首先,很幸运的是,Scikit-learn中提供了一个函数可以帮助我们更好地进行调参:
sklearn.model_selection.GridSearchCV
常用参数解读:
- estimator:所使用的分类器,如果比赛中使用的是XGBoost的话,就是生成的model。比如: model = xgb.XGBRegressor(**other_params)
- param_grid:值为字典或者列表,即需要最优化的参数的取值。比如:cv_params = {'n_estimators': [550, 575, 600, 650, 675]}
- scoring :准确度评价标准,默认None,这时需要使用score函数;或者如scoring='roc_auc',根据所选模型不同,评价准则不同。字符串(函数名),或是可调用对象,需要其函数签名形如:scorer(estimator, X, y);如果是None,则使用estimator的误差估计函数。scoring参数选择如下:
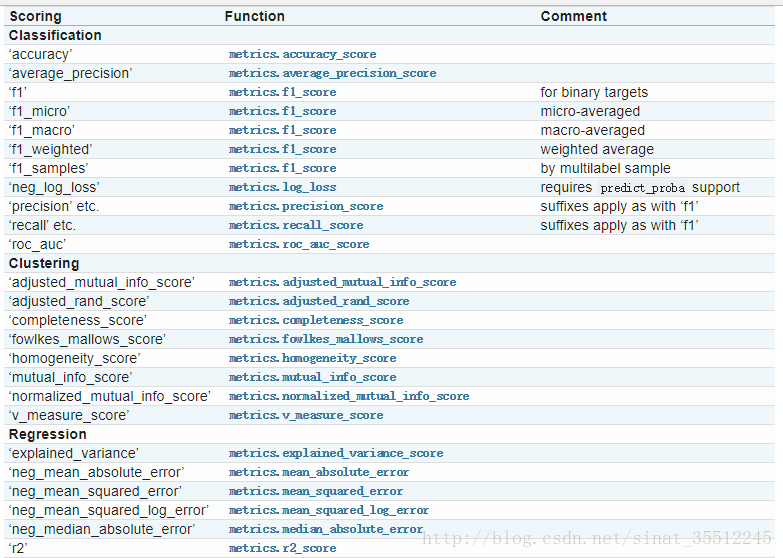
这次实战我使用的是r2这个得分函数,当然大家也可以根据自己的实际需要来选择。
调参刚开始的时候,一般要先初始化一些值:
- learning_rate: 0.1
- n_estimators: 500
- max_depth: 5
- min_child_weight: 1
- subsample: 0.8
- colsample_bytree:0.8
- gamma: 0
- reg_alpha: 0
- reg_lambda: 1
你可以按照自己的实际情况来设置初始值,上面的也只是一些经验之谈吧。
调参的时候一般按照以下顺序来进行:
1、最佳迭代次数:n_estimators
<span style="color:#000000"><span style="background-color:#282c34"><code><span style="color:#abb2bf">if</span> __name__ == <span style="color:#abb2bf">'__main__'</span>:
trainFilePath = <span style="color:#abb2bf">'dataset/soccer/train.csv'</span>
<span style="color:#abb2bf">test</span>FilePath = <span style="color:#abb2bf">'dataset/soccer/test.csv'</span>
data = pd.read_csv(trainFilePath)
X_train, y_train = featureSet(data)
X_<span style="color:#abb2bf">test</span> = loadTestData(<span style="color:#abb2bf">test</span>FilePath)
</code></span></span><span style="color:#000000"><span style="background-color:#282c34"><code>cv_params = {<span class="hljs-string" data-spm-anchor-id="a2c4e.11153940.blogcont572590.i9.56c7222bmrNz4J">'n_estimators'</span>: [400, 500, 600, 700, 800]} other_params = {<span class="hljs-string">'learning_rate'</span>: 0.1, <span class="hljs-string">'n_estimators'</span>: 500, <span class="hljs-string">'max_depth'</span>: 5, <span class="hljs-string">'min_child_weight'</span>: 1, <span class="hljs-string">'seed'</span>: 0, <span class="hljs-string">'subsample'</span>: 0.8, <span class="hljs-string">'colsample_bytree'</span>: 0.8, <span class="hljs-string">'gamma'</span>: 0, <span class="hljs-string">'reg_alpha'</span>: 0, <span class="hljs-string">'reg_lambda'</span>: 1} model = xgb.XGBRegressor(**other_params) optimized_GBM = GridSearchCV(estimator=model, param_grid=cv_params, scoring=<span class="hljs-string">'r2'</span>, cv=5, verbose=1, n_<span class="hljs-built_in">jobs</span>=4) optimized_GBM.fit(X_train, y_train) evalute_result = optimized_GBM.grid_scores_ <span class="hljs-built_in">print</span>(<span class="hljs-string">'每轮迭代运行结果:{0}'</span>.format(evalute_result)) <span class="hljs-built_in">print</span>(<span class="hljs-string">'参数的最佳取值:{0}'</span>.format(optimized_GBM.best_params_)) <span class="hljs-built_in">print</span>(<span class="hljs-string">'最佳模型得分:{0}'</span>.format(optimized_GBM.best_score_)) </code></span></span>写到这里,需要提醒大家,在代码中有一处很关键:
