第一部分 对几个芯片的认识和了解
1. AI芯片与传统芯片
人工智能是一个很老很老的概念,而神经网络只不过是人工智能范畴的一个子集。早在1956年,被誉为“人工智能之父”的图灵奖得主约翰·麦卡锡就这样定义人工智能:创造智能机器的科学与工程。而在1959年,Arthur Samuel给出了人工智能的一个子领域机器学习的定义,即“计算机有能力去学习,而不是通过预先准确实现的代码”,这也是目前公认的对机器学习最早最准确的定义。而我们日常所熟知的神经网络、深度学习等都属于机器学习的范畴,都是受大脑机理启发而发展得来的。另外一个比较重要的研究领域就是脉冲神经网络,国内具有代表的单位和企业是清华大学类脑计算研究中心和上海西井科技等。

所谓的AI芯片,一般是指针对AI算法的ASIC(专用芯片)。 传统的CPU、GPU都可以拿来执行AI算法,但是速度慢,性能低,无法实际商用。
2.几个关键词
对于人工智能技术,数据、算力和算法,这三大要素是相互促进、缺一不可的。
2.1.CPU
是“Central Processing Unit”的英语缩写,中文意思是“中央处理器”,有时我们也简称它为“处理器”或是“微处理器”。它是整个计算机系统的运算、控制中心,也就是计算机的“大脑”。CPU的工作原理:CPU的内部结构可分为控制、逻辑、存储三大部分。如果将CPU比作一台机器的话,其工作原理大致是这样的:首先是CPU将“原料”(程序发出的指令)经过“物质分配单位”(控制单元)进行初步调节,然后送到“加工车床”(逻辑运算单元)进行加工,最后将加工出来的“产品”(处理后的数据)存储到“仓库”(存储器)中,以后“销售部门”(应用程序)就可到“仓库”中按需提货了。
CPU最主要的优势就是通用性,它必须适应各种不同的应用场景,同时尽可能保持高性能和低功耗,这其实是一件非常复杂的事情。把设计芯片比作开饭店,那么设计那些针对特定应用的专用芯片就好比是开个火锅店,或者拉面馆,只需要专注于做好几道看家菜就可以了。而设计CPU就好比是开个大酒楼,各大菜系都得整明白,煎炒烹炸也得样样精通,甚至西餐甜点也得配齐。为了实现和完善这种通用性,现代CPU的设计思路也在不断进化。除了不断升级微架构,做到性能和功耗的迭代优化外,CPU还在不断集成一些专用的加速单元,用来处理像人工智能这样非常重要或者流行度越来越高的应用。这种以通用性能升级为主,并兼顾部分专用应用加速技术的思路,就成为了现代CPU设计的主旋律。
中央处理器作为计算机系统的运算和控制核心,是信息处理、程序运行的最终执行单元,CPU 是对计算机的所有硬件资源(如存储器、输入输出单元) 进行控制调配、执行通用运算的核心硬件单元。优点:CPU有大量的缓存和复杂的逻辑控制单元,非常擅长逻辑控制、串行的运算;缺点:不擅长复杂算法运算和处理并行重复的操作。
对于AI芯片来说,算力最弱的是cpu。虽然cpu主频最高,但是单颗也就8核,16核的样子,一个核3.5g,16核也就56g,再考虑指令周期,每秒最多也就30g次乘法。
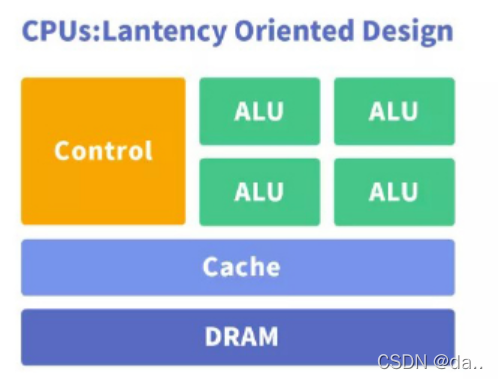
2.2.GPU
GraphicsProcessing Unit。图形处理器,又称显示核心、视觉处理器、显示芯片,是一种专门在个人电脑、工作站、游戏机和一些移动设备(如平板电脑、智能手机等)上做图像和图形相关运算工作的微处理器,设计初衷是为了应对图像处理中需要大规模并行计算。
优点:提供了多核并行计算的基础结构,且核心数非常多,可以支撑大量数据的并行计算,拥有更高的浮点运算能力。
缺点:管理控制能力(最弱),功耗(最高);第一,应用过程中无法充分发挥并行计算优势。深度学习包含训练和应用两个计算环节,GPU 在深度学习算法训练上非常高效,但在应用时一次性只能对于一张输入图像进行处理,并行度的优势不能完全发挥;第二,硬件结构固定不具备可编程性。深度学习算法还未完全稳定,若深度学习算法发生大的变化,GPU 无法像FPGA 一样可以灵活的配置硬件结构;第三,运行深度学习算法能效远低于FPGA。学术界和产业界研究已经证明,运行深度学习算法中实现同样的性能,GPU 所需功耗远大于FPGA,例如国内初创企业深鉴科技基于FPGA 平台的人工智能芯片在同样开发周期内相对GPU能效有一个数量级的提升。
