宝子们,你们要的面试题续集终于来啦~
为了提升阅读体验,这次的面试题会分成若干小章节,每章只装十道题
开始吧!!

1、java有哪些类加载器?
-
启动类(Bootstrap)加载器 BootClassPathHolder: 加载<JAVA_HOME>/lib下的jar包
-
扩展类(Extension)加载器ExtClassLoader:加载<JAVA_HOME>/lib/ext下的jar包
-
系统类(System)加载器AppClassLoader:加载我们自己项目中写的java文件编译而成的class文件,位于target/classes下
2、int和Integer有什么区别?
Integer是int的包装类,int则是java的一种基本数据类型,Integer的默认值是null,int的默认值是0;
JavaBean中我们应尽量使用Integer,打个比方,学生成绩如果用int,缺考怎么表示,0?那考0分的呢;-1?也可以,但没有null直观;
3、你在项目中如何保证缓存和数据库的一致性?
记住一句话,只要有引入缓存的地方,都不可能保证强一致性,所以这里的一致性是指最终一致性
方法很多,最常用的就是延时双删,先删除缓存,再操作数据库,完事儿再删除一次缓存
第二次删除缓存是为了避免 在第一次删除缓存之后,到操作数据库完成之前,这期间有新的查询过来,导致再次把旧数据生成缓存
4、如果你发现某个接口响应很慢,该怎么排查?
导致接口响应慢的原因太多了:网络、应用层、数据库事务、服务器自身、慢sql等
逐个来说
- 网络:对于单个请求来讲,网络因素影响其实很小,除非网络挂了导致请求超时才能意识到;而对于大批量请求,每个请求慢10ms,请求多了,时间也就长了,这种情况可以检查下你的应用部署机和数据库机地理位置是不是隔得很远,比如一个在华东一个在西南,地理距离也会对请求响应时间产生影响,请求量越大越明显;
- 应用层:就是我们敲的controller、service那些代码,这一层出问题很好解决,因为代码毕竟都是我们敲的嘛,一看日志就大概知道什么原因,最多的就是出现死循环(当然一旦出现死循环也不只是响应慢那么简单了);代码逻辑写的差点其实不会太影响性能,现在的cpu执行效率你尽管放心,再怎么优化也顶不了少一次io;
- 数据库事务:检查下你的数据库是不是卡事务了,导致锁了很多表;
- 服务器自身:服务器是不是卡了,cpu是不是炸了,内存是不是满了;
- 慢sql:这一层出问题的几率很大,同一组查询结果,由于sql不同,耗时能相差几百上千倍,可以通过查看sql执行计划来排查问题,详见 mysql执行计划解析
5、调用ReentrantLock的lock方法后,如果当前线程没有获取到锁,它会怎么办?
不管是公平锁与否,都会进入clh队列,但是注意,线程不会在获取锁失败后立马入队,在真正入队之前会多次尝试再次获取锁,尝试次数跟是否公平锁有关:
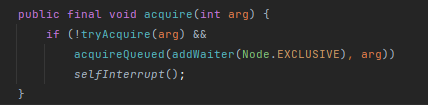
公平锁:
先tryAcquire尝试获取锁,如果失败,执行acquireQueued,acquireQueued内部会再次执行tryAcquire尝试获取锁,如果再失败,就入队;
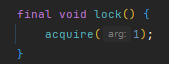
非公平锁:
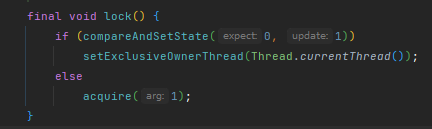
先cas尝试获取锁,如果失败,执行tryAcquire再次尝试获取锁,如果还失败,执行acquireQueued,acquireQueued内部会再次执行tryAcquire尝试获取锁,如果再失败,入队;
6、判断一块内存空间是否会被垃圾回收器回收的标准有哪些?
- 对象的引用被赋值为null,并且后面不再调用
- 对象的引用被重新分配了内存空间
- 对象的引用被赋予了新值
7、redis的持久化机制
所谓持久化机制就是保证 redis 挂掉再重启后,可以恢复数据
快照(默认)
默认开启,无需设置,有个参数 save m n,这表示m秒内进行了n次写操作就进行备份,而且可以设置多组,满足不同场景;这里备份有两种,一个是save(阻塞),一个是bgsave(异步),还有一种是自动化,redis的快照是采用bgsave;
AOF(AppendOnlyFile:只追加文件)
需手动开启,在redis.conf中开启appendonly,默认是no,改为yes,生成的日志文件名默认为appendonly.aof,可以修改,然后配置appendfsync,有三个选项,always、everysec和no:
默认是everysec,表示每秒同步一次,性能和数据可靠性都能兼顾,最坏情况会丢失不到2秒的数据;
no表示平时不进行同步,只会在redis关闭或者aof被关闭时同步,性能最佳,但是丢数据风险高;
always表示每次写操作都会同步,性能差,但是丢数据风险低;
8、Java变量的本质是什么?
String str = new String("123");
我们常说的变量,也就是上面这个str,其实就是个内存地址,真正的String对象在堆上
9、ConcurrentHashMap在jdk1.8相对于之前版本有什么区别?
1.7
基于Segment数组和HashEntry,Segment继承自ReentrantLock,懂了吧,它自然就有了锁的基本功能;每个Segment数组中都有多个HashEntry,我们的数据都存在HashEntry里面,每次需要修改数据时,先对HashEntry所在的Segment加锁,其它Segment不受影响,分段锁就是这么来的;
1.8
整体实现很像HashMap,在它基础上引入了synchronized,和大量的CAS操作,以及大量的volatile关键字,所以1.8中ConcurrentHashMap的优势在于锁的粒度更小;
10、mysql支持哪些索引结构?
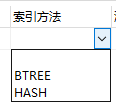
这是从navicat中截的图,有眼睛的小伙伴可以看到mysql支持B+树和hash
但是!!!
其实我们只能建BTREE索引,hash索引是不能人为创建的,mysql官方文档中有提到

InnoDB utilizes hash indexes internally for its Adaptive Hash Index feature
贴心翻译:InnoDB内部利用哈希索引实现其自适应哈希索引功能
只有mysql认为应该建hash索引的时候才会建,不信的话你建个hash索引保存,会发现变成了BTREE
再来个冷知识,hash索引全称:innodb_adaptive_hash_index,翻译成人话就是 innodb自适应hash索引,懂了吧
如文中有错,请及时指出~
ok我话说完