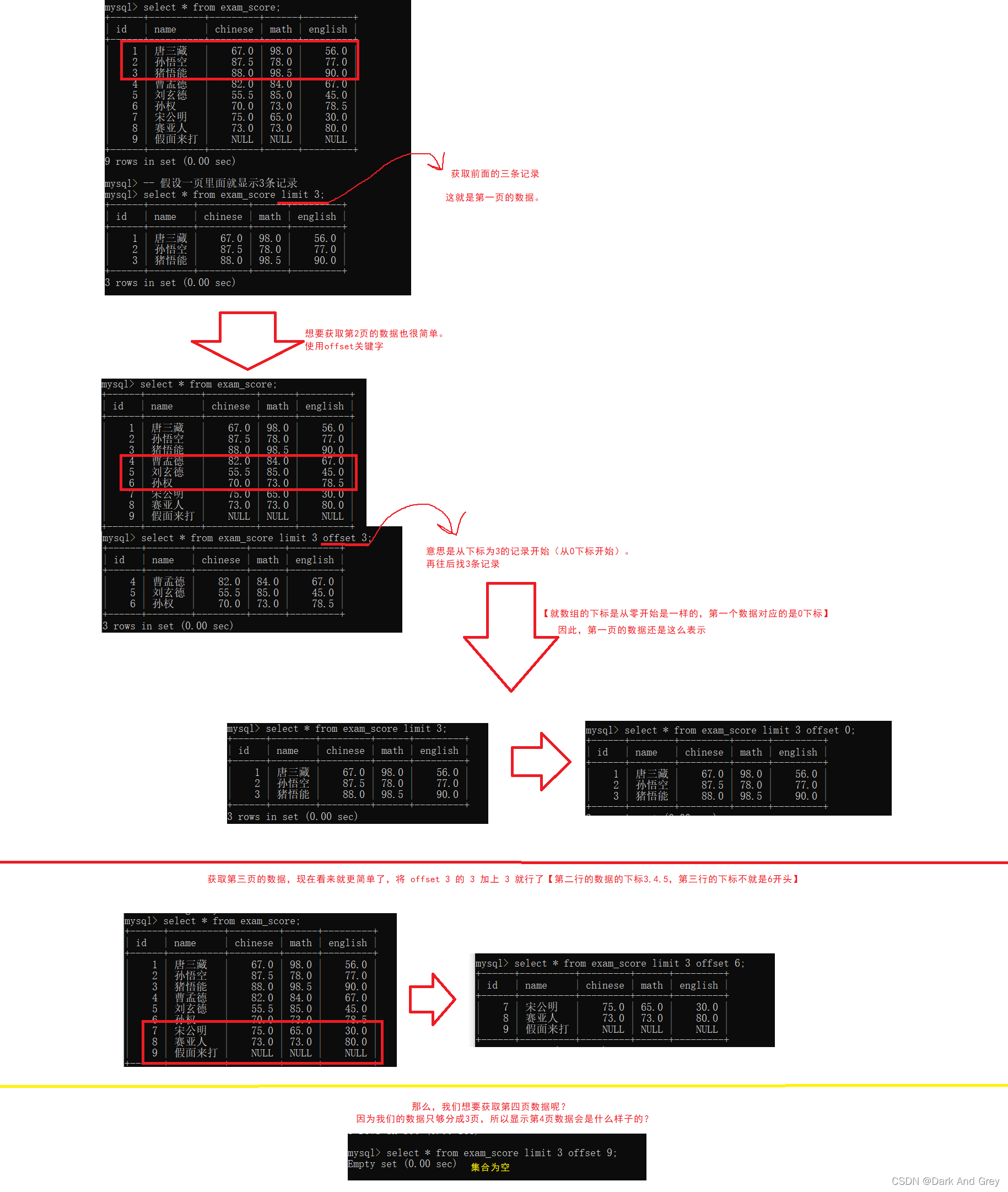
8、分页查询:关键字 limit
分页查询,其实在我们的生活中很常见,比如我们浏览器 搜索资料,它的搜索结果会有很多。
网页呢,会帮我们进行分页。让我们一页一页去翻。这里其实就是运用分页查询。
至于为什么要使用分页查找,是因为如果我们一股脑将数据去不放入一张网页中,由于数据量很大,传输很慢,页面加载速度降低,网速也会被吃很多。
分页查询:就是为了避免这种情况,将数据分割N页,一页中最多显示 k 个结果。
在进行查找的时候,就按照一页的数据量进行返回。
【比如说:一页显示20条记录,第1页:1~20、第二页21 ~40。。。。。。】
这样就提升了网页的加载速度 和 数据量的传输量。
在sql 中可以通过limit来实现分页查询,
limit 同样可以搭配条件,以及 order by 等操作来组合使用。
limit还有一个非常重要的作用。
前面说到 select * from 表名; 这个操作对生产环境的数据库很危险!