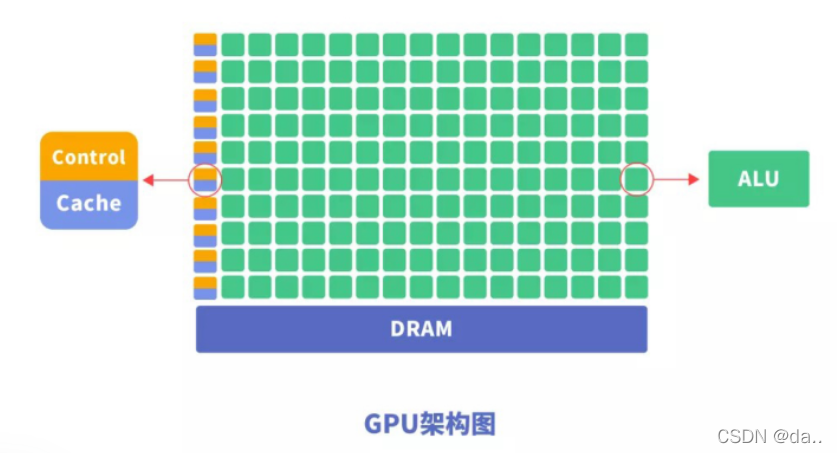
2.3.FPGA
FPGA 器件属于专用集成电路中的一种半定制电路,是可编程的逻辑列阵,FPGA 的基本结构包括可编程输入输出单元,可配置逻辑块,数字时钟管理模块,嵌入式块RAM,布线资源,内嵌专用硬核,底层内嵌功能单元。由于FPGA具有布线资源丰富,可重复编程和集成度高,投资较低的特点,在数字电路设计领域得到了广泛的应用。
FPGA的优点如下:
(1) FPGA由逻辑单元、RAM、乘法器等硬件资源组成,通过将这些硬件资源合理组织,可实现乘法器、寄存器、地址发生器等硬件电路。
(2) FPGA可通过使用框图或者Verilog HDL来设计,从简单的门电路到FIR或者FFT电路。
(3) FPGA可无限地重新编程,加载一个新的设计方案只需几百毫秒,利用重配置可以减少硬件的开销。
(4) FPGA的工作频率由FPGA芯片以及设计决定,可以通过修改设计或者更换更快的芯片来达到某些苛刻的要求(当然,工作频率也不是无限制的可以提高,而是受当前的IC工艺等因素制约)。
FPGA的缺点如下:
(1) FPGA的所有功能均依靠硬件实现,无法实现分支条件跳转等操作。
(2) FPGA只能实现定点运算。

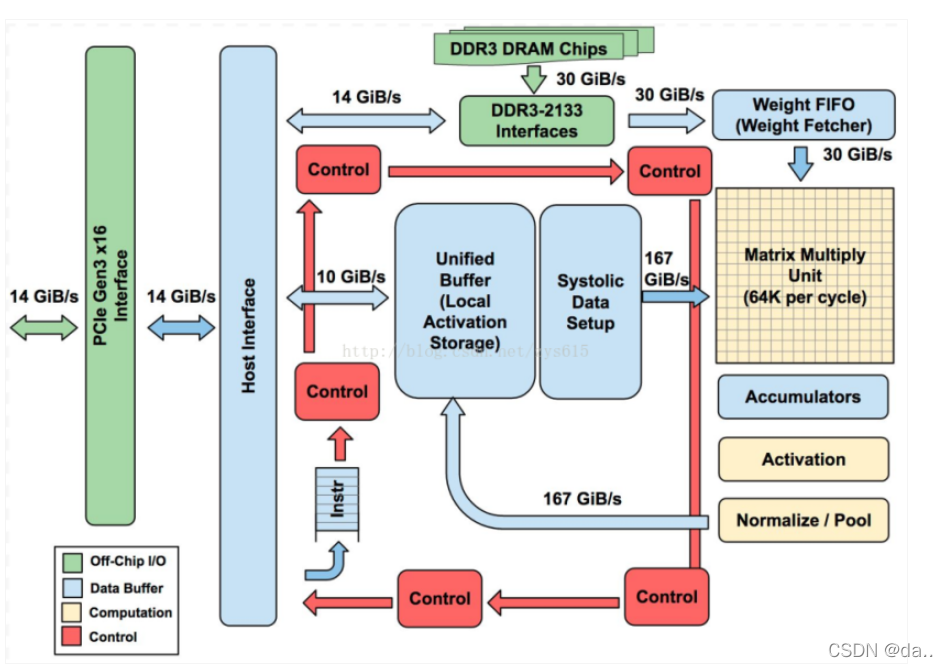
2.4.TPU
张量处理器(英语:tensor processing unit,缩写:TPU)是Google为机器学习定制的专用芯片(ASIC),专为Google的深度学习框架TensorFlow而设计。与图形处理器(GPU)相比,TPU采用低精度(8位)计算,以降低每步操作使用的晶体管数量。降低精度对于深度学习的准确度影响很小,但却可以大幅降低功耗、加快运算速度。同时,TPU使用了脉动阵列的设计,用来优化矩阵乘法与卷积运算,减少I/O操作。此外,TPU还采用了更大的片上内存,以此减少对DRAM的访问,从而更大程度地提升性能。
Google在2016年的Google I/O年会上首次公布了TPU。不过在此之前TPU已在Google内部的一些项目中使用了一年多,如Google街景服务、RankBrain以及其旗下DeepMind公司的围棋软件AlphaGo等都用到了TPU。而在2017年的Google I/O年会上,Google又公布了第二代TPU,并将其部署在Google云平台之上。第二代TPU的浮点运算能力高达每秒180万亿次。
2.5.IPU
是具有强化的加速器和以太网连接的高级网络设备,它使用紧密耦合、专用的可编程内核加速和管理基础架构功能。IPU 提供全面的基础架构分载,并可作为运行基础架构应用的主机的控制点,从而提供一层额外防护。由英特尔公司开发。
2.6.NPU
嵌入式神经网络处理器(NPU)采用“数据驱动并行计算”的架构,特别擅长处理视频、图像类的海量多媒体数据。
NPU处理器专门为物联网人工智能而设计,用于加速神经网络的运算,解决传统芯片在神经网络运算时效率低下的问题。在GX8010中,CPU和MCU各有一个NPU,MCU中的NPU相对较小,习惯上称为SNPU。NPU处理器包括了乘加、激活函数、二维数据运算、解压缩等模块。乘加模块用于计算矩阵乘加、卷积、点乘等功能,NPU内部有64个MAC,SNPU有32个。激活函数模块采用最高12阶参数拟合的方式实现神经网络中的激活函数,NPU内部有6个MAC,SNPU有3个。二维数据运算模块用于实现对一个平面的运算,如降采样、平面数据拷贝等,NPU内部有1个MAC,SNPU有1个。
解压缩模块用于对权重数据的解压。为了解决物联网设备中内存带宽小的特点,在NPU编译器中会对神经网络中的权重进行压缩,在几乎不影响精度的情况下,可以实现6-10倍的压缩效果。