model = xgb.XGBRegressor(**other_params)中两个*号千万不能省略!可能很多人不注意,再加上网上很多教程估计是从别人那里直接拷贝,没有运行结果,所以直接就用了 model = xgb.XGBRegressor(other_params)。悲剧的是,如果直接这样运行的话,会报如下错误:
<span style="color:#000000"><span style="background-color:#282c34"><code><span style="color:#abb2bf">xgboost</span><span style="color:#abb2bf">.core</span><span style="color:#abb2bf">.XGBoostError</span>: <span style="color:#abb2bf">b</span>"<span style="color:#abb2bf">Invalid</span> <span style="color:#abb2bf">Parameter</span> <span style="color:#abb2bf">format</span> <span style="color:#abb2bf">for</span> <span style="color:#abb2bf">max_depth</span> <span style="color:#abb2bf">expect</span> <span style="color:#abb2bf">int</span> <span style="color:#abb2bf">but</span> <span style="color:#abb2bf">value</span>...</code></span></span>不信,请看链接:xgboost issue
以上是血的教训啊,自己不运行一遍代码,永远不知道会出现什么Bug!
运行后的结果为:
<span style="color:#000000"><span style="background-color:#282c34"><code>[Parallel(n_jobs=<span style="color:#abb2bf">4</span>)]: Done <span style="color:#abb2bf">25</span> <span style="color:#abb2bf">out</span> of <span style="color:#abb2bf">25</span> | elapsed: <span style="color:#abb2bf">1.5</span>min finished
每轮迭代运行结果:[mean: <span style="color:#abb2bf">0.94051</span>, std: <span style="color:#abb2bf">0.01244</span>, <span style="color:#abb2bf">params</span>: {<span style="color:#abb2bf">'n_estimators'</span>: <span style="color:#abb2bf">400</span>}, mean: <span style="color:#abb2bf">0.94057</span>, std: <span style="color:#abb2bf">0.01244</span>, <span style="color:#abb2bf">params</span>: {<span style="color:#abb2bf">'n_estimators'</span>: <span style="color:#abb2bf">500</span>}, mean: <span style="color:#abb2bf">0.94061</span>, std: <span style="color:#abb2bf">0.01230</span>, <span style="color:#abb2bf">params</span>: {<span style="color:#abb2bf">'n_estimators'</span>: <span style="color:#abb2bf">600</span>}, mean: <span style="color:#abb2bf">0.94060</span>, std: <span style="color:#abb2bf">0.01223</span>, <span style="color:#abb2bf">params</span>: {<span style="color:#abb2bf">'n_estimators'</span>: <span style="color:#abb2bf">700</span>}, mean: <span style="color:#abb2bf">0.94058</span>, std: <span style="color:#abb2bf">0.01231</span>, <span style="color:#abb2bf">params</span>: {<span style="color:#abb2bf">'n_estimators'</span>: <span style="color:#abb2bf">800</span>}]
参数的最佳取值:{<span style="color:#abb2bf">'n_estimators'</span>: <span style="color:#abb2bf">600</span>}