但是,有的人呢可能就会疑惑:难道那些指定列 和 列的表达式,还有 排序、条件等操作就不危险了吗?
危不危险 是根据操作指令返回的数据量来决定的。
如果返回的数据量很大,那么这个操作就是危险的,反之,则是安全的操作。
其实我们学习这么的操作指令,就是为避免危险操作。
1、select 指定需要的列数据,缩小数据范围。
2、然后,用严格的限制条件(where)来缩小数据量。,
3、再搭配使用limit,进一步限制数据量,实现更稳妥的操作。
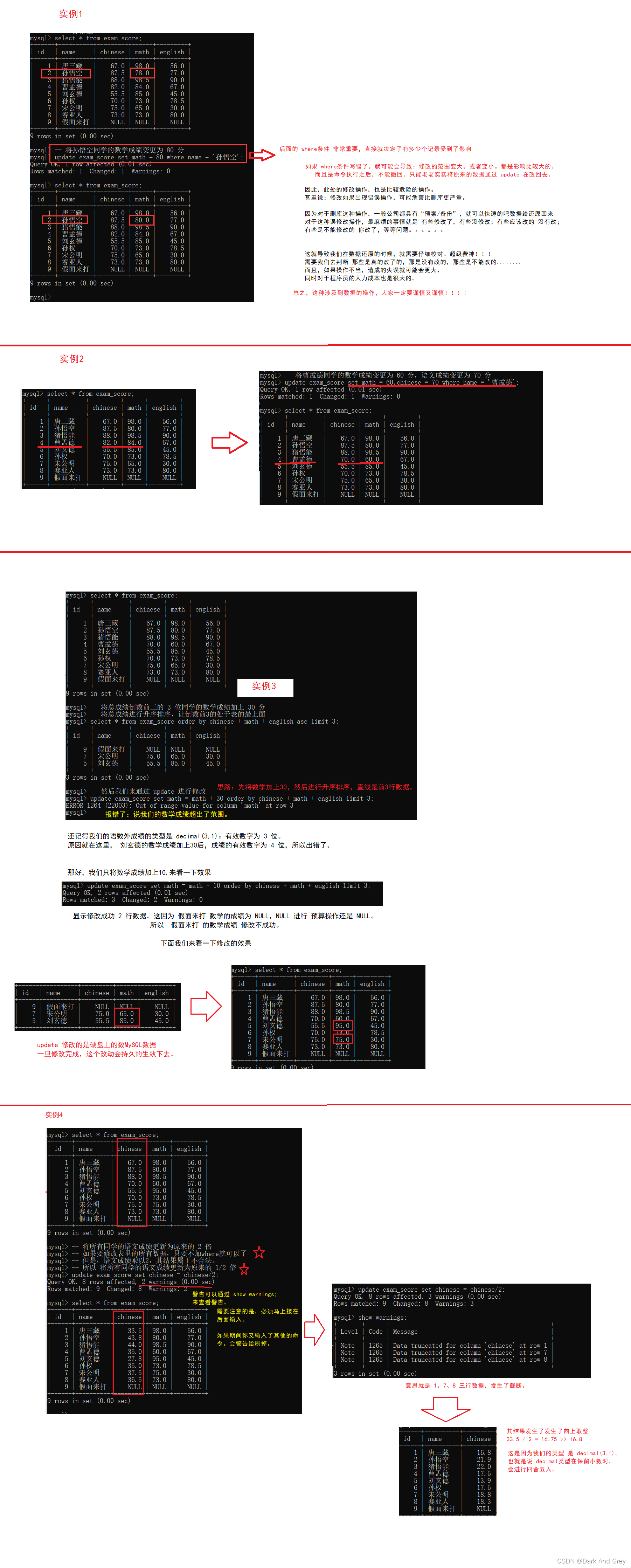
修改:关键字 update
命令格式 update 表名 set 列名 = 值,列名 = 值,列名 = 值… where 条件;
where 条件:起着筛选数据的作用,简单来说:我们更新数据,很少会是整体数据全更新,只是更新部分内容。
where 就是用来处理这种情况,来筛选需要更改的数据。
where 条件; 主要是针对那些行进行修改,符合条件的行就会修改,反之,则不会。