2.7.类脑芯片
类人脑芯片架构是一款基于神经形态的工程,旨在打破“冯·诺依曼”架构的束缚,模拟人脑处理过程,感知世界、处理问题。这种芯片的功能类似于大脑的神经突触,处理器类似于神经元,而其通讯系统类似于神经纤维,可以允许开发者为类人脑芯片设计应用程序。通过这种神经元网络系统,计算机可以感知、记忆和处理大量不同的信息。类脑芯片的两大突破:1、有望形成自主认知的新形式;2、突破传统计算机体系结构的限制,实现数据并行传送、分布式处理,能以极低功耗实时处理大量数据。
3.深度神经网络加速器体系结构
在DNN加速器设计的早期阶段,加速器被设计用于加速通用处理中的近似程序或用于小型神经网络。尽管片上加速器的功能和性能非常有限,但它们揭示了AI专用芯片的基本思想。代表:神经处理单元(neural processing unit, NPU)和一种可重新配置的 NoC 加速器RENO。对于广泛使用的DNN和CNN(卷积神经网络)应用,独立的专有域的加速器在云和边缘场景中均取得了巨大的成功。与通用CPU和GPU相比,这些定制架构可提供更好的性能和更高的能效,代表:电脑(DianNao)系列和张量处理单元(TPU)。ReRAM 和混合存储立方体(HMC)是具有代表性的新兴存储技术和可实现内存中处理(PIM)的存储结构。CPU和片外存储器之间的数据移动比浮点操作消耗的能量大两个数量级。PIM可以极大地减少计算中的数据移动。DNN加速器可以从ReRAM和HMC 中获得这些好处,并应用PIM来加速DNN执行。通过应用高效的NN结构,也可以提高DNN加速器的效率,如稀疏神经网络、低精度神经网络、生成对抗网络和递归神经网络的加速器。DNN加速器的未来趋势:①DNN训练和加速器阵列;②基于ReRAM的PIM加速器;③边缘 DNN加速器。
4.AI芯片市场需求分析
GPU是目前市场上AI计算最成熟,、应用最广泛的通用芯片,按照弗若斯特沙利文的推算,2020年GPU芯片在AI芯片中的占达35.95%,占领最主要的市场份额。作为数据中心和算力的主力军,前瞻认为,GPU市场仍将以提升效率和扩大应用场景为发展目标,继续主导芯片市场。在当前技术与运用都在快速更迭的时期,FPGA可编程带来的配置灵活性使其能更快地适应市场,具有明显的实用性。随着开发者生态的逐渐丰富,适用的编程语言增加,FPGA运用将会更加广泛。在专业芯片发展得足够完善之前,FPGA作为最好的过渡产品,在短期内将成为各大厂商的选择热点。据MRFR数据,2019年全球FPGA市场规模为69.06亿美元,在5G和AI的推动下,2025年全球FPGA的市场规模有望达到125亿美元,年复合增长率达10.42%。
目前主流 AI 芯片的核心主要是利用 MAC(Multiplier and Accumulation, 乘加计算) 加速阵列来实现对 CNN(卷积神经网络)中最主要的卷积运算的加速。这一代 AI 芯片主要有如下 3 个方面的问题。
(1)深度学习计算所需数据量巨大,造成内存带宽成为整个系统的瓶颈,即所谓“memory wall” 问题。
(2)与第一个问题相关, 内存大量访问和 MAC阵列的大量运算,造成 AI芯片整体功耗的增加。
(3)深度学习对算力要求很高,要提升算力,最好的方法是做硬件加速,但是同时深度学习算法的发展也是日新月异,新的算法可能在已经固化的硬件加速器上无法得到很好的支持,即性能和灵活度之间的平衡问题。
下一代 AI 芯片将有如下的五个发展趋势:
(1)更高效的大卷积解构/复用
(2)更低的 Inference 计算/存储位宽
(3)更多样的存储器定制设计
(4)更稀疏的大规模向量实现
(5)计算和存储一体化
5.AI芯片专利技术研发态势