最佳模型得分:<span style="color:#abb2bf">0.9406056804545407</span></code></span></span>由输出结果可知最佳迭代次数为600次。但是,我们还不能认为这是最终的结果,由于设置的间隔太大,所以,我又测试了一组参数,这次粒度小一些:
<span style="color:#000000"><span style="background-color:#282c34"><code> cv_params = {<span style="color:#abb2bf">'n_estimators'</span>: [550, 575, 600, 650, 675]}
other_params = {<span style="color:#abb2bf">'learning_rate'</span>: 0.1, <span style="color:#abb2bf">'n_estimators'</span>: 600, <span style="color:#abb2bf">'max_depth'</span>: 5, <span style="color:#abb2bf">'min_child_weight'</span>: 1, <span style="color:#abb2bf">'seed'</span>: 0,
<span style="color:#abb2bf">'subsample'</span>: 0.8, <span style="color:#abb2bf">'colsample_bytree'</span>: 0.8, <span style="color:#abb2bf">'gamma'</span>: 0, <span style="color:#abb2bf">'reg_alpha'</span>: 0, <span style="color:#abb2bf">'reg_lambda'</span>: 1}</code></span></span>运行后的结果为:
<span style="color:#000000"><span style="background-color:#282c34"><code>[Parallel(n_jobs=<span style="color:#abb2bf">4</span>)]: Done <span style="color:#abb2bf">25</span> <span style="color:#abb2bf">out</span> of <span style="color:#abb2bf">25</span> | elapsed: <span style="color:#abb2bf">1.5</span>min finished
每轮迭代运行结果:[mean: <span style="color:#abb2bf">0.94065</span>, std: <span style="color:#abb2bf">0.01237</span>, <span style="color:#abb2bf">params</span>: {<span style="color:#abb2bf">'n_estimators'</span>: <span style="color:#abb2bf">550</span>}, mean: <span style="color:#abb2bf">0.94064</span>, std: <span style="color:#abb2bf">0.01234</span>, <span style="color:#abb2bf">params</span>: {<span style="color:#abb2bf">'n_estimators'</span>: <span style="color:#abb2bf">575</span>}, mean: <span style="color:#abb2bf">0.94061</span>, std: <span style="color:#abb2bf">0.01230</span>, <span style="color:#abb2bf">params</span>: {<span style="color:#abb2bf">'n_estimators'</span>: <span style="color:#abb2bf">600</span>}, mean: <span style="color:#abb2bf">0.94060</span>, std: <span style="color:#abb2bf">0.01226</span>, <span style="color:#abb2bf">params</span>: {<span style="color:#abb2bf">'n_estimators'</span>: <span style="color:#abb2bf">650</span>}, mean: <span style="color:#abb2bf">0.94060</span>, std: <span style="color:#abb2bf">0.01224</span>, <span style="color:#abb2bf">params</span>: {<span style="color:#abb2bf">'n_estimators'</span>: <span style="color:#abb2bf">675</span>}]
参数的最佳取值:{<span style="color:#abb2bf">'n_estimators'</span>: <span style="color:#abb2bf">550</span>}
最佳模型得分:<span style="color:#abb2bf">0.9406545392685364</span></code></span></span>果不其然,最佳迭代次数变成了550。有人可能会问,那还要不要继续缩小粒度测试下去呢?这个我觉得可以看个人情况,如果你想要更高的精度,当然是粒度越小,结果越准确,大家可以自己慢慢去调试,我在这里就不一一去做了。
其实调参对于模型准确率的提高有一定的帮助,但这是有限的。最重要的还是要通过数据清洗,特征选择,特征融合,模型融合等手段来进行改进!