不过放心,这里 where 的条件 和 前面的 select 的 where 条件 是一样的。
意思就是说:前面讲的那些 操作 都能用在 update语句 上。
唯一需要注意的是:updata 是会修改数据库服务器上的原始数据的!!!!!
update是不会像 select 那样,做个样子的。它是实打实的修改了原始数据。
修改语句,也是咱们日常开发 常用的 一个 sql,大家一定要掌握它。
删除(Delete)
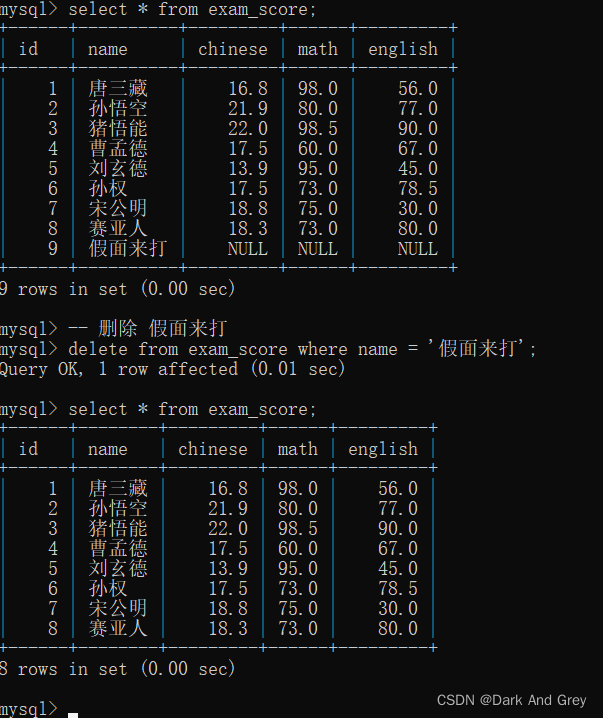
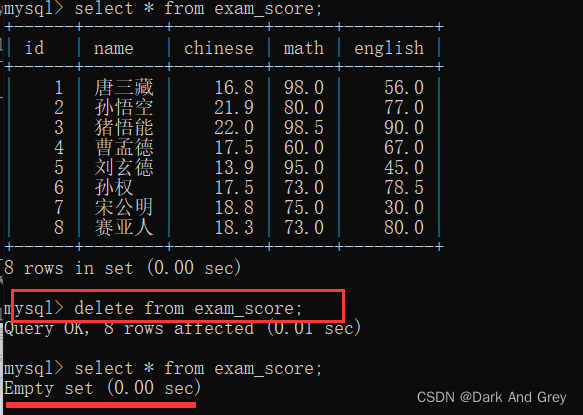
语法格式: delete from 表名 where 条件;
删除操作海慧寺很危险的,一旦这里的条件写错了,可能影响范围就会很大,如果不写条件,就会把整个表的数据都删除掉了。(也就说: delete语句,不加where条件限制,就会把数据表中的数据清空)
而 drop table 表名; 是将整个表都删除了。