在2019年,GPU、FPGI、ASIC、CPLD四个分支领域的专利布局数量最多,分别是59 071项、31 455项、8 769项、4 531项。其他如类脑芯片、VPU、NPU、DPU等分支领域的专利布局数量较少,仍处于概念设计或原型制造的阶段,尚未形成大规模产品化能力。GPU领域优势机构主要来自日本、美国和韩国。其中,日本共有13家机构进入TOP20,佳能公司以3 389项专利位列全球首位,日本理光株式会社紧随其后,共有2 007项专利;美国共有6家机构进入TOP20,富士施乐公司以1 698项专利位列全球第3位,此外还包括英伟达公司、英特尔公司、微软公司、苹果公司和高通公司。FPGA领域优势机构主要来自中国、美国和韩国。其中,中国共有15家机构进入TOP20,中国科学院以838项专利位列全球首位,国家电网公司紧随其后,共有544项专利,此外还包括中国电子科技集团公司、浪潮集团、北京航空航天大学、西安电子科技大学等;美国共有3家机构进入TOP20,赛灵思公司以243项专利位列全球第7位,此外还包括Altera公司、Actel公司;CPLD领域优势机构主要来自中国、美国和韩国。其中,中国共有18家机构进入TOP20,浪潮集团以264项专利位列全球首位,郑州云海信息技术有限公司紧随其后,共有215项专利,此外还包括英业达科技有限公司、国家电网公司、鸿海集团、中国科学院等;美国有1家机构进入TOP20,赛灵思公司以20项专利位列全球第12位。
第二部分 国内外AI集成电路现状
1.国内的集成电路产业分布
集成电路作为技术密集的高科技产业,基本集中在国内较为发达的一二线城市。
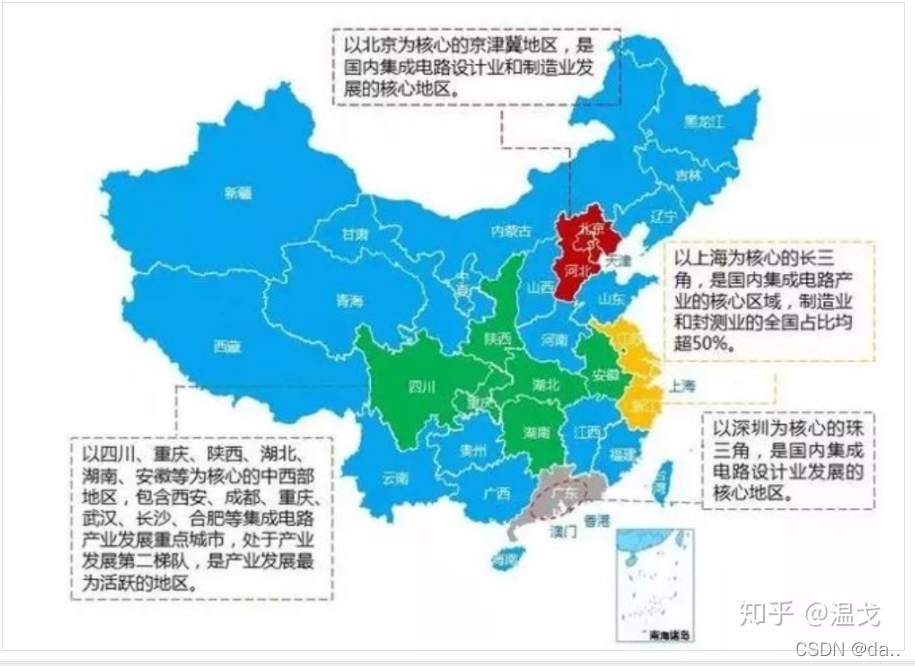
目前形成了以京津冀地区、长三角地区、珠三角地区、中西部地区为核心的四大城市群。
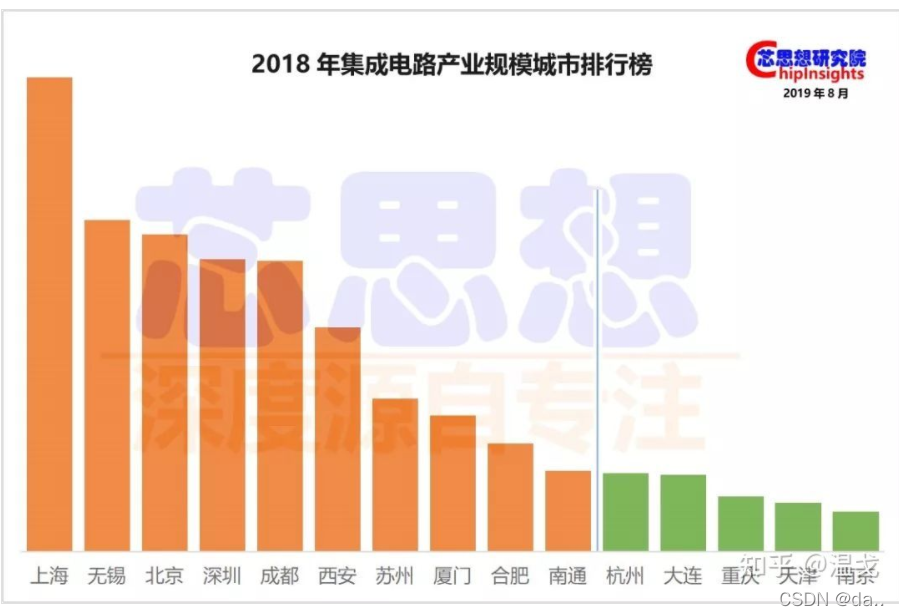
从芯思想研究院发布的数据看,前十大城市中,长三角占据一半,五席分别是上海、无锡、苏州、合肥、南通;环渤海只有北京一个入围;珠三角和中西部各有两席。
过百亿的15个城市集成电路产业规模合计为8280亿元,前10大城市集成电路产业规模合计为7370亿元,占比89%。
a.长三角
上海
据上海集成电路行业协会的数据,2018年上海集成电路产业规模达1450亿,较2017年实现23%的增长,位居全国各城市之首。
上海在设计领域,部分企业研发能力已达7纳米,紫光展锐手机基带芯片市场份额位居世界第三。在制造领域,中芯国际、华虹集团年销售额在国内位居前两位,28纳米先进工艺已量产,14纳米工艺研发基本完成。在装备材料领域,中微、上微处于国内领先水平。
上海集成电路产业投资基金总额500亿元,分为100亿元的装备材料基金、100亿元的设计基金、300亿元的制造基金。基金将加快促进汽车芯片、智能移动芯片、物联网芯片、AI储存器芯片、安全芯片以及智能储存器芯片等高端芯片的研发和生产。
无锡
根据江苏省半导体行业协会的最新数据来看,无锡市在2018年集成电路产业规模达1014亿元,较2017年实现14%的增长。
无锡市当属江苏省集成电路产业发展水平最高的城市,无锡市原计划到2019年集成电路产业规模达1000亿元,提前一年超额完成任务,无疑已是国内集成电路产业第一方阵行列。
无锡作为“国家南方微电子工业基地中心”,近年来一直在构造集成电路“芯”版图,经年积累形成了较为完备的产业链,集聚了包括华虹半导体、华润微电子、长电科技、中科芯、中德电子(江阴润玛)、江化微、东晨电子、固电半导体、宜兴中环领先等在内的200多家企业,涵盖集成电路设计、制造、封装测试、装备与材料等多个领域,集成电路的全产业链发展格局在锡渐成,勾勒出了无锡集成电路的美丽风景。
2000年以来,先后成为国家科技部批准的8个国家集成电路设计产业化基地之一、全国仅有的两个由国家发改委认定的国家微电子高新技术产业基地之一(另一家是上海)。
不过无锡IC设计业偏弱,占比仅为10%;制造业占比25%;封测业占比高达40%,设备材料占比25%。
苏州
2018年苏州集成电路产业规模较2017年实现7%增长。
苏州在集成电路封装测试、集成电路设计、第三代半导体材料等方面保持国内领先,拥有中科院苏州纳米所等为代表的一大批科研院所和龙头企业,随着中科曙光、澜起科技等一批旗舰项目落户,集聚效应已初步形成。目前,苏州市在芯片最有价值的设计领域,已积累了一批实力企业。当前,苏州市重点支持工业园区和昆山等地区发展集成电路封装和测试产业。园区是国内集成电路产业最集中、企业最密集的地区之一,目前已集聚集成电路设计企业40多家。
合肥
2018年合肥市集成电路产业规模较2017年实现25%的增长。在长鑫量产后,预计2019年合肥集成电路产业规模会有较大增长。

合肥市打造中国IC之都,被列为全国九大集成电路集聚发展基地之一,计划到2020年集成电路产业规模达500亿,其中设计业100亿,制造业300亿,封测60亿,设备材料40亿。随着晶合集成、长鑫集成的投产以及强势引进的一批设计、材料企业,加上宏实自动化、易芯半导体、大华半导体、芯碁微电子等一批本土企业,合肥已逐步形成了集成电路设计、制造、封测、设备材料等全产业链,并带动其他高科技产业取得了良好的发展态势。

在产业布局上,合肥市现已形成了三大集成电路产业基地——经开区、高新区、新站高新区。2018年9月27日合肥市正式被授牌成为“海峡两岸集成电路产业合作试验区”,合作试验区包括合肥市三大集成电路产业基地——经开区、高新区、新站高新区。
统计数据显示,去年,合肥市集成电路产量7.31亿块,同比增长11.7%。前段时间,在芯思想研究院发布的2021年中国大陆城市集成电路竞争力排行榜上,合肥市排名已经由2020年的第8名上升至第6名。
今年一季度,合肥市集成电路产量达到22297.49万块,增长了75.6%。前4个月,合肥市战新产业产值同比增长52.2%,两年平均增长22.5%;作为主要产品中的集成电路增长了56.6%。
安徽省“十四五”规划纲要提出,未来几年,安徽省将做大做强长鑫、晶合等龙头企业,迅速提升集成电路制造规模和能级,积极参与国家集成电路制造业创新中心等平台建设,打造高效协同的集成电路产业集群。
当前,合肥市已经确定了“十四五”集成电路产业发展规划的编制第三方单位。接下来,这个规划将提出合肥市全方位提升集成电路产业战略,重点围绕产业定位、发展目标、发展方向、发展路径、招商引资等方面,研究制定合肥市集成电路产业提升的工作部署。
下一步,合肥市将加快国产集成电路的技术创新步伐,进一步完善“合肥芯”“合肥产”“合肥用”全链条,全面提升集成电路产业集群能级。力争到2025年,全市集成电路产业的产值突破1000亿元。
南通
2018年南通集成电路产业规模较2017年实现23%增长。
近几年南通集成电路产业飞速发展,已初步形成完整产业体系。汇聚了包括通富微电、越亚半导体、京芯光电、捷捷微电子、启微半导体在内的一批企业。
杭州
杭州市致力打造集成电路设计创新之都,从杭州市人民政府印发的《杭州市集成电路产业发展规划》可以看出,到2020年年底,全市集成电路产业主营业务收入力争达到500亿元;明确提出集成电路设计业是杭州信息经济创新发展的长期有效的驱动力,重点发展集成电路设计产业,提升全市整机系统企业的核心竞争力。杭州市的行动目标重点发展芯片设计,选择特色芯片、高端存储芯片等芯片的制造,兼顾封装测试与材料的较为完整的集成电路产业链。
杭州是八个国家集成电路产业设计基地之一,经过多年发展,在集成电路设计领域已经取得了一些优势,汇聚了包括中天微系统、广立微电子、士兰微在内的一批优质公司。目前拥有多个细分领域精尖核心技术,在嵌入式CPU、EDA工具、微波毫米波射频集成电路、数字音视频、数字电视、固态存储(固态硬盘控制器)、计算机接口控制器(包括磁盘阵列和桥接芯片)、LED芯片和光电集成电路等领域技术水平处于国内领先地位,个别甚至处于国际先进水平,进入了国际主流市场。
南京
2018年,南京集成电路产业规模实现了56%的增长,一举突破100亿大关。
南京的集成电路产业主要聚集在江北新区,目前已经拥有台积电、华天科技、长晶科技等一批行业龙头,集聚了260余家集成电路产业企业,覆盖行业内芯片设计、晶圆制造、封装测试、终端制造等全产业链环节。
b.珠三角
深圳
深圳市2018年集成电路产业规模为890亿,较2017年实现34%的增长。
深圳市的集成电路产业规模位列珠三角地区首位,规划到2023年建成具有国际竞争力的集成电路产业集群。
深圳作为国内集成电路产业重要聚集区,长期处于设计业龙头位置,在晶圆制造、封装测试领域非常薄弱。根据深圳新的产业规划,当地将补齐芯片制造业和先进封测业产业链缺失环节,聚焦提升芯片设计业能级和技术水平,注重前瞻布局第三代半导体,努力优化产业生态系统,加快关键核心技术攻关,培育龙头骨干企业和集成电路产业集群。
c.京津冀
北京
2018年集成电路产业规模达970亿,较2017年实现8%的增长;排名仅仅次于上海和无锡,位居全国第三。
北京市规划到2020年建成设具有国际影响力的集成电路产业技术创新基地。经过多年发展,北京形成了 “北(海淀)设计,南(亦庄)制造”的集成电路产业空间布局,积累了一定的“家底儿”。以中芯北方、北方华创、屹唐半导体、集创北方为代表的一批产业链上下游企业,正紧密合作,协同打造北京集成电路产业的“芯”实力。
天津
2018年,由于统计口径的不同,天津集成电路产业规模较2017年有20%的下滑。
天津市致力建成具有国际竞争力的集成电路产业集群,计划到2020年集成电路产业规模达到600亿元。天津集成电路产业逐步形成了IC设计、芯片制造、封装测试三业并举、新型半导体材料与高端设备支撑配套业共同发展的相对完整的产业链格局,聚拢了集成电路企业百余家,聚集了紫光展锐、唯捷创芯、国芯等一批国内集成电路设计龙头企业;芯片制造业拥有中芯国际、中环股份、诺思科技等知名企业;封装测试业有恩智浦半导体、金海通、双竞科技等重点企业;材料与设备支撑业聚集了中环半导体、中电46所、华海清科等企业。
d.陕川渝
成都
2018年成都集成电路产业规模较2017年实现23%增长。
成都市要跻身国内集成电路设计第一方阵,打造中国“芯”高地,规划到2035年集成电路产业规模3400亿元。这个规划周期确实有点远。
成都的集成电路产业主要集聚在高新区。在芯片设计方面,拥有各类设计公司120多家,包括振芯科技、锐成芯微、和芯微、雷电微力、华大九天、华为海思、新华三等各具特色的企业,设计领域涵盖网络通讯、智能家电、物联网、北斗导航、IP等;在晶圆制造方面,拥有德州仪器8英寸晶圆生产线;在半导体封测方面,成都拥有华天科技(原宇芯)、士兰微、英特尔、德州仪器、芯源系统(MPS)等近十家封装测试企业,形成西南最大的芯片封装测试基地。。
西安
2018年西安集成电路产业规模较2017年实现5%增长。
西安市打造集成电路产业新高地,规划在2021年集成电路产业规模达1000亿元。西安依靠三星电子存储芯片项目和华天科技西安、美光/力成封装项目,大大增强了西安在集成电路产业中的竞争力。
目前西安形成了从半导体设备和材料的研制与生产,到集成电路设计、制造、封装测试及系统应用的较完整产业链。
从整个产业链的发展情况来看,西安集成电路产业已经形成制造业一枝独秀,设计业与封装测试业相互依存、协调发展的产业格局。
重庆
重庆市规划到2022年力争成为中国集成电路创新高地,集成电路产业规模达1000亿。重庆一直是我国重要的电子信息产业基地,但电子信息产业需要高水平集成电路技术支撑产业发展。重庆将养生培育高端功率半导体芯片项目,重点解决制约集成电路产业发展的技术问题和创新生态问题,实现重庆产芯片产品全面支撑重庆市智能终端、物联网、汽车电子、智能制造、仪器仪表、5G通信等电子信息领域应用需求。
重庆的集成电路产业主要集中在西永微电子产业园区,园区已构建从EDA平台、共享IP库、芯片设计、制造到封装测试的集成电路全新产业生态,吸引了华润微电子、SK海力士、中国电科、西南集成等一批知名集成电路企业聚集发展。目前正全力打造全球协同研发创新平台UMEC联合微电子中心、全国最大功率半导体基地和韩国SK海力士集团全球最大的芯片封装测试工厂。
e.其他
厦门
2018年厦门集成电路产业规模突破400亿关口。
厦门市是国家集成电路布局规划重点城市,致力构建集成电路全产业链,规划到2025年集成电路产业将达1500亿元。厦门已经形成火炬高新区、海沧区、自贸试验区湖里片区三个集成电路集聚区,目前成功引进了一大批龙头项目,初步覆盖集成电路设计、制造、封测、装备与材料以及应用等产业链环节,聚集了三安光电、联芯集成、士兰微、通富微电、紫光展锐、瀚天天成、美日丰创等200多家集成电路企业,部分环节的生产力达到国际一流水平。
大连
2018年大连市集成电路产业规模较2017年实现60%增长,其中英特尔大连就高达227亿。
大连市要打造世界级集成电路产业基地,计划到2025年集成电路产业规模达500亿。2108年随着英特尔大连工厂二期扩建项目投产,有力助推大连市集成电路产业发展水平迈向新的高度。
2.国内AI芯片发展现状
2020中国人工智能芯片企业TOP50
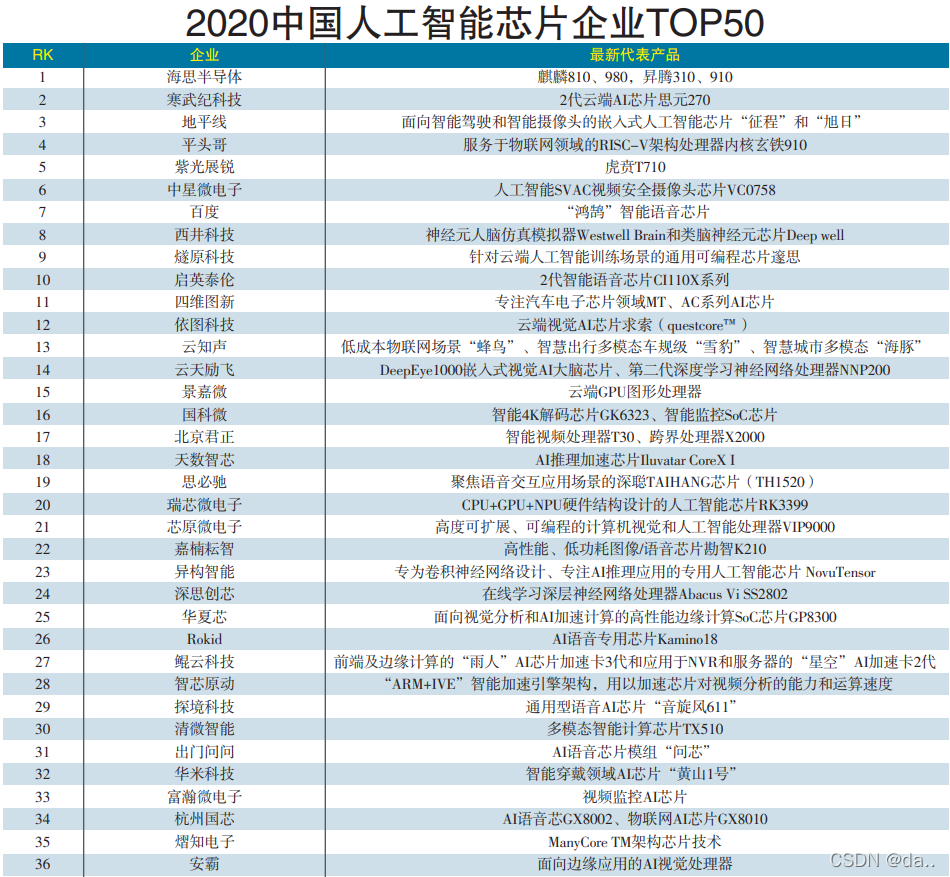
可以说,国内各个单位在人工智能处理器领域的发展和应用与国外相比依然存在很大的差距。由于我国特殊的环境和市场,国内人工智能处理器的发展呈现出百花齐放、百家争鸣的态势,这些单位的应用领域遍布股票交易、金融、商品推荐、安防、早教机器人以及无人驾驶等众多领域,催生了大量的人工智能芯片创业公司,如地平线、深鉴科技、中科寒武纪等。尽管如此,国内起步较早的中科寒武纪却并未如国外大厂一样形成市场规模,与其他厂商一样,存在着各自为政的散裂发展现状。
a.全球AI芯片界首个独角兽——寒武纪
2017年8月,国内AI芯片初创公司寒武纪宣布已经完成1亿美元A轮融资,战略投资方可谓阵容豪华,阿里巴巴、联想、科大讯飞等企业均参与投资。而其公司也成为全球AI芯片界首个独角兽,受到国内外市场广泛关注。
寒武纪科技主要负责研发生产AI芯片,公司最主要的产品为2016年发布的寒武纪1A处理器(Cambricon-1A),是一款可以深度学习的神经网络专用处理器,面向智能手机、无人机、安防监控、可穿戴设备以及智能驾驶等各类终端设备,在运行主流智能算法时性能功耗比全面超越传统处理器。目前已经研发出1A、1H等多种型号。与此同时,寒武纪也推出了面向开发者的寒武纪人工智能软件平台 Cambricon NeuWare,包含开发、调试和调优三大部分。
b.软硬件协同发展的典范——深鉴科技
深鉴科技的联合创始人韩松在不同场合曾多次提及软硬件协同设计对人工智能处理器的重要性,而其在FPGA领域顶级会议FPGA2017最佳论文ESE硬件架构就是最好的证明。该项工作聚焦于使用 LSTM 进行语音识别的场景,结合深度压缩(Deep Compression)、专用编译器以及 ESE 专用处理器架构,在中端的 FPGA 上即可取得比 Pascal Titan X GPU 高 3 倍的性能,并将功耗降低 3.5 倍。
在2017年10月的时候,深鉴科技推出了六款AI产品,分别是人脸检测识别模组、人脸分析解决方案、视频结构化解决方案、ARISTOTLE架构平台,深度学习SDK DNNDK、双目深度视觉套件。而在人工智能芯片方面,公布了最新的芯片计划,由深鉴科技自主研发的芯片“听涛”、“观海”将于2018年第三季度面市,该芯片采用台积电28nm工艺,亚里士多德架构,峰值性能 3.7 TOPS/W。
c.对标谷歌TPU——比特大陆算丰
作为比特币独角兽的比特大陆,在2015年开始涉足人工智能领域,其在2017年发布的面向AI应用的张量处理器算丰Sophon BM1680,是继谷歌TPU之后,全球又一款专门用于张量计算加速的专用芯片(ASIC),适用于CNN / RNN / DNN的训练和推理。
BM1680单芯片能够提供2TFlops单精度加速计算能力,芯片由64 NPU构成,特殊设计的NPU调度引擎(Scheduling Engine)可以提供强大的数据吞吐能力,将数据输入到神经元核心(Neuron Processor Cores)。BM1680采用改进型脉动阵列结构。2018年比特大陆将发布第2代算丰AI芯片BM1682,计算力将有大幅提升。
3. 国外AI芯片发展现状
技术寡头,优势明显
由于具有得天独厚的技术和应用优势,英伟达和谷歌几乎占据了人工智能处理领域80%的市场份额,而且在谷歌宣布其Cloud TPU开放服务和英伟达推出自动驾驶处理器Xavier之后,这一份额占比在2018年有望进一步扩大。其他厂商,如英特尔、特斯拉、ARM、IBM以及Cadence等,也在人工智能处理器领域占有一席之地。
当然,上述这些公司的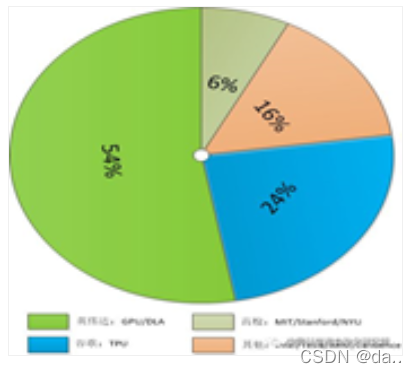
要针对云端市场,英特尔则主要面向计算机视觉,Cadence则以提供加速神经网络计算相关IP为主。如果说前述这些公司还主要偏向处理器设计等硬件领域,那么ARM公司则主要偏向软件,致力于针对机器学习和人工智能提供高效算法库。
a.独占鳌头——英伟达
在人工智能领域,英伟达可以说是目前涉及面最广、市场份额最大的公司,旗下产品线遍布自动驾驶汽车、高性能计算、机器人、医疗保健、云计算、游戏视频等众多领域。其针对自动驾驶汽车领域的全新人工智能超级计算机Xavier,用NVIDIA首席执行官黄仁勋的话来说就是“这是我所知道的 SoC 领域非常了不起的尝试,我们长期以来一直致力于开发芯片。”
Xavier 是一款完整的片上系统 (SoC),集成了被称为 Volta 的全新 GPU 架构、定制 8 核 CPU 架构以及新的计算机视觉加速器(CVA)。该处理器提供 20 TOPS(万亿次运算/秒)的高性能,而功耗仅为 20 瓦。单个 Xavier 人工智能处理器包含 70 亿个晶体管,采用最前沿的 16nm FinFET 加工技术进行制造,能够取代目前配置了两个移动 SoC 和两个独立 GPU 的 DRIVE PX 2,而功耗仅仅是它的一小部分。
而在2018年拉斯维加斯CES展会上,NVIDIA又推出了三款基于Xavier的人工智能处理器,包括一款专注于将增强现实(AR)技术应用于汽车的产品、一款进一步简化车内人工智能助手构建和部署的DRIVE IX和一款对其现有自主出租车大脑——Pegasus的修改,进一步扩大自己的优势。
b.产学研的集大成者——谷歌
如果你只是知道谷歌的AlphaGo、无人驾驶和TPU等这些人工智能相关的产品,那么你还应该知道这些产品背后的技术大牛们:谷歌传奇芯片工程师Jeff Dean、谷歌云计算团队首席科学家、斯坦福大学AI实验室主管李飞飞、Alphabet董事长John Hennessy和谷歌杰出工程师David Patterson。
时至今日,摩尔定律遇到了技术和经济上的双重瓶颈,处理器性能的增长速度越来越慢,然而社会对于计算能力的需求增速却并未减缓,甚至在移动应用、大数据、人工智能等新的应用兴起后,对于计算能力、计算功耗和计算成本等提出了新的要求。与完全依赖于通用CPU及其编程模型的传统软件编写模式不同,异构计算的整个系统包含了多种基于特定领域架构 (Domain-Specific Architecture, DSA)设计的处理单元,每一个DSA处理单元都有负责的独特领域并针对该领域做优化,当计算机系统遇到相关计算时便由相应的DSA处理器去负责。而谷歌就是异构计算的践行者,TPU就是异构计算在人工智能应用的一个很好例子。
2017年发布的第二代TPU芯片,不仅加深了人工智能在学习和推理方面的能力,而且谷歌是认真地要将它推向市场。根据谷歌的内部测试,第二代芯片针对机器学习的训练速度能比现在市场上的图形芯片(GPU)节省一半时间;第二代TPU包括了四个芯片,每秒可处理180万亿次浮点运算;如果将64个TPU组合到一起,升级为所谓的TPU Pods,则可提供大约11500万亿次浮点运算能力。
c.计算机视觉领域的搅局者——英特尔
英特尔作为世界上最大的计算机芯片制造商,近年来一直在寻求计算机以外的市场,其中人工智能芯片争夺成为英特尔的核心战略之一。为了加强在人工智能芯片领域的实力,不仅以167亿美元收购FPGA生产商Altera公司,还以153亿美元收购自动驾驶技术公司Mobileye,以及机器视觉公司Movidius和为自动驾驶汽车芯片提供安全工具的公司Yogitech,背后凸显这家在PC时代处于核心位置的巨头面向未来的积极转型。